1、pooling是在卷積網絡(CNN)中一般在卷積層(conv)之后使用的特征提取層,使用pooling技術將卷積層后得到的小鄰域內的特征點整合得到新的特征。一方面防止無用參數增加時間復雜度,一方面增加了特征的整合度。
2、pooling是用更高層的抽象表示圖像特征,至于pooling為什么可以這樣做,是因為:我們之所以決定使用卷積后的特征是因為圖像具有一種“靜態性”的屬性,這也就意味著在一個圖像區域有用的特征極有可能在另一個區域同樣適用。因此,為了描述大的圖像,一個很自然的想法就是對不同位置的特征進行聚合統計。這個均值或者最大值就是一種聚合統計的方法。
3、做窗口滑動卷積的時候,卷積值就代表了整個窗口的特征。因為滑動的窗口間有大量重疊區域,出來的卷積值有冗余,進行最大pooling或者平均pooling就是減少冗余。減少冗余的同時,pooling也丟掉了局部位置信息,所以局部有微小形變,結果也是一樣的。就像圖片上的字母A,局部出現微小變化,也能夠被識別成A。而加上椒鹽噪音,就是字母A上有很多小洞,同樣的能夠被識別出來。而平移不變性,就是一個特征,無論出現在圖片的那個位置,都會識別出來。所以平移不變性不是pooling帶來的,而是層層的權重共享帶來的。
4、關于平移不變性的解釋:
4.1. invariance(不變性),這種不變性包括translation(平移),rotation(旋轉),scale(尺度)
4.2. 保留主要的特征同時減少參數(降維,效果類似PCA)和計算量,防止過擬合,提高模型泛化能力
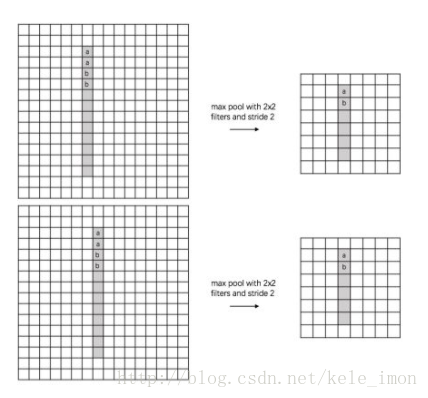
(1) translation invariance:這里舉一個直觀的例子(數字識別),假設有一個16x16的圖片,里面有個數字1,我們需要識別出來,這個數字1可能寫的偏左一點(圖1),這個數字1可能偏右一點(圖2),圖1到圖2相當于向右平移了一個單位,但是圖1和圖2經過max pooling之后它們都變成了相同的8x8特征矩陣,主要的特征我們捕獲到了,同時又將問題的規模從16x16降到了8x8,而且具有平移不變性的特點。圖中的a(或b)表示,在原始圖片中的這些a(或b)位置,最終都會映射到相同的位置。
(2) rotation invariance:下圖表示漢字“一”的識別,第一張相對于x軸有傾斜角,第二張是平行于x軸,兩張圖片相當于做了旋轉,經過多次max pooling后具有相同的特征
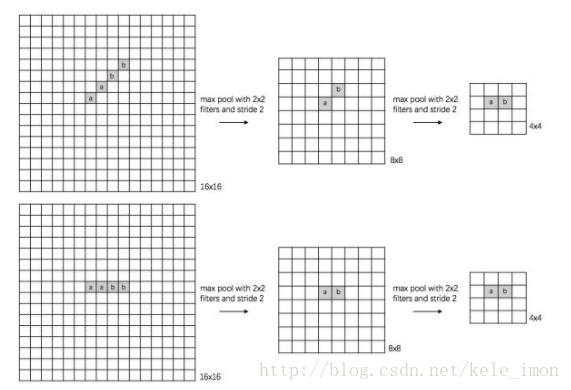
(3) scale invariance:
下圖表示數字“0”的識別,第一張的“0”比較大,第二張的“0”進行了較小,相當于作了縮放,同樣地,經過多次max pooling后具有相同的特征

)





)


:start_armboot)
、Nacos(配置中心、注冊中心)、loadbalancer)



如何完成精準時間同步?)




 ?)