Redis的持久化功能在一定程度上保證了數據的安全性,即便是服務器宕機的情況下,也可以保證數據的丟失非常少。通常,為了避免服務的單點故障,會把數據復制到多個副本放在不同的服務器上,且這些擁有數據副本的服務器可以用于處理客戶端的讀請求,擴展整體的性能
下面會介紹Redis的主從復制配置和實現原理,后續還會有Redis的高可用方案:哨兵機制(Sentinel)、分區集群(Cluster)
什么是主從復制
我們可以通過slaveof <host> <port>命令,或者通過配置slaveof選項,來使當前的服務器(slave)復制指定服務器(master)的內容,被復制的服務器稱為主服務器(master),對主服務器進行復制操作的為從服務器(slave)
主服務器master可以進行讀寫操作,當主服務器的數據發生變化,master會發出命令流來保持對salve的更新,而從服務器slave通常是只讀的(可以通過slave-read-only指定),在主從復制模式下,即便master宕機了,slave是不能變為主服務器進行寫操作的
一個master可以有多個slave,即一主多從;而slave也可以接受其他slave的連接,形成“主從鏈”層疊狀結構(cascading-like structure),自 Redis 4.0 起,所有的sub-slave也會從master收到完全一樣的復制流。如下圖

?
主從復制的好處:
- 數據冗余,實現數據的熱備份
- 故障恢復,避免單點故障帶來的服務不可用
- 讀寫分離,負載均衡。主節點負載讀寫,從節點負責讀,提高服務器并發量
- 高可用基礎,是哨兵機制和集群實現的基礎
主從復制的配置
使用和配置主從復制是比較簡單的,在從服務器slave的配置文件中設置slaveof選項,或者直接使用slaveof <masterip> <masterport>命令
這里我使用3臺虛擬機來搭建一下,主服務器的ip為192.168.249.20,兩個從服務器的ip分別為192.168.249.21和192.168.249.21,端口號都為6379,具體的配置如下
主服務器并不需要額外多配置什么,這里我們先把三臺服務器的都需要改的地方列一下
復制代碼
# 設置為后臺運行 daemonize yes # 保存pid的文件,如果是在一臺機器搭建主從,需要區分一下 pidfile /var/run/redis_6379.pid # 綁定的主機地址,這里注釋掉,開放ip連接 #bind 127.0.0.1 # 指定日志文件 logfile "6379.log"
在從服務器中添加配置slaveof <masterport> <masterport>選項,在5.0版本中使用了replicaof代替了slaveof(github.com/antirez/red…),slaveof還可以繼續使用,不過建議使用replicaof。如果是使用命令行來復制的話,重啟之后會無效
復制代碼
# replicaof <masterip> <masterport> replicaof 192.168.249.20 6379
配置好redis.conf之后,我們分別啟動3臺服務器,可以用戶命令info replication查看復制信息
復制代碼
192.168.249.20:6379> info replication # Replication role:master connected_slaves:2 slave0:ip=192.168.249.22,port=6379,state=online,offset=700,lag=0 slave1:ip=192.168.249.21,port=6379,state=online,offset=700,lag=0 master_replid:b80a4720c0001efb62940f5ad6abaf9cdaf7a813 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:700 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:700 192.168.249.21:6379> info replication # Replication role:slave master_host:192.168.249.20 master_port:6379 master_link_status:up master_last_io_seconds_ago:3 master_sync_in_progress:0 slave_repl_offset:854 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:b80a4720c0001efb62940f5ad6abaf9cdaf7a813 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:854 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:57 repl_backlog_histlen:798 192.168.249.22:6379> info replication # Replication role:slave master_host:192.168.249.20 master_port:6379 master_link_status:up master_last_io_seconds_ago:6 master_sync_in_progress:0 slave_repl_offset:854 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:b80a4720c0001efb62940f5ad6abaf9cdaf7a813 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:854 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:854
接下來我們可以在主服務器中寫入數據,然后可以在其他的從服務器中讀取數據
復制代碼
192.168.249.20:6379> set test 'Hello World' OK 192.168.249.21:6379> get test "Hello World" 192.168.249.22:6379> get test "Hello World"
然后我們試著在從服務器中寫入數據,會提示不能在只讀的從服務器中寫入數據
復制代碼
192.168.249.21:6379> set test2 hello (error) READONLY You can't write against a read only replica.
如果我們需要slave對master的復制進行驗證,可以在master中配置
requirepass <password>選項設置密碼那么需要在從服務器中使用該密碼,可以使用命令
config set masterauth <password>,或者在配置文件中設置masterauth <password>
主從復制的實現原理
主從復制的配置還是比較簡單的,下面來了解下主從復制的實現原理
Redis的主從復制過程大體上分3個階段:建立連接、數據同步、命令傳播
建立連接
這個階段主要是從服務器發出slaveof命令之后,與主服務器如何建立連接,為數據同步做準備的過程。
1)在slaveof命令執行之后,從服務器根據設置的master的ip地址和端口,創建連向主服務器的socket套接字連接,連接成功后,從服務器會為這個套接字關聯一個專門的處理器,用于處理后續的復制工作
2)建立連接之后,從服務器會向主服務器發送ping命令,確認主服務器是否可用,以及當前是否可用接受處理命令。如果收到主服務器的pong回復說明是可用的,否則有可能是網絡超時或主服務器阻塞,從服務器會斷開連接發起重連
3)身份驗證。如果主服務器設置了requirepass選項,那么從服務器必須配置masterauth選項,且保證密碼一致才能通過驗證
4)身份驗證完成之后,從服務器會發送自己的監聽端口,主服務器會保存下來
復制代碼
192.168.249.20:6379> info replication ... slave0:ip=192.168.249.22,port=6379,state=online,offset=700,lag=0 slave1:ip=192.168.249.21,port=6379,state=online,offset=700,lag=0 ...
數據同步
在主從服務器建立連接確認各自身份之后,就開始數據同步,從服務器向主服務器發送PSYNC命令,執行同步操作,并把自己的數據庫狀態更新至主服務器的數據庫狀態
Redis的主從同步分為:完整重同步(full resynchronization)和部分重同步(partial resynchronization)
完整重同步
有兩種情況下是完整重同步,一是slave連接上master第一次復制的時候;二是如果當主從斷線,重新連接復制的時候有可能是完整重同步,這個在后面說
下面是完整重同步的步驟

?
- 從服務器連接主服務器,發送SYNC命令
- 主服務器接收到SYNC命名后,開始執行
bgsave命令生成RDB文件并使用緩沖區記錄此后執行的所有寫命令 - 主服務器
basave執行完后,向所有從服務器發送快照文件,并在發送期間繼續記錄被執行的寫命令 - 從服務器收到快照文件后丟棄所有舊數據,載入收到的快照
- 主服務器快照發送完畢后開始向從服務器發送緩沖區中的寫命令
- 從服務器完成對快照的載入,開始接收命令請求,并執行來自主服務器緩沖區的寫命令
部分重同步
部分重同步是用于處理斷線后重復制的情況,先介紹幾個用于部分重同步的部分
runid(replication ID),主服務器運行id,Redis實例在啟動時,隨機生成一個長度40的唯一字符串來標識當前節點offset,復制偏移量。主服務器和從服務器各自維護一個復制偏移量,記錄傳輸的字節數。當主節點向從節點發送N個字節數據時,主節點的offset增加N,從節點收到主節點傳來的N個字節數據時,從節點的offset增加Nreplication backlog buffer,復制積壓緩沖區。是一個固定長度的FIFO隊列,大小由配置參數repl-backlog-size指定,默認大小1MB。需要注意的是該緩沖區由master維護并且有且只有一個,所有slave共享此緩沖區,其作用在于備份最近主庫發送給從庫的數據
當slave連接到master,會執行PSYNC <runid> <offset>發送記錄舊的master的runid(replication ID)和偏移量offset,這樣master能夠只發送slave所缺的增量部分。但是如果master的復制積壓緩存區沒有足夠的命令記錄,或者slave傳的runid(replication ID)不對,就會進行完整重同步,即slave會獲得一個完整的數據集副本
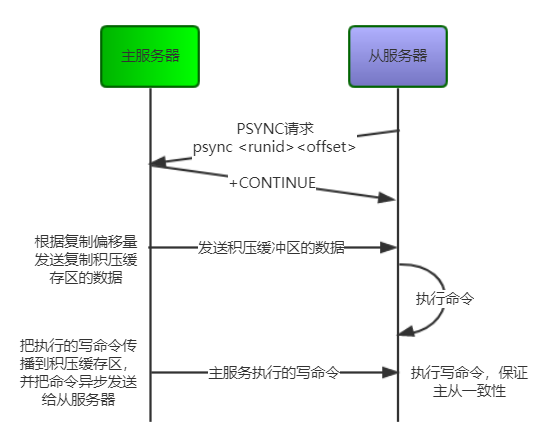
?
PSYNC命令執行完整重同步和部分重同步的流程圖

?
命令傳播
當完成數據同步之后,主從服務器的數據暫時達到一致狀態,當主服務器執行了客戶端的寫命令之后,主從的數據便不再一致。為了能夠使主從服務器的數據保持一致性,主服務器會對從服務器執行命令傳播操作,即每執行一個寫命令就會向從服務器發送同樣的寫命令
在命令傳播階段,從服務器會默認以每秒一次的頻率向主服務器發送心跳檢測
復制代碼
REPLCONF ACK <replication_offset>
其中replication_offset是當前從服務器的復制偏移量,該命令的作用有三個
- 檢測主從服務器的網絡連接狀態
- 輔助實現
min-slaves選項 - 檢測命令丟失
關閉持久化時,復制的安全性
關于關閉持久化時,復制的安全性問題,我這里摘入官網的一段描述www.redis.cn/topics/repl…
在使用Redis復制功能時的設置中,強烈建議在master和在slave中啟用持久化。當不可能啟用時,例如由于非常慢的磁盤性能而導致的延遲問題,應該配置實例來避免重置后自動重啟。
為了更好地理解為什么關閉了持久化并配置了自動重啟的 master 是危險的,檢查以下故障模式,這些故障模式中數據會從 master 和所有 slave 中被刪除:
- 我們設置節點 A 為 master 并關閉它的持久化設置,節點 B 和 C 從 節點 A 復制數據。
- 節點 A 崩潰,但是他有一些自動重啟的系統可以重啟進程。但是由于持久化被關閉了,節點重啟后其數據集合為空。
- 節點 B 和 節點 C 會從節點 A 復制數據,但是節點 A 的數據集是空的,因此復制的結果是它們會銷毀自身之前的數據副本。
當 Redis Sentinel 被用于高可用并且 master 關閉持久化,這時如果允許自動重啟進程也是很危險的。例如, master 可以重啟的足夠快以致于 Sentinel 沒有探測到故障,因此上述的故障模式也會發生。
任何時候數據安全性都是很重要的,所以如果 master 使用復制功能的同時未配置持久化,那么自動重啟進程這項應該被禁用
參考:《Redis設計與實現》、redis replication
作者:TurboSnail
鏈接:https://juejin.cn/post/6844903943764443149
來源:稀土掘金
著作權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉載請注明出處。











![[java學習日記]反射、動態代理](http://pic.xiahunao.cn/[java學習日記]反射、動態代理)
操作 Excel 詳解)



ServerBootstrap)


