文章目錄
- 預處理語言模型的發展
- 預訓練
- 語言模型
- 統計語言模型
- 神經網絡語言模型
- 詞向量
- onehot編碼
- 詞嵌入word embedding
- Word2Vec模型
- RNN和LSTM
- RNN
- LSTM
- ELMo模型
- 預訓練
- 下游任務
- Attention
- 自注意力
- Masked Self Attention
- Multi-head Self Attention
- 位置編碼
- Transformer概念
- GPT概念
- BERT概念
- 參考鏈接
預處理語言模型的發展
| 年份 | 技術 | 說明 |
|---|---|---|
| 2013 | word2vec | 靜態編碼,無法一詞多義 |
| 2014 | GloVe | |
| 2015 | LSTM/Attention | 可以處理長距離文本,但存在長距離依賴問題(如梯度消失/爆炸),難以并行化訓練 |
| 2016 | Self-Attention | |
| 2017 | Transformer | Transformer是一個模型結構,用自注意力機制self-attention替代循環結構,可實現并行化計算 |
| 2018 | GPT/ELMo/BERT/GNN | ELMo使用雙向LSTM訓練語言模型,然后將其中間層輸出作為動態詞向量,用于下游任務。BERT結合了ELMo的上下文思想和Transformer的結構 |
| 2019 | XLNet/BoBERTa/GPT-2/ERNIE/T5 | |
| 2020 | GPT-3/ELECTRA/ALBERT |
預訓練
以圖像領域的預訓練為例,CNN一般用于圖片分類任務,越淺的層學到的特征越通用(橫豎撇捺),越深的層學到的特征和具體任務的關聯性越強。
預訓練的思想具體做法就是,對于一個具有少量數據的任務,首先通過一個現有的大量數據搭建一個CNN模型A,對模型A做出一部分改進(凍結或微調)得到模型B。
(1)凍結:淺層參數使用模型A的參數,高層參數隨機初始化,淺層參數一直不變,然后利用現有小規模圖片訓練參數
(2)微調:淺層參數使用模型A的參數,高層參數隨機初始化,然后利用現有小規模圖片訓練參數,但是在這里淺層參數會隨著任務的訓練不斷發生變化
然后利用模型B的參數對模型A進行初始化,再通過任務中的少量數據對模型A進行訓練。其中模型B的參數是隨機初始化的。
語言模型
語言模型通俗點講就是計算一個句子的概率
給定一句由n個詞組成的句子W=w1,w2,?,wn,計算這個句子的概率P(w1,w2,?,wn),或者計算根據上文計算下一個詞的概率P(wn|w1,w2,?,wn?1)。
語言模型有兩個分支,統計語言模型和神經網絡語言模型
統計語言模型
統計語言模型的基本思想就是計算條件概率
P ( w 1 , w 2 , ? , w n ) = P ( w 1 ) P ( w 2 ∣ w 1 ) P ( w 3 ∣ w 1 , w 2 ) ? p ( w n ∣ w 1 , w 2 , ? , w n ? 1 ) = ∏ i P ( w i ∣ w 1 , w 2 , ? , w i ? 1 ) \begin{align*} P(w_1,w_2,\cdots,w_n) & = P(w_1)P(w_2|w_1)P(w_3|w_1,w_2)\cdots p(w_n|w_1,w_2,\cdots,w_{n-1}) \\ & = \prod_i P(w_i|w1,w_2,\cdots,w_{i-1}) \end{align*} P(w1?,w2?,?,wn?)?=P(w1?)P(w2?∣w1?)P(w3?∣w1?,w2?)?p(wn?∣w1?,w2?,?,wn?1?)=i∏?P(wi?∣w1,w2?,?,wi?1?)?
因為Wn詞只和它前面的k的詞有相關性,用馬爾科夫鏈化簡為二元語言模型公式如下
P ( w i ∣ w i ? 1 ) = c o u n t ( w i ? 1 , w i ) c o u n t ( w i ? 1 ) P(w_i|w_{i-1})=\frac{count(w_{i-1},w_i)}{count(w_{i-1})} P(wi?∣wi?1?)=count(wi?1?)count(wi?1?,wi?)?
統計語言模型會出現數據稀疏的情況,即訓練時未出現,測試時出現了的未登錄單詞,為了避免0值的出現,使用一種平滑的策略
P ( w i ∣ w i ? 1 ) = c o u n t ( w i ? 1 , w i ) + 1 c o u n t ( w i ? 1 ) + ∣ V ∣ P(w_i|w_{i-1}) = \frac{count(w_{i-1},w_i)+1}{count(w_{i-1})+|V|} P(wi?∣wi?1?)=count(wi?1?)+∣V∣count(wi?1?,wi?)+1?
神經網絡語言模型
神經網絡語言模型(NNLM)引入神經網絡架構來估計單詞的分布,通過詞向量的距離衡量單詞之間的相似度。因此對于未登錄單詞,也可以通過相似詞進行估計,進而避免出現數據稀疏問題。
NNLM學習任務是輸入某個句中單詞wt=bert前的t?1個單詞,要求調整網絡中的參數,正確預測單詞bert,即最大化下面公式結果。
P ( w t = b e r t ∣ w 1 , w 2 , ? , w t ? 1 ; θ ) P(w_t=bert|w_1,w_2,\cdots,w_{t-1};\theta) P(wt?=bert∣w1?,w2?,?,wt?1?;θ)

詞向量
將單詞轉成向量形式,叫詞向量,有如下兩種
onehot編碼
對于onehot編碼,如果采用余弦相似度計算向量間的相似度,任意兩者向量的相似度結果都為0,即任意二者都不相關,也就是說onehot表示無法解決詞之間的相似性問題。
詞嵌入word embedding
對于神經網絡語言模型的矩陣Q(這個矩陣Q和注意力機制中的Q不是一回事),是一個V x m,V代表詞典大小,每一行的內容代表對應的單詞的Word Embedding值。
矩陣Q通過訓練學習正確的參數,將單詞的onehot編碼點乘矩陣Q,得到這個詞的Word Embeddind向量Ci。
Word2Vec模型
2013年最火的用語言模型做Word Embedding的工具是Word2Vec
Word2Vec有兩種訓練方法
-
CBOW,核心思想是從一個句子里面把一個詞摳掉,用這個詞的上文和下文去預測被摳掉的這個詞
-
Skip-gram,和CBOW正好反過來,輸入某個單詞,要求網絡預測它的上下文單詞
神經網絡語言模型NNLM主要任務是看到上文去預測下文,其中的Word Embedding只是其中的一個掛件
Word2Vec主要任務就是做Word Embedding
訓練好的Word Embedding矩陣Q,就可以當作其他任務的預訓練模型的參數,進行凍結或微調,應用于其他任務模型。
但是Word2Vec的詞嵌入模型生成的詞向量,無法做到一詞多義
RNN和LSTM
RNN
傳統的神經網絡無法獲取時序信息,然而時序信息在自然語言處理任務中非常重要。

每一個模塊A都會把當前信息傳遞給下一個模塊。
RNN的出現,讓處理時序信息變為可能。但這里的時序一般指的是短距離的。
RNN存在梯度消失和梯度爆炸問題,即被近距離梯度主導,而遠距離的梯度影響特別小。
LSTM
LSTM是為了解決RNN缺乏序列長距離依賴問題,LSTM的一個RNN門控結構(LSTM的timestap)
但是LSTM無法做到并行計算

ELMo模型
Word2Vec的詞嵌入模型生成的詞向量,無法做到一詞多義
ELMo可以做到一詞多義
ELMo采用了典型的兩階段過程:
- 第一個階段是利用語言模型進行預訓練;網絡結構采用了雙層雙向LSTM
- 第二個階段是在做下游任務時,從預訓練網絡中提取對應單詞的網絡各層的Word Embedding作為新特征補充到下游任務中。
預訓練
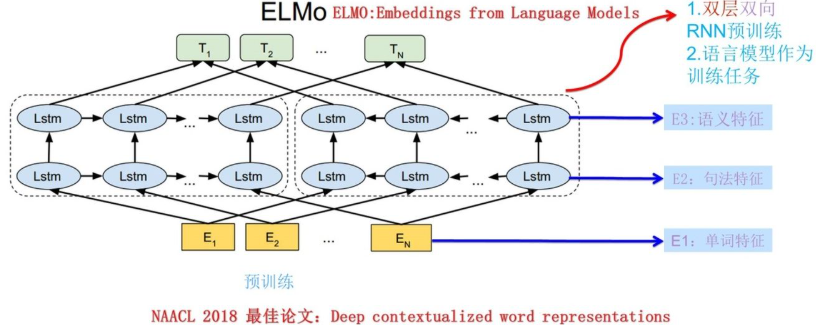
使用這個網絡結構利用大量語料做語言模型任務就能預先訓練好這個網絡,如果訓練好這個網絡后,輸入一個新句子,句子中每個單詞都能得到對應的三個Embedding:
- 最底層是單詞的Word Embedding;
- 往上走是第一層雙向LSTM中對應單詞位置的Embedding,這層編碼單詞的句法信息更多一些;
- 再往上走是第二層LSTM中對應單詞位置的Embedding,這層編碼單詞的語義信息更多一些。
下游任務

對于QA(question-answer)任務,輸入問句為X
-
先將句子X作為預訓練好的ELMo網絡的輸入,這樣句子X中每個單詞在ELMO網絡中都能獲得對應的三個Embedding
-
之后給予這三個Embedding中的每一個Embedding一個權重a,這個權重可以學習得來,根據各自權重累加求和,將三個Embedding整合成一個;
-
然后將整合后的這個Embedding作為X句在自己任務的那個網絡結構中對應單詞的輸入,以此作為補充的新特征給下游任務使用。
-
對于上圖所示下游任務QA中的回答句子Y來說也是如此處理。
因為ELMo給下游提供的是每個單詞的特征形式,所以這一類預訓練的方法被稱為“Feature-based Pre-Training”。
Attention
注意力模型從大量信息Values中篩選出少量重要信息,這些重要信息一定是相對于另外一個信息Query而言是重要的
從編碼器的每個輸入向量創建三個向量因此,對于每個單詞,我們創建一個 Query 向量、一個 Key 向量和一個 Value 向量。這些向量是通過將嵌入向量乘以我們在訓練過程中訓練的三個矩陣來創建的。
Q/K/V的定義和作用
- Query(Q):表示當前需要關注的詞(或位置)的“提問”,用于與其他位置的鍵(Key)進行匹配。
- Key(K):表示序列中每個詞的“索引”,用于與 Query 計算相關性。
- Value(V):表示序列中每個詞的“實際內容”,最終根據注意力權重加權求和得到輸出。
- Query 是你的搜索關鍵詞。
- Key 是數據庫中的文檔標題或關鍵詞。
- Value 是文檔的實際內容。 搜索引擎會用 Query 和 Key 計算匹配度,然后返回對應的 Value
按照如下流程計算出每個單詞經過注意力層的輸出向量Z,這時Thinking這個詞經過注意力機制得到的向量Z就包含了這個詞在所在句子中的重要程度了。即Think相對于Thinking和Machines這句話的加權輸出。

自注意力
自注意力強調QKV三個矩陣都源自于輸入X本身
因為Self Attention在計算過程中會直接將句子中任意兩個單詞的聯系通過一個計算步驟直接聯系起來,所以遠距離依賴特征之間的距離被極大縮短,有利于有效地利用這些特征
每個單詞的計算是可以并行處理的
但是由于文本長度增加時,訓練時間也將會呈指數增長
Masked Self Attention
這里的Masked就是要在做語言模型(或者像翻譯)的時候,不給模型看到未來的信息
例如在補全或生成回答時,每次生成一個單詞后,當前回答變成從頭開始到當前單詞的句子,后面的單詞未知,需要下一步生成。
Multi-head Self Attention
允許模型在不同的語義或位置組合上分配注意力權重,避免單一注意力頭只能捕捉一種固定模式
將 Q/K/V 矩陣分割為多個獨立的子空間(頭),每個頭學習不同的注意力模式

位置編碼
Attention解決了長距離依賴問題,并且可以支持并行化。但是也丟棄了輸入序列X的中的各個單詞在句子中的位置序列關系。
因此在對X進行Attention計算之前,在X詞向量中加上位置信息
參考https://www.cnblogs.com/nickchen121/p/16470569.html#tid-YGp2KR
某個單詞的位置信息是其他單詞位置信息的線性組合,這種線性組合就意味著位置向量中蘊含了相對位置信息。
Transformer概念


GPT概念
NLP中兩種預訓練方法:Feature-based Pre-Training和基于Fine-tuning的模式
前者以ELMo為代表,后者以GPT為典型

GPT是Generative Pre-Training的簡稱,生成式的預訓練。主要基于Transformer的Decoder堆疊結構,不包含Encoder部分
GPT也采用兩階段過程:
- 第一個階段:利用語言模型進行預訓練;
- 第二個階段:通過 Fine-tuning 的模式解決下游任務。
BERT概念
Bidirectional Encoder Representations from Transformers
它的核心特點是
- 基于 Transformer Encoder 架構,
- 使用雙向注意力機制(bidirectional attention)建模上下文,
- 通過 Masked Language Model 進行預訓練,提升自然語言理解能力。
BERT參考了 ELMO 模型的雙向編碼思想、借鑒了 GPT 用 Transformer 作為特征提取器的思路、采用了 word2vec 所使用的 CBOW 方法

BERT和ELMo、GPT比較
- BERT和ELMo區別在與,ELMo使用LSTM作為特征提取器,有長距離問題和無法并行計算問題,而BERT用transformer塊作為特征提取器,解決了上述問題。
- BERT和GPT的區別在于,BERT使用transformer encoder,將GPT的單向編碼改成雙向編碼,雖然舍棄了文本生成能力,但是換來了更強的語義理解能力。
參考鏈接
https://www.cnblogs.com/nickchen121/p/16470569.html#tid-YGp2KR
https://blog.csdn.net/qq_62954485/article/details/146191691
![瀏覽器工作原理24 [#]分層和合成機制:為什么css動畫比JavaScript高效](http://pic.xiahunao.cn/瀏覽器工作原理24 [#]分層和合成機制:為什么css動畫比JavaScript高效)















】大模型為什么需要RAG)


