目錄
1. 索引
1.1索引的概念
1.2索引的特點
1.3?索引的使用場景
?1.4索引的使用
1.4.1查看索引
1.4.2創建索引
?1.4.3刪除索引
?1.5索引保存的數據結構
2.事務
2.1經典例子
2.2事務的概念
2.3事務的使用
2.4事務的4個核心特性
2.5事務的并發問題
2.5.1臟讀
2.5.2不可重復讀
2.5.3幻讀
1. 索引
1.1索引的概念
1.2索引的特點
(1)加快查詢的速度。
(2)索引自身也是數據結構,也需要存儲空間。
(3)當我們需要進行新增,刪除,修改時,索引也需要更新(額外的開銷)。
1.3?索引的使用場景
1.數據量較大,且經常對這些列進行條件查詢。2.該數據庫表的插入操作,及對這些列的修改操作頻率較低。3.有足夠大的磁盤空間,因為索引會占用額外的磁盤空間。
?1.4索引的使用
使用博主已經建立好的student表。


1.4.1查看索引
語法:
show index from 表名;
查看某個表是否有索引,以及有幾個索引。
展示:
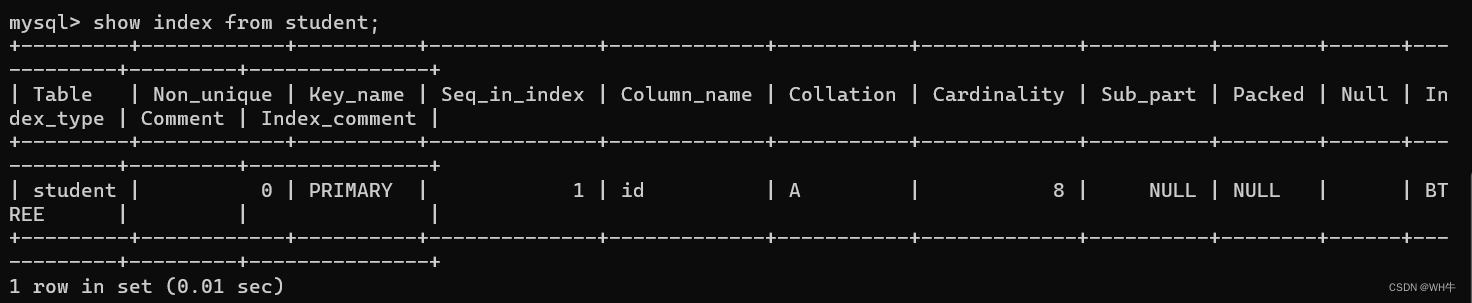
顯示指定表中所有索引的詳細信息
包括索引名稱(Key_name)、索引列(Column_name)、是否是唯一索引(Non_unique)、排序方式(Collation)、索引的基數(Cardinality)等。
1.4.2創建索引
對于非主鍵、非唯一約束、非外鍵的字段,可以創建普通索引,普通索引是最常見的索引類型,用于加速對表中數據的查詢。
語法:
create index 索引名 on 表名(字段名);
意思是:在那個表的那給字段上添加索引。
展示:
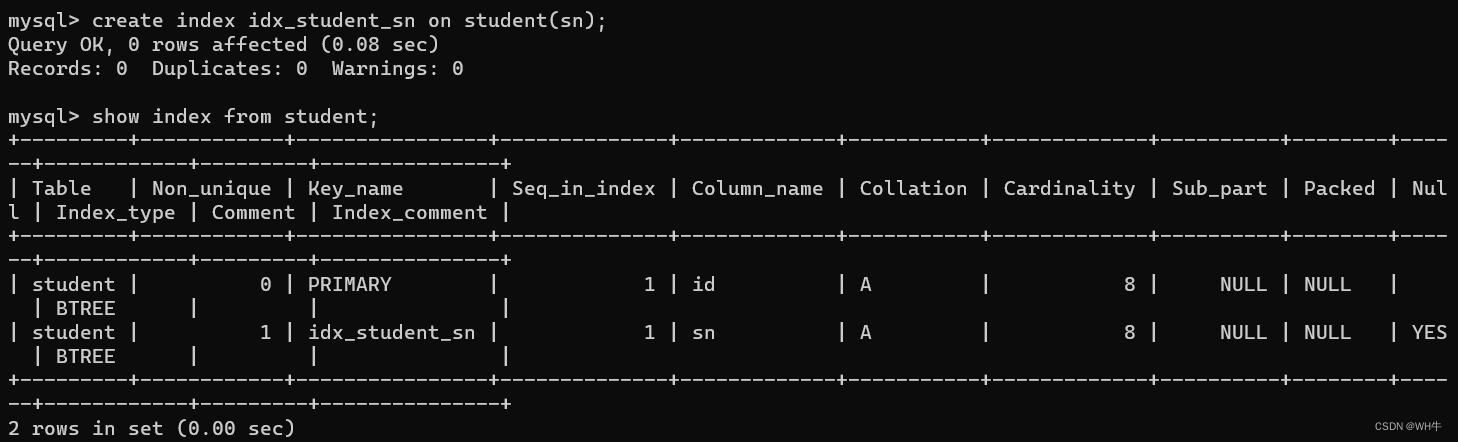
?1.4.3刪除索引
語法:
drop index 索引名 on 表名;
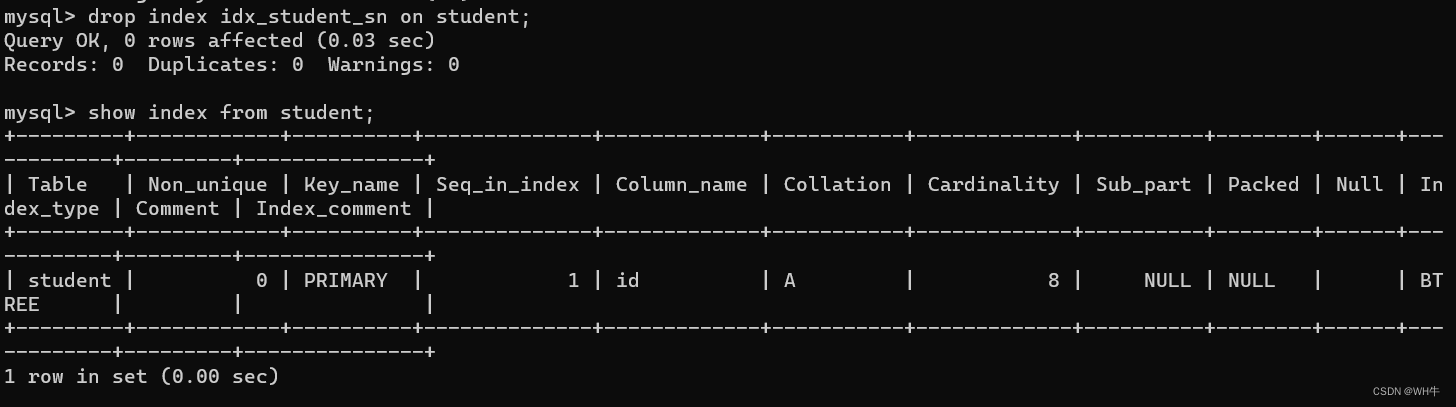
展示:
?
?1.5索引保存的數據結構
索引保存的數據結構主要為B+樹
B+樹的特點:
(1)為N叉二叉樹,每個節點有n個key,n個key劃分出n個區間。
(2)每個節點的n個key中,會存在最大(小)值。
(3)每個節點的key,都會在子樹中重復出現。
(4)葉子節點之間使用鏈式結構相連。
結構如下:
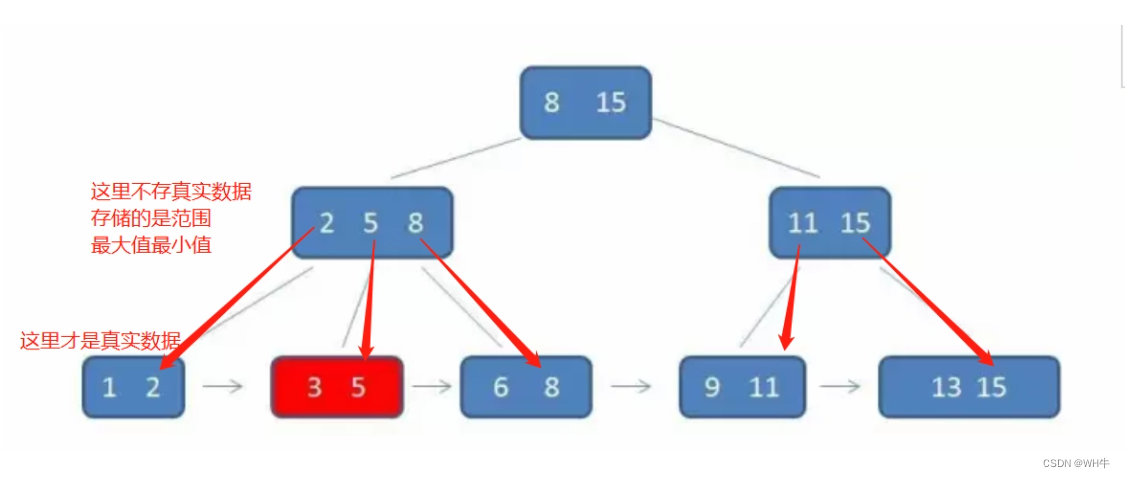
是B-Tree的改進版本,同時也是數據庫索引索引所采用的存儲結構。數據都在葉子節點上,并且增加了順序訪問指針,每個葉子節點都指向相鄰的葉子節點的地址。相比B-Tree來說,進行范圍查找時只需要查找兩個節點,進行遍歷即可。而B-Tree需要獲取所有節點,相比之下B+Tree效率高。
?為什么索引結構默認使用B-Tree,而不是hash,二叉樹,紅黑樹?
hash:雖然可以快速定位,但是沒有順序,IO復雜度高。
二叉樹:樹的高度不均勻,不能自平衡,查找效率跟數據有關(樹的高度),并且IO代高。
紅黑樹:樹的高度隨著數據量增加而增加,IO代價高。
?使用B+樹的好處:
(1)所有數據都包含在葉子節點這一層中(數據全集數)進行范圍查詢時,只要找到對應初始位置,之后沿鏈表遍歷即可。
(2)查詢時間穩定。查詢任意一個元素,都要從根節點查詢到子節點。(穩定比單純的快更有用)
(3)葉子節點這一層是數據全集數,故只存葉子節點在數據行,其他節點可以在緩存區。
2.事務
2.1經典例子
drop table if exists accout;create table accout(id int primary key auto_increment,name varchar ( 20 ) comment ' 賬戶名稱 ' ,money decimal ( 11 , 2 ) comment ' 金額 ');insert into accout(name, money) values( ' 阿里巴巴 ' , 5000 ),( ' 四十大盜 ' , 1000 );
比如說,四十大盜把從阿里巴巴的賬戶上偷盜了2000元?
--阿里巴巴賬戶減少2000update accout set money=money- 2000 where name = ' 阿里巴巴 ' ;-- 四十大盜賬戶增加 2000update accout set money=money+ 2000 where name = ' 四十大盜 ' ; ?
?
2.2事務的概念
2.3事務的使用
( 1 )開啟事務: start transaction;(2)執行多條 SQL 語句( 3 )回滾或提交: rollback/commit;
commit會提交事務,并使已對數據庫進行的所有修改成為永久性的;?
rollback會結束用戶的事務,并撤銷正在進行的所有未提交的修改;
只要沒有commit,數據庫就可以rollback復原到開始。?
?舉例:
start transaction;
-- 阿里巴巴賬戶減少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盜賬戶增加2000
update accout set money=money+2000 where name = '四十大盜';
commit;2.4事務的4個核心特性
(1)原子性:通過事務把多個操作打包在一起。
(2)一致性:在事務開始之前和事務結束以后,數據庫的完整性沒有被破壞。這表示寫入的資料必須完全符合所有的預設規則,這包含資料的精確度、串聯性以及后續數據庫可以自發性地完成預定的工作。
(3)事務處理結束后,對數據的修改就是永久的,即便系統故障也不會丟失。
(4)隔離性:數據庫允許多個并發事務同時對其數據進行讀寫和修改的能力,隔離性可以防止多個事務并發執行時由于交叉執行而導致數據的不一致。
2.5事務的并發問題
2.5.1臟讀
概念:一個事務讀到另一個事務還沒有提交的數據。
案例:
事務A修改了原來的數據但未提交,事務B讀了事務A修改的數據提交了,但事務A進行了回滾,事務B就讀了假數據。
解決:給操作加鎖(在放鎖之前不可訪問),也就是寫時不讓讀,寫完才讓讀。
2.5.2不可重復讀
概念:一個事務先后讀取相同的數據,但兩次讀取的數據不同。
圖示:
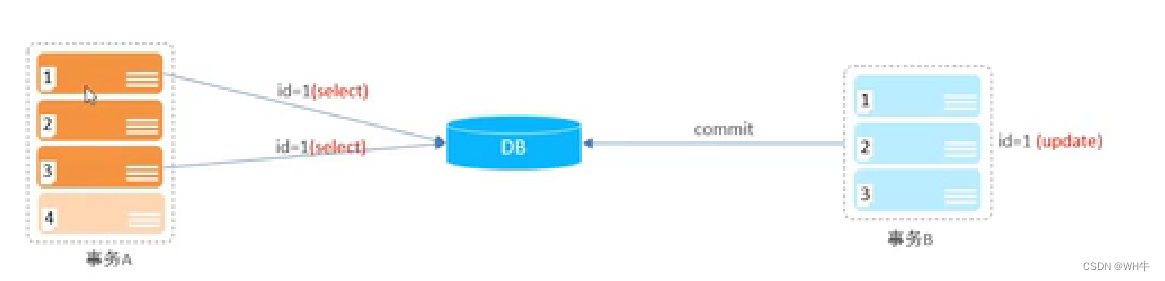
解決:給讀操作也加鎖,也就是讀的時候也不讓寫。
2.5.3幻讀
概念:一個事務按照條件查詢時,此時無對應的數據行,但插入時又發現數據已經存在。
圖示:?
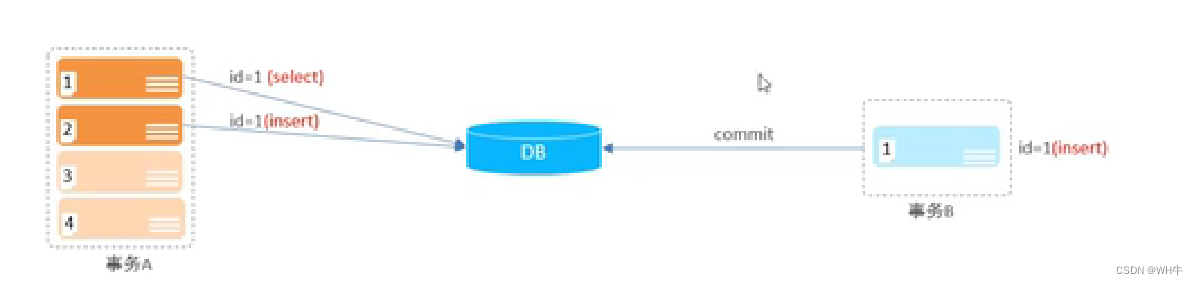
解決:串行化,不再進行任何并發。
2.6事務隔離級別
事務隔離分為不同級別,包括讀未提交(Read uncommitted)、讀提交(read committed)、可重復讀(repeatable read)和串行化(Serializable)。
(1)未提交(Read uncommitted)
并發程度最高,隔離程度最低,效果最高,數據最不靠譜。可能出現臟讀,不可重復讀,幻讀。
(2)讀提交(read committed)
相當給寫操作加鎖,可能出現不可重復讀,幻讀。
(3)可重復讀(repeatable read)
相當給寫和讀操作都加鎖,可能出現幻讀。
(4)串行化(Serializable)
并發程度最低,隔離程度最高,效果最低,數據最靠譜。?
都看到這了,不如關注一下,給個免費的贊?![]()


)






 處理Get、Post請求)










