這篇綜述全面回顧了物理信息機器學習 的原理、應用、軟件實現、理論進展與未來發展趨勢,這樣即使數據稀疏、帶噪,也能保證預測結果符合物理規律,適合解決偏微分方程正問題、反問題、非線性動力學和多物理耦合系統等科學計算場景。
作者信息:
George Em Karniadakis 12?、Ioannis G. Kevrekidis 3?、Lu Lu ?、Paris Perdikaris ?、Sifan Wang ?、Liu Yang 1
1 美國布朗大學 應用數學系
2 美國布朗大學 工程學院
3 美國約翰霍普金斯大學 化學與生物分子工程系
? 美國約翰霍普金斯大學 應用數學與統計系
? 美國麻省理工學院 數學系
? 美國賓夕法尼亞大學 機械工程與應用力學系
? 美國賓夕法尼亞大學 應用數學與計算科學研究生組
? 通訊作者郵箱:george_karniadakis@brown.edu
期刊:Nature Reviews Physics(2021)
[1] Karniadakis G E, Kevrekidis I G, Lu L, et al. Physics-informed machine learning[J]. Nature Reviews Physics, 2021, 3(6): 422-440.
1?? PINNs 方法原理
-
將 PDE 殘差通過自動微分嵌入損失函數,與觀測數據誤差一起優化
-
可以處理整數階PDE、積分-微分方程、分數階PDE、隨機PDE
-
損失函數包含:
- 數據監督項
- PDE殘差項(無監督項)
2?? 應用案例
- 4D-flow MRI 血流模擬:提高分辨率,物理約束解耦去噪,計算血管壁剪應力
- 等離子體湍流預測:部分觀測數據下重建湍流場
- 高維概率分布的亞穩態躍遷:用PINNs求committor函數
- 熱力學一致性PDE求解:提出control volume PINN (cvPINN) 替代有限體積法
- 量子化學:FermiNet 求解多電子薛定諤方程
- 材料科學:聲波無損檢測裂紋、3D打印鈦合金彈塑性性質反演
- 分子動力學:DeePMD 實現百萬原子納秒級量子精度分子動力學
- 地球物理:地震反演、多物理耦合地下流動模擬
3?? 軟件生態
-
主流庫:DeepXDE、SimNet、PyDEns、NeuralPDE、SciANN、ADCME
-
絕大多數基于 Python(少數基于 Julia)
-
多庫特點:
- solver型(用戶只需定義問題,庫自動求解)
- wrapper型(封裝TensorFlow低階接口,用戶實現詳細求解步驟)
- DeepXDE支持整數階、分數階PDE、復雜幾何
- SimNet優化GPU大規模問題
4?? 現存挑戰
- 多尺度、多物理耦合問題:高頻、劇烈梯度區域訓練困難,存在譜偏置(F-principle)
- 優化問題復雜:高階導數求解效率低,損失函數項間梯度沖突
- 樣本復雜度未知
- 數學理論基礎薄弱:偏微分方程數值解誤差理論、訓練動態、泛化誤差缺少系統化研究
- 數據集和標準基準缺乏:缺少可公開、物理模型參數齊全的大型數據集和算法評測體系
5?? 未來展望
- 數字孿生(Digital Twins):實時融合觀測數據與物理模型,輔助工程設計與預測
- 多模型、多數據融合與可解釋性:建立不同物理模型/神經網絡模型間可互換、互映射的變換關系
- 主動學習與實驗設計優化:利用潛變量空間結構,指導實驗點選取,動態提升模型性能
- 新型潛變量與空間重構:從觀測數據自動挖掘內蘊變量,構建ML驅動的“自洽時空”
- 多物理場、復雜幾何、高維動態系統的統一建模框架
文章目錄
- 引言
- 📦 Box 1 | 數據與物理場景分類
- 📦 Box 2 | 物理信息學習的基本原則
- 📦 Box 3 | 物理信息神經網絡(Physics-informed Neural Networks, PINNs)
- 將物理規律嵌入機器學習的方法
- **觀測偏置(Observational biases)**
- **歸納偏置(Inductive biases)**
- **學習偏置(Learning bias)**
- 混合方法(Hybrid approaches)
- 與核方法的聯系(Connections to kernel methods)
- 與經典數值方法的聯系(Connections to classical numerical methods)
- 物理信息學習的優勢
- 不完整模型與不完美數據
- 小樣本數據下的強泛化能力
- 理解深度學習機制
- 應對高維問題
- 不確定性量化
- 應用亮點
- 示例:意式濃縮咖啡杯上的流動
- 物理信息深度學習在 4D 流場 MRI 中的應用
- 通過部分觀測用深度學習揭示邊緣等離子體動力學
- 研究高維分布中亞穩態間的轉變
- 熱力學一致的 PINNs
- 量子化學中的應用
- 材料科學中的應用
- 分子模擬中的應用
- 地球物理中的應用
- 軟件支持
- 選擇模型、框架和算法
- 當前限制
- 多尺度與多物理問題
- 新算法與計算框架
- 數據生成與基準測試
- 新的數學理論
- 展望
- 未來方向
- 數字孿生(Digital twins)
- 數據與模型變換、融合及可解釋性
- 尋找內在變量與新興、有用的表征
全文翻譯
盡管通過偏微分方程(PDE)數值離散化方法在多物理場問題模擬方面取得了巨大進展,但現有算法仍難以無縫融入含噪數據,網格生成過程復雜,高維參數化PDE問題也難以求解。此外,求解隱含物理機制的反問題往往計算代價高昂,且需采用不同的數學建模方法和復雜的計算代碼。近年來,機器學習作為一種有前景的替代方案受到關注,但訓練深度神經網絡通常依賴于大量數據,而科學計算問題中往往難以獲得足夠的數據。
針對這一問題,可以通過在連續時空域內隨機點上強制物理規律成立,向神經網絡提供額外的信息,從而實現網絡訓練。這類物理信息學習方法將(含噪)觀測數據與數學模型相結合,通過神經網絡或其他基于核的回歸模型進行實現。此外,還可以設計專門的網絡結構,使其自動滿足部分物理不變量,以提升預測精度、加快訓練速度并改善模型泛化性能。
本文回顧了當前將物理規律嵌入機器學習模型的主流方法,總結了現有方法的優勢與局限,并探討了物理信息學習在正問題和反問題求解中的多種應用,包括物理規律挖掘與高維問題建模。
Key points
- 物理信息機器學習能夠將觀測數據與數學物理模型無縫融合,適用于部分已知、存在不確定性及高維復雜問題的建模場景。
- 基于核方法或神經網絡的回歸模型,提供了高效、簡便且無網格(meshless)的實現方案。
- **物理信息神經網絡(PINNs)**在求解不適定問題和反問題中表現出較高的有效性與計算效率,結合區域分解方法(domain decomposition)后,可擴展至大規模問題。
- 算子回歸、內稟變量與表示方法的挖掘、以及具備內建物理約束的等變神經網絡結構是未來值得關注的重要研究方向。
- 亟需構建適用于可擴展、穩健且嚴謹的下一代物理信息學習模型的新型數學理論、統一的評估框架與標準化數據基準。
引言
對多物理場與多尺度系統動態過程的建模與預測,依然是尚未解決的科學難題。以地球系統為例,這一獨特且復雜的系統,其動力學過程由物理、化學與生物過程相互作用所共同支配,作用的時空尺度跨度高達17個數量級1。過去50年中,科學界通過有限差分、有限元、譜方法以及無網格方法等數值求解偏微分方程(PDE)手段,在從地球物理到生物物理等多個領域對多尺度物理過程的理解取得了巨大進展。
盡管取得了持續進步,使用傳統解析方法或計算方法對非線性、多尺度系統中存在尺度級聯(cascade-of-scales)現象的演化過程進行建模與預測,仍面臨嚴峻挑戰。這類方法計算代價高昂,且存在多重不確定性來源。此外,反問題求解(例如功能材料中的材料參數反演,或反應傳輸過程中的缺失物理規律挖掘)往往計算代價高昂,需要復雜的數學建模方法、新型算法以及繁瑣的計算代碼。更重要的是,面對缺失、不完整或含噪邊界條件的真實物理問題,傳統方法已難以有效求解。
在這一背景下,觀測數據的重要作用日益凸顯。預計未來十年,全球將部署超過萬億個傳感器,包括空基、海基以及衛星遙感設備,生成海量多保真度觀測數據,為數據驅動方法提供了豐富的數據基礎。然而,盡管當前可獲取的數據量、更新速度與多樣性空前,現實應用中卻難以將這些多保真度觀測數據無縫融入現有物理模型。盡管數學與實際意義上的數據同化方法取得了長足發展,但觀測數據的豐富性、時空異質性,以及缺乏普適性的數學模型,進一步凸顯了對變革性方法的迫切需求。
這正是機器學習(ML)發揮作用的關鍵所在。機器學習能夠探索龐大的設計空間,挖掘多維相關性,并處理不適定問題。例如,它可用于氣候極端事件的檢測,或對降水量、植被生產力等動態變量進行統計預測23。特別是深度學習方法,天然具備從海量多保真度觀測數據中自動提取特征的能力,這些數據具有前所未有的時空覆蓋度?。深度學習還能夠將這些特征與現有近似模型相結合,進而開發新的預測工具。即便在生物物理和生物醫學建模領域,將機器學習方法與多尺度、多物理場模型融合應用的研究方向,也已被廣泛倡導?。
當前各科學領域普遍面臨的一個問題是,觀測數據的獲取與生成速度遠遠超過了對其合理同化、甚至基本理解的能力?(見 Box 1)。盡管機器學習(ML)方法在某些應用中展現出了強大的經驗潛力并取得了初步成果?,但大多數現有方法尚無法從這些龐雜數據中提取出可解釋的信息與知識。此外,純數據驅動模型雖然能夠很好地擬合觀測數據,但由于外推或觀測偏差等問題,往往導致預測結果與物理規律不符甚至不合理,進而造成模型泛化性能較差。
因此,迫切需要通過將基本物理規律與領域知識融入機器學習模型,賦予模型“物理認知”,為其提供“信息先驗”——即在觀測數據之外,施加強有力的理論約束和歸納偏置。為此,物理信息學習(physics-informed learning)應運而生,其核心理念是:借助我們對世界的觀測、經驗、物理或數學規律等先驗知識,提升機器學習算法的建模性能。近期,一個典型代表是物理信息神經網絡(PINNs) ? ,這是一類將觀測數據與抽象數學算子(包括包含或不包含缺失物理規律的PDE)無縫融合的深度學習算法(見 Box 2、Box 3)。
開發這類方法的核心動因在于,物理先驗知識或約束能夠賦予機器學習模型更強的可解釋性,使其在面對不完整數據(如缺失值、噪聲、異常值等)時依然保持穩健,并能在外推和泛化任務中實現高精度、符合物理規律的預測。盡管當前已建立了眾多公共數據庫,但復雜物理系統中可用的實驗數據仍然有限。針對這類系統的預測建模方法,具體應依賴于可用數據量及系統本身復雜性(見 Box 1)。
如 Box 1 所示,在經典建模范式中,假設僅有邊界條件和初始條件可用,而系統的偏微分方程(PDE)及相關參數是完全已知的。另一極端情形是,盡管可以獲取大量數據(例如時間序列),但連續體層面的控制方程(即基礎PDE)未知???。大多數現實應用場景則介于兩者之間,物理規律部分已知(例如守恒定律已知,但本構關系未知),且存在若干分散觀測值(主變量或輔助變量),可用于同時反演PDE參數、缺失項以及求解系統響應。這一“混合型”情形是最常見且最具代表性的,同時也囊括了前述兩種極端情形,當觀測數據過少或過多時皆可歸入其中。
此外,這類中間情形可能演化為更復雜場景,例如由于激勵或材料性質的不確定性,使得PDE的求解過程呈現隨機性,需借助隨機PDE來描述隨機解與不確定性。同時,對于存在長程時空相互作用的問題(如湍流、粘彈塑性材料或其他異常輸運過程),非局部或分數階微積分、分數階PDE可能是更合適的數學語言,其表現出的強大表達能力與深度神經網絡(DNN)不無相似。
過去二十年來,為實現數值模擬中的不確定性量化,學者們提出了包含大量不確定參數的復雜建模方案,復雜問題甚至涉及數百個參數,導致實際計算常常不可行。目前,許多國家實驗室的仿真代碼及開源程序(如 OpenFOAM1?、LAMMPS11)代碼行數超10萬,難以維護與迭代更新。
我們認為,借助物理信息學習,可以有效解決上述基礎性與實踐性問題,實現在PINNs或其他基于非線性回歸的物理信息網絡(PINs)(見 Box 2)中,無縫集成數據與數學模型。本文綜述將首先介紹如何將物理規律嵌入機器學習模型,以及不同類型的物理機制如何指導新型神經網絡結構的設計。其次,闡述物理信息學習方法的最新能力與應用進展。鑒于該領域發展極為迅速,最后還將探討當前方法的主要局限與未來展望。同時,讀者可參考文獻12了解現有物理驅動機器學習方法的分類體系。
📦 Box 1 | 數據與物理場景分類
下圖示意性地展示了物理問題及其可用數據的三種典型分類情形:
- 小數據情形:假定已完全掌握所有物理規律,同時觀測數據提供了偏微分方程的初始條件、邊界條件及系數信息。
- 中等數據情形:這是現實應用中最普遍的情況,此時部分物理規律已知,同時存在部分觀測數據,可能存在某些參數缺失,甚至偏微分方程中的某個項缺失。例如,在對流-擴散-反應系統中,反應項未知。
- 大數據情形:此時對系統的物理機制幾乎一無所知,僅依賴大量觀測數據,通過數據驅動方法(如算子回歸方法)挖掘潛在物理規律。
物理信息機器學習(Physics-informed machine learning)可在統一框架下,將觀測數據與控制物理規律(包括部分缺失物理機制的模型)無縫集成。該方法通常借助自動微分技術與神經網絡實現?,確保預測結果遵循基本物理原理。

📦 Box 2 | 物理信息學習的基本原則
將學習算法構建為物理信息模型,實質上是引入適當的觀測偏置、歸納偏置或學習偏置,以引導學習過程朝向物理一致性解(見下圖)。主要包括:
-
觀測偏置(Observational biases):
通過包含基礎物理信息的觀測數據,或經過精心設計的數據增強方法,引入觀測偏置。基于此類數據訓練的機器學習系統,能夠學習反映數據物理結構的函數、矢量場或算子。 -
歸納偏置(Inductive biases):
即在機器學習模型架構中植入先驗假設,通過定制的結構性設計,確保預測結果隱式滿足給定的物理規律(通常以數學約束形式表達)。這被認為是構建物理信息學習算法最為嚴謹的方法,因其可嚴格遵循物理約束。不過,該方法多局限于事先已知的相對簡單的對稱群(如平移、置換、反射、旋轉等),且模型實現較復雜、可擴展性有限。 -
學習偏置(Learning biases):
通過選擇合適的損失函數、約束條件和推斷算法,在模型訓練階段引導優化過程,促使模型收斂于符合物理規律的解。此類方法通過調節軟懲罰約束,雖無法嚴格滿足物理規律,但為引入積分方程、微分方程甚至分數階方程形式的物理偏置,提供了極為靈活的實現平臺。
上述三類偏置方式相互獨立但并不排斥,可以靈活組合,構建多樣化的混合式物理信息學習方法,廣泛應用于物理信息機器學習模型的開發中。

📦 Box 3 | 物理信息神經網絡(Physics-informed Neural Networks, PINNs)
物理信息神經網絡(PINNs)通過將偏微分方程(PDEs)嵌入神經網絡的損失函數中,并利用自動微分技術,實現了對測量數據與PDEs信息的無縫整合。這里的PDEs可以是整數階PDEs、積分微分方程、分數階PDEs或隨機PDEs等多種形式。
以下以粘性Burgers方程為例介紹PINNs求解正問題的算法:
ν ? u ? t + u ? u ? x = ν ? 2 u ? x 2 \nu \frac{\partial u}{\partial t} + u \frac{\partial u}{\partial x} = \nu \frac{\partial^2 u}{\partial x^2} ν?t?u?+u?x?u?=ν?x2?2u?
配合適當的初始條件和Dirichlet邊界條件。
圖中左側的“無物理信息”神經網絡表示PDE的解的近似函數 u ( x , t ) u(x,t) u(x,t);
右側的“物理信息”神經網絡描述PDE的殘差: ? u ? t + u ? u ? x ? ν ? 2 u ? x 2 \frac{\partial u}{\partial t} + u \frac{\partial u}{\partial x} - \nu \frac{\partial^2 u}{\partial x^2} ?t?u?+u?x?u??ν?x2?2u?
損失函數由兩個部分組成:
- 監督學習損失:來自初始和邊界條件處的觀測數據 u u u 的誤差
- 無監督損失:PDE殘差的誤差
具體表達為:
L = w data L data + w PDE L PDE \mathcal{L} = w_{\text{data}} \mathcal{L}_{\text{data}} + w_{\text{PDE}} \mathcal{L}_{\text{PDE}} L=wdata?Ldata?+wPDE?LPDE?
其中,
L data = 1 N data ∑ i = 1 N data ∣ u ( x i , t i ) ? u i ∣ 2 \mathcal{L}_{\text{data}} = \frac{1}{N_{\text{data}}} \sum_{i=1}^{N_{\text{data}}} \left| u(x_i, t_i) - u_i \right|^2 Ldata?=Ndata?1?i=1∑Ndata??∣u(xi?,ti?)?ui?∣2
表示數據點的誤差,
L PDE = 1 N PDE ∑ j = 1 N PDE ∣ ? u ? t + u ? u ? x ? ν ? 2 u ? x 2 ∣ 2 \mathcal{L}_{\text{PDE}} = \frac{1}{N_{\text{PDE}}} \sum_{j=1}^{N_{\text{PDE}}} \left| \frac{\partial u}{\partial t} + u \frac{\partial u}{\partial x} - \nu \frac{\partial^2 u}{\partial x^2} \right|^2 LPDE?=NPDE?1?j=1∑NPDE?? ??t?u?+u?x?u??ν?x2?2u? ?2
表示PDE殘差的誤差。
這里 { ( x i , t i ) } \{(x_i, t_i)\} {(xi?,ti?)} 是采樣于初始/邊界條件處的點集, u i u_i ui? 是對應的測量值; { ( x j , t j ) } \{(x_j, t_j)\} {(xj?,tj?)} 是采樣于整個計算域的點集。權重 w data w_{\text{data}} wdata? 和 w PDE w_{\text{PDE}} wPDE? 用于平衡兩個損失項的權重,這些權重可以由用戶定義,也可以自動調節,對提升PINNs的訓練性能起著重要作用。
該神經網絡通過基于梯度的優化器(如Adam、L-BFGS)訓練,直到損失小于設定閾值 ε \varepsilon ε。

算法1:PINN算法流程
- 構建神經網絡 u ( x , t ; θ ) u(x,t; \theta) u(x,t;θ),其中 θ \theta θ 是網絡中所有可訓練參數(權重和偏置), σ \sigma σ 是非線性激活函數。
- 指定觀測數據 { ( x i , t i , u i ) } \{(x_i, t_i, u_i)\} {(xi?,ti?,ui?)} 和PDE殘差點 { ( x j , t j ) } \{(x_j, t_j)\} {(xj?,tj?)}。
- 定義損失函數 L \mathcal{L} L(見上式),結合數據損失和PDE殘差損失的加權和。
- 通過優化 θ \theta θ 最小化損失函數 L \mathcal{L} L,得到最佳參數 θ ? \theta^* θ?。
將物理規律嵌入機器學習的方法
任何預測模型都離不開前提假設,因而,沒有適當偏置的機器學習模型,也無法具備良好的泛化能力。針對物理信息學習,目前主要有三種路徑可供單獨或組合應用,以嵌入物理規律、加速模型訓練并提升泛化性能(見 Box 2):
觀測偏置(Observational biases)
觀測數據是機器學習近年來取得重要進展的基礎,也是最直接、最簡單的偏置引入方式。當學習任務輸入域內存在充足觀測數據時,機器學習方法已被證明能夠在高維任務中實現高精度插值。尤其對于物理系統,隨著傳感網絡迅猛發展,已能夠獲得多保真度觀測數據,監測復雜現象在不同時空尺度上的演化。這些觀測數據應體現其生成過程所遵循的基本物理規律,原則上可以作為弱形式機制,在機器學習模型訓練過程中嵌入這些物理規律。例如文獻 [13–16] 中提出的神經網絡方法。但對于過參數化的深度學習模型,通常需要大量觀測數據才能強化這類偏置,使預測結果滿足某些對稱性與守恒律。此時,數據獲取成本成為現實障礙,尤其在物理與工程領域,觀測數據往往依賴于昂貴實驗或大規模數值模擬。
歸納偏置(Inductive biases)
另一類方法專注于設計專門的神經網絡結構,在架構中隱式嵌入與預測任務相關的先驗知識和歸納偏置。最具代表性的例子是卷積神經網絡(CNN) [17],它通過尊重圖像中的對稱性群與分布式模式表示,徹底變革了計算機視覺領域 [18]。其他典型方法包括圖神經網絡(GNN)[19]、等變網絡(Equivariant Networks)[20]、高斯過程等核方法 [21–26],以及廣義物理信息網絡(PINs)[27],其中核函數由控制物理規律直接誘導。卷積網絡還可擴展至更復雜對稱群(如旋轉、反射、更一般的規范變換)[19,20],支持在流形上構建依賴于內蘊幾何結構的神經網絡架構,適用于醫學圖像 [28]、氣候模式分割 [20] 等任務。

此外,可通過小波散射變換構建平移不變表示,具備變形穩定性并保留高頻信息 [29]。協變神經網絡 [30] 專門適用于遵循旋轉、平移不變性的多體系統(見圖 1a)。類似的,等變 Transformer 網絡 [31] 提供了一類針對預定義連續變換群的可微映射,增強模型在連續對稱變換下的魯棒性。這類方法盡管表現優異,但目前主要適用于物理規律簡單、對稱群明確定義的任務,且模型實現復雜,擴展至復雜問題仍具挑戰,尤其是許多物理系統中的對稱性與守恒律往往尚未完全明晰,或難以隱式編碼進網絡結構中。
廣義卷積并非強歸納偏置架構的唯一形式。例如,通過矩陣值函數行列式可實現神經網絡中輸入變量交換反對稱性 [32]。文獻 [33] 將基于物理的鍵序勢模型與神經網絡結合,將結構參數劃分為局部與全局部分,用于預測大規模原子模擬中的原子間勢能面。另有研究 [34] 采用不變張量基將伽利略不變性嵌入網絡結構,顯著提升湍流建模中的預測精度。
針對哈密頓系統建模,已有方法設計網絡結構保持哈密頓系統下的辛結構 [35]。例如,文獻 [36] 改進自編碼器表示 Koopman 算子,將非線性動力學坐標變換映射為近似線性系統。
特別是用于偏微分方程求解的神經網絡,可通過調整架構,嚴格滿足初始條件 [37]、Dirichlet 邊界條件 [37,38]、Neumann 邊界條件 [39,40]、Robin 邊界條件 [41]、周期邊界條件 [42,43] 及界面條件 [41]。若偏微分方程解的某些特性已知,也可編碼進網絡結構,如多尺度特性 [44,45]、奇偶對稱性、能量守恒 [46]、高頻特性 [47] 等。
舉例而言,文獻 [48] 提出了一種將神經網絡架構與 Hamilton–Jacobi 偏微分方程(HJ-PDE)粘性解相聯系的方法。其兩層結構如圖 1b 所示,定義映射:
f ( x , t ) = min ? i ∈ { 1 , … , m } ( ? t + a i + t L ( x ? u i t ) ) f(x, t) = \min_{i \in \{1, \dots, m\}} \left( -t + a_i + t L\left( \frac{x - u_i}{t} \right) \right) f(x,t)=i∈{1,…,m}min?(?t+ai?+tL(tx?ui??))
其中, x x x 與 t t t 分別為空間與時間變量, L L L 為凸且 Lipschitz 激活函數, a _ i ∈ R a\_i \in \mathbb{R} a_i∈R, u _ i ∈ R n u\_i \in \mathbb{R}^n u_i∈Rn 為神經網絡參數, m m m 為神經元數量。文獻 [48] 證明, f f f 即為以下 HJ-PDE 的粘性解:
? f ( x , t ) ? t + H ( ? x f ( x , t ) ) = 0 , ( x , t ) ∈ R n × ( 0 , + ∞ ) \frac{\partial f(x, t)}{\partial t} + H(\nabla_x f(x, t)) = 0, \quad (x, t) \in \mathbb{R}^n \times (0, +\infty) ?t?f(x,t)?+H(?x?f(x,t))=0,(x,t)∈Rn×(0,+∞)
且初始條件為:
f ( x , 0 ) = J ( x ) f(x, 0) = J(x) f(x,0)=J(x)
其中,Hamiltonian H H H 與初始值 J J J 可由網絡參數與激活函數顯式確定。要求 H H H 必須是凸函數,但 J J J 無需滿足該條件。需注意,文獻 [48] 的結果無需依賴神經網絡通用逼近定理,而是表明某些特定 HJ-PDE 的物理規律可通過特定神經網絡架構自然編碼,無需高維數值逼近。
學習偏置(Learning bias)
另一類方法則從不同角度探討如何將先驗知識賦予神經網絡。這種方法并不依賴于專門的網絡結構來隱式強制執行物理知識,而是通過在常規神經網絡近似模型的損失函數中加入軟約束項,以懲罰項形式引入物理規律。這一策略可視為多任務學習(multi-task learning)的一種特例,即學習算法在擬合觀測數據的同時,還需生成大致滿足給定物理約束(如質量守恒、動量守恒、單調性等)的預測結果。典型代表包括Deep Galerkin Method [49]、PINNs 及其變體 [7,37,50–52]。PINNs 框架在 Box 3 中進一步說明,系統闡述了基于軟懲罰約束嵌入物理規律的優勢與局限性。
軟懲罰約束具備極高靈活性,便于將多種領域知識形式融入機器學習模型。例如,文獻 [53] 提出了一種統計約束生成對抗網絡(GAN),通過強制訓練數據中的協方差約束,改進了基于機器學習的模擬器,使其能捕捉完全求解偏微分方程生成數據的統計特性。其他示例還包括:用于學習機器人接觸誘導不連續行為的模型 [54],采用附加軟約束以保持 Lyapunov 穩定性的物理信息自編碼器(Physics-informed autoencoders)[55],以及通過損失函數中的軟約束項編碼不變性的 InvNet [56]。此外,還有卷積、循環結構以及概率推斷框架的擴展方法 [51,52,57],如文獻 [52] 中的貝葉斯框架,可對復雜偏微分方程動態系統預測結果的不確定性進行量化。
基于軟懲罰約束和正則化優化得到的解,可等價視作基于物理規律假設的貝葉斯方法中的最大后驗估計(maximum a posteriori estimate)。另一種方法是采用馬爾科夫鏈蒙特卡洛(MCMC) 或變分推斷(variational inference)方法,量化觀測數據缺失和噪聲帶來的不確定性。
混合方法(Hybrid approaches)
前述幾類物理信息機器學習方法各具優劣,因此將其相互結合是理想方案,目前已有多種混合方法被提出。例如,通過無量綱化(non-dimensionalization) 可恢復系統特性,借助 Reynolds 數、Froude 數或 Mach 數等物理無量綱參數引入偏置。已有多種方法用于學習描述物理現象的算子 [13,15,58,59],如 DeepONets [13],是一種強大的監督學習算子方法。更具前景的是,結合 DeepONets 與 PINNs 融合編碼的物理知識,可在多物理場應用(如電對流 [60] 和高超聲速流動 [61])中實現實時、高精度的外推預測。
當存在低保真度模型時,還可采用多保真策略 [62],輔助復雜系統的學習。例如,文獻 [63] 將觀測偏置與學習偏置結合,利用大渦模擬數據和受限神經網絡訓練方法,為低保真 RANS 模型構建湍流封閉項。其他代表性應用還包括:文獻 [64] 中基于多保真神經網絡從壓痕數據提取材料性能,文獻 [65] 中利用 PINs 從流變數據反演非牛頓流體本構關系,以及文獻 [66] 中提出的粗粒化策略。即使低保真模型無法直接編碼進學習過程,也可通過數據增強手段,利用簡化數學模型或現有計算程序(如 [64])生成大量低保真數據。
其他典型案例包括 FermiNets [32] 和圖神經算子方法(graph neural operator methods)[58]。此外,也可通過將神經網絡嵌入傳統數值方法(如有限元法)中實現物理約束,此類方法已應用于非線性動力系統 [67]、計算力學本構關系建模 [68,69]、地下力學 [70–72]、隨機反演 [73] 等多個領域 [74,75]。
與核方法的聯系(Connections to kernel methods)
許多基于神經網絡的方法與核方法存在漸近等價性,這一聯系可用于深入理解模型本質。例如,文獻 [76,77] 證明,PINNs 的訓練動態可視為在網絡寬度趨于無窮大時的核回歸方法。更一般地,神經網絡方法可嚴格視作一種變形核(warping kernel) 學習方法,其中核函數由數據學習得到 [78,79]。最初,這類核方法用于地統計學中的非平穩空間結構建模 [80],現已應用于解釋殘差神經網絡(ResNet)\ [27,80]。
PINNs 也可視為在再生核希爾伯特空間(RKHS)中求解偏微分方程,其中 RKHS 由神經網絡初始層參數化的特征映射所張成。此外,已有研究探索統計推斷方法與數值逼近方法之間的緊密聯系,應用于偏微分方程求解與反問題 [81]、最優恢復 [82] 和貝葉斯數值分析 [83–88]。即便是復雜架構如 attention-based transformer 網絡 [89],也可在核方法框架下建立聯系,而算子值核方法(operator-valued kernel methods)[90] 則有望成為分析和解釋深度學習算子學習工具的有效路徑。總之,基于核方法視角分析神經網絡模型極具價值,因為核方法具備良好的可解釋性與堅實的理論基礎,有助于理解深度學習方法在何時何因成功或失效。
與經典數值方法的聯系(Connections to classical numerical methods)
經典數值算法(如 Runge–Kutta 法和有限元法)一直是數值模擬物理系統的主力。值得注意的是,許多現代深度學習模型在結構與原理上,與這些經典方法存在明顯對應關系。例如,卷積神經網絡類似于偏微分方程平移等變離散化中的有限差分模板 [91,92],并與多重網格方法(multigrid)[93] 結構一致;殘差神經網絡(ResNet)[94] 本質上等價于自治常微分方程前向 Euler 離散化 [95–98]。Runge–Kutta 算法(如 RK4)與循環神經網絡架構,甚至 Krylov 型矩陣自由線性代數方法(如廣義最小殘差法)[95,99] 之間也存在顯著類比。此外,帶 ReLU 激活函數的深度神經網絡表示等價于有限元法中的連續分片線性函數 [100]。這類類比不僅提供了重要洞察,也為未來“數學信息”元學習架構鋪平了道路。例如,文獻 [7] 提出一種基于隱式 Runge–Kutta 積分方法啟發的離散時間神經網絡方法,采用多達 500 個隱變量階段,允許極大時間步長,獲得高精度解。
物理信息學習的優勢
目前,物理信息機器學習(physics-informed machine learning)已在多個學科領域針對具體應用取得大量成果。例如,PINNs 的不同擴展形式已覆蓋守恒方程 [101],以及用于隨機現象和異常輸運問題的隨機與分數階偏微分方程(PDEs)[102,103]。將區域分解方法(domain decomposition) 與 PINNs 相結合,在多尺度問題中提供了更高的靈活性,同時該方法的數值實現相對簡單,適合并行計算,因為每個子區域可由單獨神經網絡建模,并分配到不同 GPU 上,通信開銷極小 [101,104,105]。這些研究結果表明,PINNs 在求解病態問題(ill-posed problems)與反問題(inverse problems)中表現尤為出色;而對于無需數據同化的正向良定問題(well-posed problems),現有基于數值網格的方法仍優于 PINNs。
下文將詳細討論 PINNs 在何種情形下具有優勢,并列舉典型應用示例。
不完整模型與不完美數據
如 Box 1 所示,物理信息學習能夠輕松整合物理模型與離散噪聲數據,即便兩者均不完美。近期研究 [106] 證明,即使由于 PINN 公式本身的光滑性或正則性,問題未必完全良定,依然能夠求得有意義的解。這類問題包括無初始或邊界條件的正向/反問題,或 PDE 中部分參數未知,傳統數值方法對此常常無能為力。
在應對不完美模型與數據時,將貝葉斯方法與物理信息學習相結合以實現不確定性量化(uncertainty quantification)十分有益,如Bayesian PINNs(B-PINNs) [107]。此外,相較于傳統數值方法,物理信息學習是無網格方法(mesh-free),無需耗費大量計算資源生成網格,因此能便捷處理不規則和運動邊界問題 [108]。并且,基于現有 TensorFlow、PyTorch 等開源深度學習框架,代碼實現簡單。
小樣本數據下的強泛化能力
深度學習通常依賴大量數據,而在多數物理問題中,獲取高精度數據極為困難。此時,物理信息學習在小樣本場景下表現出強泛化能力。通過施加或嵌入物理規律,深度學習模型等效地被限制在低維流形上,僅需少量數據即可訓練出高精度模型。可通過嵌入物理原則于網絡結構、將物理作為軟懲罰項或利用數據增強等方法強制模型滿足物理規律。此外,物理信息學習不僅具備插值能力,還能實現外插預測,例如在邊值問題中執行空間外插 [107]。
理解深度學習機制
除了提升模型可訓練性與泛化性,物理規律也有助于揭示深度學習方法背后的內在機制。例如,文獻 [109–112] 基于顆粒介質的擁塞躍遷現象(jamming transition) 解釋了過參數化階段深度學習中出現的雙下降現象(double-descent)。淺層神經網絡還可視為相互作用粒子系統,因而可在概率測度空間而非高維參數空間內,利用平均場理論(mean-field theory)分析其性質 [113]。
另一項研究 [114] 將變分重整化群(variational renormalization group) 精確映射至基于限制玻爾茲曼機(RBM)的深度學習結構。受物理學中密度矩陣重整化群(DMRG)算法啟發,文獻 [115] 提出將量子張量網絡(tensor network) 應用于多分類監督學習,大幅降低計算開銷。
文獻 [116] 從統計物理學視角研究深度網絡損失函數景觀,將其與自旋玻璃模型(spin-glass models) 建立直觀聯系。同時,寬深度神經網絡中的信息傳播也可基于動力系統理論研究 [117,118],分析網絡初始化如何決定輸入信號傳播,進而確定一組保證深度網絡有效信息傳播的超參數和激活函數(即“混沌邊緣 edge of chaos”)。
應對高維問題
深度學習已在高維問題求解中取得巨大成功,如高分辨圖像分類、語言建模和高維偏微分方程求解。其中一個原因在于,當目標函數是局部函數的層級復合(hierarchical composition of local functions)時,深度神經網絡可打破維數災難(curse of dimensionality)[119,120]。
例如,文獻 [121] 將一般高維拋物型 PDE 重構為向后隨機微分方程(backward stochastic differential equations, BSDEs),用神經網絡逼近解的梯度,基于離散化隨機積分和給定終值條件設計損失函數。實際應用中,該方法用于求解高維 Black–Scholes 方程、Hamilton–Jacobi–Bellman 方程和 Allen–Cahn 方程。
生成對抗網絡(GANs)[122] 也在高維分布建模中取得成功,廣泛應用于圖像和文本生成任務 [123–125]。在物理問題中,文獻 [102] 利用 GANs 量化高維隨機微分方程中的參數不確定性,文獻 [126] 則用 GANs 學習高維隨機動力學參數。這些實例表明,GANs 能有效建模物理問題中的高維概率分布。
最后,文獻 [127,128] 證明,即使是算子回歸與 PDE 應用,深度算子網絡(DeepONets) 也能有效緩解輸入空間維數災難。
不確定性量化
對多尺度、多物理場系統的演化進行可靠預測,必須考慮不確定性量化(uncertainty quantification,UQ)。過去 20 年里,這一重要問題受到廣泛關注,傳統計算方法通過引入隨機建模來處理邊界條件或材料屬性導致的不確定性 [129–131]。對于物理信息學習模型,至少存在三種不確定性來源:
- 物理不確定性:指隨機物理系統,通常由隨機偏微分方程(SPDEs)或隨機常微分方程(SODEs)描述。參數的不確定性歸屬于此類。例如,文獻 [132] 采用神經網絡作為輸入的投影函數,恢復低維非線性流形,針對具有不確定擴散系數的 SPDE 中不確定性傳播問題給出了結果。類似地,文獻 [133] 利用物理信息損失函數(即對隨機變量上 PDE 能量泛函的期望)訓練神經網絡,參數化橢圓型 SPDE 的解。文獻 [51] 使用條件卷積生成模型預測解的概率密度,采用物理信息的概率損失函數,無需訓練數據標簽。
值得注意的是,生成對抗網絡(GANs)在學習高維隨機 PDE 解的分布方面表現強大,相關工作 [102,134] 是首批嘗試。物理信息 GANs 通過利用有限傳感器同時采集的多重隨機過程數據,能在同一框架下解決從正向到反問題的多種問題。已有結果顯示,若合理設計,GANs 能有效緩解高隨機維數問題的維數災難。
-
數據不確定性:一般指由于數據噪聲引起的本質不確定性(aleatoric uncertainty)和數據缺失造成的認知不確定性(epistemic uncertainty)。貝葉斯框架能夠很好地處理此類不確定性。如果物理信息學習模型基于高斯過程回歸,則可以直接量化不確定性,并利用其進行主動學習和 PDE 分辨率細化研究 [23,135],甚至設計更優實驗 [136]。文獻 [107] 提出了基于貝葉斯 PINNs(B-PINNs)的另一種方法,展示了 B-PINNs 可提供合理的不確定區間,該區間量級與誤差相當,且隨著數據噪聲增大而增大。但如何系統地設置 B-PINNs 的先驗仍是未解決的問題。
-
模型不確定性:指學習模型本身的限制,如神經網絡的近似誤差、訓練誤差和泛化誤差,通常難以嚴格量化。文獻 [137] 采用卷積編碼-解碼神經網絡,將 PDE 的源項和域幾何映射到解及其不確定性,使用基于有限元數據的概率監督學習進行訓練。文獻 [138] 首次嘗試量化學習帶來的聯合不確定性,結合了 [139] 中的 dropout 方法和因物理隨機性引入的任意多項式混沌展開。文獻 [42] 對時變系統和長時間積分的擴展中,利用隨機 PDE 的動態雙正交模態分解,解決了參數不確定性,適合長期隨機系統積分。
應用亮點
本節討論物理信息學習在多個應用中的能力,重點關注傳統方法難以或無法解決的反問題和病態問題,并介紹若干科學機器學習開源軟件的開發進展。
示例:意式濃縮咖啡杯上的流動
第一個示例展示了如何提取意式濃縮咖啡杯上方三維速度和壓力場的定量信息 [140]。輸入數據基于溫度梯度視頻(見圖 2)。該例為文獻 [106] 引入的“隱形流體力學”典型的病態反問題,未提供邊界條件或任何其他信息。

具體來說,利用體積式背景導向施利倫成像(Tomo-BOS)獲得測量密度或溫度的三維可視化數據,作為 PINN 的輸入。PINN 無縫結合了可視化數據與流動及被動標量控制方程,推斷隱含的速度和壓力場。物理假設基于布辛涅斯克近似(Boussinesq approximation),適用于密度變化較小的情況。PINN 以空間和時間坐標作為輸入,通過最小化包含溫度數據不匹配和守恒定律殘差(質量、動量和能量)的損失函數訓練模型。獨立的粒子圖像測速(PIV)實驗結果驗證了 Tomo-BOS/PINN 方法能夠提供連續、高分辨率且準確的三維流場。
物理信息深度學習在 4D 流場 MRI 中的應用
接下來,我們討論物理信息神經網絡(PINNs)在生物物理學中,結合真實磁共振成像(MRI)數據的應用。MRI 由于非侵入性及其多種結構和生理對比機制,已成為臨床心血管疾病患者血流和血管功能定量活體評估的關鍵工具。然而,MRI 測量常受限于分辨率較低且噪聲較大,導致重建血管拓撲及流動條件流程繁瑣且經驗性強。
物理信息深度學習的最新進展,尤其是針對 4D 流場 MRI,可以顯著提升 MRI 技術的分辨率和信息含量。具體而言,可構建受納維–斯托克斯方程約束的深度神經網絡(DNN),有效去噪 MRI 數據,生成物理一致的速度和壓力場重建,保證質量守恒和動量守恒,達到任意高的時空分辨率。此外,濾波后的速度場可用于識別無滑移流動區,進而重構動脈壁位置及運動,并推斷壁面剪切應力、動能和耗散等重要物理量(見圖 3)。綜上,這些方法能極大提升 MRI 在科研和臨床中的能力。

然而,PINNs 的穩健性仍存在潛在風險,尤其是在 MRI 測量信噪比極高及復雜流動模式(如邊界層、高渦旋區、狹窄處瞬態湍流爆發、曲折分支血管等)下。但在生理條件下,血流通常為層流,當前 PINN 模型大多能有效處理此類情況。
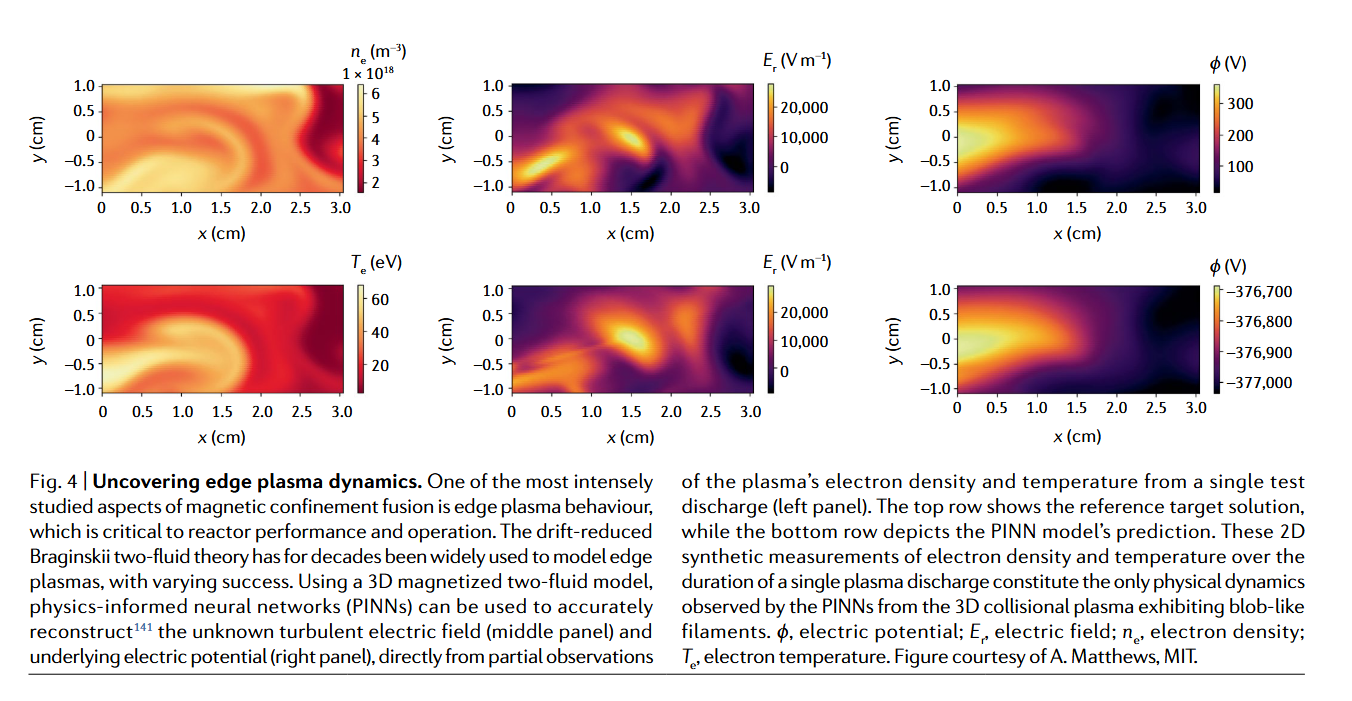
通過部分觀測用深度學習揭示邊緣等離子體動力學
預測磁約束聚變裝置邊緣的湍流輸運,是數十年來的研究目標,目前聚變電站粒子和能量約束仍存在顯著不確定性。文獻 [141] 證明 PINNs 能僅通過合成等離子體的電子密度和溫度的部分觀測,準確學習與雙流體理論一致的湍流場動力學,用于等離子體診斷和熱核環境中的模型驗證。圖 4 展示了 PINNs 從部分 3D 合成等離子體數據學習的湍流徑向電場。
研究高維分布中亞穩態間的轉變
物理信息學習還能創造性地用于處理高維問題。文獻 [142] 提出使用 PINNs 研究高維概率分布中兩個亞穩態之間的轉變。具體地,使用神經網絡表示承諾函數(committor function),用物理信息損失函數訓練,該損失函數基于承諾函數的變分表達式,并對邊界條件施加軟約束。此外,采用自適應重要性采樣來抽取主導損失的罕見事件,從而降低解的漸近方差并提升泛化能力。圖 5 展示了 144 維 Allen–Cahn 型系統概率分布的結果。盡管計算結果顯示該方法對高維問題有效,但將其應用于更復雜系統及針對具體系統選取神經網絡架構仍具挑戰。

熱力學一致的 PINNs
PINNs 中普遍采用的物理正則化可解釋為利用神經網絡基函數進行點值最小二乘殘差的形式。對于涉及激波的雙曲型問題,由于解的點值無定義,需考慮降階正則的物理穩定化方案。文獻 [143] 提出的控制體積 PINN(cvPINN)將傳統有限體積方法推廣至深度學習環境。該方法不僅因降低正則需求提高精度,還可自然引入總變差消減限幅器,恢復熵解。該框架可用于估計金屬等材料適用的激波流體動力學黑箱狀態方程。對于極端壓強和溫度下的相變等情形,深度神經網絡提供理想手段處理未知模型形式,且 cvPINNs 的有限體積結構確保熱力學一致性。
量子化學中的應用
在一些應用中,研究者結合物理設計專用架構和物理信息學習原則。例如,文獻 [32] 提出用于多電子薛定諤方程從頭算的費米子神經網絡(FermiNet)。FermiNet 是一種混合嵌入物理的方法:首先,為波函數參數化設計了滿足費米–狄拉克統計的專用架構,即輸入電子狀態交換時反對稱,且滿足邊界條件(無窮遠處衰減);其次,訓練過程也是物理信息驅動的,損失函數設置為能量期望值的變分形式,梯度通過蒙特卡洛方法估計。雖然神經網絡避免了計算量子化學中常見的基組外推誤差,網絡性能仍依賴架構與優化算法,需要進一步系統研究。
材料科學中的應用
材料領域的許多問題屬于病態逆問題,物理信息學習可發揮重要作用。例如,文獻 [144] 引入了優化 PINN,用于識別和精確表征金屬板表面裂紋。該 PINN 以 5 MHz 超聲表面聲波數據監督,物理信息由聲波方程提供,未知波速函數由神經網絡表示。訓練中關鍵是采用自適應激活函數,引入可訓練超參數,大幅加快收斂,即使在噪聲顯著的情況下也表現優異。
另一種引入物理信息的思路是多保真度框架,如文獻 [64] 用于通過儀器化壓痕提取 3D 打印材料力學性能。作者通過求解深度感應壓痕逆問題,確定鈦合金和鎳合金的彈塑性參數。框架采用兩層復合神經網絡結構:一層低保真度 ResNet 利用大量有限元仿真數據,另一層高保真度 ResNet 以稀疏實驗數據和低保真輸出為輸入,目標是學習兩者間的非線性映射,進而高保真預測彈性模量和屈服強度。該方法顯著提升性能,將屈服強度推斷誤差從超 100% 降至 5% 以下。
分子模擬中的應用
文獻 [145] 提出神經網絡架構表示分子動力學模擬中的勢能面,借助合適預處理保持分子系統的平移、旋轉和置換對稱性。該表示在深度勢分子動力學(DeePMD)\ [146] 中得到改進,用神經網絡替代傳統勢能函數,訓練數據源自從頭算模擬,達到了從頭算精度且計算成本隨系統規模線性增長。文獻 [147] 利用高度優化的 DeePMD 代碼,在 Summit 超級計算機上實現了每天模擬超 1 億原子的 1 納秒級軌跡,刷新了此前百萬原子規模的從頭算分子動力學模擬記錄 [147,148]。
地球物理中的應用
物理信息學習還被應用于多種地球物理逆問題。文獻 [71] 結合神經網絡與全波形反演、地下流動過程和巖石物理模型,實現從地震數據估計巖石滲透率和孔隙度等地下屬性。此外,文獻 [149] 證明結合深度神經網絡和數值 PDE 求解器(如混合方法節中所述),物理信息學習可解決廣泛的地震反演問題,包括速度估計、斷層破裂成像、地震定位和震源時函數反演。
軟件支持
為了高效實現物理信息神經網絡(PINNs),基于當前主流機器學習庫(如 TensorFlow 150 ^{150} 150、PyTorch 151 ^{151} 151、Keras 152 ^{152} 152 和 JAX 153 ^{153} 153)構建新算法是有利的。目前,已有若干專門為物理信息機器學習設計的軟件庫,推動該領域快速發展(見表 1)。

當前活躍開發的庫包括 DeepXDE 154 ^{154} 154、SimNet 155 ^{155} 155、PyDEns 156 ^{156} 156、NeuroDiffEq 157 ^{157} 157、NeuralPDE 158 ^{158} 158、SciANN 159 ^{159} 159 和 ADCME 160 ^{160} 160。鑒于 Python 是機器學習的主流語言,大多數庫均采用 Python 實現,唯 NeuralPDE 和 ADCME 使用 Julia。它們均利用如 TensorFlow 150 ^{150} 150 等軟件提供的自動微分機制。部分庫(如 DeepXDE 和 SimNet)可作為“求解器”直接使用,即用戶定義問題后,求解器自動處理底層細節;而如 SciANN 和 ADCME 則為“包裝器”,封裝底層函數為更高級接口,用戶仍需自行實現問題求解步驟。
此外,軟件包如 GPyTorch 161 ^{161} 161 和 Neural Tangents 162 ^{162} 162 通過核方法視角研究神經網絡及 PINNs,推動了對 PINNs 訓練動態的新理解,進而促使設計新架構和訓練算法 76 , 77 ^{76,77} 76,77。
DeepXDE 不僅支持整數階常微分方程(ODE)和偏微分方程(PDE),還支持積分微分方程和分數階 PDE,支持通過構造實體幾何(CSG)處理復雜域,用戶代碼緊湊且貼近數學表達。其模塊化設計良好,適合科研和教育用途。相對地,Nvidia 開發的 SimNet 針對 Nvidia GPU 優化,適合大規模工程問題。
在 PINNs 中,需計算網絡輸出對輸入的導數。例如,使用 TensorFlow 可通過 tf.gradients( U U U, t t t) 計算一階導數 ? U ? t \frac{\partial U}{\partial t} ?t?U?,二階導數可通過兩次調用 tf.gradients 實現。DeepXDE 提供了更便捷的高階導數計算接口,如 dde.grad.hessian 計算 Hessian 矩陣。該函數具備延遲計算和緩存已計算梯度的特性,避免重復計算,適合耦合 PDE 系統中多次梯度計算,提升計算效率。
大多數庫(如 DeepXDE 和 SimNet)將物理信息作為軟約束(見 Box 3),ADCME 將 DNN 嵌入傳統科學數值方案(如 Runge–Kutta 方法、有限差分/元/體積法)中,解決逆問題。ADCME 近期擴展支持隱式方案和非線性約束 163 , 164 ^{163,164} 163,164,并支持基于 MPI 的域分解方法,在復雜問題上展現良好擴展性 165 ^{165} 165。
選擇模型、框架和算法
隨著方法和軟件工具日益豐富,自然出現以下問題:面對物理系統和觀測數據,選擇哪個機器學習框架?采用何種訓練算法?需要多少訓練樣本?目前尚無通用經驗法則,建立有效的物理信息機器學習模型仍需一定經驗,但未來元學習技術 166 ? 168 ^{166-168} 166?168 有望實現自動化。
從高層次分類看,PINNs 通常用于推斷與物理定律兼容的確定性函數,適用于有限觀測(初/邊界條件或其他測量)情況。PINNs 模型的架構依問題性質而定:多層感知機適用廣泛但無特殊歸納偏置;卷積神經網絡適合二維網格域;傅里葉特征網絡適合解含高頻或周期邊界的 PDE;遞歸神經網絡適合非馬爾科夫和時序離散問題。
概率 PINNs 可推斷隨機過程,捕捉模型不確定性(貝葉斯推斷或頻率學派集成)及數據噪聲不確定性(變分自編碼器、生成對抗網絡等生成模型)。DeepONet 框架可推斷算子而非函數,其架構根據數據性質調整,如多層感知機用于散亂傳感器數據,卷積網絡用于圖像,遞歸網絡用于時序數據。
樣本復雜度一般未知,依賴架構中歸納偏置強度、觀測數據與物理正則化的匹配程度及目標函數或算子復雜度。
當前限制
多尺度與多物理問題
盡管物理信息學習已在多領域取得成功,多尺度和多物理問題仍需進一步發展。全連接神經網絡難以學習高頻函數,稱為“F-原理” 169 ^{169} 169 或“頻譜偏差” 170 ^{170} 170。文獻 171 , 172 ^{171,172} 171,172 證明 DNN 頻率偏差存在性,導出訓練收斂速率與目標頻率的關系。高頻解對應陡峭梯度,導致 PINN 難以準確懲罰 PDE 殘差 45 ^{45} 45,多尺度問題中高頻成分難學且訓練易失敗 76 , 173 ^{76,173} 76,173。解決方法包括域分解 105 ^{105} 105、傅里葉特征 174 ^{174} 174及多尺度 DNN 45 , 175 ^{45,175} 45,175。多物理同時學習計算量大,可先分開學習再耦合,如 DeepM&M 方法針對電荷對流 60 ^{60} 60和高超音速 61 ^{61} 61,先訓練多個 DeepONet,再通過并行或串行 DeepM&M 架構基于額外數據監督學習耦合解。
目前神經網絡訓練中物理信息損失多以點值形式定義,雖在部分高維問題有效,某些低維特殊問題如非光滑擴散方程等可能失效 177 ^{177} 177。
新算法與計算框架
物理信息機器學習模型通常涉及大規模神經網絡及復雜多項損失,非凸性強 178 ^{178} 178,訓練過程不穩定且不保證全局收斂 179 ^{179} 179。需發展更魯棒網絡架構和訓練算法。文獻 76 , 77 , 173 ^{76,77,173} 76,77,173 指出 PINNs 兩大弱點,關聯頻譜偏差 170 ^{170} 170與不同損失項收斂率差異,導致訓練不穩和梯度消失。設計合理模型架構和新訓練算法可緩解此問題。文獻 104 ^{104} 104 利用 PDE 弱形式和 h p hp hp-細化提升網絡擬合能力。其他方法包括自適應修改激活函數 180 ^{180} 180,訓練時動態采樣數據和殘差點 181 ^{181} 181,加快收斂且提升性能。
神經網絡架構設計目前依賴用戶經驗,費時費力,元學習技術有望自動化該過程 166 ? 168 ^{166-168} 166?168。值得注意的是,系統分岔參數(如雷諾數)增大時,網絡架構可能需調整。
深度學習訓練代價高昂,需加速訓練,例如通過 DeepONet 轉移學習(裂紋擴展案例 182 ^{182} 182)。也需利用 GPU、張量處理單元等硬件開發可擴展并行訓練算法,支持數據并行與模型并行。
與傳統分類回歸僅需一階導數不同,物理信息學習多涉及高階導數。目前主流軟件如 TensorFlow 和 PyTorch 對高階導數支持不足。更高效的 ML 軟件庫(例如基于泰勒模式自動微分 183 , 184 ^{183,184} 183,184)可顯著降低計算成本,推動跨學科物理信息機器學習發展。除整數階導數,積分算子和分數階導數等算子 103 ^{103} 103 在物理信息學習中也十分有用。
數據生成與基準測試
在機器學習社區中,尤其是圖像、語音和自然語言處理領域,使用標準基準數據集是非常普遍的做法,以評估算法的改進、結果的可復現性以及預期的計算成本。UCI 機器學習庫 185 ^{185} 185,創建已有三十多年歷史,是一個包含數據庫和數據生成器的集合,常用于對比新算法的相對性能。目前,該庫還包含物理科學領域的實驗數據集,例如由機翼產生的噪聲、與厄爾尼諾相關的海洋溫度和洋流測量,以及不同游艇設計相關的流體阻力數據。這些數據集對機器學習中的數據驅動建模非常有用,原則上也可以用于物理信息機器學習方法的基準測試,前提是數據庫中明確包含適當參數化的物理模型。
然而,在物理和化學的許多應用中,往往需要全場數據,這類數據實驗上難以獲取(例如密度泛函理論、分子動力學模擬或湍流的直接數值模擬),且在時間和內存資源上消耗極大。因此,如何公開這些數據、如何策劃珍貴數據以及如何包含生成這些數據庫所需的物理模型和所有參數,需要慎重考慮。此外,設計有意義的基準以測試新提出的物理信息算法的準確性和加速效果,也是一項復雜的任務。事實上,即使是在上述成熟的圖像等機器學習應用中,現有基準和評價指標依然在不斷精進,特別是當軟件和硬件因素也被納入考量時(例如圖像識別的深入分析 186 ^{186} 186)。
物理系統的困難更加凸顯,因其目標是預測動力學。舉例來說,捕捉或識別動力系統的分岔和混沌態非常復雜。然而,諸如文獻 187 ^{187} 187中提出的有效預測時間(valid-time prediction)等新指標,可能適合且具有良好的發展前景。
新的數學理論
盡管物理信息學習模型取得了經驗性成功,但其理論基礎尚知之甚少。需要一套新理論,嚴謹分析物理信息學習的能力與局限(例如神經網絡的學習容量)。更具體的問題是:神經網絡能否通過梯度優化找到 PDE 的解?為回答該問題,應分析深度學習中的總誤差,該誤差可分解為三類:
- 逼近誤差(approximation error):網絡是否能以任意精度逼近 PDE 的解?
- 優化誤差(optimization error):是否能達到零或極小的訓練損失?
- 泛化誤差(generalization error):較小的訓練誤差是否意味著更準確的預測解?
此外,需分析問題的適定性(well-posedness),以及誤差的穩定性和收斂性。尤其當待求解算子部分由數據學習得到時,相關問題的適定性成為一項激動人心的數學挑戰。此問題在初始/邊界/內部條件本身為(可能存在不確定的)數據時更加復雜。適定性問題必須結合數學分析與機器學習計算實驗加以研究。
PINNs 在正問題上的首個數學分析見文獻 188 ^{188} 188,其中引入 H?lder 正則化以控制泛化誤差。具體而言,文獻 188 ^{188} 188分析了二階線性橢圓和拋物型 PDE,并證明了解的一致性。文獻 189 , 190 ^{189,190} 189,190在損失函數中采用數值積分點,給出了正問題和逆問題的抽象誤差估計,但未報告收斂結果,因為積分點方法未量化泛化誤差。后續工作中,文獻 191 ^{191} 191研究線性 PDE,提出統一誤差估計框架,涵蓋 PINNs 和變分 PINNs 7 , 104 , 192 ^{7,104,192} 7,104,192。基于緊性假設和范數等價關系,得到了充分收斂條件,泛化誤差由 Rademacher 復雜度處理。文獻 49 , 193 ? 195 ^{49,193-195} 49,193?195基于連續損失函數形式推導了誤差估計。雖然 PDE 文獻中的連續范數誤差界可作為(連續)PINNs 的誤差界,但需結合數據樣本以量化泛化誤差。
一般而言,神經網絡由基于梯度的優化方法訓練,亟需建立新理論以更好理解訓練動態(如梯度下降、隨機梯度下降、Adam 196 ^{196} 196等)。文獻 197 ^{197} 197分析了過參數化兩層網絡,證明了梯度下降在二階線性 PDE 上的收斂性,但未納入邊界條件。文獻 76 ^{76} 76將神經切線核理論 198 ^{198} 198推廣到 PINNs,展示了網絡寬度趨于無窮時 PINNs 訓練動態可視為核回歸。通過可視化不同損失函數(強形式、弱形式等)的損失地形,有助于理解網絡訓練過程。
此外,隨著新方法快速發展,理解模型間及不同范數下損失函數的等價性也十分重要。基于嚴謹理論分析物理信息機器學習模型,需深度融合深度學習、優化、數值分析與 PDE 理論,不僅可催生更魯棒有效的訓練算法,也可為這代新計算方法奠定堅實基礎。
展望
物理信息學習能夠無縫整合數據與數學模型,即使在噪聲和高維環境下,也能高效解決廣泛的逆問題。本文總結了關鍵概念(見盒子1–3),并提供了框架和開源軟件參考,幫助讀者快速入門物理信息學習。還討論了當前能力與局限,展示了流體力學、生物物理學、等離子體物理、亞穩態轉變及材料等多個應用。
接下來,介紹物理信息學習機器的新應用方向及研究趨勢,有望加快訓練速度、提高預測準確性和增強可解釋性。雖然已有 TensorBoard 等工具可視化模型圖、變量和指標,但物理問題常需更高階功能:集成多物理、多復雜幾何域、解決高維解場的可視化,類似傳統計算平臺如 FEniCS 199 ^{199} 199、OpenFOAM 10 ^{10} 10 等。
設計用戶友好、基于圖形的機器學習開發環境,滿足上述需求,將助力更多研究者開發物理信息機器學習算法,廣泛應用于多樣物理問題。
未來方向
數字孿生(Digital twins)
“數字孿生”概念由通用電氣提出,指工廠制造發動機的數字副本,如今正成為多個行業的現實。通過同化真實測量數據校準計算模型,數字孿生旨在數字空間精準再現物理實體的行為。
轉化該技術為實踐前,需解決一系列基本問題。首先,觀測數據稀缺且噪聲大,數據類型異構(圖像、時間序列、實驗室測試、歷史數據、臨床記錄等),某些關鍵變量難以直接獲得。其次,基于物理的計算模型依賴繁瑣的預處理和校準(如網格生成、初邊界條件校準),成本高昂,限制其實時決策應用。再者,許多復雜自然系統的物理模型至多是“部分”已知的守恒律,除非假設合適的本構關系,否則無閉合方程系統。
物理信息學習具備天然融合物理模型與數據的能力,且自動微分避免了網格生成,極具潛力成為數字孿生時代的催化劑。
數據與模型變換、融合及可解釋性
隨著基于物理的建模與機器學習的深入融合,研究者越來越常遇到不同團隊即使使用同一訓練數據(或等效信息數據,通過不同傳感器觀測)也會得到不同的數據驅動模型(學習的潛空間、算子不同),即使其訓練集預測結果近似無異。
鑒于觀測現象往往無唯一物理解釋,未來構建 ML 基礎的模型間變換(不同保真度模型、理論間一一對應、可校準的“對偶”關系)將變得尤為重要。研究者日益發現此類變換(如非線性動力學與對應 Koopman 模型、泊松系統與對應哈密頓系統、Nesterov 迭代與對應 ODE)可通過數據驅動方式獲得。這些變換有助于系統融合數據與模型。
ML 潛空間特征與物理可解釋觀測量,或 ML 學得算子與閉式方程間的變換,將大大提升 ML 模型的可解釋性。最終,應檢驗這些變換的泛化能力:在哪些觀測范圍內 ML 模型間、或 ML 模型與物理模型間可映射,及其超出何種極限后不再可轉化或校準。
尋找內在變量與新興、有用的表征
當前大多數物理信息機器學習方法遵循這樣一個范式:首先定義一組(人類可解釋的)觀測量或變量;然后收集數據;基于所選觀測量,使用“合理”的算子字典,完整或不完整地表達物理規律;最后應用選擇的學習算法。
隨著機器學習的進步,一種新興范式正在形成,即利用觀測和學習方法自動確定良好或內在變量,同時尋找有用或信息豐富的物理模型表達式。超越主成分分析(PCA),流形學習技術(從 isoMAP 到 t-SNE 和擴散映射)及其深度學習對應方法——生成模型和(可能是變分)自動編碼器——被用來將原始觀測嵌入到降維且數學上有用的潛空間中,在該潛空間內可以學習演化規律。
值得注意的是,這些有用的表征不僅僅是對相關特征或 PDE 中因變量的嵌入。對于時空無序數據,還可以構建機器學習驅動的“新興空間” 200 , 201 ^{200,201} 200,201,以機器學習所得的獨立變量表示:即新興的“時空”,其中模型算子將被學習。
2011 年的 DARPA Shredder Challenge 202 ^{202} 202通過有效地解開各種碎紙機粉碎的文件,重構了空間。如今,雜亂的時空觀測數據也可以被嵌入到信息豐富的“獨立變量”新興空間中。例如,演化算子可以以 PDE 或隨機微分方程(SODE)的形式,在這些新的新興空間(甚至可能是時間)獨立變量中被學習;這里與現代物理中對新興時空的討論 203 ^{203} 203有直接類比。
這種新范式可能在設計優化或復雜系統(甚至系統的系統)的數字孿生構建中起關鍵作用,因為人類難以寫出封閉形式的整潔物理表達式。
此外,與先收集實驗數據再執行學習算法不同,整合兩者進入主動學習框架變得重要。借助學習算法潛空間的幾何結構,可輔助明智地選擇新的信息性數據,而算法則能逐步優化潛空間描述符和控制物理的數學表達,從而隨著實驗進展產生更逼真的預測。
最終,最核心的變化是對“理解”的定義。迄今為止,“理解”意味著 PDE 中每一項都有物理或機械的解釋,作用于一些物理有意義的觀測量(因變量)及物理有意義的時空(自變量)。現在,即使沒有這種機械式理解,也可以實現準確預測,而“理解”可能在這一過程中被重新定義。






 B (物理?) + CF 860 (Div. 2) C (數學思維 + lcm + gcd))


)





:流程控制全解析——分支(if/switch)和循環(for/while)的深度指南)



:從概念到第一個容器)