Apache Hadoop YARN(Yet Another Resource Negotiator)是Hadoop生態系統中的核心資源管理框架,通過解耦資源管理和任務調度,提供了一個通用的分布式計算資源調度平臺,使Hadoop從單一的MapReduce框架演進為支持多種計算模式的生態系統。YARN作為Hadoop 2.0版本引入的革命性設計,不僅提高了集群資源利用率,還支持多租戶共享和多種計算框架共存,成為現代大數據處理的基礎架構。本文將從YARN的基本概念、架構設計、工作流程、關鍵特性、與同類產品的對比以及實際應用場景等方面進行深入解析,幫助技術開發人員全面理解這一分布式資源管理平臺。

一、YARN的基本概念與核心功能
YARN是Apache Hadoop生態系統中的資源管理器,全稱為"Yet Another Resource Negotiator"(另一種資源協調者)。作為Hadoop 2.0的核心組件,YARN重新設計了Hadoop的資源管理架構,將原本由MapReduce框架獨占的資源管理功能獨立出來,為各種計算框架提供統一的資源調度服務。YARN的核心功能包括資源抽象、動態資源分配、任務調度與監控、多租戶支持等,其設計目標是提高集群資源利用率,支持多種計算模式,以及簡化系統設計。
YARN在Hadoop生態系統中的定位非常關鍵。在Hadoop 1.0版本中,資源管理與任務調度功能被集成在MapReduce框架的JobTracker組件中,導致擴展性差,難以支持新計算框架。YARN作為獨立的資源管理平臺,位于HDFS(分布式文件系統)和各種計算框架(如MapReduce、Spark等)之間,通過標準化的資源抽象機制,使不同計算框架能夠共享集群資源。這種設計使Hadoop從單一的HDFS+MapReduce模式轉變為開放、多元化的生態系統,支持批處理、流處理、交互式查詢等多種計算場景 。
YARN的引入為集群帶來了三大核心優勢:首先,提高了資源利用率,通過動態資源分配機制,避免了資源的靜態劃分和浪費;其次,增強了系統擴展性,允許用戶根據需求添加新的計算框架,而無需修改底層資源管理邏輯;最后,支持多租戶共享集群,通過隊列管理和資源隔離機制,確保不同團隊或應用能夠公平共享集群資源。這些優勢使YARN成為現代大數據處理平臺不可或缺的組成部分。
二、YARN的誕生背景與MapReduce 1.0的局限性
YARN的誕生源于對Hadoop 1.0版本中MapReduce框架局限性的深刻認識。在Hadoop 1.0時代,MapReduce是唯一支持的大數據處理框架,其JobTracker組件同時承擔了資源管理和任務調度兩大職責,導致系統在規模擴展和功能靈活性方面存在嚴重不足 。
MapReduce 1.0的局限性主要體現在以下幾個方面:
首先,資源管理與任務調度的耦合導致系統擴展性差。JobTracker作為單一節點,負責整個集群的資源監控和任務分配,隨著集群規模擴大,JobTracker成為性能瓶頸,難以支持數千節點的大規模集群。此外,JobTracker的故障會導致整個集群不可用,缺乏高可用性。
其次,資源抽象粒度粗。MapReduce 1.0采用靜態的槽位(slot)劃分資源,每個槽位固定為CPU和內存的組合,無法根據應用需求動態調整資源分配。這種設計導致資源利用率低,特別是當不同應用對資源需求不同時。
第三,任務調度策略單一。MapReduce 1.0僅支持FIFO(先進先出)調度策略,無法滿足多租戶、混合負載場景下的資源公平分配需求。隨著大數據應用場景的多樣化,需要更靈活的調度策略來平衡不同應用的資源需求。
最后,功能受限于MapReduce模型。MapReduce的"分而治之"思想雖然適合批處理場景,但在流處理、迭代計算等新興場景下表現不佳。隨著Spark、Flink等新計算框架的出現,Hadoop生態系統需要一個更通用的資源管理平臺來支持這些框架。
正是基于以上局限性,Apache社區決定重新設計Hadoop的資源管理架構,將資源管理與任務調度分離,從而誕生了YARN。YARN的出現不僅解決了MapReduce 1.0的架構問題,還為Hadoop生態系統的擴展奠定了基礎,使Hadoop能夠適應更廣泛的大數據應用場景。
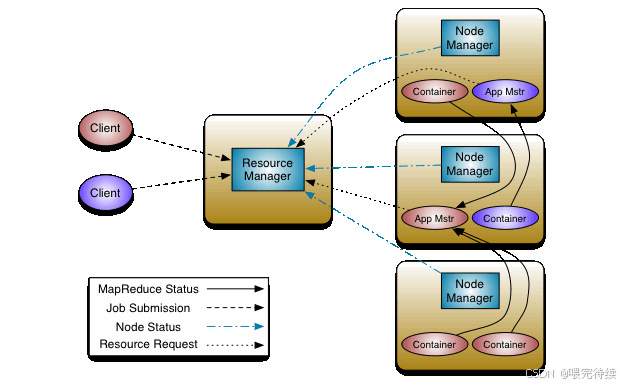
三、YARN的架構設計與組件職責
YARN采用主從(Master-Slave)架構,主要由三個核心組件構成:ResourceManager(RM)、NodeManager(NM)和ApplicationMaster(AM)。這種分層架構設計實現了資源管理與任務調度的分離,使YARN成為一個通用的資源調度平臺。
1. 資源管理器(ResourceManager)
ResourceManager是YARN的全局資源管理器,運行在集群的主節點上,負責整個集群的資源監控和分配。RM主要由兩個子組件構成:
調度器(Scheduler):負責根據應用程序的資源需求和集群資源情況,將資源分配給各個應用程序。調度器不負責應用程序任務的監控和狀態反饋,只關注資源分配。
應用程序管理器(Applications Manager,ASM):負責接收用戶提交的應用程序,啟動應用程序的ApplicationMaster,并監督其運行狀態。當AM失敗時,ASM會提供重啟服務。
調度器是YARN的核心組件,支持多種調度策略,包括FIFO Scheduler(先進先出)、Capacity Scheduler(容量調度)和Fair Scheduler(公平調度)。其中,Capacity Scheduler通過隊列劃分資源,保證不同團隊或應用的資源隔離;Fair Scheduler則動態平衡資源,確保所有應用程序公平共享資源。用戶可以根據需求選擇合適的調度器,或實現自定義調度器 。
2. 節點管理器(NodeManager)
NodeManager是每個工作節點上的資源和任務管理代理,負責管理本節點上的資源(CPU、內存等)。NM的主要職責包括:
資源匯報:定期向RM發送心跳,匯報本節點的可用資源和已分配資源的使用情況。
Container生命周期管理:根據AM的請求,啟動或停止Container,并監控其運行狀態。
任務執行環境配置:為每個任務配置運行環境(如環境變量、JAR包、二進制程序等)。
NodeManager通過心跳機制與RM保持通信,心跳頻率通常為幾秒鐘一次,確保RM能夠及時了解集群狀態變化 。當NM檢測到節點故障或資源不足時,會向RM發送相應信號,觸發資源重新分配。
3. 應用程序管理器(ApplicationMaster)
ApplicationMaster是用戶應用程序的專屬協調者,由每個應用程序在提交時創建,負責協調應用程序的資源請求、任務分配和監控。AM的主要職責包括:
資源協商:向RM申請資源(以Container形式表示),并根據應用程序需求動態調整資源請求。
任務分配:將獲得的資源進一步分配給應用程序內部的各個任務,決定任務的執行位置和方式。
任務監控:與NM協作啟動任務,并監控任務運行狀態,當任務失敗時重新申請資源重啟任務。
進度與狀態匯報:向客戶端匯報應用程序的進度和狀態,客戶端通過與AM交互獲取詳細信息。
YARN的架構設計采用了雙層調度機制 :第一層由RM的調度器負責將資源分配給應用程序;第二層由AM負責將獲得的資源分配給應用程序內部的具體任務 。這種設計使YARN能夠同時支持全局資源管理和應用級任務調度,提高了系統的靈活性和可擴展性。
下表詳細列出了YARN三大組件的職責與通信關系:
| 組件 | 主要職責 | 通信對象 | 通信協議 |
|---|---|---|---|
| ResourceManager | 全局資源監控與分配 接收應用程序提交 啟動ApplicationMaster | NodeManager ApplicationMaster | ResourceTracker ApplicationMasterProtocol |
| NodeManager | 資源匯報 Container生命周期管理 任務執行環境配置 | ResourceManager | ResourceTracker |
| ApplicationMaster | 應用程序資源協商 任務分配與監控 進度與狀態匯報 | ResourceManager<br NodeManager | ApplicationMasterProtocol ContainerManagementProtocol |
4. 資源抽象機制:Container
YARN的核心資源抽象是Container,它封裝了某個節點上的多維度資源,如內存、CPU等。與MapReduce 1.0中的固定槽位不同,YARN的Container是動態資源劃分單位,可以根據應用程序的需求靈活調整資源量。當AM向RM申請資源時,RM返回的資源即以Container形式表示,每個任務只能使用其Container中描述的資源。
Container包含以下關鍵信息:
優先級:任務的執行優先級 。
期望節點:任務希望運行的節點 。
資源量:所需的CPU和內存資源 。
Container數目:所需的Container數量。
是否松弛本地性:是否接受非本地數據的Container 。
YARN通過Linux Cgroups實現資源隔離,確保不同應用程序和任務之間的資源使用不會互相干擾。Cgroups提供了一種輕量級的資源隔離機制,可以限制應用程序對CPU、內存等資源的使用。
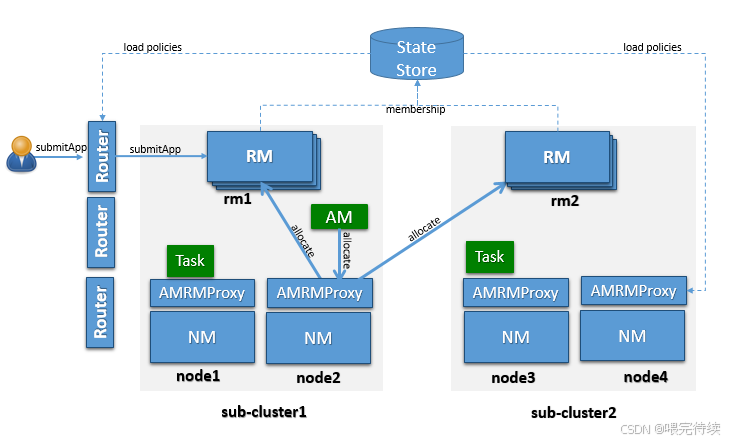
四、YARN解決的核心問題與工作流程
YARN解決了Hadoop 1.0版本中MapReduce框架面臨的幾個核心問題:
1. 資源管理與任務調度的耦合
YARN將資源管理與任務調度分離,RM專注于全局資源分配,AM專注于應用級任務調度。這種分離使系統能夠獨立優化資源管理和任務調度邏輯,提高了系統的靈活性和可擴展性。
2. 資源利用率低
通過動態資源分配機制,YARN能夠根據應用程序的需求靈活分配資源,避免了MapReduce 1.0中槽位固定導致的資源浪費。YARN的Container機制允許應用程序按需申請資源 ,提高了集群的整體資源利用率。
3. 功能受限于單一計算框架
YARN提供了通用的資源調度接口,使各種計算框架(如MapReduce、Spark、Flink等)能夠共享集群資源。這種設計使Hadoop生態系統能夠擴展到支持多種計算模式,滿足不同應用場景的需求。
4. 多租戶支持不足
YARN通過隊列管理和資源隔離機制,支持多租戶共享集群,確保不同團隊或應用能夠公平使用集群資源。用戶可以根據需求配置不同的隊列,為不同團隊或應用分配特定的資源配額和優先級。
YARN的工作流程可以分為以下幾個主要階段:
應用程序提交:用戶將應用程序提交到YARN,其中包括用戶程序、啟動AM的命令等內容 。
啟動ApplicationMaster:ResourceManager為該應用程序分配第一個Container,并與對應的NodeManager通信,要求其啟動應用程序的AM 。
資源申請與分配:AM向RM注冊后,開始為應用程序的各個任務申請資源。AM采用輪詢的方式,通過RPC協議向RM申請和領取資源 。
任務執行與監控:當AM申請到資源后,會與對應的NM通信,要求其啟動任務 。NM為任務配置運行環境后,將任務啟動命令寫入腳本并執行 。任務運行過程中,定期向AM匯報狀態和進度,以便AM監控任務執行情況并處理失敗任務 。
應用程序完成:當應用程序的所有任務完成后,AM向RM申請注銷并關閉自己,釋放占用的資源 。
YARN采用拉式(pull-based)通信模型,資源分配過程是異步的。RM調度器將資源分配給應用程序后,不會立即推送給對應的AM,而是暫時放到緩沖區,等待AM通過周期性的心跳來取 。這種設計減少了RM的負載,提高了系統的可擴展性。
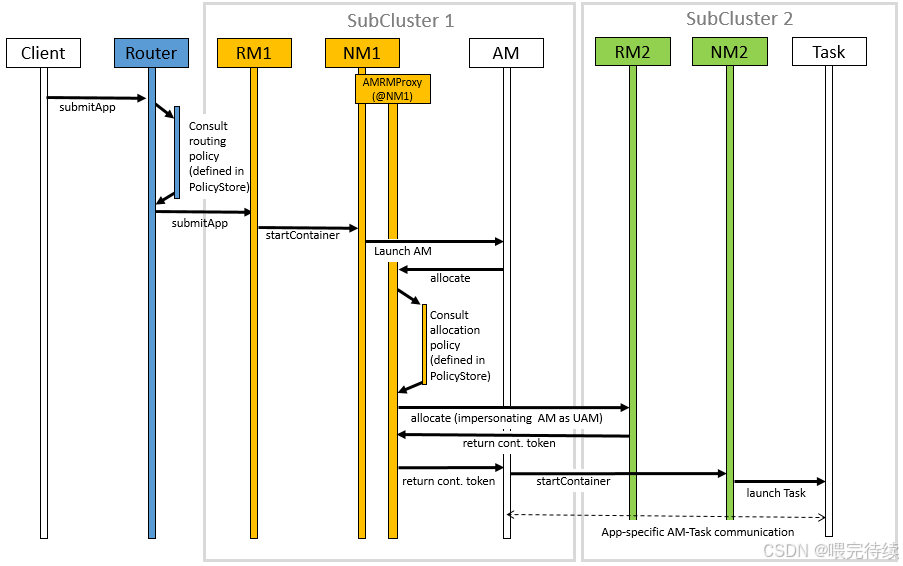
五、YARN的關鍵特性與優勢
YARN作為Hadoop 2.0的核心資源管理框架,具有以下關鍵特性與優勢:
1. 高吞吐量資源調度
YARN可以每秒調度超過1000個容器,適合處理大規模數據集和高并發任務。這種高性能調度能力使YARN能夠快速響應應用程序的資源需求,減少任務等待時間,提高整體系統吞吐量。
2. 動態資源分配
YARN支持兩種資源請求模式:靜態模式和動態模式 。靜態模式適用于資源需求在應用程序提交時確定的場景;動態模式則允許應用程序在運行時根據實際需求調整資源請求,提高了資源使用的靈活性和效率 。
3. 多框架支持
YARN為各種計算框架提供統一的資源調度服務,包括MapReduce、Spark、Flink、Hive等。這種設計使用戶可以在同一集群上運行多種計算框架,避免了為每種框架單獨維護集群的開銷,提高了資源利用率和系統管理效率。
4. 層級隊列管理
YARN原生支持層級隊列管理,用戶可以根據組織結構或業務需求創建多級隊列,并為每個隊列分配特定的資源配額和優先級。這種設計使YARN能夠支持多租戶共享集群 ,確保不同團隊或應用能夠公平使用集群資源,同時可以根據業務需求進行資源優先級調整。
5. 資源彈性擴展
YARN支持資源彈性擴展,允許應用程序在運行過程中動態調整資源需求 。當應用程序需要更多資源時,AM可以向RM申請額外的Container;當資源過剩時,應用程序可以釋放多余的資源,供其他應用使用。這種彈性設計提高了資源利用率,減少了資源浪費。
6. 支持混合負載
YARN能夠同時處理批處理、流處理、交互式查詢等多種類型的計算任務,使集群能夠應對復雜的混合負載場景。通過合理配置調度策略和隊列,用戶可以確保不同負載類型之間的資源公平分配,提高集群的整體利用率。
7. 高可用性設計
YARN支持高可用性(HA)模式,通過主備RM和ZooKeeper協調,避免了單點故障問題 。當主RM故障時,備用RM可以快速接管,確保集群的持續可用性,提高了系統的可靠性和穩定性。
8. 安全認證機制
YARN支持多種安全認證機制,包括Kerberos、SASL消化-MD5認證等 。這些機制確保了組件之間的安全通信,防止未授權訪問和惡意操作,提高了系統的安全性。
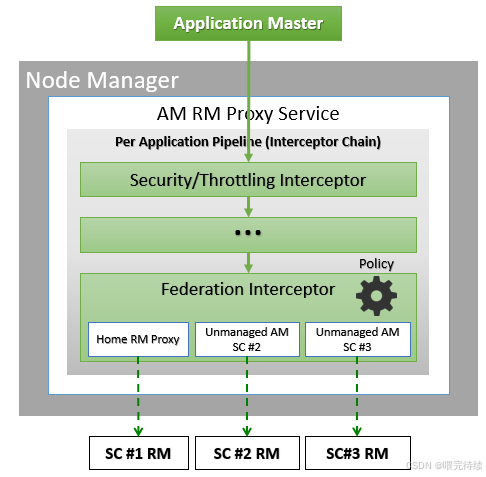
六、YARN與同類產品的對比
YARN作為分布式資源管理平臺,與Kubernetes、Mesos等產品有相似之處,但也存在顯著差異。這些差異主要源于設計目標、適用場景和架構設計的不同。
1. YARN與Kubernetes對比
YARN和Kubernetes都是分布式資源管理平臺,但它們的設計目標和適用場景有所不同:
設計目標:YARN專注于大數據處理場景,優化了對數據密集型應用的支持;Kubernetes則專注于容器編排,優化了對微服務和云原生應用的支持。
調度性能:YARN可以每秒調度超過1000個容器,適合處理大規模數據集和高并發任務;Kubernetes因依賴etcd存儲大量數據,調度性能受限,每秒只能調度約100個容器。
資源管理粒度:YARN以Container為單位管理資源,支持CPU和內存的動態分配;Kubernetes以Pod為單位管理資源,支持更細粒度的資源類型(如GPU顯存)。
隊列管理:YARN原生支持層級隊列管理,適合多租戶共享集群;Kubernetes需要依賴第三方工具(如YuniKorn)實現類似功能。
生態集成:YARN深度集成Hadoop生態系統(如HDFS、Spark、Hive等),為這些框架提供無縫的資源調度支持 ;Kubernetes則需要這些框架進行額外適配才能在Kubernetes上運行。
2. YARN與Mesos對比
YARN和Mesos都是通用的分布式資源管理平臺,但它們的架構和調度策略有所不同:
架構設計:YARN采用雙層調度架構(全局RM調度+應用級AM調度),調度決策集中在RM;Mesos采用雙層調度架構(資源調度器+框架調度器),資源調度器僅將可用資源推送給各個框架,由框架決定是否接受和使用這些資源。
資源分配模式:YARN采用拉式模式,應用程序主動向RM申請資源;Mesos采用推式模式,資源調度器將資源推送給各個框架,由框架決定是否接受。
資源隔離機制:YARN依賴Linux Cgroups實現資源隔離;Mesos支持更細粒度的資源類型(如GPU顯存),但資源隔離機制相對簡單。
調度策略:YARN支持多種調度策略(如FIFO、Capacity、Fair),用戶可以根據需求選擇或實現自定義調度器;Mesos的調度策略相對固定,用戶需要通過框架調度器實現自定義邏輯。
生態集成:YARN深度集成Hadoop生態系統,為這些框架提供優化的資源調度支持 ;Mesos則需要這些框架進行額外適配才能在Mesos上運行。
3. YARN與Slurm對比
YARN和Slurm都是集群資源管理系統,但它們的適用場景和設計重點有所不同:
適用場景:YARN專注于大數據處理和分布式計算場景;Slurm則專注于高性能計算(HPC)場景,優化了對計算密集型任務的支持。
資源管理粒度:YARN以Container為單位管理資源,適合處理大規模數據集和高并發任務;Slurm以作業為單位管理資源,適合處理長時間運行的計算密集型任務。
調度策略:YARN支持多種調度策略,適合處理混合負載場景;Slurm專注于優化作業調度,適合處理單一批次的計算任務。
生態集成:YARN深度集成Hadoop生態系統,為這些框架提供資源調度支持;Slurm則與HPC生態系統集成緊密,適合處理科學計算和工程模擬等任務。
YARN在大數據處理領域具有明顯優勢,其高性能調度、層級隊列管理和對Hadoop生態系統的深度集成使其成為數據工程領域的首選。然而,對于需要細粒度GPU資源管理或長期運行的應用,Kubernetes可能更具優勢。用戶可以根據具體應用場景和需求選擇合適的資源管理平臺。
七、YARN的資源抽象與擴展能力
YARN的資源抽象機制是其靈活性和可擴展性的關鍵。YARN將物理資源抽象為邏輯資源單位(Container) ,允許應用程序根據需求動態申請和釋放資源。這種設計使YARN能夠適應不同計算框架的需求,提高集群資源利用率。
1. 資源類型支持
YARN的核心資源抽象是Container,它封裝了某個節點上的多維度資源。在YARN的早期版本中,主要支持內存和CPU兩種資源類型,這是數據密集型應用的主要資源需求。隨著Hadoop 3.0版本的發布,YARN開始支持GPU和FPGA等異構計算資源 。
然而,YARN對GPU等異構資源的支持仍然存在局限性:
粗粒度分配:YARN將GPU作為整塊設備分配給應用程序,無法實現同一GPU上多個任務的共享 。這種設計雖然簡單,但可能導致資源浪費,特別是在處理中小型GPU任務時。
依賴第三方工具:由于CUDA在Java語言方面的不足,YARN需要依賴第三方監視框架來監控GPU的使用狀況 。
資源隔離機制:YARN通過Linux Cgroups對GPU進行限制,也支持通過Docker進行資源限制 。這種設計雖然能夠實現基本的資源隔離,但不如Kubernetes的容器化隔離機制靈活。
2. 資源模型的雙重表示
為了更好地管理異構資源,YARN采用了資源模型的雙重表示機制 :
實際資源狀態:表示集群中實際在用的資源狀態,由各節點的資源匯報進程匯總得出。
邏輯資源狀態:表示應用程序所需最小資源的總和,作為任務調度的標準 。
這種設計使YARN能夠在資源彈性分配的情況下,更合理地判斷隊列是否能夠滿足新任務的需求,避免資源過度分配或不足的問題 。
3. 擴展能力與未來方向
YARN的架構設計使其具有良好的擴展能力:
可插拔調度器:用戶可以根據需求實現自定義調度器,只需繼承AbstractYarnScheduler抽象類并實現調度器接口規范 。
事件驅動模型:RM調度器采用事件驅動的編程模型,處理多種類型的事件(如NODE_REMOVED、NODE_ADDED、APPLICATION_ADDED等),通過狀態機管理資源狀態 。
標簽化資源管理:YARN支持通過物理標注方法,為掛載不同計算資源的機器打上不同的標簽,并依據標簽將集群劃分為不同的邏輯集群 。例如,可以為沒有計算加速部件的節點打上normal標簽,為帶有GPU的節點打上gpu標簽。
YARN的未來發展方向包括對GPU等異構資源的細粒度管理 ,以及與容器技術(如Docker)的更深度集成。目前,學術界對GPU資源的細粒度管理已有研究,包括時間分片(多個Kernel函數依次共享計算資源)和空間分片(將GPU按照流多處理器粒度進行調度)兩種方式 。這些研究為YARN的資源管理能力提供了潛在的改進方向。
八、YARN的實際應用場景
YARN的通用性和高性能使其適用于多種大數據處理場景。以下是YARN的幾個典型應用場景:
1. 混合負載集群
YARN能夠同時處理批處理、流處理、交互式查詢等多種類型的計算任務,使集群能夠應對復雜的混合負載場景。例如,一個企業可以在同一YARN集群上同時運行MapReduce批處理作業、Spark Streaming流處理任務和Hive交互式查詢,根據業務需求動態調整資源分配。
2. GPU加速的大數據任務
隨著深度學習和機器學習的普及,YARN支持GPU資源分配,為需要GPU加速的數據處理任務提供支持 。雖然YARN對GPU的支持是粗粒度的,但通過節點標簽劃分和資源隔離機制,可以確保GPU資源的合理使用。例如,可以將帶有GPU的節點劃分為一個邏輯集群,專門處理需要GPU加速的任務。
3. 企業級多租戶環境
YARN的層級隊列管理和資源隔離機制使其非常適合企業級多租戶環境 。企業可以根據部門或團隊創建多級隊列,并為每個隊列分配特定的資源配額和優先級。這種設計確保了不同團隊或應用能夠公平使用集群資源,同時可以根據業務需求進行資源優先級調整。
4. 流數據處理
YARN為流數據處理框架(如Storm、Flink)提供了資源調度支持。通過動態資源調度和容器管理,YARN可以有效支持需要彈性資源的流數據處理任務 。例如,可以設計基于實時負載的動態資源調度模型,根據流數據處理的延遲情況實時調整集群資源分布,有效減小系統延遲。
5. 分布式機器學習
YARN支持分布式機器學習框架(如Spark MLlib、TensorFlow on YARN)的資源調度。通過為機器學習任務分配足夠的內存和CPU資源,YARN可以加速模型訓練和推理過程。可以為大規模數據集的機器學習任務分配更多的內存資源,提高模型訓練效率。
九、YARN的使用方法與最佳實踐
YARN提供了多種使用方式,包括命令行工具、Java API和REST API等。以下是YARN的使用方法和最佳實踐:
1. 基本命令行操作
YARN提供了豐富的命令行工具,用戶可以通過以下命令查看YARN用法和幫助:
yarn --help常用的YARN命令包括:
yarn top:列出當前正在運行的YARN應用程序及其狀態。
yarn application -list:顯示所有應用程序的詳細信息。
yarn application -kill <application-id>:終止指定的應用程序。
yarn application -status <application-id>:查看指定應用程序的運行狀態。
yarn logs -application-id <application-id>:獲取應用程序的聚合日志。
2. 提交應用程序
用戶可以通過命令行提交應用程序到YARN集群:
配置和啟動 HDFS 和 YARN 組件
<property><description>Enable services rest api on ResourceManager.</description><name>yarn.webapp.api-service.enable</name><value>true</value>
</property>示例服務
{"name": "sleeper-service","version": "1.0","components" : [{"name": "sleeper","number_of_containers": 1,"launch_command": "sleep 900000","resource": {"cpus": 1, "memory": "256"}}]
}可以使用以下命令在 YARN 上簡單地運行預構建的示例服務:
yarn app -launch <service-name> <example-name>
yarn app -launch my-sleeper sleeper提交一個MapReduce作業:
yarn jar /path/to/example.jar org.apache.hadoop mapreduce.example WordCount /input/path /output/path3. 配置與調優
YARN的性能和行為可以通過配置文件進行調優。主要的配置文件包括:
yarn-site.xml:定義YARN的全局配置參數。
mapred-site.xml:定義MapReduce應用程序的配置參數。
capacity-scheduler.xml:配置Capacity Scheduler的隊列和資源分配策略。
<!-- yarn-site.xml核心配置 -->?
<property>?<name>yarn.resourcemanager.hostname</name>?<value>rm-host</value> <!-- ResourceManager主機名 -->?
</property>?
<property>?<name>yarn.nodemanager.resource.memory-mb</name>?<value>8192</value> <!-- 每個節點可用內存(MB) -->?
</property>?
<property>?<name>yarn.nodemanager.resource.cpu-vcores</name>?<value>4</value> <!-- 每個節點可用CPU核心數 -->?
</property>YARN的調優主要集中在資源分配策略、隊列配置和容器大小設置等方面 。用戶可以根據應用程序的特點和集群規模,調整這些參數以優化YARN的性能。
4. 安全配置
YARN支持多種安全認證機制,包括Kerberos、SASL消化-MD5認證等 。用戶可以通過配置yarn-site.xml中的相關參數啟用這些安全機制,確保YARN集群的安全性。
5. 監控與診斷
YARN提供了多種監控和診斷工具,幫助用戶了解集群狀態和應用程序性能:
YARN Web UI:提供圖形化界面,顯示集群狀態、應用程序列表和詳細信息。
YARN REST API:允許用戶通過編程方式獲取集群狀態和應用程序信息。
日志聚合功能:聚合工作節點上所有容器的日志,存儲在默認文件系統中,便于問題排查。
資源監控工具:如Ganglia、Prometheus等,可以監控YARN集群的資源使用情況。
YARN的監控與診斷是確保集群高效運行的關鍵。用戶應該定期檢查集群狀態,分析應用程序性能,及時發現和解決潛在問題。
十、YARN的局限性與發展趨勢
盡管YARN在大數據處理領域表現出色,但仍存在一些局限性:
1. 局限性
不支持低延遲任務:YARN的調度策略對實時計算(如低延遲流處理)支持較弱,任務調度延遲較高。
資源隔離依賴Container:YARN的資源隔離機制(Cgroups)雖然有效,但不如容器技術(如Docker)靈活,特別是在處理非Hadoop生態系統的應用時。
GPU資源管理粗粒度:YARN對GPU等異構資源的支持是粗粒度的,無法實現同一GPU上多個任務的共享,可能導致資源浪費 。
生態局限性:YARN深度集成Hadoop生態系統,但對非Hadoop生態系統的應用支持相對有限。
2. 發展趨勢
細粒度資源管理:未來YARN可能會支持更細粒度的資源管理,如GPU顯存、FPGA資源等,提高資源利用率 。
與容器技術的深度集成:YARN可能會與Docker等容器技術更深度集成,提供更靈活的應用部署和資源隔離機制。
混合云支持:YARN可能會增強對混合云環境的支持,允許應用程序在跨云集群上運行和調度。
智能化調度:YARN可能會引入更多智能化調度算法,如基于機器學習的資源預測和動態調整,提高集群的整體性能和利用率。
YARN作為Hadoop生態系統的資源管理平臺,將繼續演進以適應不斷變化的大數據處理需求。隨著Hadoop生態系統的擴展和云原生技術的發展,YARN可能會在保持其核心優勢的同時,增強對異構資源和新應用場景的支持,進一步鞏固其在數據工程領域的地位。
十一、總結與展望
Apache Hadoop YARN作為分布式資源管理平臺,通過解耦資源管理和任務調度,提供了一個通用的資源調度框架,使Hadoop生態系統能夠支持多種計算模式,滿足不同應用場景的需求。YARN的核心優勢在于其高性能調度、層級隊列管理和對Hadoop生態系統的深度集成,使其成為數據工程領域的首選資源管理平臺。
在實際應用中,YARN能夠有效支持混合負載集群、GPU加速的大數據任務、企業級多租戶環境等多種場景,提高了集群資源利用率和系統整體性能。然而,YARN在低延遲任務支持、資源隔離機制和異構資源管理方面仍存在局限性,需要進一步優化和擴展。
隨著大數據技術的發展和云原生架構的普及,YARN可能會在以下幾個方向繼續演進:
首先,YARN可能會增強對GPU等異構資源的支持 ,實現細粒度資源管理和共享,提高資源利用率。其次,YARN可能會與容器技術(如Docker)更深度集成,提供更靈活的應用部署和資源隔離機制。最后,YARN可能會引入更多智能化調度算法,如基于機器學習的資源預測和動態調整,提高集群的整體性能和利用率。
對于技術開發人員來說,深入理解YARN的架構設計、工作流程和關鍵特性,不僅有助于更好地利用YARN平臺,還能為構建更高效的分布式計算系統提供有價值的參考。隨著YARN的不斷演進,它將繼續在大數據處理領域發揮重要作用,成為連接數據存儲(如HDFS)和計算框架(如Spark、Flink)的橋梁,推動大數據技術的發展和應用。

 支持已上線 JetBrains、Eclipse 和 Xcode)

)



框架 - Peewee 入門教程)


)






)

