?
這個案例展示如何運用 MATLAB 中自帶的 Binning Explorer 小程序來創建信用評級中的評分卡。
用 Binning Explorer 對樣本進行分箱操作, 創建圖表來展示分箱信息,并將創建的對象”creditscorecard”導出。
然后利用 creditscorecard 對象,結合 Financial Toolbox? 中的函數來對邏輯回歸模型進行擬合, 為樣本進行評分并計算違約概率(PD),然后用三個不同的指標對評分卡模型進行驗證。
-
步驟1 將樣本數據導入到 MATLAB 的工作區
-
步驟2 將數據導入到 Binning Explorer 小程序
-
步驟3 在 Binning Explorer 中對分箱做進一步調整
-
步驟4 在 Binning Explorer 中將 creditscorecard 對象導出
-
步驟5 對邏輯回歸模型進行擬合
-
步驟6 檢查并調整評分卡分數的比例
-
步驟7 對樣本進行評分
-
步驟8 計算違約概率 PD
-
步驟9 用 CAP,ROC,KS 檢驗來對信用評分卡模型進行驗證
◆??◆??◆??◆
步驟1. 將樣本數據導入到 MATLAB 的工作區
將保存在 CreditCardData.mat 中的數據導入 MATLAB? 工作區 (使用 Refaat 2011 的數據). 運行代碼如下:
load CreditCardData
disp(data(1:10,:))
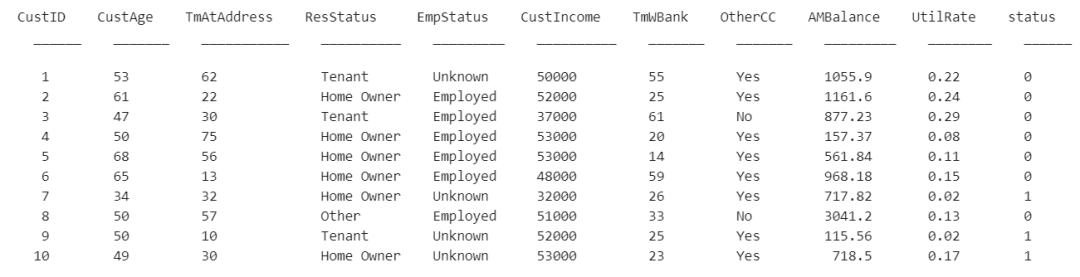
步驟2.?將數據導入到 Binning Explorer 小程序
方法一, 從 MATLAB 工具欄中打開?Binning Explorer?: 在?Apps 菜單下, 找到計算金融學(Computational Finance), 點擊 Binning Explorer 的圖標.?
方法二, 在 MATLAB 中運行如下命令行 .?
binningExplorer
(更多關于啟動 Binning Explorer 小程序的信息, 參見?Start from MATLAB Command Line Using Data or an Existing creditscorecard Object.)?(鏈接如下)
https://ww2.mathworks.cn/help/risk/common-binning-explorer-tasks.html#startbinningexplorercommandline
在?Binning Explorer?的工具欄,點擊?Import Data?按鈕來打開導入數據的窗口.
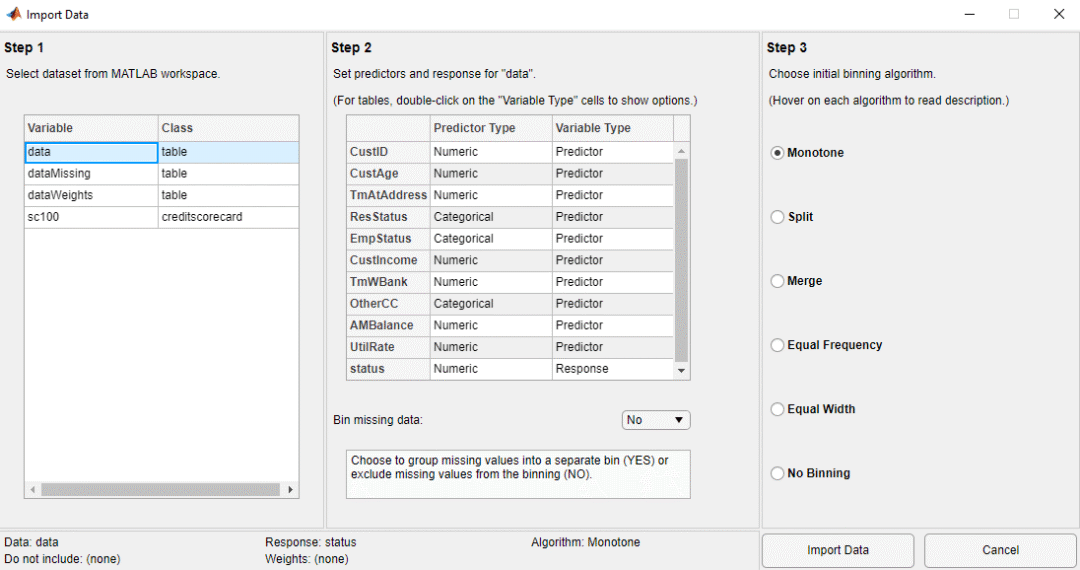
在?Step 1(第一步)下, 選擇 data 為需要導入的數據
在?Step 2(第二步)下, 可在?Variable Type?下為每個變量指定其類型. 缺省設置下,數據的最后一列(本例中為’status’)為‘Response’, 也就是因變量。因變量的值最好的樣本(本例中為“0“)被標記為'Good'. 所有其它的變量被歸為因變量。此外, 在這個例子中,'CustID'(客戶的編號)不是一個包含信息的因變量, 因此把?Variable Type?下面的'CustID' 對應設為?Do not include
| 注意?
如果導入的數據中有一列是各個因變量的權重,那么在?Step 2?的下面, 對應的?Variable Type?, 應在下拉菜單中選中?Weights.?關于在creditscorecard 對象中應用樣本的權重, 參見?Credit Scorecard Modeling Using Observation Weights?(鏈接如下). https://ww2.mathworks.cn/help/finance/credit-scorecard-using-weights.html |

如果原始數據中有部分數據缺失,那么在?Step 2?, 將?Bin missing data?設置為?Yes. 關于這部分的更詳盡信息,參見?Credit Scorecard Modeling with Missing Values (鏈接如下).
https://ww2.mathworks.cn/help/finance/credit-scorecard-modeling-with-missing-values.html
在?Step 3, 選擇?Monotone?作為缺省的初始化的分箱算法。
點擊?Import Data?完成這一導入數據的步驟。在數據導入的過程中,Binning Explorer?采用我們之前選中的算法自動的對應每個自變量對樣本進行分箱。
每個自變量對應的樣本分箱的結果都單獨以柱狀圖的形式顯示如下。點擊其中一個因變量,對應的分箱結果的詳細信息就會在左下角的?Bin Information?以及右下角的?Predictor Information?這兩個面板中顯示出來。
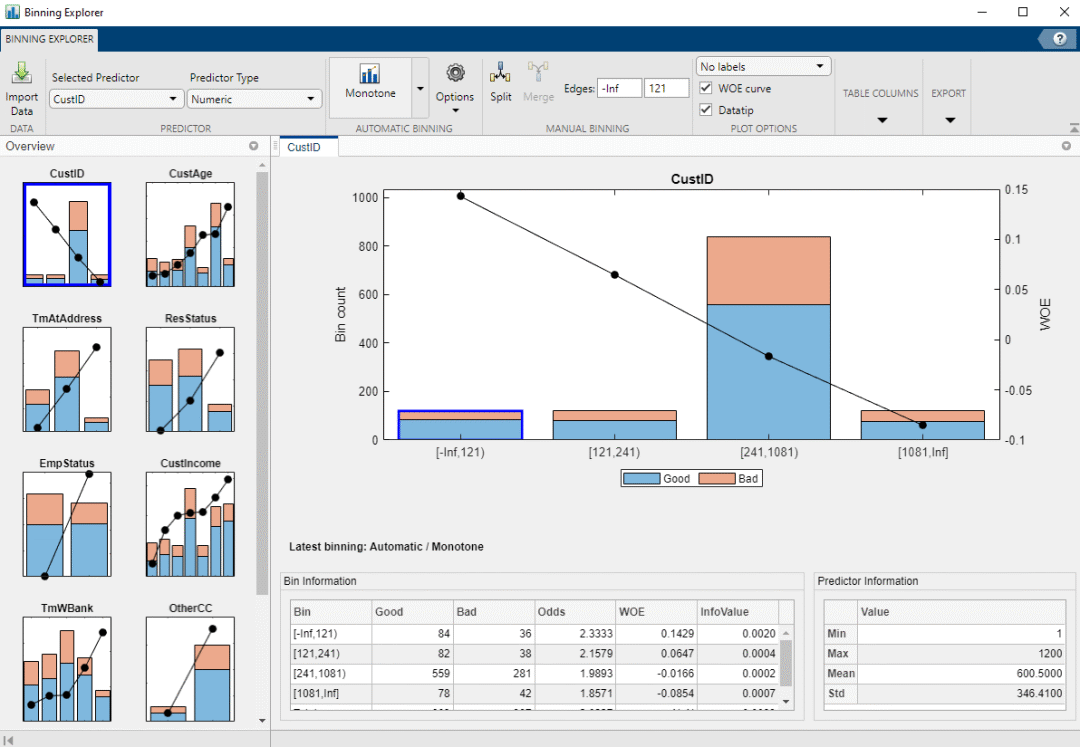
Binning Explorer?對應每個自變量,都對樣本自動進行分箱。采用的缺省算法是“Monotone”。該算法是針對信用評分卡最理想的算法,因為通過該算法得出的樣本數據的分箱結果,對應每個分箱的 WOE(Weight of Evidence)都是盡可能(完全或近似的)呈單調線性的趨勢(線性遞增或遞減)。在本例中各個自變量的分箱圖中可以看到 WOE 這一單調性的趨勢。
我們來看一下如何對數據進行一些初步的分析。以'ResStatus'(居住狀況)這個類別型變量(categorical variable)為例。
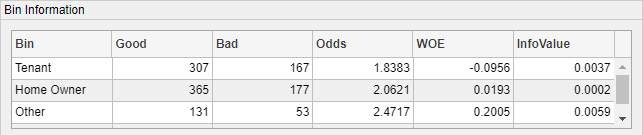
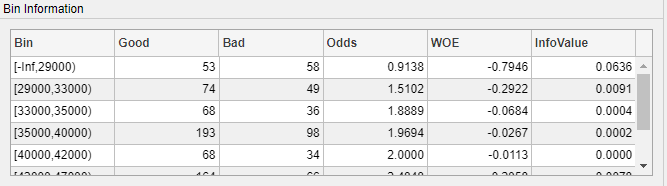
點擊?ResStatus?的分箱圖. 在?Bin Information?面板中包含了不同分箱(分組)的好樣本和壞樣本的數量和其他的分箱信息如 WOE。以“Tenant”這一分箱(樣本人的居住狀況為“租房”)為例:在租房居住的樣本中,307 個為好樣本(沒有發生過違約),167 個壞樣本(有違約記錄)好樣本與壞樣本之比(Odds)為1.8383。
對于數值型的變量, 以 CustIncome ?為例,點擊?CustIncome?的分箱圖。則?Bin Information?的面板中的數據更新為?CustIncome?的分箱信息。
步驟3.?對分箱結果進行手動調整
以?CustAge (客戶年齡)? 為例,點擊?CustAge?這個變量的分箱圖。注意第一組和第二組分箱(年齡為 33 歲以下,以及 33 到 37 歲)的 WOE 非常接近,第五組和第六組分箱也是類似情況. 我們認為這兩對相鄰的分組并沒有把樣本更好的區分開來,也就是說,這樣的分組并沒有給接下來的打分操作(以便區分好樣本和壞樣本)帶來可以明顯區分的信息。因此可以將這兩對分組分別合并。
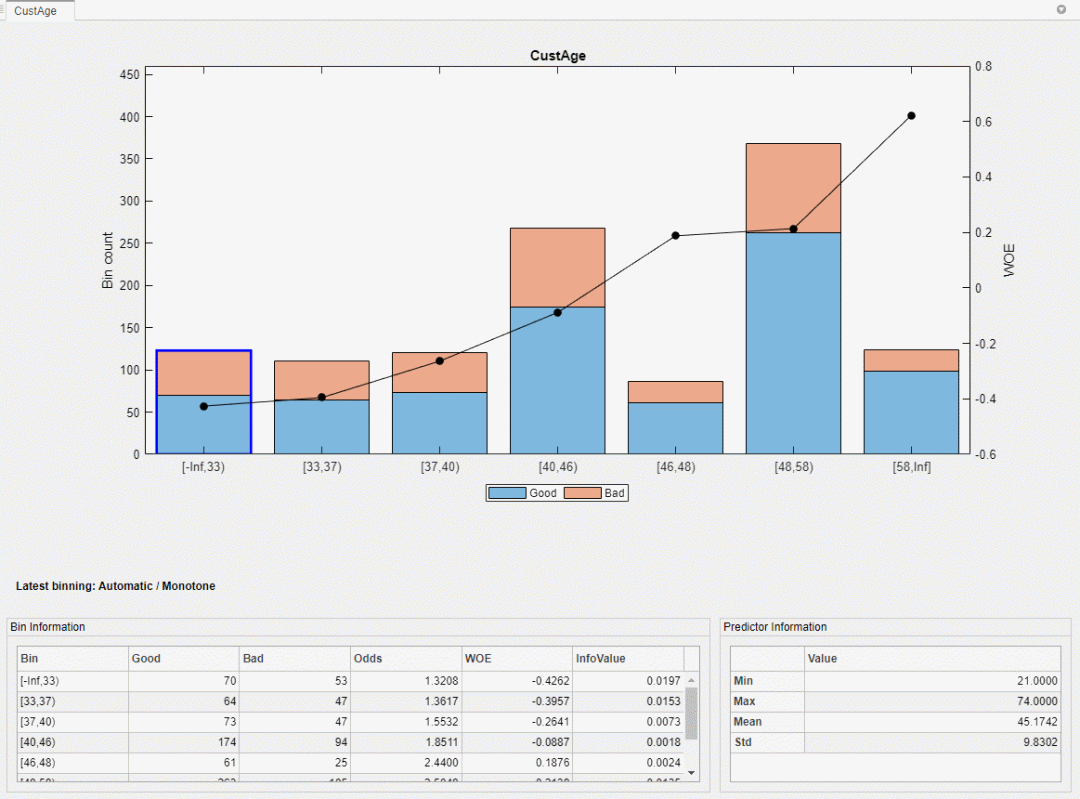
要合并第一組和第二組分箱,我們進行如下操作:
在?Binning Explorer?菜單下, 點擊?Manual Binning?可將當前選中的變量 CustAge 在一個新的窗口下打開(Manual Binning: CustAge). 您也可以直接用鼠標雙擊對應變量的圖來打開?Manual Binning?窗口. 用?Ctrl +?鼠標點擊來同時選中要合并的分箱 1 和 2,此時兩個分箱的柱狀圖會被藍色邊框圈起來。
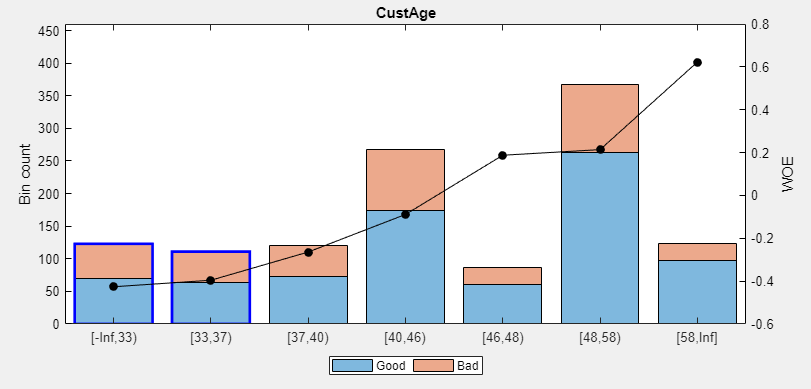
在?Manual Binning?菜單下,?Edges?右邊的兩個文本框顯示的是將要合并的兩個分箱所涵蓋的變量的取值的范圍,本例是從 0 到 37 歲(不含37歲)。
?
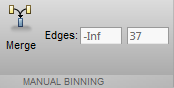
點擊?Merge?將前兩個分箱合并。此時在 Overview 窗口下面的?CustAge?的圖已經更新為了合并后的新的分箱的圖例,同時在?Bin Information?和?Predictor Information?面板下的數據也會相應更新。
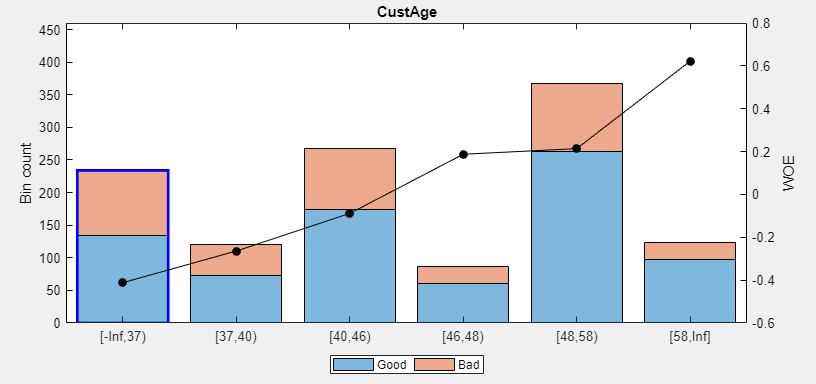
接下來,合并初始的第 4 和第 5 分箱(上面合并步驟后的第 3 和第 4 分箱,即 46~48 歲組和 48 到 58 歲組), 因為這兩組的 WOE 也非常接近.
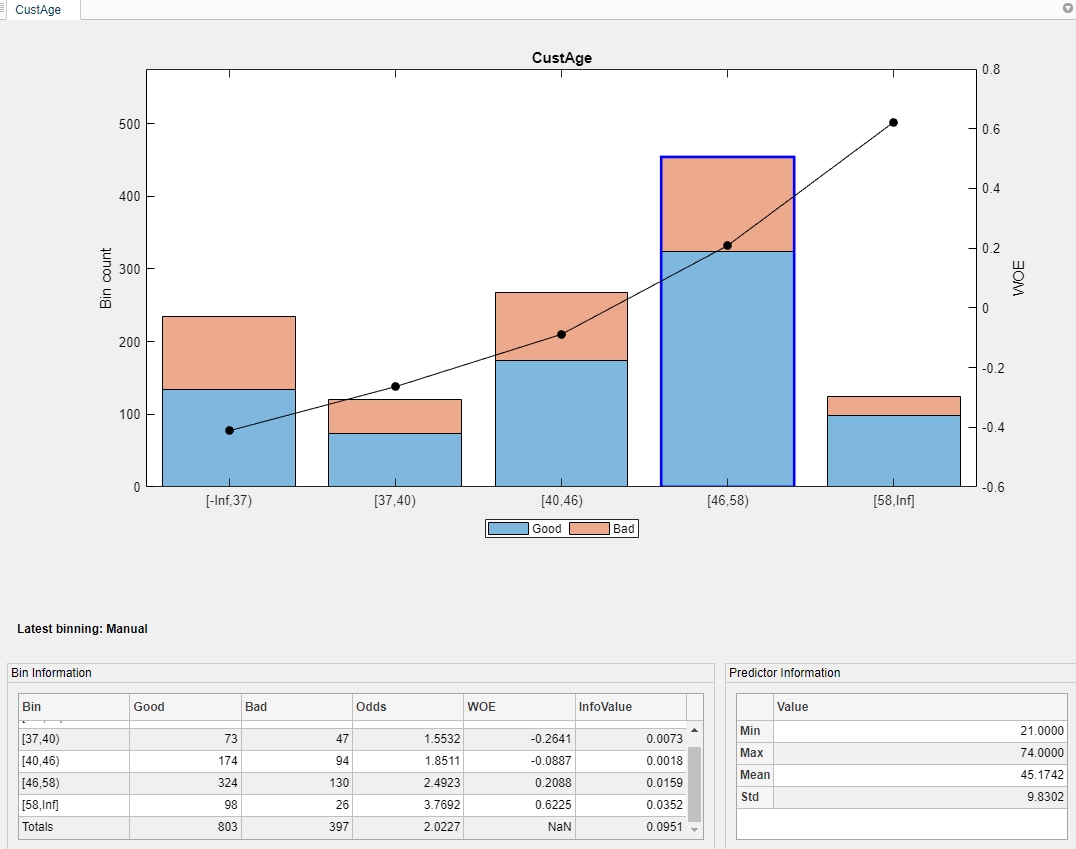
變量?CustAge?的分箱圖在前面兩個合并操作后已經更新為了新的信息。Bin Information?和?Predictor Information?這兩個面板的信息也同樣更新了。(注:?Predictor Information?在合并操作后沒有變化,是因為這兩次操作并沒有改變具體的樣本,因此沒有影響到該面板下的四個數據統計的信息)
對下面這些有接近的 WOE 的分箱進行類似的合并操作:
-
變量?CustIncome?(客戶的收入情況), 合并分箱 3、4 和5.
-
變量?TmWBank?(在該銀行的開戶時長), 合并分箱 2 和 3.
-
變量?AMBalance, (賬戶平均每月盈余),合并分箱 2 和 3.
現在所有變量的分箱顯示的 WOE 都為近似線性單調(遞增或遞減)的趨勢.
步驟4. 將 creditscorecard 對象從 Binning Explorer 導出到工作區
在完成所有分箱的操作之后,在?Binning Explorer?菜單下,點擊?Export Scorecard?然后給 creditscorecard 這個對象命名. 本例中將該對象命名為“sc”保存到工作區 .
步驟5. 進行邏輯回歸擬合
通過?fitmodel?函數來對WOE數據進行邏輯回歸的擬合.?(鏈接如下)
https://ww2.mathworks.cn/help/finance/creditscorecard.fitmodel.html
fitmodel 會對訓練集的數據樣本進行分箱,將其轉化成相應的 WOE 的值,并與相應因變量的值進行映射,(即好樣本對應的因變量值為1)然后做線性的邏輯回歸模型的擬合。缺省設置下,fitmodel 逐一將變量進行測試來決定是否將其納入模型中作為自變量. 代碼運行結果如下:
sc = fitmodel(sc);
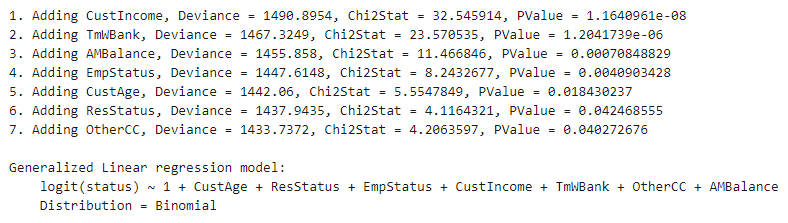
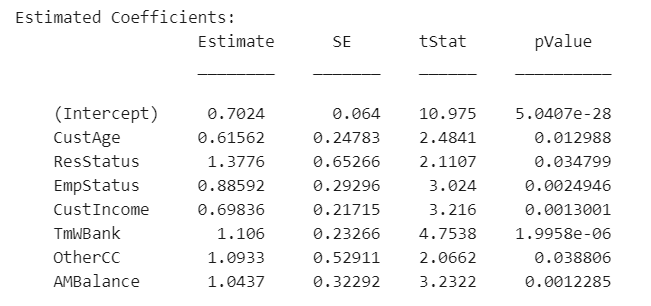
1200 observations, 1192 error degrees of freedom Dispersion: 1 Chi^2-statistic vs. constant model: 89.7, p-value = 1.42e-16
步驟6. 檢查并調整評分卡的分數
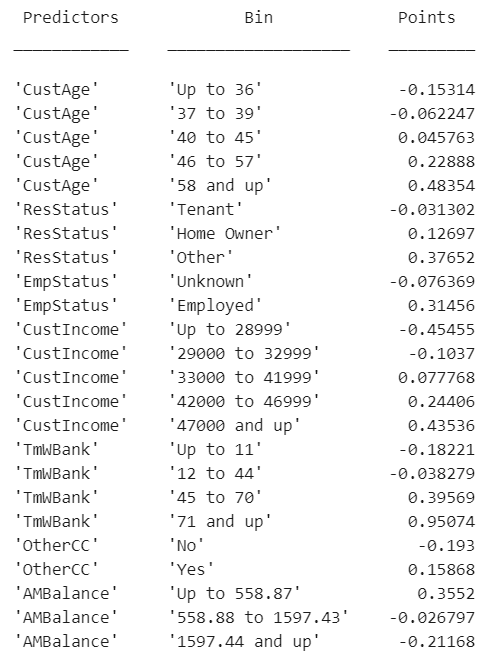
在進行模型擬合之后,各個變量的分箱對應評分卡的分數尚未按照比例進行調整,是直接以WOE 值和模型變量的系數的乘積得來的分數。用??displaypoints?函數可以看到評分卡上所有的分箱和對分數.?(鏈接如下)
https://ww2.mathworks.cn/help/finance/creditscorecard.displaypoints.html
代碼運行結果如下:
p1 = displaypoints(sc); disp(p1)

用?modifybins?函數來調整對變量的每個分箱的文字描述.?(鏈接如下)
https://ww2.mathworks.cn/help/finance/creditscorecard.modifybins.html

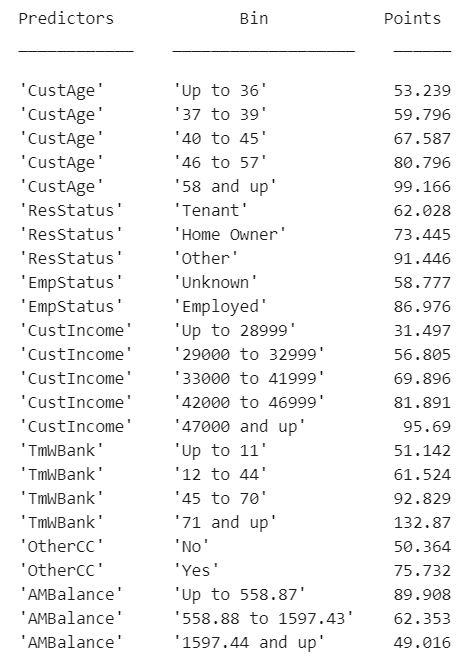
評分卡的分數通常要按照一定的比例調整并四舍五入進行取整。可用?formatpoints?函數來進行這些操作.?(鏈接如下)
https://ww2.mathworks.cn/help/finance/creditscorecard.formatpoints.html
比如,可設定達到一定好壞樣本比例(odds ratio)的分箱可以獲得的分數,以及每次該比例翻倍時候可以增加的分數。運行代碼如下:
步驟7. 對樣本進行評分
用?score?函數來計算訓練集中的樣本的分數。(鏈接如下)
https://ww2.mathworks.cn/help/finance/creditscorecard.score.html
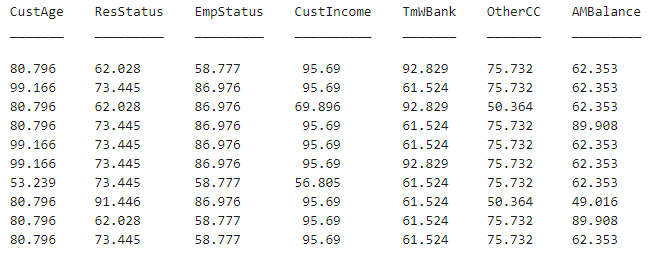
也可以用該函數來計算其它樣本的分數,比如預留的用來驗證模型的測試集樣本。該函數也可以顯示每個客戶樣本在每個自變量上所獲得的分數。運行代碼如下:
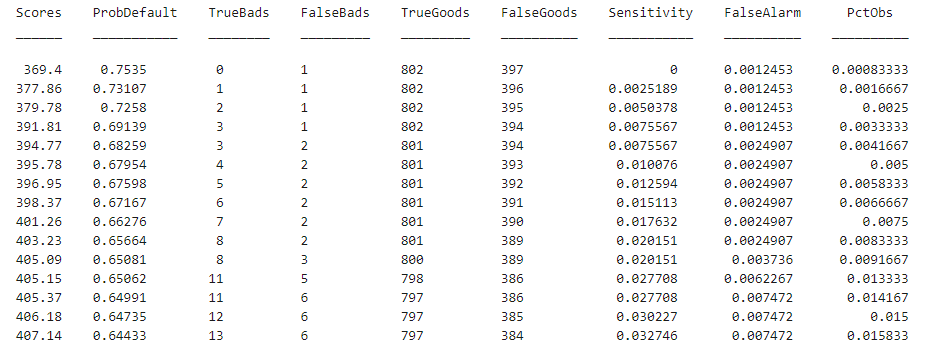
[Scores,Points] = score(sc); disp(Scores(1:10)) disp(Points(1:10,:))
528.2044554.8861505.2406564.0717554.8861586.1904441.8755515.8125524.4553
508.3169
步驟8. 計算違約概率PD
用?probdefault?函數來計算違約概率 pd.?(鏈接如下)
https://ww2.mathworks.cn/help/finance/creditscorecard.probdefault.html
pd = probdefault(sc);
定義好樣本的概率,并將好壞樣本的比率 (odds) 和對應的評分卡分數畫圖顯示。圖中我們可以看出,樣本的分數與對應的好壞樣本比(odds)相吻合,并且滿足預定義的“odds翻倍則分數增加50“。運行代碼如下:

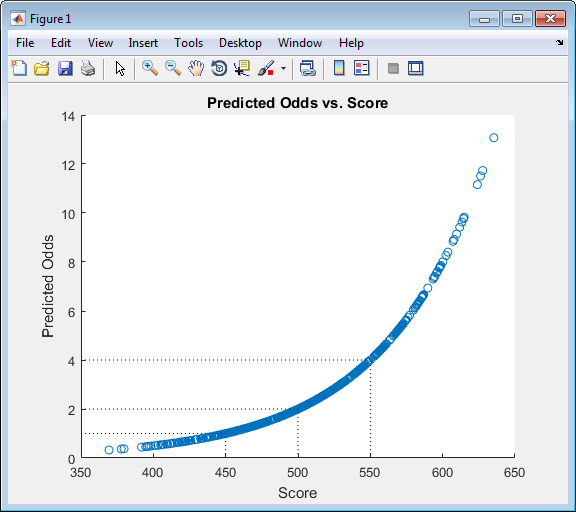
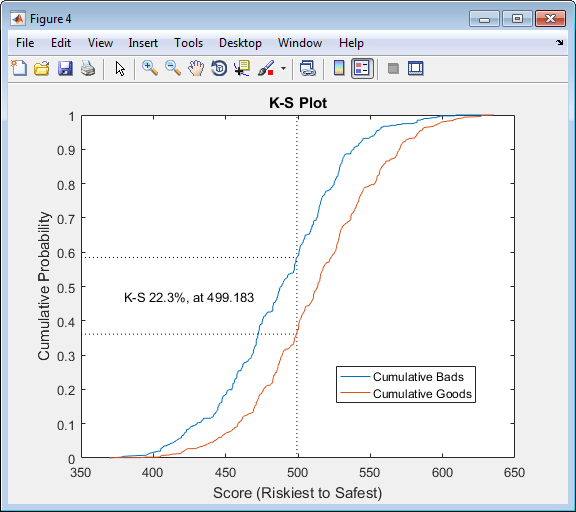
步驟 9. 利用 CAP、ROC 和 Kolmogorov-Smirnov 檢驗來驗證信用評分卡模型
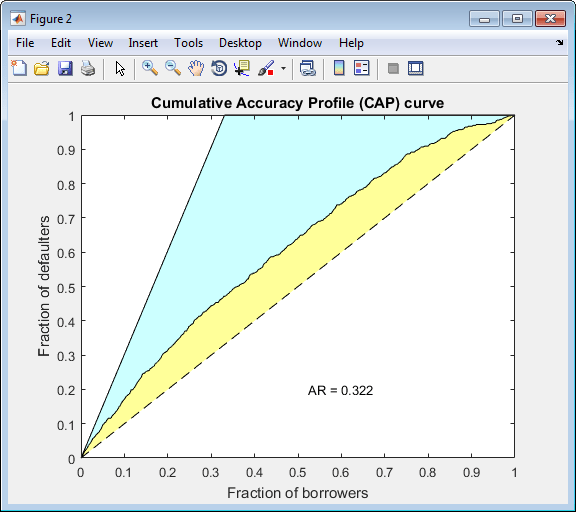
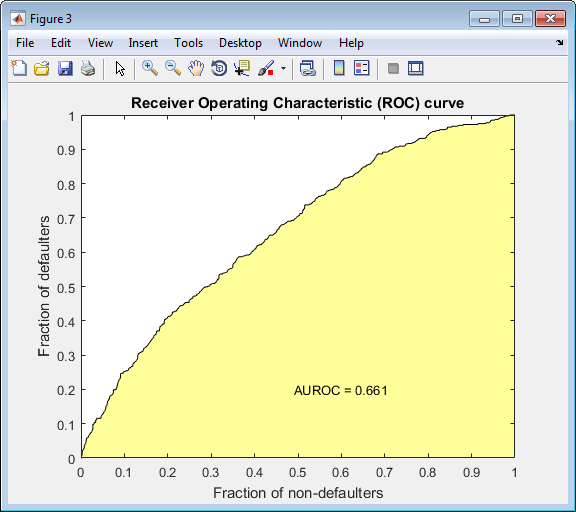
Creditscorecard 這個對象支持三種驗證方式: CAP,ROC 和 K-S 檢驗. 更多關于這三種檢驗方式的信息,參見?validatemodel. 運行代碼如下:?(鏈接如下)
https://ww2.mathworks.cn/help/finance/creditscorecard.validatemodel.html


?
??免費分享一些我整理的人工智能學習資料給大家,整理了很久,非常全面。包括一些人工智能基礎入門視頻+AI常用框架實戰視頻、圖像識別、OpenCV、NLP、YOLO、機器學習、pytorch、計算機視覺、深度學習與神經網絡等視頻、課件源碼、國內外知名精華資源、AI熱門論文等。
下面是部分截圖,加我免費領取
目錄
一、人工智能免費視頻課程和項目
二、人工智能必讀書籍
三、人工智能論文合集
四、機器學習+計算機視覺基礎算法教程
最后,我想說的是,自學人工智能并不是一件難事。只要我們有一個正確的學習方法和學習態度,并且堅持不懈地學習下去,就一定能夠掌握這個領域的知識和技術。讓我們一起抓住機遇,迎接未來!
上面這份完整版的Python全套學習資料已經上傳至CSDN官方,朋友如果需要可以點擊鏈接領取?
二維碼詳情



















