目錄
- Elasticsearch邏輯設計和物理設計
- 邏輯設計
- 物理設計
- Elasticsearch原理
- 倒排索引
- 文檔的分析過程
- 保存文檔
- 搜索文檔
- 寫數據的底層原理
- 數據刷新(fresh)
- 事務日志的寫入
- ES在大數據量下的性能優化
- 文件系統緩存優化
- 數據預熱
- 文檔(Document)模型設計
- 分頁性能優化
- Elasticsearch和DB的差異
- 參考
Elasticsearch邏輯設計和物理設計
邏輯設計
- 索引(Index):類似于ES中的一張表,可以通過映射(Mapping)定義索引的結構和設置。
- 類型(Type):可以對ES的索引進一步做劃分。ES 7中已經移除類型,建議一個索引一個類型即可
- 映射(Mapping):索引結構的定義,包括索引的字段,字段類型,索引的設置等。
- 文檔(Document):索引中的一條記錄。
物理設計
Elasticsearch本身是分布式搜索引擎。它的高可用、高性能就是通過分片實現的。
- 主分片:一個索引可以劃分成多個主分片,通過將主分片分布到不同的ES節點,從而實現高性能。
- 副本分片:副本分片和主分片保持數據同步,和主分片不能分布在同一個節點,從而實現主分片的讀能力的橫向擴展,同時保證主分片不可用時實現故障轉移。

Elasticsearch原理
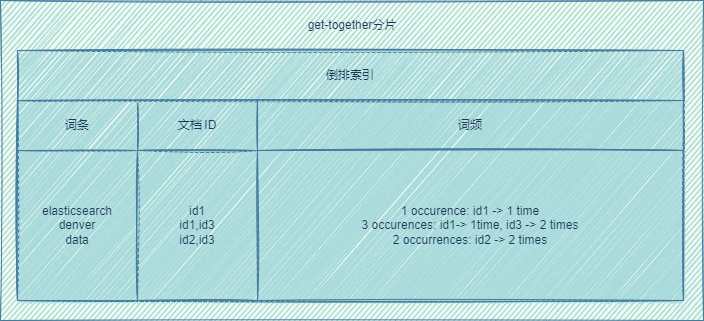
倒排索引
每個文檔都有唯一的文檔ID,一個文檔經過分析器變成一組詞條。
倒排索引:記錄詞條以及詞條出現的文檔ID的數據結構,同時倒排索引還會記錄詞條在文檔中出現的頻率。
文檔的分析過程
示例引用自《Elasticsearch實戰》。
在文檔加入倒排索引之前,需要經過分析器執行分析,轉換成一組詞條(Term)。
以下是文檔“share your experience with Nosql & big data technologies”的分析過程。
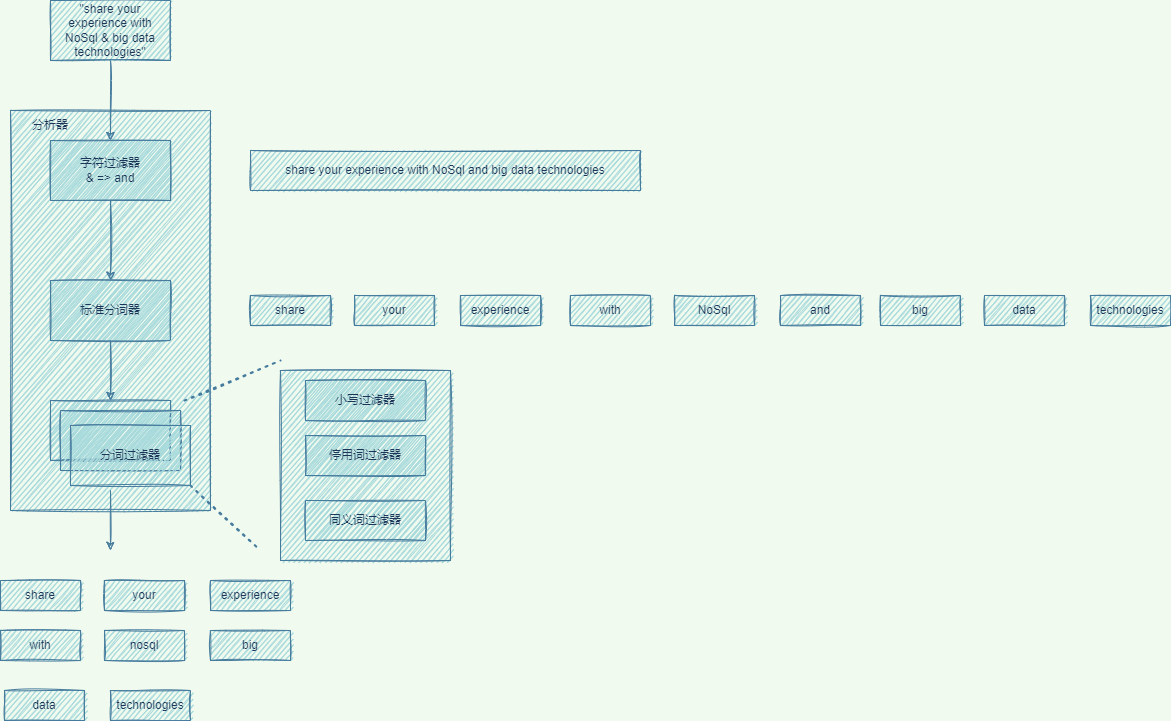
- 過濾字符:字符過濾器轉換個別字符。如:將
&轉換成and - 切分文本:分詞器將文本切分成多個詞條
- 過濾分詞:一組分詞過濾器按序轉換每個分詞。如:小寫分詞過濾器,將所有的分詞轉換成小寫。
- 創建索引:為詞條創建倒排索引
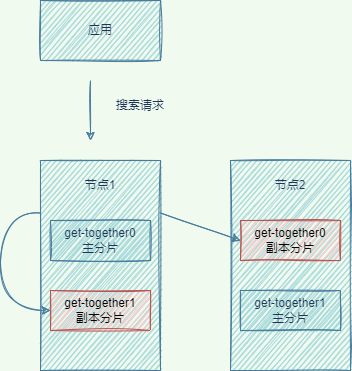
保存文檔
保存文檔是寫入主分片,然后,同步到副本分片;搜索文檔是根據輪詢算法,從主分片或副本分片讀取。
- 通過計算
文檔ID的哈希值,決定文檔的目標分片。如果文檔的目標分片不在當前節點,將文檔轉發到目標分片的節點。 - 將文檔加入倒排索引
- 將數據同步到所有的副本分片,即在副本分片創建倒排索引
- 所有的副本分片創建倒排索引成功,節點響應結果給客戶端
說明:
- 協調節點:接收客戶端請求/響應客戶端的節點,負責數據的請求轉發,數據的匯總。

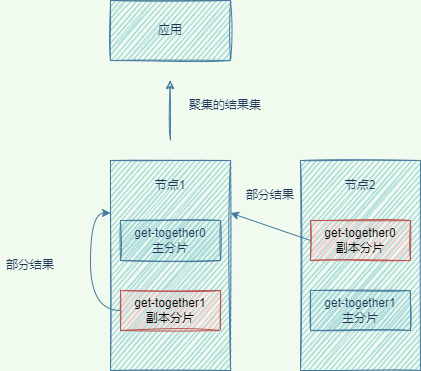
搜索文檔
-
協調節點使用round-robin隨機循環算法,將請求轉發到包含完整數據集合的分片集合(包括主分片和副本分片)。
-
協調節點收集各節點的返回結果,將結果返回客戶端:
2.1 查詢階段(Query Phase):每個分片將自己的搜索結果的
文檔ID返回給協調節點,協調節點進行數據的合并、排序、分頁,得到最終結果。2.2 拉取階段(Fetch Phase):協調節點根據
文檔ID取各個節點上拉取文檔數據,最終返回給客戶端。
?
寫數據的底層原理
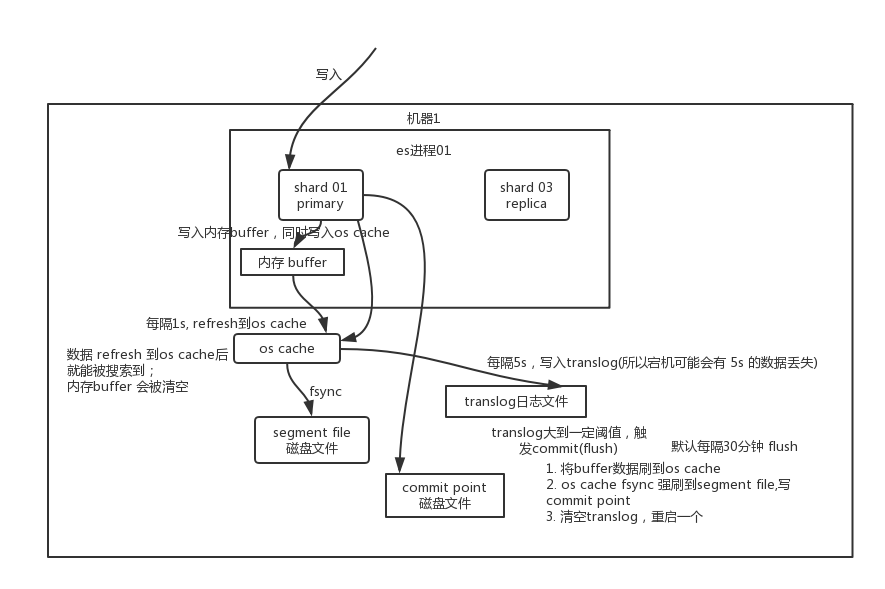
Elasticsearch會將數據先寫入內存的緩沖區,這時數據并不能用于查詢。
- 刷新數據:緩沖區過大或者默認每隔1秒,將緩沖區中的數據寫入段文件(segment file),然后清空緩沖區。數據在緩沖區時是不可見的,變成段文件后,就可以用于查詢。段文件不可變,所以每隔一秒ES就會生成一個新的段文件。
- 事務日志的寫入:為了防止數據丟失,ES會實時將數據寫入事務日志(tranlog)文件,事務日志文件是在磁盤里的。
- 數據沖刷:事務日志過大或者默認每隔30分鐘,會觸發數據沖刷,會將一個提交點(commit point)中的所有段文件(在操作系統緩沖區中的數據)和緩沖區所有的數據寫入磁盤,然后,刪除事務日志。
數據刷新(fresh)
數據刷新負責將緩沖區的數據寫入段文件。段文件實際上就Lucene索引。出于性能考慮,數據并不是直接寫入磁盤的,而是默認每隔1秒,數據從緩沖區寫入系統緩存(OS Cache),變成段文件。之后,就可以通過搜索接口查詢到對應的數據了。因為,數據都是在內存中的,所以一旦宕機,數據會丟失。ES通過事務日志保存了數據,所以,能夠保證數據的恢復。
ES是接近實時的(Near Real-time)
因為,數據是每1秒刷新的系統緩存,之后才可以訪問,所以是接近實時的。
事務日志的寫入
為了防止數據丟失,數據在寫入緩沖區的同時寫入事務日志文件。事務日志同樣是先寫入系統緩存(OS Cache),然后刷新到磁盤。
index.translog.durability參數- 刷盤策略
index.translog.durability取值:
- request:每次請求都執行fsync刷盤,ES要等待日志文件刷盤后才返回成功響應。能夠保證數據基本不丟失,但是,性能低下,不推薦使用。
- async:每隔5秒fsync一次translog數據到磁盤,默認值。兼顧數據的持久化和性能。
數據丟失
因為事務日志的默認刷盤方式是每隔5秒fsync一次,所以如果ES宕機,最多可能丟失5秒的數據。
ES在大數據量下的性能優化
文件系統緩存優化
ES中的索引數據會持久化到磁盤中,查詢的時候,索引數據從磁盤加載到系統緩存中。
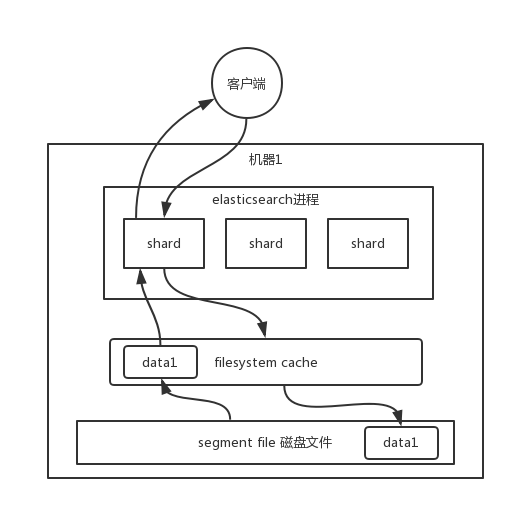
這里的filesystem cache就是上文的OS cache,都是指系統緩存。
ES搜索性能非常依賴于系統緩存,因為系統緩存是在內存中的。如果查詢走系統緩存,可以達到幾毫秒到幾百毫秒不等的查詢效率;但是,查詢走磁盤的話,搜索性能就要達到秒級。
最佳的情況下,機器的內存要達到容納總數據量的一半。
ES + HBase
為了減少ES的數據量,可以僅在ES索引中保存用于檢索的幾個字段,將完整的記錄保存在HBase中。查詢時,先通過ES獲取doc id,然后,根據doc id到HBase獲取完整的數據。
數據預熱
開啟定時任務,定時加載一些頻繁被訪問的熱點數據。如:電商系統中,如iphone,后臺開個任務,每隔1分鐘訪問一次相關數據,刷新到系統緩存中。
文檔(Document)模型設計
ES盡量不要使用復雜的操作,如:join(關聯)/nested/parent-child,對性能影響很大。
可以在Java應用里完成關聯,將關聯好的數據寫入ES中。
分頁性能優化
如果要取第100頁的10條數據,那么ES的分頁流程如下:
- 將每個分片上的前1000條數據都查到協調節點上,如果有5個分片,那就是5000條數據。
- 接著協調節點對這5000條數據做合并、排序
- 返回第100頁的10條數據。
所以,ES的分頁越深,查詢越慢。
有兩種優化方案:
- 不允許深度分頁:系統直接不允許深度的分頁。
- 通過scroll API:類似于游標,或者Java中的迭代器,訪問效率可以達到毫秒級。不過只能一頁頁的訪問,不能隨機跳到任意一頁訪問。
Elasticsearch和DB的差異
- Elasticsearch不支持事務,表連接。
- ES是個自帶分布式屬性的,高可用、可擴展、高性能,傳統關系型數據庫存在單機的性能瓶頸
- ES單個字段的數據類型豐富,除了核心的數據類型,還支持多字段,對象類型、數組類型等。
參考
部分圖片引用自:advanced-Java
- 《Elasticsearch實戰》
- Elasticsearch如何做到億級數據查詢毫秒級返回的:Elasticsearch如何做到億級數據查詢毫秒級返回的? - 掘金
- 互聯網 Java 工程師進階知識完全掃盲 - Doocs 技術社區
- 互聯網 Java 工程師進階知識完全掃盲 - Doocs 技術社區
)








:iced中如何為窗口添加icon圖標)




)




