一、本文介紹
本文給大家帶來的改進機制是利用今年新推出的AFPN(漸近特征金字塔網絡)來優化檢測頭,AFPN的核心思想是通過引入一種漸近的特征融合策略,將底層、高層和頂層的特征逐漸整合到目標檢測過程中。這種漸近融合方式有助于減小不同層次特征之間的語義差距,提高特征融合效果,使得檢測模型能更好地適應不同層次的語義信息。本文在AFPN的結構基礎上,為了適配YOLOv8改進AFPN結構,同時將AFPN融合到YOLOv8中(因為AFPN需要四個檢測頭,我們只有三個,下一篇文章我會出YOLOv8適配AFPN增加小目標檢測頭)實現暴力漲點。
推薦指數:????
打星原因:為什么打四顆星是因為我覺得這個機制的計算量會上漲,這是扣分點,同時替換這個檢測頭剛開始前20個epochs的效果不好,隨著輪次的增加漲幅才能體現出來,這也是扣分點,我給結構打分完全是客觀的,并不是我推出的結構必須滿分。
專欄回顧:YOLOv8改進系列專欄——本專欄持續復習各種頂會內容——科研必備????
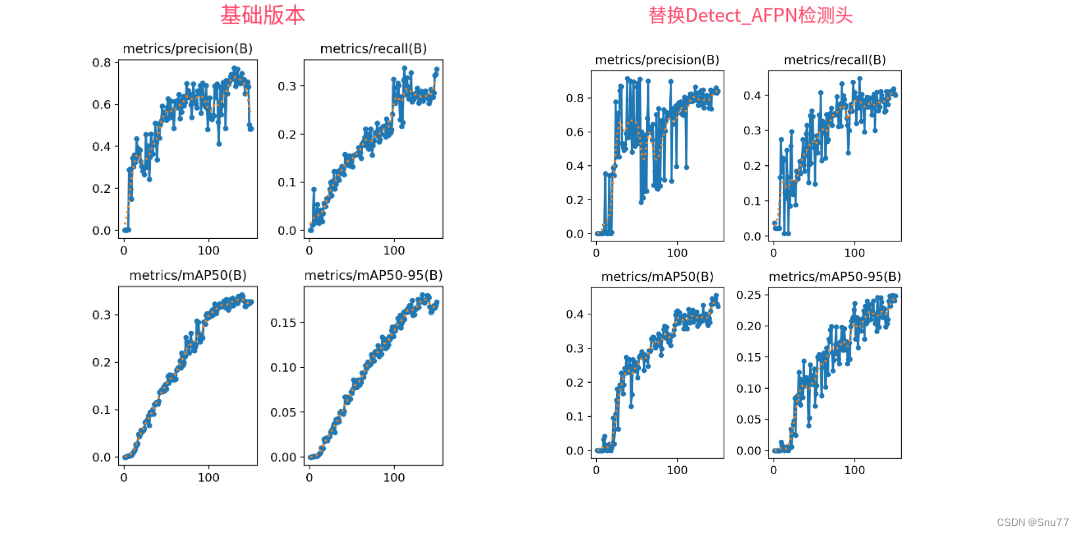
訓練結果對比圖->??
這次試驗我用的數據集大概有七八百張照片訓練了150個epochs,雖然沒有完全擬合但是效果有一定的漲點幅度,所以大家可以進行嘗試畢竟不同的數據集上效果也可能差很多,同時我在后面給了多種yaml文件大家可以分別進行實驗來檢驗效果。
目錄
一、本文介紹
二、AFPN基本框架原理?編輯
2.1 AFPN的基本原理
三、Detect_AFPN完整代碼
四、手把手教你添加Detect_AFPN檢測頭
4.1 修改一
4.2 修改二
4.3 修改三?
4.4 修改四?
4.5 修改五?
4.6 修改六?
4.7 修改七?
4.8 修改八
4.9 修改九?
五、Detect_AFPN檢測頭的yaml文件
六、完美運行記錄
七、本文總結
二、AFPN基本框架原理
論文地址:官方論文地址
代碼地址:官方代碼地址

2.1 AFPN的基本原理
AFPN的核心思想是通過引入一種漸近的特征融合策略,將底層、高層和頂層的特征逐漸整合到目標檢測過程中。這種漸近融合方式有助于減小不同層次特征之間的語義差距,提高特征融合效果,使得檢測模型能更好地適應不同層次的語義信息。
主要改進機制:
1. 底層特征融合:?AFPN通過引入底層特征的逐步融合,首先融合底層特征,接著深層特征,最后整合頂層特征。這種層級融合的方式有助于更好地利用不同層次的語義信息,提高檢測性能。
2. 自適應空間融合: 引入自適應空間融合機制(ASFF),在多級特征融合過程中引入變化的空間權重,加強關鍵級別的重要性,同時抑制來自不同對象的矛盾信息的影響。這有助于提高檢測性能,尤其在處理矛盾信息時更為有效。
3. 底層特征對齊: AFPN采用漸近融合的思想,使得不同層次的特征在融合過程中逐漸接近,減小它們之間的語義差距。通過底層特征的逐步整合,提高了特征融合的效果,使得模型更能理解和利用不同層次的信息。
個人總結:AFPN的靈感就像是搭積木一樣,它不是一下子把所有的積木都放到一起,而是逐步地將不同層次的積木慢慢整合在一起。這樣一來,我們可以更好地理解和利用每一層次的積木,從而構建一個更牢固的目標檢測系統。同時,引入了一種智能的機制,能夠根據不同情況調整注意力,更好地處理矛盾信息。

上面上AFPN的網絡結構,可以看出從Backbone中提取出特征之后,將特征輸入到AFPN中進行處理,然后它可以獲得不同層級的特征進行融合,這也是它的主要思想質疑,同時將結果輸入到檢測頭中進行預測。
(需要注意的是本文砍掉了最下面那一條線適應YOLOv8因為我們是三個檢測頭,下一篇文章我會出增加小目標檢測頭的然后四個頭的yolov8改進,從而適應AFPN的結構)。?
三、Detect_AFPN完整代碼
這里代碼是我對于2023年新提出的AFPN進行了修改然后適配YOLOv8的整體結構提出的檢測頭,本來該結構是四個檢測頭部分,但是我去除掉了一個從而適配yolov8,當然在我也在出一篇文章里會用到四頭的(增加輔助訓練頭,針對小目標檢測)講解(要不然一個博客放不下 這么多代碼)。
import math
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
from ultralytics.nn.modules import DFL
from ultralytics.nn.modules.conv import Conv
from ultralytics.utils.tal import dist2bbox, make_anchors__all__ =['Detect_AFPN']def BasicConv(filter_in, filter_out, kernel_size, stride=1, pad=None):if not pad:pad = (kernel_size - 1) // 2 if kernel_size else 0else:pad = padreturn nn.Sequential(OrderedDict([("conv", nn.Conv2d(filter_in, filter_out, kernel_size=kernel_size, stride=stride, padding=pad, bias=False)),("bn", nn.BatchNorm2d(filter_out)),("relu", nn.ReLU(inplace=True)),]))class BasicBlock(nn.Module):expansion = 1def __init__(self, filter_in, filter_out):super(BasicBlock, self).__init__()self.conv1 = nn.Conv2d(filter_in, filter_out, 3, padding=1)self.bn1 = nn.BatchNorm2d(filter_out, momentum=0.1)self.relu = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(filter_out, filter_out, 3, padding=1)self.bn2 = nn.BatchNorm2d(filter_out, momentum=0.1)def forward(self, x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out += residualout = self.relu(out)return outclass Upsample(nn.Module):def __init__(self, in_channels, out_channels, scale_factor=2):super(Upsample, self).__init__()self.upsample = nn.Sequential(BasicConv(in_channels, out_channels, 1),nn.Upsample(scale_factor=scale_factor, mode='bilinear'))def forward(self, x):x = self.upsample(x)return xclass Downsample_x2(nn.Module):def __init__(self, in_channels, out_channels):super(Downsample_x2, self).__init__()self.downsample = nn.Sequential(BasicConv(in_channels, out_channels, 2, 2, 0))def forward(self, x, ):x = self.downsample(x)return xclass Downsample_x4(nn.Module):def __init__(self, in_channels, out_channels):super(Downsample_x4, self).__init__()self.downsample = nn.Sequential(BasicConv(in_channels, out_channels, 4, 4, 0))def forward(self, x, ):x = self.downsample(x)return xclass Downsample_x8(nn.Module):def __init__(self, in_channels, out_channels):super(Downsample_x8, self).__init__()self.downsample = nn.Sequential(BasicConv(in_channels, out_channels, 8, 8, 0))def forward(self, x, ):x = self.downsample(x)return xclass ASFF_2(nn.Module):def __init__(self, inter_dim=512):super(ASFF_2, self).__init__()self.inter_dim = inter_dimcompress_c = 8self.weight_level_1 = BasicConv(self.inter_dim, compress_c, 1, 1)self.weight_level_2 = BasicConv(self.inter_dim, compress_c, 1, 1)self.weight_levels = nn.Conv2d(compress_c * 2, 2, kernel_size=1, stride=1, padding=0)self.conv = BasicConv(self.inter_dim, self.inter_dim, 3, 1)def forward(self, input1, input2):level_1_weight_v = self.weight_level_1(input1)level_2_weight_v = self.weight_level_2(input2)levels_weight_v = torch.cat((level_1_weight_v, level_2_weight_v), 1)levels_weight = self.weight_levels(levels_weight_v)levels_weight = F.softmax(levels_weight, dim=1)fused_out_reduced = input1 * levels_weight[:, 0:1, :, :] + \input2 * levels_weight[:, 1:2, :, :]out = self.conv(fused_out_reduced)return outclass ASFF_3(nn.Module):def __init__(self, inter_dim=512):super(ASFF_3, self).__init__()self.inter_dim = inter_dimcompress_c = 8self.weight_level_1 = BasicConv(self.inter_dim, compress_c, 1, 1)self.weight_level_2 = BasicConv(self.inter_dim, compress_c, 1, 1)self.weight_level_3 = BasicConv(self.inter_dim, compress_c, 1, 1)self.weight_levels = nn.Conv2d(compress_c * 3, 3, kernel_size=1, stride=1, padding=0)self.conv = BasicConv(self.inter_dim, self.inter_dim, 3, 1)def forward(self, input1, input2, input3):level_1_weight_v = self.weight_level_1(input1)level_2_weight_v = self.weight_level_2(input2)level_3_weight_v = self.weight_level_3(input3)levels_weight_v = torch.cat((level_1_weight_v, level_2_weight_v, level_3_weight_v), 1)levels_weight = self.weight_levels(levels_weight_v)levels_weight = F.softmax(levels_weight, dim=1)fused_out_reduced = input1 * levels_weight[:, 0:1, :, :] + \input2 * levels_weight[:, 1:2, :, :] + \input3 * levels_weight[:, 2:, :, :]out = self.conv(fused_out_reduced)return outclass ASFF_4(nn.Module):def __init__(self, inter_dim=512):super(ASFF_4, self).__init__()self.inter_dim = inter_dimcompress_c = 8self.weight_level_0 = BasicConv(self.inter_dim, compress_c, 1, 1)self.weight_level_1 = BasicConv(self.inter_dim, compress_c, 1, 1)self.weight_level_2 = BasicConv(self.inter_dim, compress_c, 1, 1)self.weight_levels = nn.Conv2d(compress_c * 3, 3, kernel_size=1, stride=1, padding=0)self.conv = BasicConv(self.inter_dim, self.inter_dim, 3, 1)def forward(self, input0, input1, input2):level_0_weight_v = self.weight_level_0(input0)level_1_weight_v = self.weight_level_1(input1)level_2_weight_v = self.weight_level_2(input2)levels_weight_v = torch.cat((level_0_weight_v, level_1_weight_v, level_2_weight_v), 1)levels_weight = self.weight_levels(levels_weight_v)levels_weight = F.softmax(levels_weight, dim=1)fused_out_reduced = input0 * levels_weight[:, 0:1, :, :] + \input1 * levels_weight[:, 1:2, :, :] + \input2 * levels_weight[:, 2:3, :, :]out = self.conv(fused_out_reduced)return outclass BlockBody(nn.Module):def __init__(self, channels=[64, 128, 256, 512]):super(BlockBody, self).__init__()self.blocks_scalezero1 = nn.Sequential(BasicConv(channels[0], channels[0], 1),)self.blocks_scaleone1 = nn.Sequential(BasicConv(channels[1], channels[1], 1),)self.blocks_scaletwo1 = nn.Sequential(BasicConv(channels[2], channels[2], 1),)self.downsample_scalezero1_2 = Downsample_x2(channels[0], channels[1])self.upsample_scaleone1_2 = Upsample(channels[1], channels[0], scale_factor=2)self.asff_scalezero1 = ASFF_2(inter_dim=channels[0])self.asff_scaleone1 = ASFF_2(inter_dim=channels[1])self.blocks_scalezero2 = nn.Sequential(BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),)self.blocks_scaleone2 = nn.Sequential(BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),)self.downsample_scalezero2_2 = Downsample_x2(channels[0], channels[1])self.downsample_scalezero2_4 = Downsample_x4(channels[0], channels[2])self.downsample_scaleone2_2 = Downsample_x2(channels[1], channels[2])self.upsample_scaleone2_2 = Upsample(channels[1], channels[0], scale_factor=2)self.upsample_scaletwo2_2 = Upsample(channels[2], channels[1], scale_factor=2)self.upsample_scaletwo2_4 = Upsample(channels[2], channels[0], scale_factor=4)self.asff_scalezero2 = ASFF_3(inter_dim=channels[0])self.asff_scaleone2 = ASFF_3(inter_dim=channels[1])self.asff_scaletwo2 = ASFF_3(inter_dim=channels[2])self.blocks_scalezero3 = nn.Sequential(BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),)self.blocks_scaleone3 = nn.Sequential(BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),)self.blocks_scaletwo3 = nn.Sequential(BasicBlock(channels[2], channels[2]),BasicBlock(channels[2], channels[2]),BasicBlock(channels[2], channels[2]),BasicBlock(channels[2], channels[2]),)self.downsample_scalezero3_2 = Downsample_x2(channels[0], channels[1])self.downsample_scalezero3_4 = Downsample_x4(channels[0], channels[2])self.upsample_scaleone3_2 = Upsample(channels[1], channels[0], scale_factor=2)self.downsample_scaleone3_2 = Downsample_x2(channels[1], channels[2])self.upsample_scaletwo3_4 = Upsample(channels[2], channels[0], scale_factor=4)self.upsample_scaletwo3_2 = Upsample(channels[2], channels[1], scale_factor=2)self.asff_scalezero3 = ASFF_4(inter_dim=channels[0])self.asff_scaleone3 = ASFF_4(inter_dim=channels[1])self.asff_scaletwo3 = ASFF_4(inter_dim=channels[2])self.blocks_scalezero4 = nn.Sequential(BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),BasicBlock(channels[0], channels[0]),)self.blocks_scaleone4 = nn.Sequential(BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),BasicBlock(channels[1], channels[1]),)self.blocks_scaletwo4 = nn.Sequential(BasicBlock(channels[2], channels[2]),BasicBlock(channels[2], channels[2]),BasicBlock(channels[2], channels[2]),BasicBlock(channels[2], channels[2]),)def forward(self, x):x0, x1, x2 = xx0 = self.blocks_scalezero1(x0)x1 = self.blocks_scaleone1(x1)x2 = self.blocks_scaletwo1(x2)scalezero = self.asff_scalezero1(x0, self.upsample_scaleone1_2(x1))scaleone = self.asff_scaleone1(self.downsample_scalezero1_2(x0), x1)x0 = self.blocks_scalezero2(scalezero)x1 = self.blocks_scaleone2(scaleone)scalezero = self.asff_scalezero2(x0, self.upsample_scaleone2_2(x1), self.upsample_scaletwo2_4(x2))scaleone = self.asff_scaleone2(self.downsample_scalezero2_2(x0), x1, self.upsample_scaletwo2_2(x2))scaletwo = self.asff_scaletwo2(self.downsample_scalezero2_4(x0), self.downsample_scaleone2_2(x1), x2)x0 = self.blocks_scalezero3(scalezero)x1 = self.blocks_scaleone3(scaleone)x2 = self.blocks_scaletwo3(scaletwo)scalezero = self.asff_scalezero3(x0, self.upsample_scaleone3_2(x1), self.upsample_scaletwo3_4(x2))scaleone = self.asff_scaleone3(self.downsample_scalezero3_2(x0), x1, self.upsample_scaletwo3_2(x2))scaletwo = self.asff_scaletwo3(self.downsample_scalezero3_4(x0), self.downsample_scaleone3_2(x1), x2)scalezero = self.blocks_scalezero4(scalezero)scaleone = self.blocks_scaleone4(scaleone)scaletwo = self.blocks_scaletwo4(scaletwo)return scalezero, scaleone, scaletwoclass AFPN(nn.Module):def __init__(self,in_channels=[256, 512, 1024, 2048],out_channels=128):super(AFPN, self).__init__()self.fp16_enabled = Falseself.conv0 = BasicConv(in_channels[0], in_channels[0] // 8, 1)self.conv1 = BasicConv(in_channels[1], in_channels[1] // 8, 1)self.conv2 = BasicConv(in_channels[2], in_channels[2] // 8, 1)# self.conv3 = BasicConv(in_channels[3], in_channels[3] // 8, 1)self.body = nn.Sequential(BlockBody([in_channels[0] // 8, in_channels[1] // 8, in_channels[2] // 8]))self.conv00 = BasicConv(in_channels[0] // 8, out_channels, 1)self.conv11 = BasicConv(in_channels[1] // 8, out_channels, 1)self.conv22 = BasicConv(in_channels[2] // 8, out_channels, 1)# self.conv33 = BasicConv(in_channels[3] // 8, out_channels, 1)# init weightfor m in self.modules():if isinstance(m, nn.Conv2d):nn.init.xavier_normal_(m.weight, gain=0.02)elif isinstance(m, nn.BatchNorm2d):torch.nn.init.normal_(m.weight.data, 1.0, 0.02)torch.nn.init.constant_(m.bias.data, 0.0)def forward(self, x):x0, x1, x2 = xx0 = self.conv0(x0)x1 = self.conv1(x1)x2 = self.conv2(x2)# x3 = self.conv3(x3)out0, out1, out2 = self.body([x0, x1, x2])out0 = self.conv00(out0)out1 = self.conv11(out1)out2 = self.conv22(out2)return out0, out1, out2class Detect_AFPN(nn.Module):"""YOLOv8 Detect head for detection models."""dynamic = False # force grid reconstructionexport = False # export modeshape = Noneanchors = torch.empty(0) # initstrides = torch.empty(0) # initdef __init__(self, nc=80, channel=256, ch=()):"""Initializes the YOLOv8 detection layer with specified number of classes and channels."""super().__init__()self.nc = nc # number of classesself.nl = len(ch) # number of detection layersself.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x)self.no = nc + self.reg_max * 4 # number of outputs per anchorself.stride = torch.zeros(self.nl) # strides computed during buildc2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], min(self.nc, 100)) # channelsself.cv2 = nn.ModuleList(nn.Sequential(Conv(channel, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch)self.cv3 = nn.ModuleList(nn.Sequential(Conv(channel, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()self.AFPN = AFPN(ch, channel)def forward(self, x):"""Concatenates and returns predicted bounding boxes and class probabilities."""x = list(self.AFPN(x))shape = x[0].shape # BCHWfor i in range(self.nl):x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)if self.training:return xelif self.dynamic or self.shape != shape:self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))self.shape = shapex_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)if self.export and self.format in ('saved_model', 'pb', 'tflite', 'edgetpu', 'tfjs'): # avoid TF FlexSplitV opsbox = x_cat[:, :self.reg_max * 4]cls = x_cat[:, self.reg_max * 4:]else:box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.stridesif self.export and self.format in ('tflite', 'edgetpu'):# Normalize xywh with image size to mitigate quantization error of TFLite integer models as done in YOLOv5:# https://github.com/ultralytics/yolov5/blob/0c8de3fca4a702f8ff5c435e67f378d1fce70243/models/tf.py#L307-L309# See this PR for details: https://github.com/ultralytics/ultralytics/pull/1695img_h = shape[2] * self.stride[0]img_w = shape[3] * self.stride[0]img_size = torch.tensor([img_w, img_h, img_w, img_h], device=dbox.device).reshape(1, 4, 1)dbox /= img_sizey = torch.cat((dbox, cls.sigmoid()), 1)return y if self.export else (y, x)def bias_init(self):"""Initialize Detect() biases, WARNING: requires stride availability."""m = self # self.model[-1] # Detect() module# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # nominal class frequencyfor a, b, s in zip(m.cv2, m.cv3, m.stride): # froma[-1].bias.data[:] = 1.0 # boxb[-1].bias.data[:m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)
四、手把手教你添加Detect_AFPN檢測頭
這里教大家添加檢測頭,檢測頭的添加相對于其它機制來說比較復雜一點,修改的地方比較多。
具體更多細節可以看我的添加教程博客,下面的教程也是完美運行的,看那個都行具體大家選擇。
添加教程->YOLOv8改進 | 如何在網絡結構中添加注意力機制、C2f、卷積、Neck、檢測頭?
4.1 修改一
首先我們將上面的代碼復制粘貼到'ultralytics/nn/modules' 目錄下新建一個py文件復制粘貼進去,具體名字自己來定,我這里起名為AFPN.py。
 ?
?
4.2 修改二
我們新建完上面的文件之后,找到如下的文件'ultralytics/nn/tasks.py'。這里需要修改的地方有點多,總共有7處,但都很簡單。首先我們在該文件的頭部導入我們AFPN文件中的檢測頭。
 ?
?
4.3 修改三?
找到如下的代碼進行將檢測頭添加進去,這里給大家推薦個快速搜索的方法用ctrl+f然后搜索Detect然后就能快速查找了。
 ?
?
4.4 修改四?
同理將我們的檢測頭添加到如下的代碼里。
 ?
?
4.5 修改五?
同理
 ?
?
4.6 修改六?
同理
 ?
?
4.7 修改七?
同理
 ?
?
4.8 修改八
這里有一些不一樣,我們需要加一行代碼
else:return 'detect'為啥呢不一樣,因為這里的m在代碼執行過程中會將你的代碼自動轉換為小寫,所以直接else方便一點,以后出現一些其它分割或者其它的教程的時候在提供其它的修改教程。?
 ?
?
4.9 修改九?
這里也有一些不一樣,需要自己手動添加一個括號,提醒一下大家不要直接添加,和我下面保持一致。
 ?
?
五、Detect_AFPN檢測頭的yaml文件
這個代碼的yaml文件和正常的對比也需要修改一下,如下->
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect_AFPN, [nc, 256]] # Detect(P3, P4, P5)
六、完美運行記錄
最后提供一下完美運行的圖片。
 ?
?
七、本文總結
到此本文的正式分享內容就結束了,在這里給大家推薦我的YOLOv8改進有效漲點專欄,本專欄目前為新開的平均質量分98分,后期我會根據各種最新的前沿頂會進行論文復現,也會對一些老的改進機制進行補充,目前本專欄免費閱讀(暫時,大家盡早關注不迷路~),如果大家覺得本文幫助到你了,訂閱本專欄,關注后續更多的更新~
專欄回顧:YOLOv8改進系列專欄——本專欄持續復習各種頂會內容——科研必備
 ?
?



補充--內核頁表及內核虛擬空間)


燈光、陰影、霧以及多Pass(源碼))

![[ffmpeg] AVFrame 功能整理](http://pic.xiahunao.cn/[ffmpeg] AVFrame 功能整理)





適配器模式)
 動態規劃思想)



)