論文題目:Visual Point Cloud Forecasting enables Scalable Autonomous Driving(視覺點云預測實現可擴展的自動駕駛)
會議:CVPR2024
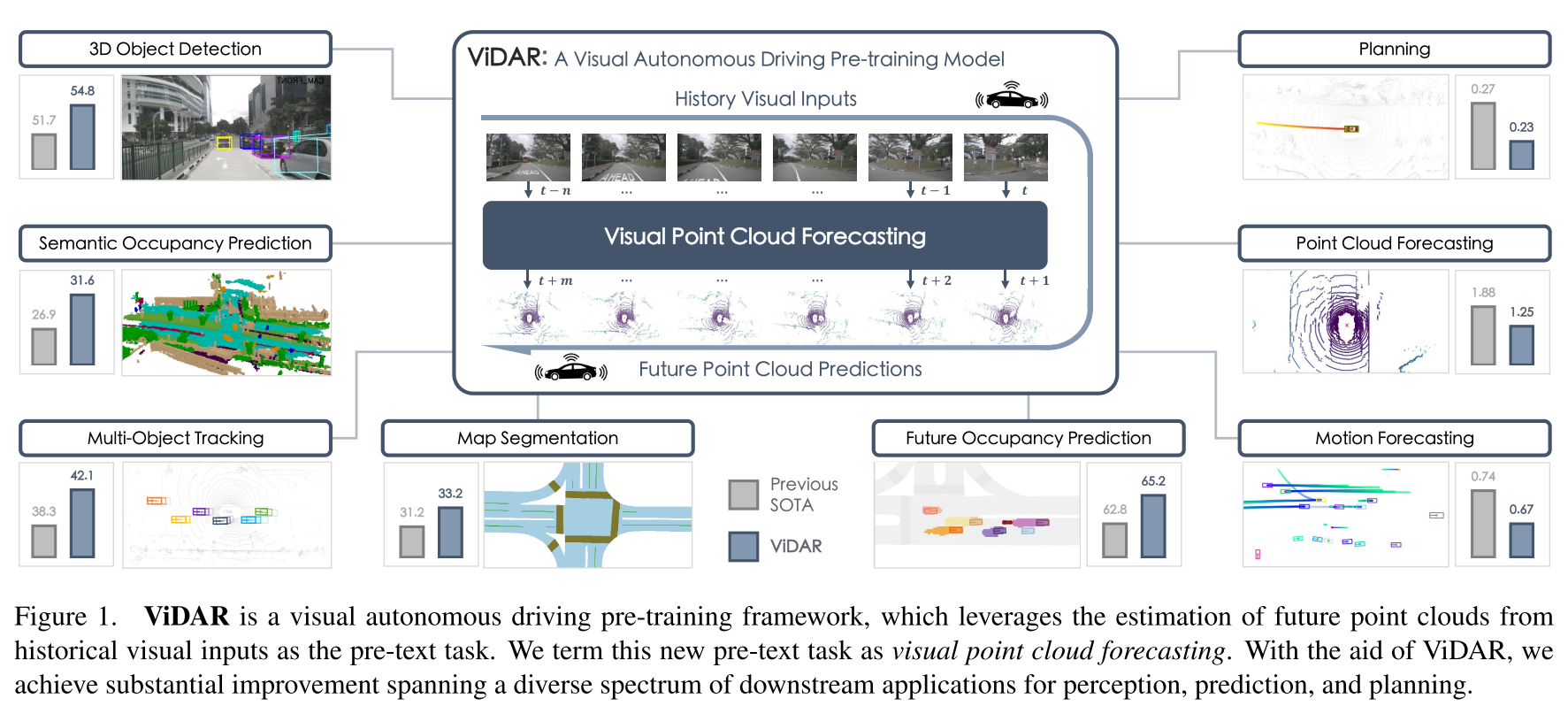
摘要:與對通用視覺的廣泛研究相比,可擴展視覺自動駕駛的預訓練很少被探索。視覺自動駕駛應用需要同時包含語義、3D幾何和時間信息的功能,以進行聯合感知、預測和規劃,這對預訓練提出了巨大的挑戰。為了解決這個問題,我們提出了一種新的預訓練任務,稱為視覺點云預測-從歷史視覺輸入預測未來的點云。該任務的關鍵優點是捕獲語義,3D結構和時間動態的協同學習。因此,它在各種下游任務中顯示出優勢。為了解決這個新問題,我們提出了一種通用的預訓練下游視覺編碼器的模型ViDAR。它首先通過編碼器提取歷史嵌入。然后通過一種新的潛在渲染算子將這些表示轉換為3D幾何空間,用于未來的點云預測。實驗表明,在下游任務中有顯著的增益,例如,3D檢測的NDS降低3.1%,運動預測的誤差降低~ 10%,規劃的碰撞率降低~ 15%。
源碼鏈接:https://github.com/OpenDriveLab/ViDAR
前言
自動駕駛技術正在快速發展,但面臨著一個關鍵挑戰:如何在減少對昂貴3D標注依賴的同時,訓練出既能感知環境、又能預測未來、還能做出安全規劃決策的智能系統?
背景:自動駕駛預訓練的困境
現有方法的局限性
在計算機視覺領域,預訓練已經取得了巨大成功,但在視覺自動駕駛領域卻面臨獨特挑戰:
- 多維度需求:自動駕駛系統需要同時理解語義信息(這是什么)、3D幾何結構(在哪里)和時序動態(如何運動)
- 數據標注昂貴:3D邊界框、占用網格、軌跡等標注成本極高,難以大規模獲取
- 時序建模缺失:現有預訓練方法如深度估計僅處理單幀,缺乏時序信息
傳統預訓練方法對比
| 方法 | 多視圖幾何 | 時序建模 | 標注需求 |
|---|---|---|---|
| 深度估計 | ? | ? | 中等 |
| 場景渲染 | ? | ? | 中等 |
| ViDAR | ? | ? | 極低 |
ViDAR:創新的解決方案
核心思想:視覺點云預測
ViDAR的核心創新在于提出了一個全新的預訓練任務——視覺點云預測:
給定歷史的多視圖圖像序列,預測未來的3D點云
這個看似簡單的任務實際上非常巧妙:
- 語義理解:需要識別場景中的物體和結構
- 3D幾何建模:需要理解物體的三維空間關系
- 時序動態學習:需要建模物體的運動模式
系統架構詳解
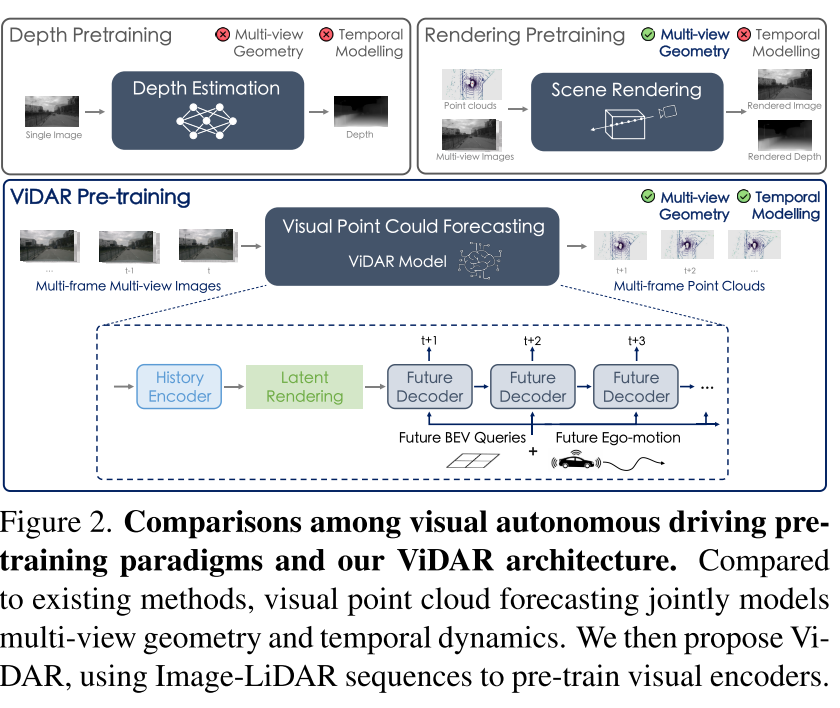
ViDAR包含三個核心組件:
1. History Encoder(歷史編碼器)
- 這是預訓練的目標結構
- 可以是任何視覺BEV編碼器(如BEVFormer)
- 將多視圖圖像序列編碼為BEV特征
2. Latent Rendering(潛在渲染算子)
這是ViDAR最關鍵的創新組件,解決了一個重要問題:
問題:直接使用可微光線投射會導致"射線形狀特征"——同一射線上的網格趨向于學習相似特征,缺乏判別性。
解決方案:
特征期望函數:F?(i) = Σ p?(i,k) * F(k)_bev
幾何特征計算:F?_bev = p? · F?
通過條件概率函數為每個網格分配權重,確保學習到有判別性的幾何特征。
3. Future Decoder(未來解碼器)
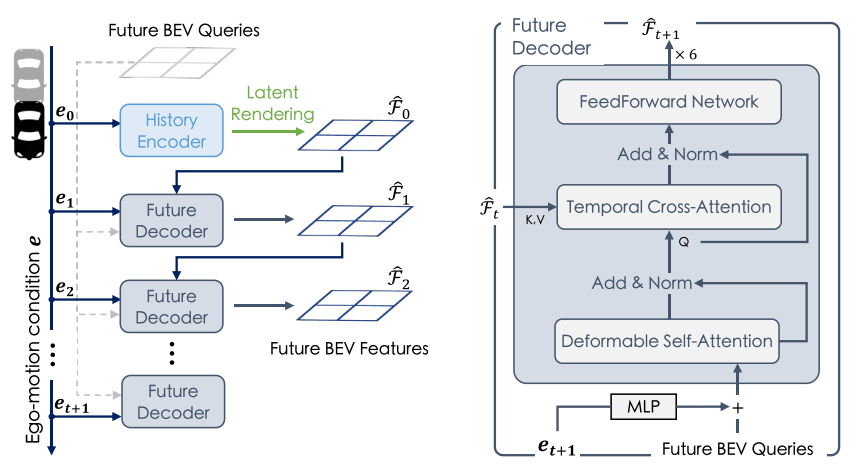
- 基于Transformer的自回歸架構
- 包含時序交叉注意力機制
- 處理自車運動導致的坐標系變化
技術深度解析
Latent Rendering的數學原理

傳統的可微光線投射使用以下公式:
條件概率:p?(i,j) = (∏(1-p(i,k))) * p(i,j) [k=1到j-1]
距離期望:λ?(i) = Σ p?(i,j) * λ(j)
ViDAR的創新在于在潛在空間中進行類似操作:
特征期望:F?(i) = Σ p?(i,k) * F(k)_bev
權重分配:F?_bev = p? · F?
這種設計使得模型能夠:
- 避免射線形狀特征問題
- 學習更有判別性的幾何表示
- 保持3D結構的一致性
多組并行設計
為了增強特征多樣性,ViDAR采用了多組并行的Latent Rendering:
- 將256維特征分為16組,每組16維
- 每組獨立進行潛在渲染
- 最后拼接得到完整的幾何特征
實驗表明,隨著組數增加,性能持續提升:
| 組數 | 1 | 2 | 4 | 8 | 16 |
|---|---|---|---|---|---|
| NDS | 39.18 | 43.36 | 45.53 | 47.01 | 47.58 |
實驗結果:全面的性能提升
點云預測能力
ViDAR在點云預測任務上顯著超越現有方法:
| 時間范圍 | 4D-Occ (LiDAR) | ViDAR (視覺) | 改進 |
|---|---|---|---|
| 1s預測 | 1.88 m2 | 1.25 m2 | -33% |
| 3s預測 | 2.11 m2 | 1.73 m2 | -18% |
令人驚喜的是,僅使用視覺輸入的ViDAR竟然超越了使用LiDAR的方法!
下游任務全面提升
ViDAR在所有自動駕駛任務上都帶來了顯著提升:
感知任務
- 3D目標檢測:NDS提升3.1%,mAP提升4.3%
- 語義占用預測:mIoU提升5.2%
- 地圖分割:lane IoU提升1.9%
- 多目標跟蹤:AMOTA提升6.1%
預測任務
- 運動預測:minADE減少10.7%,minFDE減少8.3%
- 未來占用預測:近距離VPQ提升2.7%,遠距離VPQ提升2.5%
規劃任務
- 碰撞率:降低14.8%
- 規劃精度:L2誤差減少18.8%
數據效率革命
ViDAR最令人印象深刻的優勢在于大幅減少了對標注數據的依賴:
- 使用一半監督數據,ViDAR預訓練的模型仍能超越全監督基線1.7% mAP
- 隨著可用標注減少,ViDAR的優勢越來越明顯
- 在1/8數據量時,性能提升達到7.3% mAP
這意味著通過ViDAR,我們可以用一半的標注數據達到更好的性能!
技術亮點與創新
1. 統一的預訓練范式
ViDAR首次提出了能夠同時提升感知、預測和規劃的統一預訓練方法,這是端到端自動駕駛的重要突破。
2. 幾何感知的特征學習
通過Latent Rendering,ViDAR學習到的特征具有更強的3D幾何感知能力,這對自動駕駛至關重要。
3. 可擴展的數據利用
僅需Image-LiDAR序列,無需精確標注,使得大規模預訓練成為可能。
4. 即插即用的架構
ViDAR可以與任何BEV編碼器結合,具有良好的通用性。
實際應用價值
產業影響
- 降低開發成本:減少對昂貴3D標注的依賴
- 加速模型訓練:提供更好的初始化權重
- 提升系統性能:在所有關鍵任務上都有顯著提升
研究意義
- 新的預訓練范式:為視覺自動駕駛提供了新的研究方向
- 理論創新:Latent Rendering為3D視覺任務提供了新的技術路徑
- 基準設定:為未來相關研究提供了強基線
局限性與未來方向
當前局限
- 數據規模:主要在nuScenes數據集上驗證,規模相對有限
- 計算復雜度:多組Latent Rendering增加了計算開銷
- 泛化能力:跨數據集的泛化能力有待進一步驗證
未來發展
研究團隊計劃:
- 擴大預訓練數據規模
- 研究跨數據集的視覺點云預測
- 構建視覺自動駕駛的基礎模型
總結:邁向可擴展的自動駕駛
ViDAR代表了視覺自動駕駛預訓練的重大進步。通過巧妙的任務設計和技術創新,它解決了長期困擾該領域的核心問題:
? 統一建模:同時處理語義、幾何和時序信息
? 數據高效:大幅減少對標注數據的依賴
? 性能優異:在所有關鍵任務上都有顯著提升
? 可擴展性:為大規模預訓練奠定基礎
隨著自動駕駛技術的快速發展,ViDAR這樣的創新方法將為構建更安全、更智能的自動駕駛系統提供強有力的技術支撐。我們有理由相信,這一研究將推動整個行業向著更加成熟和實用的方向發展。


:總結——基于源碼分析的UGUI設計原則與性能優化策略)
















