文章目錄
- 1 滿秩分解(Full-Rank Factorization)
- 2 三角分解(Triangular Factorization)
- 3 正交三角分解(QR Factorization)
- 4 奇異值分解(SVD)
1 滿秩分解(Full-Rank Factorization)
-
滿秩分解定理
設 m × n m\times n m×n矩陣 A A A的秩為 r > 0 r>0 r>0,則存在 m × r m\times r m×r矩陣 B B B(列滿秩矩陣)和 r × n r\times n r×n矩陣 C C C(行滿秩矩陣)使得
A = B C A=BC A=BC
并且 r a n k ( B ) = r a n k ( C ) = r rank(B)=rank(C)=r rank(B)=rank(C)=r滿秩分解不唯一
定理:設 A A A為 m × n m\times n m×n矩陣,且 r a n k ( A ) = r rank(A)=r rank(A)=r,存在 m m m階可逆矩陣 P P P和 n n n階可逆矩陣 Q Q Q,使得 A = P [ I r 0 0 0 ] Q A=P\begin{bmatrix}I_r & 0 \\ 0 & 0\end{bmatrix}Q A=P[Ir?0?00?]Q。
證明滿秩分解定理:
∵ [ I r 0 0 0 ] = [ I r 0 ] [ I r 0 ] \because \begin{bmatrix}I_r & 0 \\ 0 & 0\end{bmatrix}=\begin{bmatrix}I_r \\ 0\end{bmatrix}\begin{bmatrix}I_r & 0\end{bmatrix} ∵[Ir?0?00?]=[Ir?0?][Ir??0?]
∴ A = P [ I r 0 ] [ I r 0 ] Q \therefore A=P\begin{bmatrix}I_r \\ 0\end{bmatrix}\begin{bmatrix}I_r & 0\end{bmatrix}Q ∴A=P[Ir?0?][Ir??0?]Q
則令 P [ I r 0 ] = B P\begin{bmatrix}I_r \\ 0\end{bmatrix}=B P[Ir?0?]=B, [ I r 0 ] Q = C \begin{bmatrix}I_r & 0\end{bmatrix}Q=C [Ir??0?]Q=C,可得到 A = B C A=BC A=BC
∵ \because ∵ P , C P,C P,C是可逆矩陣, B B B的 r r r個列是 P P P的前 r r r列; C C C的 r r r個行是 Q Q Q的前 r r r行
∴ \therefore ∴ r a n k ( B ) = r a n k ( C ) = r rank(B)=rank(C)=r rank(B)=rank(C)=r
-
滿秩分解步驟
- 設 A A A為 m × n m\times n m×n矩陣,首先求 r a n k ( A ) rank(A) rank(A)
- 取 A A A的 j 1 , j 2 , . . . j r j_1,j_2,...j_r j1?,j2?,...jr?列構成 B m × r B_{m\times r} Bm×r?
- 取 A A A的
Hermite標準型(即行最簡行矩陣) H H H的前 r r r行構成矩陣 C r × n C_{r\times n} Cr×n? - 則 A = B C A=BC A=BC就是矩陣 A A A的一個滿秩分解
-
Python求解滿秩分解import numpy as np from sympy import Matrix''' Full-Rank Factorization @params: A Matrix @return: F, G Matrix ''' def full_rank(A):r = A.rank()A_arr1 = np.array(A.tolist())# 求解A的最簡行階梯矩陣,要轉換成list,再轉換成arrayA_rref = np.array(A.rref()[0].tolist())k = [] # 存儲被選中的列向量的下標# 遍歷A_rref的行for i in range(A_rref.shape[0]):# 遍歷A_rref的列for j in range(A_rref.shape[1]):# 遇到1就說明找到了A矩陣的列向量的下標# 這些下標的列向量組成F矩陣,然后再找下一行if A_rref[i][j] == 1:k.append(j)break# 通過選中的列下標,構建F矩陣 B = Matrix(A_arr1[:,k])# G就是取行最簡行矩陣A的前r行構成的矩陣C = Matrix(A_rref[:r])return B, Cif __name__ == "__main__":# 表示矩陣AA = np.array([[1, 1, 0], [0, 1, 1], [-1, 0, 0], [1, 1, 1]])A = Matrix(A)B, C = full_rank(A)print("B:", B)print("C:", C)
2 三角分解(Triangular Factorization)
-
L U LU LU分解定義
如果有一個矩陣 A A A,我們能表示下三角矩陣 L L L和上三角矩陣 U U U的乘積,稱為 A A A的三角分解或 L U LU LU分解。
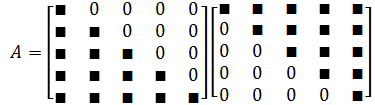
更進一步,我們希望下三角矩陣的對角元素都為 1 1 1
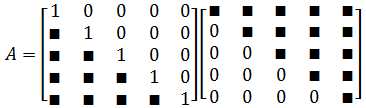
-
L U LU LU分解定理
若 A A A是== n n n階非奇異矩陣==,則存在唯一的單位下三角矩陣 L L L和上三角矩陣 U U U使得 A = L U A=LU A=LU的充分必要條件是 A A A的所有順序主子式均非零(這一條件保證了對角線元素非零),即 Δ k ≠ 0 ( k = 1 , . . . , n ? 1 ) \Delta_k\neq 0(k=1,...,n-1) Δk?=0(k=1,...,n?1)
-
L U LU LU分解步驟
設 A A A為 n × n n\times n n×n矩陣
- 進行初等行變換(注意:不涉及行交換的初等變換),從第 1 1 1行開始,到第 n n n行結束。將第 i i i行第 i i i列以下的元素全部消為 0 0 0
- 這樣操作后得到的矩陣即為 U U U
- 構造對角線元素全為 1 1 1的單位下三角矩陣 L L L, L L L的剩余元素通過構建方程組的形式來求解。
-
Python求解 L U LU LU分解 -
L U LU LU分解的實際意義
-
解線性方程組
假設我們有一個線性方程組 A x = b Ax=b Ax=b,其中 A A A是一個非奇異矩陣,而 b b b是一個列向量。通過 L U LU LU分解,我們可以將方程組轉化為兩個簡化的方程組 L y = b Ly=b Ly=b和 U x = y Ux=y Ux=y,其中 L L L是下三角矩陣, U U U是上三角矩陣。這兩個方程組分別易于求解。
具體:
首先,通過前代法(forward substitution)解 L y = b Ly=b Ly=b,然后通過回代法(backward substitution)解 U x = y Ux=y Ux=y。這樣,我們就得到了方程組的解。
-
-
L D U LDU LDU分解定理
設 A A A是== n n n階非奇異矩陣==,則存在唯一的單位下三角矩陣 L L L,對角矩陣 D = d i a g ( d 1 , d 2 , . . . , d n ) D=diag(d_1,d_2,...,d_n) D=diag(d1?,d2?,...,dn?)和上三角矩陣 U U U使得 A = L D U A=LDU A=LDU的充分必要條件是 A A A的所有順序主子式均非零(這一條件保證了對角線元素非零),即 Δ k ≠ 0 ( k = 1 , . . . , n ? 1 ) \Delta_k\neq 0(k=1,...,n-1) Δk?=0(k=1,...,n?1)并且 d 1 = a 11 , d k = Δ k Δ k + 1 , k = 2 , . . . , n d_1=a_{11},d_k=\frac{\Delta _k}{\Delta_{k+1}},k=2,...,n d1?=a11?,dk?=Δk+1?Δk??,k=2,...,n
-
L D U LDU LDU分解步驟
設 A A A為 n × n n\times n n×n矩陣
- 先求 L U LU LU分解
- 將 U U U的對角線元素提出來構成對角矩陣 D D D
- U U U中的元素 u i j u_{ij} uij?除以 d i d_i di?,其中 d i d_i di?表示第 i i i個對角元素。這樣操作得到變換后的 U U U
-
Python求解 L D U LDU LDU分解import numpy as np from sympy import Matrix import pprintEPSILON = 1e-8def is_zero(x):return abs(x) < EPSILONdef LU(A):# 斷言A必須是非奇異方陣Aassert A.rows == A.cols, "Matrix A must be a square matrix"assert A.det() != 0, "Matrix A must be a nonsingular matrix"n = A.rowsU = A# 構建出U矩陣# 將U轉換成list,再轉換成arrayU = np.array(U.tolist())# 遍歷U的每一行利用高斯消元法for i in range(n):# 判斷U[i][i]是否為0assert not is_zero(U[i][i]), "主元為0,無法進行LU分解"# 對i+1行到n行進行消元for j in range(i + 1, n):# 計算消元因子factor = U[j][i] / U[i][i]# 對第j行進行消元for k in range(i, n):U[j][k] -= factor * U[i][k]# 消元后的矩陣U則是最終U矩陣U = Matrix(U)# 根據LU = A,得到L矩陣L = A * U.inv()return L, Udef LDU(A):L, U = LU(A)D = Matrix(np.diag(np.diag(U)))U = D.inv() * Ureturn L, D, Uif __name__ == '__main__':A = np.array([[2, 3, 4], [1, 1, 9], [1, 2, -6]])A = Matrix(A)'''# test LU分解L, U = LU(A)pprint.pprint("L:")pprint.pprint(L)pprint.pprint("U:")pprint.pprint(U)'''# test LDU分解L, D, U = LDU(A)pprint.pprint("L:")pprint.pprint(L)pprint.pprint("D:")pprint.pprint(D)pprint.pprint("U:")pprint.pprint(U) -
P L U PLU PLU分解
PLU 分解是將矩陣 A A A分解成一個置換矩陣 P P P、單位下三角矩陣 L L L和上三角矩陣 U U U的乘積,即
A = P L U A=PLU A=PLU
之前 L U LU LU分解中限制了行交換,如果不可避免的必須進行行互換,我們就需要進行 P L U PLU PLU分解。實際上只需要把 A = L U A = LU A=LU變成 P ? 1 A = P ? 1 P L U P^{-1}A = P^{-1}PLU P?1A=P?1PLU就可以了,實際上所有的 A = L U A = LU A=LU都可以寫成 P ? 1 A = L U P^{-1}A = LU P?1A=LU的形式,由于左乘置換矩陣 P ? 1 P^{-1} P?1是在交換行的順序,所以由 P ? 1 A = P ? 1 P L U P^{-1}A = P^{-1}PLU P?1A=P?1PLU推得適當的交換 A A A的行的順序,即可將 A A A 做 L U LU LU 分解。當 A A A沒有行互換時, P P P就是單位矩陣。
事實上,所有的方陣都可以寫成 P L U PLU PLU 分解的形式,事實上, P L U PLU PLU 分解有很高的數值穩定性,因此實用上是很好用的工具。
有時為了計算上的方便,會同時間換行與列的順序,此時會將 A A A 分解成
A = P L U Q A=PLUQ A=PLUQ
其中 P P P、 L L L、 U U U 同上, Q Q Q 是一個置換矩陣。
3 正交三角分解(QR Factorization)
-
Q R QR QR分解定理
設 A A A是 m × n m\times n m×n實(復)矩陣, m ≥ n m\ge n m≥n且其 n n n個列向量線性無關,則存在 m m m階正交(酉)矩陣 Q Q Q和 n 階 n階 n階非奇異實(復)上三角矩陣 R R R使得
A = Q [ R 0 ] A=Q\begin{bmatrix}R \\ 0\end{bmatrix} A=Q[R0?] -
Q R QR QR分解步驟
設 A A A為 3 × 3 3\times 3 3×3矩陣,即 A = ( α 1 , α 2 , α 3 ) A=(\alpha_1, \alpha_2,\alpha_3) A=(α1?,α2?,α3?)。則:
-
正交化: β 1 = α 1 \beta_1=\alpha_1 β1?=α1?, β 2 = α 2 ? k 21 β 1 \beta_2=\alpha_2-k_{21}\beta_1 β2?=α2??k21?β1?, β 3 = α 3 ? k 31 β 1 ? k 32 β 2 \beta_3=\alpha_3-k_{31}\beta_1-k_{32}\beta_2 β3?=α3??k31?β1??k32?β2?,其中 k 21 = < α 2 , β 1 > < β 1 , β 1 > k_{21}=\frac{<\alpha_2,\beta_1>}{<\beta_1,\beta_1>} k21?=<β1?,β1?><α2?,β1?>?, k 31 = < α 3 , β 1 > < β 1 , β 1 > k_{31}=\frac{<\alpha_3,\beta_1>}{<\beta_1,\beta_1>} k31?=<β1?,β1?><α3?,β1?>?, k 31 = < α 3 , β 2 > < β 2 , β 2 > k_{31}=\frac{<\alpha_3,\beta_2>}{<\beta_2,\beta_2>} k31?=<β2?,β2?><α3?,β2?>?。
-
單位化得到矩陣 Q Q Q: Q = ( β 1 ∣ ∣ β 1 ∣ ∣ , β 2 ∣ ∣ β 2 ∣ ∣ , β 3 ∣ ∣ β 3 ∣ ∣ ) Q=(\frac{\beta_1}{||\beta_1||},\frac{\beta_2}{||\beta_2||},\frac{\beta_3}{||\beta_3||}) Q=(∣∣β1?∣∣β1??,∣∣β2?∣∣β2??,∣∣β3?∣∣β3??)
-
計算得到矩陣 R R R:
( ∣ ∣ β 1 ∣ ∣ ∣ ∣ β 2 ∣ ∣ ∣ ∣ β 3 ∣ ∣ ) ( 1 k 21 k 31 1 k 32 1 ) = ( ∣ ∣ β 1 ∣ ∣ ∣ ∣ β 1 ∣ ∣ × k 21 ∣ ∣ β 1 ∣ ∣ × k 31 ∣ ∣ β 2 ∣ ∣ ∣ ∣ β 2 ∣ ∣ × k 32 ∣ ∣ β 3 ∣ ∣ ) \begin{pmatrix} ||\beta _1|| & & \\ & ||\beta _2|| & \\ & &||\beta _3|| \end{pmatrix}\begin{pmatrix} 1 & k_{21} & k_{31} \\ & 1 & k_{32} \\ & & 1 \end{pmatrix}=\begin{pmatrix} ||\beta _1|| & ||\beta _1||\times k_{21} & ||\beta _1||\times k_{31}\\ & ||\beta _2|| & ||\beta _2||\times k_{32}\\ & & ||\beta _3|| \end{pmatrix} ?∣∣β1?∣∣?∣∣β2?∣∣?∣∣β3?∣∣? ? ?1?k21?1?k31?k32?1? ?= ?∣∣β1?∣∣?∣∣β1?∣∣×k21?∣∣β2?∣∣?∣∣β1?∣∣×k31?∣∣β2?∣∣×k32?∣∣β3?∣∣? ? -
這樣, A = Q R A=QR A=QR
-
-
Python求解 Q R QR QR分解常規計算:
import numpy as np import sympy from sympy import Matrix from sympy import * import pprint#正交三角分解(QR) a = [[1, 1, -1],[-1, 1, 1],[1, 1, -1],[1, 1, 1]]# a = [[1,1,-1], # [1,0,0], # [0,1,0], # [0,0,1]] A_mat = Matrix(a)#α向量組成的矩陣A # A_gs= GramSchmidt(A_mat) A_arr = np.array(A_mat) L = [] for i in range(A_mat.shape[1]):L.append(A_mat[:,i]) #求Q A_gs = GramSchmidt(L)#α的施密特正交化得到β A_gs_norm = GramSchmidt(L,True)#β的單位化得到vA = []for i in range(A_mat.shape[1]):for j in range(A_mat.shape[0]):A.append(A_gs_norm[i][j])#把數排成一行A_arr = np.array(A) A_arr = A_arr.reshape((A_mat.shape[0],A_mat.shape[1]),order = 'F')#用reshape重新排列(‘F’為豎著寫) #得到最后的Q Q = Matrix(A_arr)#求RC = [] for i in range(A_mat.shape[1]):for j in range(A_mat.shape[1]):if i > j:C.append(0)elif i == j:t = np.array(A_gs[i])m = np.dot(t.T,t)C.append(sympy.sqrt(m[0][0]))else:t = np.array(A_mat[:,j])x = np.array(A_gs_norm[i])n = np.dot(t.T,x) # print(n)C.append(n[0][0]) # C_final為R C_arr = np.array(C) # print(C_arr) C_arr = C_arr.reshape((A_mat.shape[1],A_mat.shape[1])) R = Matrix(C_arr)pprint.pprint("Q:") pprint.pprint(Q) pprint.pprint("R:") pprint.pprint(R)調用庫函數
# 求矩陣A的QR分解,保留根號 Q_, R_ = A_mat.QRdecomposition() pprint.pprint("Q_:") pprint.pprint(Q_) pprint.pprint("R_:") pprint.pprint(R_) assert Q_ == Q, "Q_ != Q" assert R_ == R, "R_ != R"
4 奇異值分解(SVD)
-
S V D SVD SVD定理
設 A A A是 m × n m\times n m×n矩陣,且 r a n k ( A ) = r rank(A)=r rank(A)=r,則存在 m m m階酉矩陣 U U U和 n n n階酉矩陣 V V V使得
A = U [ Σ 0 0 0 ] V H A=U\begin{bmatrix}\Sigma & 0\\ 0 & 0 \end{bmatrix}V^H A=U[Σ0?00?]VH
其中 Σ = d i a g ( σ 1 , . . . , σ r ) \Sigma=diag(\sigma_1,...,\sigma_r) Σ=diag(σ1?,...,σr?),且 σ 1 ≥ . . . ≥ σ r > 0 \sigma_1\geq ...\geq \sigma_r>0 σ1?≥...≥σr?>0。σ \sigma σ為 A A A的奇異值,具體含義這里不在敘述,但需要記住的是 σ 2 \sigma^2 σ2是 A H A A^HA AHA的特征值,也是 A A H AA^H AAH的特征值,且:
- A H A A^HA AHA與 A A H AA^H AAH的特征值均為非負數
- A H A A^HA AHA與 A A H AA^H AAH的非零特征值相同,并且非零特征值的個數(重特征值按重數計算)等于 r a n k ( A ) rank(A) rank(A)
所以我們求 Σ \Sigma Σ就轉換成求這兩個矩陣其中一個的特征值。
-
S V D SVD SVD分解步驟
-
求 A H A A^HA AHA的 n n n個特征值,即計算 ∣ λ I ? A H A ∣ = 0 |\lambda I-A^HA|=0 ∣λI?AHA∣=0。得到特征值: λ 1 , . . . , λ r , λ r + 1 = 0 , . . . , λ n = 0 \lambda_1,...,\lambda_r,\lambda_{r+1}=0,...,\lambda_n=0 λ1?,...,λr?,λr+1?=0,...,λn?=0,其中 r = r a n k ( A ) r=rank(A) r=rank(A)。
-
將 r r r個奇異值(即非零特征值開根號)從大到小排列組成對角矩陣,再添加額外的 0 0 0構成 Σ m × n \Sigma_{m\times n} Σm×n?矩陣。
Σ m × n = ( λ 1 . . . 0 0 0 0 λ 2 0 0 0 . . . . . . . . . . . . . . . . . . . . . . . . λ r . . . 0 . . . 0 0 0 ) \Sigma_{m\times n}=\begin{pmatrix} \sqrt[]{\lambda _1} & ... & 0&0&0 \\ 0& \sqrt[]{ \lambda _2} & 0 &0&0\\ ...& ... & ... &...&...\\ ...& ... & ... &\sqrt[]{\lambda_r}&...\\ 0& ... & 0 &0&0 \end{pmatrix} Σm×n?= ?λ1??0......0?...λ2??.........?00......0?00...λr??0?00......0? ? -
求特征值: λ 1 , . . . , λ r , λ r + 1 = 0 , . . . , λ n = 0 \lambda_1,...,\lambda_r,\lambda_{r+1}=0,...,\lambda_n=0 λ1?,...,λr?,λr+1?=0,...,λn?=0對應的特征向量 ξ 1 , . . . , ξ n \xi_1,...,\xi_n ξ1?,...,ξn?:當 λ = λ 1 \lambda=\lambda_1 λ=λ1?時, ( λ I ? A H A ) × ξ 1 = 0 (\lambda I-A^HA)\times \xi_1=0 (λI?AHA)×ξ1?=0,解得 ξ 1 \xi_1 ξ1?,同理,計算其余特征向量。
-
因為 ξ 1 , . . . , ξ n \xi_1,...,\xi_n ξ1?,...,ξn?相互正交,我們還需要進行單位化,得到 v 1 , . . . , v n v_1,...,v_n v1?,...,vn?,即 v 1 = ξ 1 ∣ ∣ ξ 1 ∣ ∣ , . . . , v n = ξ n ∣ ∣ ξ n ∣ ∣ v_1=\frac{\xi_1}{||\xi_1||},...,v_n=\frac{\xi_n}{||\xi_n||} v1?=∣∣ξ1?∣∣ξ1??,...,vn?=∣∣ξn?∣∣ξn??。則 V = ( v 1 , . . . , v n ) V=(v_1,...,v_n) V=(v1?,...,vn?)。
-
根據 A = U m × m Σ m × n V n × n H A=U_{m\times m}\Sigma_{m\times n}V_{n\times n}^H A=Um×m?Σm×n?Vn×nH?,可得 U 1 = A V n × n Σ r × n ? 1 U_1=AV_{n\times n}\Sigma_{r\times n}^{-1} U1?=AVn×n?Σr×n?1?(注意, σ \sigma σ此時為 Σ m × n \Sigma_{m\times n} Σm×n?的前 r r r行),易知 U 1 U_1 U1?為 m × r m\times r m×r的矩陣,我們還需要擴充 U 2 U_2 U2?,其為 m × ( m ? r ) m\times (m-r) m×(m?r)矩陣。
-
取 U 1 H U 2 = 0 U_1^HU_2=0 U1H?U2?=0,取 U 2 U_2 U2?,必須要單位化 U 2 U_2 U2?,這樣 U = [ U 1 : U 2 ] U=[U_1:U_2] U=[U1?:U2?]
-
則 A = U m × m [ Σ 0 0 0 ] m × n V n × n H A=U_{m\times m}\begin{bmatrix}\Sigma & 0\\ 0 & 0 \end{bmatrix}_{m\times n}V_{n\times n}^H A=Um×m?[Σ0?00?]m×n?Vn×nH?
-
-
Python求解奇異值分解import numpy as np from sympy import Matrix import pprintA = np.array([[1,0],[0,1],[1,1]]) # 求A的奇異值分解 U, sigma, VT = np.linalg.svd(A) print ("U:", U) print ("sigma:", sigma) print ("VT:", VT)









)







:統一響應結果和全局異常處理)

