文章標題
- 一、Qwen-Image-Edit
- 1.ComfyOrg Qwen-Image-Edit 直播回放
- 2.Qwen-Image-Edit ComfyUI 原生工作流示例
- 2.1 工作流文件
- 2.2 模型下載
- 3.3 按步驟完成工作流
一、Qwen-Image-Edit
Qwen-Image-Edit 是 Qwen-Image 的圖像編輯版本,基于20B模型進一步訓練,支持精準文字編輯和語義/外觀雙重編輯能力。
Qwen-Image-Edit 是 Qwen-Image 的圖像編輯版本。它基于20B的Qwen-Image模型進一步訓練,成功將Qwen-Image的文本渲染特色能力拓展到編輯任務上,以支持精準的文字編輯。此外,Qwen-Image-Edit將輸入圖像同時輸入到Qwen2.5-VL(獲取視覺語義控制)和VAE Encoder(獲得視覺外觀控制),以同時獲得語義/外觀雙重編輯能力。
模型特性
特性包括:
- 精準文字編輯: Qwen-Image-Edit支持中英雙語文字編輯,可以在保留文字大小/字體/風格的前提下,直接編輯圖片中文字,進行增刪改。
- 語義/外觀 雙重編輯: Qwen-Image-Edit不僅支持low-level的視覺外觀編輯(例如風格遷移,增刪改等),也支持high-level的視覺語義編輯(例如IP制作,物體旋轉等)
- 強大的跨基準性能表現: 在多個公開基準測試中的評估表明,Qwen-Image-Edit 在編輯任務中均獲得SOTA,是一個強大的圖像生成基礎模型。
官方鏈接:
- GitHub 倉庫
- Hugging Face
- ModelScope
1.ComfyOrg Qwen-Image-Edit 直播回放
2.Qwen-Image-Edit ComfyUI 原生工作流示例
請確保你的 ComfyUI 已經更新。- ComfyUI 下載
- ComfyUI 更新教程
本指南里的工作流可以在 ComfyUI 的工作流模板中找到。如果找不到,可能是 ComfyUI 沒有更新。
如果加載工作流時有節點缺失,可能原因有:
- 你用的不是最新開發版(nightly)。
- 你用的是穩定版或桌面版(沒有包含最新的更新)。
- 啟動時有些節點導入失敗。
2.1 工作流文件
更新 ComfyUI 后你可以從模板中找到工作流文件,或者將下面的工作流拖入 ComfyUI 中加載

下載下面的圖片作為輸入
https://raw.githubusercontent.com/Comfy-Org/example_workflows/refs/heads/main/image/qwen/qwen-image-edit/input.png

2.2 模型下載
所有模型都可在 Comfy-Org/Qwen-Image_ComfyUI 或 Comfy-Org/Qwen-Image-Edit_ComfyUI 找到
Diffusion model
- qwen_image_edit_fp8_e4m3fn.safetensors
LoRA
- Qwen-Image-Lightning-4steps-V1.0.safetensors
Text encoder
- qwen_2.5_vl_7b_fp8_scaled.safetensors
VAE
- qwen_image_vae.safetensors
安裝aria2快速下載模型,幾乎能將我家1000M的寬帶跑滿,每秒80~90M,接下來的介紹模型都會給出安裝命令。
apt install aria2
aria2c https://huggingface.co/Comfy-Org/Qwen-Image-Edit_ComfyUI/resolve/main/split_files/diffusion_models/qwen_image_edit_fp8_e4m3fn.safetensors -o ComfyUI/models/diffusion_models/qwen_image_edit_fp8_e4m3fn.safetensors --auto-file-renaming=false --allow-overwrite=falsearia2c https://huggingface.co/lightx2v/Qwen-Image-Lightning/resolve/main/Qwen-Image-Lightning-4steps-V1.0.safetensors -o ComfyUI/models/loras/Qwen-Image-Lightning-4steps-V1.0.safetensors --auto-file-renaming=false --allow-overwrite=falsearia2c https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/resolve/main/split_files/text_encoders/qwen_2.5_vl_7b_fp8_scaled.safetensors -o ComfyUI/models/text_encoders/qwen_2.5_vl_7b_fp8_scaled.safetensors --auto-file-renaming=false --allow-overwrite=falsearia2c https://huggingface.co/Comfy-Org/Qwen-Image_ComfyUI/resolve/main/split_files/vae/qwen_image_vae.safetensors -o ComfyUI/models/vae/qwen_image_vae.safetensors --auto-file-renaming=false --allow-overwrite=false
小技巧:你要是打不開https://huggingface.co,可以將其換成為https://hf-mirror.com/試一試
Model Storage Location
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ └── qwen_image_edit_fp8_e4m3fn.safetensors
│ ├── 📂 loras/
│ │ └── Qwen-Image-Lightning-4steps-V1.0.safetensors
│ ├── 📂 vae/
│ │ └── qwen_image_vae.safetensors
│ └── 📂 text_encoders/
│ └── qwen_2.5_vl_7b_fp8_scaled.safetensors
3.3 按步驟完成工作流
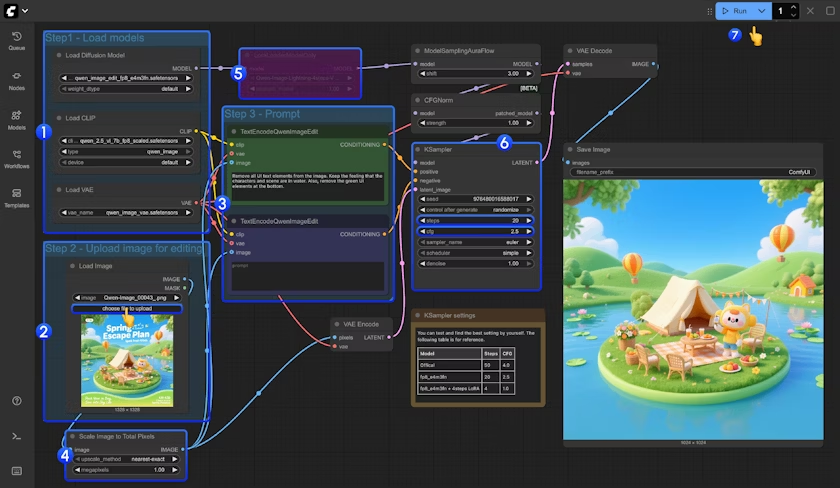
- 模型加載
- 確保
Load Diffusion Model節點加載了qwen_image_edit_fp8_e4m3fn.safetensors - 確保
Load CLIP節點中加載了qwen_2.5_vl_7b_fp8_scaled.safetensors - 確保
Load VAE節點中加載了qwen_image_vae.safetensors
- 確保
- 圖片加載
- 確保
Load Image節點中上傳了用于編輯的圖片
- 確保
- 提示詞設置
- 在
CLIP Text Encoder節點中設置好提示詞
- 在
- Scale Image to Total Pixels 節點會將你輸入圖片縮放到總像素為 一百萬像素,
- 主要是避免輸入圖片尺寸過大如 2048x2048 導致的輸出圖像質量損失問題
- 如果你很了解你輸入的圖片尺寸,你可以使用
Ctrl+B繞過這個節點
- 如果你要使用 4 步 Lighting LoRA 來實現圖片生成的提速,你可以選中
LoraLoaderModelOnly節點,然后按Ctrl+B啟用該節點 - 對于 Ksampler 節點的
steps和cfg設置,我們在節點下方增加了一個筆記,你可以測試一下最佳的參數設置 - 點擊
Queue按鈕,或者使用快捷鍵Ctrl(cmd) + Enter(回車)來運行工作流

)



---檢測B樣條軌跡的障礙物進入點與退出點)
、POST(帶請求頭)、下載文件、上傳文件等)

——Gemini Live API:實時音視頻連接)



)






