鋼鐵產業產品智能自動化檢測識別相關的項目在我們前面的博文中已經有了相應的實踐了,感興趣的話可以自行移步閱讀即可:
《python基于DETR(DEtection TRansformer)開發構建鋼鐵產業產品智能自動化檢測識別系統》
《AI助力鋼鐵產業數字化,python基于YOLOv5開發構建鋼鐵產業產品智能自動化檢測識別系統》
在前文中我們大都是使用較為新穎的檢測模型來完成相應的項目開發的,這時我們不免有個疑問,早期提出來的模型比如YOLOv3是否還有一戰之力呢?出于好奇就拿來開發實踐了,首先看下實例效果:

整體使用層面上來說yolov3和yolov5的項目差異不大,所以比較熟悉yolov5的話,直接上手使用yolov3項目的話基本是沒有什么難度的。
因為是出于好奇,這里就直接先選擇的是yolov3-tiny版本的模型,目的就是能夠比較快的訓練完成,模型如下:
# parameters
nc: 10 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# anchors
anchors:- [10,14, 23,27, 37,58] # P4/16- [81,82, 135,169, 344,319] # P5/32# YOLOv3-tiny backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [16, 3, 1]], # 0[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 1-P1/2[-1, 1, Conv, [32, 3, 1]],[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 3-P2/4[-1, 1, Conv, [64, 3, 1]],[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 5-P3/8[-1, 1, Conv, [128, 3, 1]],[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 7-P4/16[-1, 1, Conv, [256, 3, 1]],[-1, 1, nn.MaxPool2d, [2, 2, 0]], # 9-P5/32[-1, 1, Conv, [512, 3, 1]],[-1, 1, nn.ZeroPad2d, [0, 1, 0, 1]], # 11[-1, 1, nn.MaxPool2d, [2, 1, 0]], # 12]# YOLOv3-tiny head
head:[[-1, 1, Conv, [1024, 3, 1]],[-1, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [512, 3, 1]], # 15 (P5/32-large)[-2, 1, Conv, [128, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 8], 1, Concat, [1]], # cat backbone P4[-1, 1, Conv, [256, 3, 1]], # 19 (P4/16-medium)[[19, 15], 1, Detect, [nc, anchors]], # Detect(P4, P5)]
訓練數據配置文件如下所示:
# path
train: ./dataset/images/train/
val: ./dataset/images/test/# number of classes
nc: 10# class names
names: ['chongkong', 'hanfeng', 'yueyawan', 'shuiban', 'youban', 'siban', 'yiwu', 'yahen', 'zhehen', 'yaozhe']默認是100次epoch的迭代計算,訓練日志如下所示:
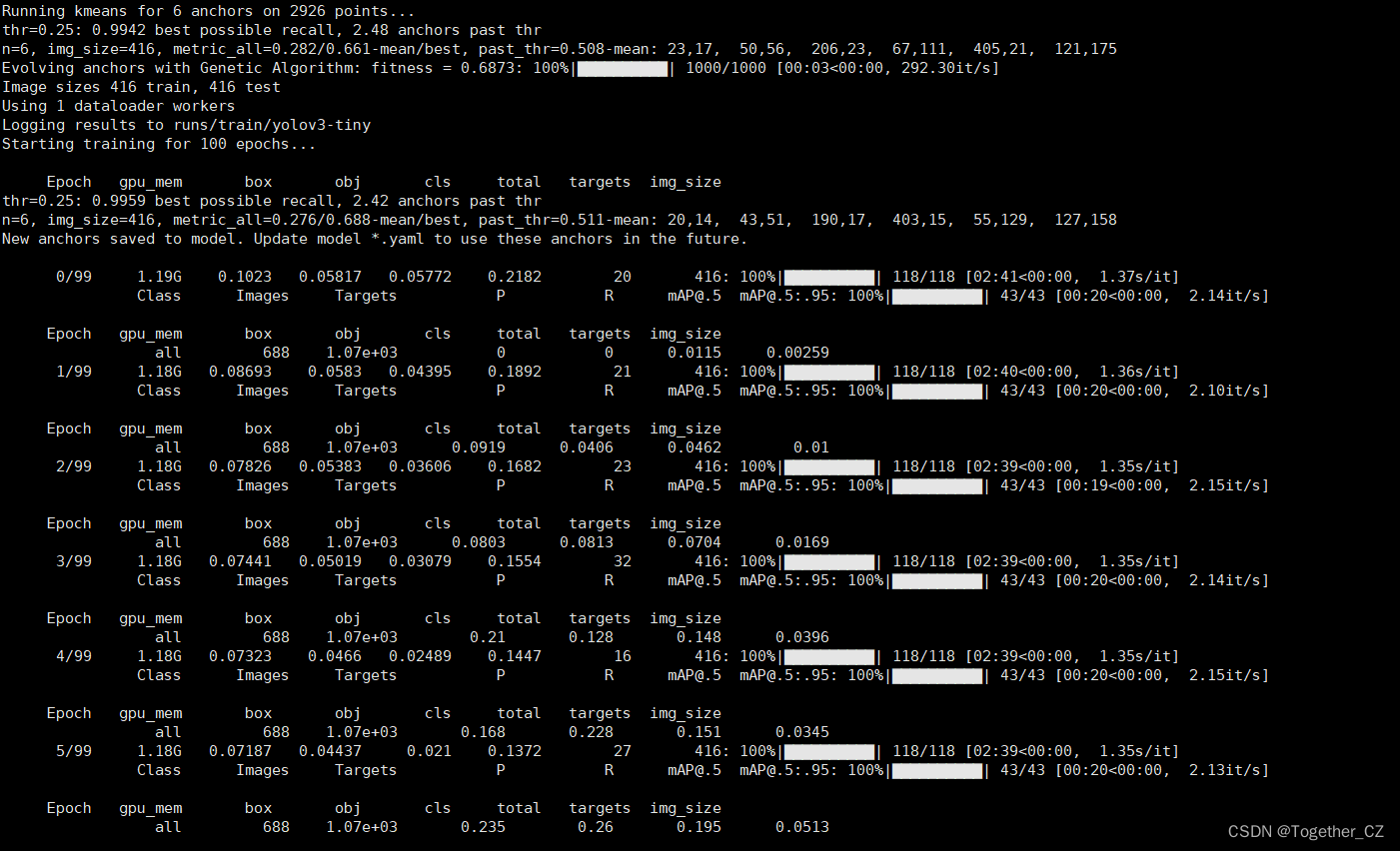
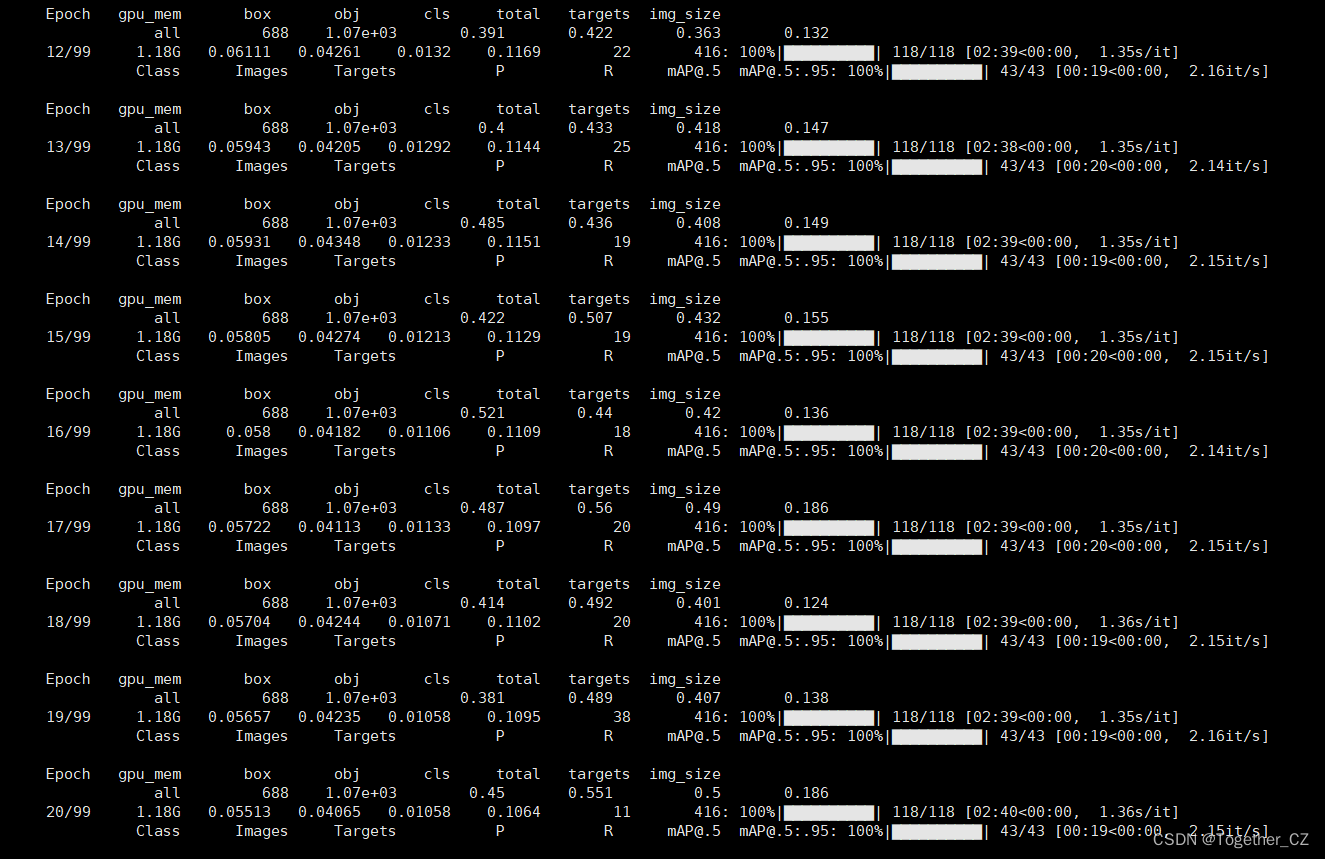
等待訓練完成后,看下結果詳情:
【混淆矩陣】
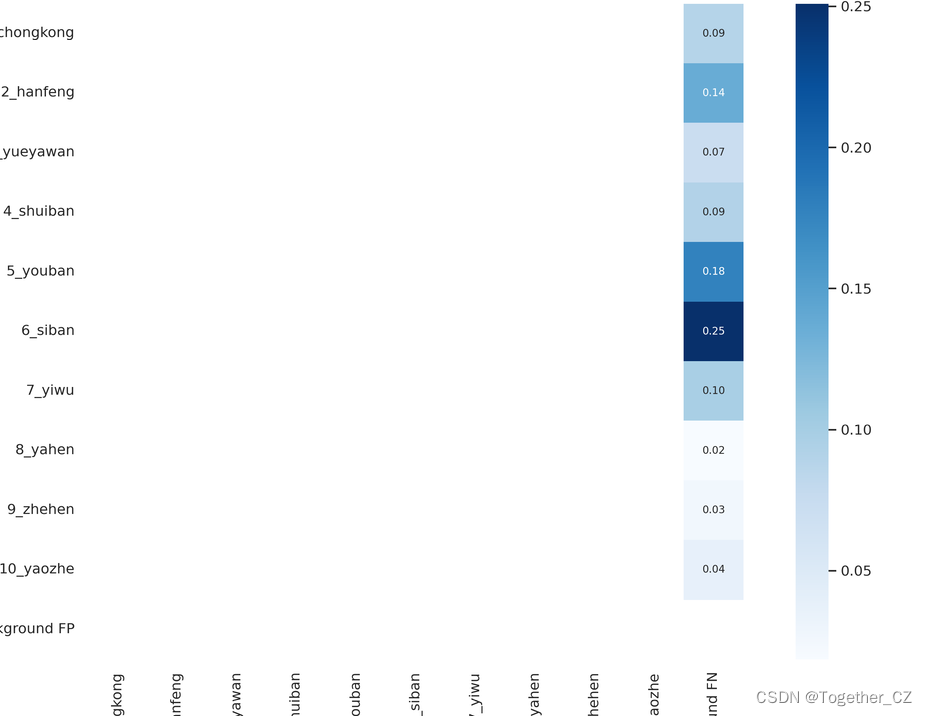
感覺yolov3項目提供的混淆矩陣不如yolov5項目的直觀,下面是yolov5項目的混淆矩陣:

【Label數據可視化】
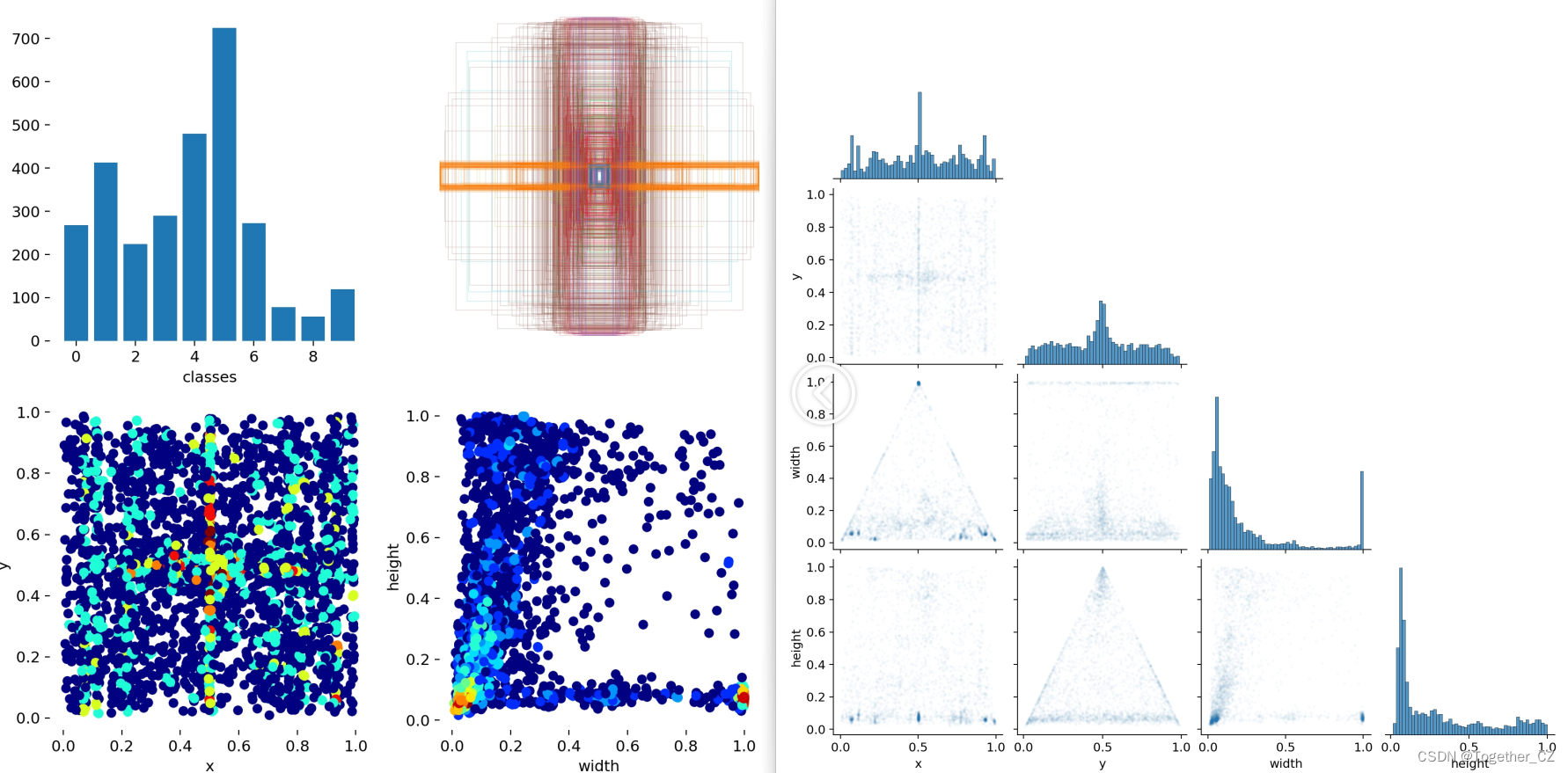
【PR曲線】
精確率-召回率曲線(Precision-Recall Curve)是一種用于評估二分類模型性能的可視化工具。它通過繪制不同閾值下的精確率(Precision)和召回率(Recall)之間的關系圖來幫助我們了解模型在不同閾值下的表現。
精確率是指被正確預測為正例的樣本數占所有預測為正例的樣本數的比例。召回率是指被正確預測為正例的樣本數占所有實際為正例的樣本數的比例。
繪制精確率-召回率曲線的步驟如下:
使用不同的閾值將預測概率轉換為二進制類別標簽。通常,當預測概率大于閾值時,樣本被分類為正例,否則分類為負例。
對于每個閾值,計算相應的精確率和召回率。
將每個閾值下的精確率和召回率繪制在同一個圖表上,形成精確率-召回率曲線。
根據曲線的形狀和變化趨勢,可以選擇適當的閾值以達到所需的性能要求。
精確率-召回率曲線提供了更全面的模型性能分析,特別適用于處理不平衡數據集和關注正例預測的場景。曲線下面積(Area Under the Curve, AUC)可以作為評估模型性能的指標,AUC值越高表示模型的性能越好。
通過觀察精確率-召回率曲線,我們可以根據需求選擇合適的閾值來權衡精確率和召回率之間的平衡點。根據具體的業務需求和成本權衡,可以在曲線上選擇合適的操作點或閾值。
?
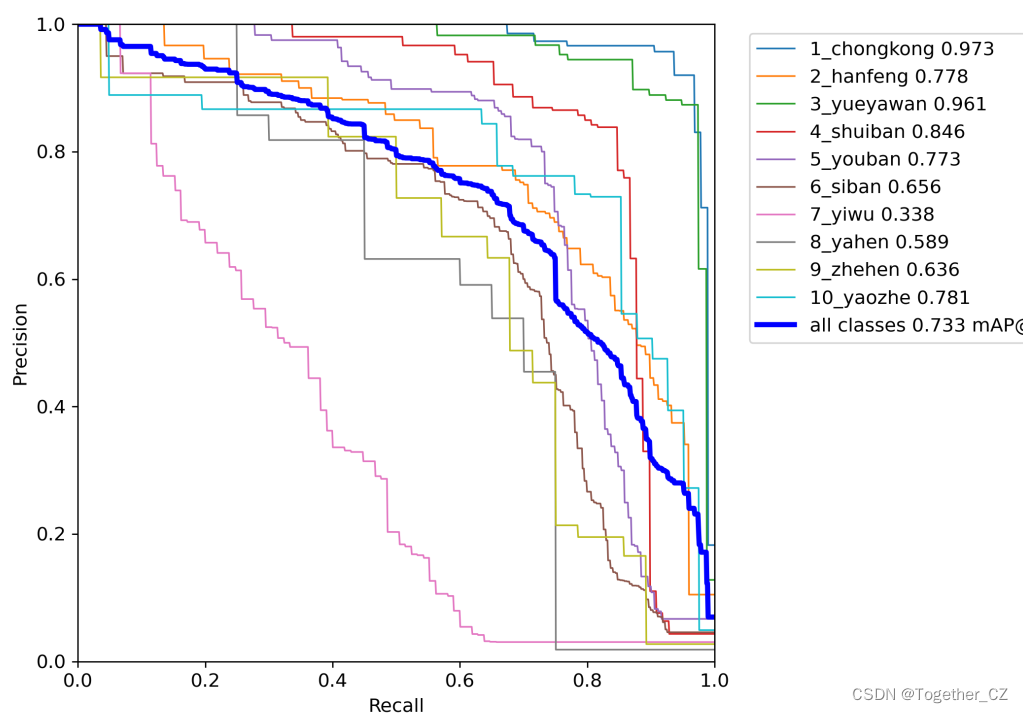
?yolov3的項目只提供了PR曲線可視化,沒有單獨的precision曲線和recall曲線和F1曲線,這點感覺是肯定不如yolov5項目的。
【訓練可視化】
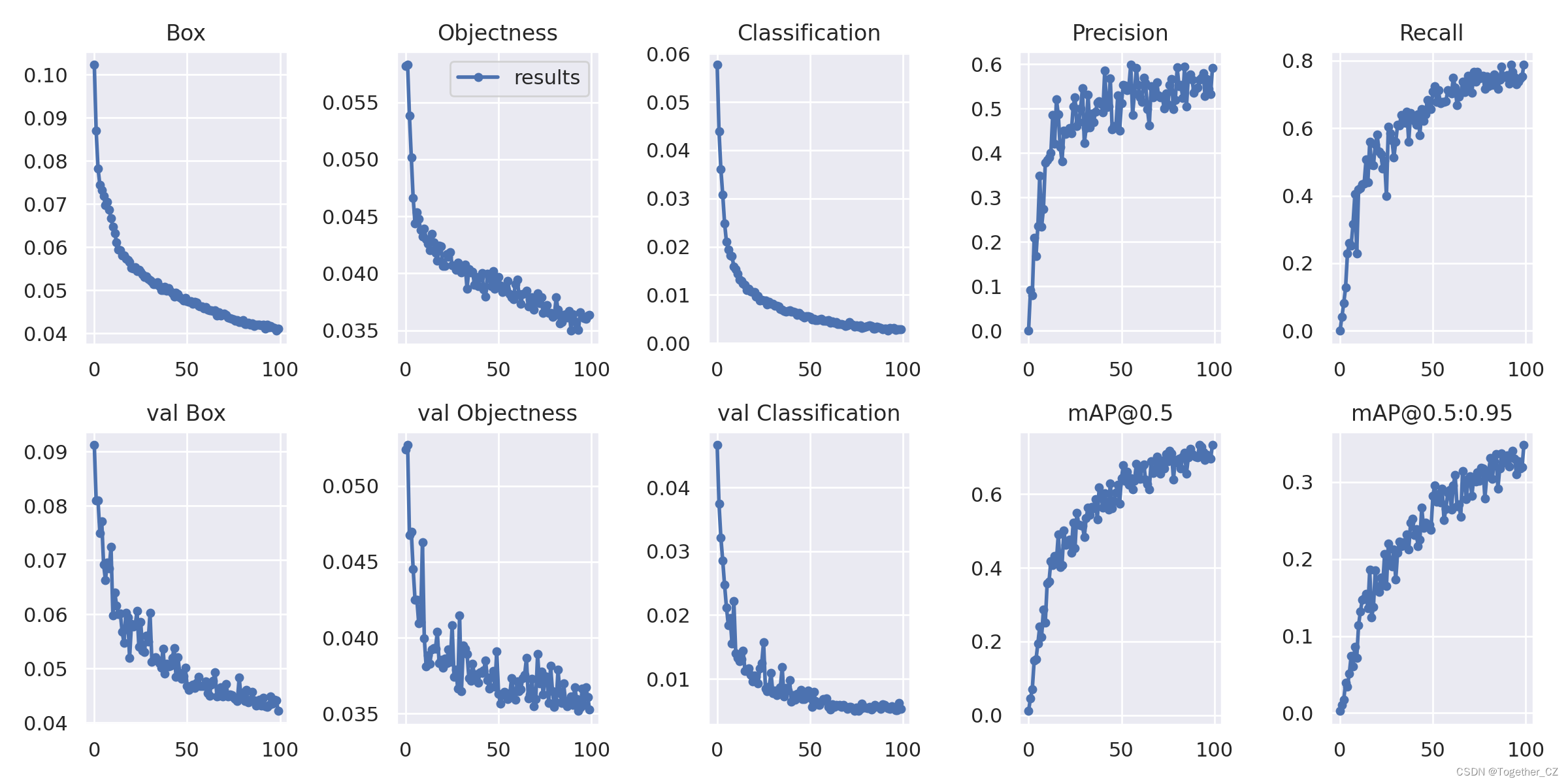
?【Batch計算實例】


既然yolov3只提供了PR曲線,那我就直接基于PR曲線來進行對比吧,如下:

上面是yolov5最強的模型效果與yolov3-tiny的對比,可以說是毫不意外全面碾壓了。
接下來我們來看yolov5系列最弱的模型與yolov3-tiny的對比效果,如下:
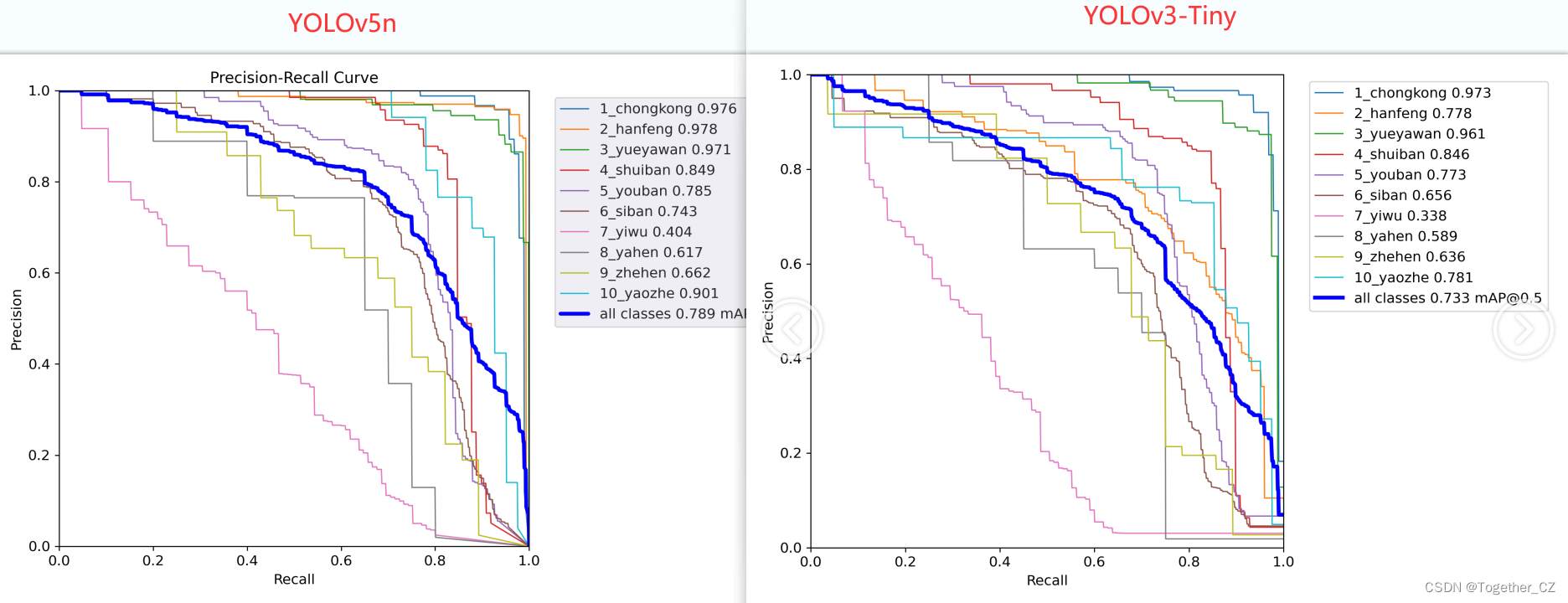
可以看到:即使是yolov5最弱的n系列的模型也做到了對yolov3-tiny系列模型的全面碾壓了,所有的訓練數據集等參數在整個過程是保持完全一致的。
那么你覺得YOLOv3在當下的目標檢測類任務中是否還有一戰之力了呢?感興趣的話也都自行動手實踐下吧!
?



、322. 零錢兌換、279.完全平方數)















