引言
在考慮生成對抗網絡的文獻時,Wasserstein GAN 因其與傳統 GAN 相比的訓練穩定性而成為關鍵概念之一。在本文中,我將介紹基于梯度懲罰的 WGAN 的概念。文章的結構安排如下:
- WGAN 背后的直覺;
- GAN 和 WGAN 的比較;
- 基于梯度懲罰的WGAN的數學背景;
- 使用 PyTorch 從頭開始??在;
- CelebA-Face 數據集上實現;
- WGAN 結果討論。
WGAN 背后的直覺
GAN 最初由Ian J. Goodfellow 等人發明。在 GAN 中,有一個由生成器和判別器進行的雙玩家最小最大游戲。早期 GAN 的主要問題是模式崩潰和梯度消失問題。為了克服這些問題,長期以來發明了許多技術。WGAN 是試圖克服傳統 GAN 的這些問題的方法之一。
GAN 與 WGAN
與傳統的 GAN 相比,WGAN 有一些改進/變化。
- 評論家而非判別器;
- W-Loss 代替 BCE Loss;
- 使用梯度懲罰/權重剪裁進行權重正則化。
傳統GAN的判別器被“Critic”取代。從實現的角度來看,這只不過是最后一層沒有 Sigmoid 激活的判別器。
我們稍后將討論 WGAN 損失函數和權重正則化。
數學背景
損失函數
這是基于梯度懲罰的 WGAN 的完整損失函數。
等式 1. 具有梯度懲罰的完整 WGAN 損失函數 — [3]

看起來很嚇人吧?讓我們分解一下這個方程。
第 1 部分:原始批評損失

該方程產生的值應由生成器正向最大化,同時由批評家負向最大化。請注意,這里的 x_CURL 是生成器 (G(z)) 生成的圖像。
這里,D 在最后一層沒有 Sigmoid 激活,因此 D(*) 可以是任何實數。這給出了地球移動器的真實分布和生成分布之間的距離的近似值 - [1]。我們在這里想做的是,
- 評論家的觀點:通過最大化等式 2結果的負值/最小化正值,盡可能地將評論家對真實圖像和生成圖像的輸出分布分開。這反映了評論家的目標,即為真實圖像提供更高的分數,為更低的分數到生成的圖像。
- 生成器的觀點:嘗試通過以相反的方向分離真實圖像和生成圖像的輸出分布來抵消評論家的努力。這最終使式 2 的結果的正值最大化。這反映了生成器的目標是通過欺騙 Critic 來提高生成圖像的 Critic 分數。
- 在這里你可能已經注意到,Critic over Discriminator這個名字的出現是因為 Critic 不區分真假圖像,只是給出一個無界的分數。
為了確保方程有效,我們需要確保 Critic 函數是 1-Lipschitz 連續的 — [1]。
1-Lipschitz連續性
函數 f(x) 是 1-L 連續的,梯度應始終小于或等于 1。
為了確保這種1-Lipschitz連續性,文獻中主要提出了2種方法。
- Weight Clipping——這是 WGAN 論文 [2] 附帶的初始方法;
- 梯度懲罰方法——這是在最初的論文之后作為改進提出的[3]。
在本文中,我們將重點關注基于梯度懲罰的 WGAN。
第二部分:梯度懲罰

這是 Gulrajani 等人提出的梯度懲罰。——[3]。這里我們通過減小 Critic 梯度的 L2 范數與 1 之間的平方距離來強制 Critic 的梯度為 1。注意,我們不能強制 Critic 的梯度為 0,因為這會導致梯度消失問題。
等等!x(^)是什么?
考慮到 1-Lipschitz 連續性的定義,所有 x 的梯度應≤1。但實際上,確保所有可能的圖像都滿足這種條件是很困難的。因此,我們使用 x(^) 表示使用真實圖像和生成圖像作為梯度懲罰的數據點的隨機插值圖像。這確保了 Critic 的梯度將通過查看訓練期間遇到的一組公平的數據點/圖像進行正則化。
Pytorch實現
在這里,我將介紹大家應該做的必要更改,以便將傳統的 GAN 更改為 WGAN。
對于下面的實現,我將使用我在之前有關 DCGAN 的文章中詳細解釋的模型和訓練原理。
數據集
Celeba-face 數據集用于訓練。下載、預處理、制作數據加載器腳本如代碼1所示。
import zipfile
import os
if not os.path.isfile('celeba.zip'):!mkdir data_faces && wget https://s3-us-west-1.amazonaws.com/udacity-dlnfd/datasets/celeba.zip with zipfile.ZipFile("celeba.zip","r") as zip_ref:zip_ref.extractall("data_faces/")from torch.utils.data import DataLoadertransform = transforms.Compose([transforms.Resize((img_size,img_size)),transforms.ToTensor(),transforms.Normalize((0.5,0.5, 0.5),(0.5, 0.5, 0.5))])dataset = datasets.ImageFolder('data_faces', transform=transform)
data_loader = DataLoader(dataset,batch_size=batch_size,shuffle=True)
生成器和評論家
Critic 與 Discriminator 相同,但不包含最后一層 Sigmoid 激活。
class Generator(nn.Module):def __init__(self,noise_channels,img_channels,hidden_G):super(Generator,self).__init__()self.G=nn.Sequential(conv_trans_block(noise_channels,hidden_G*16,kernal_size=4,stride=1,padding=0),conv_trans_block(hidden_G*16,hidden_G*8),conv_trans_block(hidden_G*8,hidden_G*4),conv_trans_block(hidden_G*4,hidden_G*2),nn.ConvTranspose2d(hidden_G*2,img_channels,kernel_size=4,stride=2,padding=1),nn.Tanh())def forward(self,x):return self.G(x)class Critic(nn.Module):def __init__(self,img_channels,hidden_D):super(Critic,self).__init__()self.D=nn.Sequential(conv_block(img_channels,hidden_G),conv_block(hidden_G,hidden_G*2),conv_block(hidden_G*2,hidden_G*4),conv_block(hidden_G*4,hidden_G*8),nn.Conv2d(hidden_G*8,1,kernel_size=4,stride=2,padding=0))def forward(self,x):return self.D(x)
Generator 和 Critic 的支持塊如下面的代碼 3 所示。
class conv_trans_block(nn.Module):def __init__(self,in_channels,out_channels,kernal_size=4,stride=2,padding=1):super(conv_trans_block,self).__init__()self.block=nn.Sequential(nn.ConvTranspose2d(in_channels,out_channels,kernal_size,stride,padding),nn.BatchNorm2d(out_channels),nn.ReLU())def forward(self,x):return self.block(x)class conv_block(nn.Module):def __init__(self,in_channels,out_channels,kernal_size=4,stride=2,padding=1):super(conv_block,self).__init__()self.block=nn.Sequential(nn.Conv2d(in_channels,out_channels,kernal_size,stride,padding),nn.BatchNorm2d(out_channels),nn.LeakyReLU(0.2))def forward(self,x):return self.block(x)
損失函數
與任何其他典型的損失函數不同,損失函數可能有點棘手,因為它包含梯度。在這里,我們將使用梯度懲罰來實現 W-loss,稍后可以將其插入 WGAN 模型中。
def get_gen_loss(crit_fake_pred):gen_loss= -torch.mean(crit_fake_pred)return gen_lossdef get_crit_loss(crit_fake_pred, crit_real_pred, gradient_penalty, c_lambda):crit_loss= torch.mean(crit_fake_pred)- torch.mean(crit_real_pred)+ c_lambda* gradient_penaltyreturn crit_loss
讓我們分解一下代碼 4 中所示的損失函數。
- 生成器損失 - 生成器損失不受梯度懲罰的影響。因此,它必須僅最大化 D(x_CURL)/ D(G(z)) 項,這意味著最小化 -D(G(z))。這是在第 2 行中實現的。
- 批評者損失 - 批評者損失包含等式 1 中所示損失的 2 個部分。在第 6 行中,前兩項給出等式 2 中解釋的原始批評者損失,而最后一項給出等式 3 中解釋的梯度懲罰。
梯度懲罰可以按照下面的代碼 5 來實現 - [1]。
def get_gradient(crit, real_imgs, fake_imgs, epsilon):mixed_imgs= real_imgs* epsilon + fake_imgs*(1- epsilon)mixed_scores= crit(mixed_imgs)gradient= torch.autograd.grad(outputs= mixed_scores,inputs= mixed_imgs,grad_outputs= torch.ones_like(mixed_scores),create_graph=True,retain_graph=True)[0]return gradientdef gradient_penalty(gradient):gradient= gradient.view(len(gradient), -1)gradient_norm= gradient.norm(2, dim=1)penalty = torch.nn.MSELoss()(gradient_norm, torch.ones_like(gradient_norm))return penalty
在代碼 5 中,get_gradient()函數返回從x_hat (混合圖像)開始到Critic 輸出 (mixed_scores)結束的所有網絡梯度。這將在gradient_penalty()函數中使用,它返回Critic梯度的1和L2范數之間的均方距離。
減少 Critic 的損失最終會減少這種梯度懲罰。這確保了 Critic 函數保留了 1-Lipschitz 連續性。
訓練
訓練將與上一篇文章中的幾乎相同。但這里的損失與傳統的 GAN 損失不同。我已經使用WANDB記錄我的結果。如果您有興趣記錄結果,WANDB 是一個非常好的工具。
C=Critic(img_channels,hidden_C).to(device)
G=Generator(noise_channels,img_channels,hidden_G).to(device)#C=C.apply(init_weights)
#G=G.apply(init_weights)wandb.watch(G, log='all', log_freq=10)
wandb.watch(C, log='all', log_freq=10)opt_C=torch.optim.Adam(C.parameters(),lr=lr, betas=(0.5,0.999))
opt_G=torch.optim.Adam(G.parameters(),lr=lr, betas=(0.5,0.999))gen_repeats=1
crit_repeats=3noise_for_generate=torch.randn(batch_size,noise_channels,1,1).to(device)losses_C=[]
losses_G=[]for epoch in range(1,epochs+1):loss_C_epoch=[]loss_G_epoch=[]for idx,(x,_) in enumerate(data_loader):C.train()G.train()x=x.to(device)x_len=x.shape[0]### Train Closs_C_iter=0for _ in range(crit_repeats):opt_C.zero_grad()z=torch.randn(x_len,noise_channels,1,1).to(device)real_imgs=xfake_imgs=G(z).detach()real_C_out=C(real_imgs)fake_C_out=C(fake_imgs)epsilon= torch.rand(len(x),1,1,1, device= device, requires_grad=True)gradient= get_gradient(C, real_imgs, fake_imgs.detach(), epsilon)gp= gradient_penalty(gradient)loss_C= get_crit_loss(fake_C_out, real_C_out, gp, c_lambda=10)loss_C.backward()opt_C.step()loss_C_iter+=loss_C.item()/crit_repeats### Train Gloss_G_iter=0for _ in range(gen_repeats):opt_G.zero_grad()z=torch.randn(x_len,noise_channels,1,1).to(device)fake_C_out = C(G(z))loss_G= get_gen_loss(fake_C_out)loss_G.backward()opt_G.step()loss_G_iter+=loss_G.item()/gen_repeats
結果
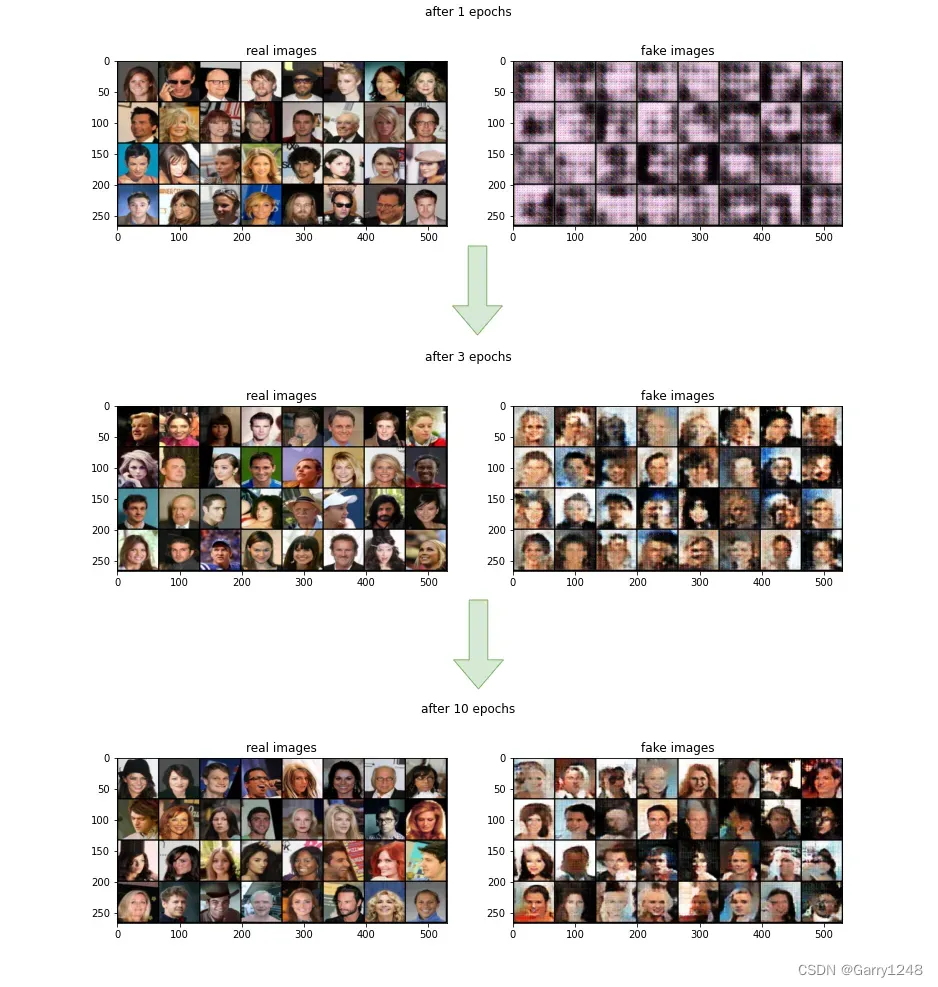
這是經過 10 個 epoch 訓練后獲得的結果。與傳統 GAN 一樣,生成的圖像隨著時間的推移變得更加真實。WANDB 項目的所有結果都可以在這里找到。
結論
生成對抗網絡一直是深度學習社區的熱門話題。由于 GAN 傳統訓練方法的缺點,WGAN 隨著時間的推移變得越來越流行。這主要是因為它對模式崩潰具有魯棒性并且不存在梯度消失問題。在本文中,我們實現了一個能夠生成人臉的簡單 WGAN 模型。
請隨意查看 GitHub 代碼。如有任何意見、建議和意見,我們將不勝感激。
Reference
[1] GAN specialization on coursera
[2] Arjovsky, Martin et al. “Wasserstein GAN”
[3] Gulrajani, Ishaan et al. “Improved Training of Wasserstein GANs”
[4] Goodfellow, Ian et al. “Generative Adversarial Networks”
[5] Vincent Herrmann, “Wasserstein GAN and the Kantorovich-Rubinstein Duality”
[6] Karras, Tero et al. “A Style-Based Generator Architecture for Generative Adversarial Networks”
本文譯自Udith Haputhanthri的博文。
)

)






![實現極坐標圖表QPolarChart的角度軸范圍是[0,360]時,0度在水平右側](http://pic.xiahunao.cn/實現極坐標圖表QPolarChart的角度軸范圍是[0,360]時,0度在水平右側)


)



![[網鼎杯 2018]Fakebook](http://pic.xiahunao.cn/[網鼎杯 2018]Fakebook)


