在大模型知識庫開發領域,向量數據庫的選擇直接影響系統的性能、擴展性和開發效率。隨著Redis 8.0推出Vector Set數據結構并增強向量搜索能力,開發者面臨新的選擇困境:是采用傳統專用向量數據庫(如Milvus、Pinecone),還是擁抱Redis這一“新晉”向量存儲解決方案?本文將從技術架構、性能指標、成本效益和典型場景四個維度,為您提供一套完整的決策框架,幫助您在大模型知識庫開發中做出最優選擇。

Redis 8.0向量能力深度解析
Redis 8.0的向量支持并非簡單功能疊加,而是從底層數據結構到查詢引擎的全方位革新。其核心Vector Set數據類型由Redis創始人Salvatore Sanfilippo親自設計,基于改進的Sorted Set結構擴展而來,支持存儲高維向量(如768維的文本嵌入)并執行高效的相似性搜索。與傳統的Sorted Set使用score進行排序不同,Vector Set通過內置的HNSW(Hierarchical Navigable Small World)算法實現近似最近鄰搜索,在百萬級向量庫中Top 100近鄰查詢延遲可低至1.3秒(含網絡往返)。
Redis向量搜索的技術實現包含三個關鍵層:
-
存儲引擎:向量數據以緊湊格式存儲在內存中,支持float32和int8兩種精度,內存占用優化達40%;
-
索引層:默認采用HNSW算法,支持可配置的參數(如
efConstruction和M),平衡構建時間和查詢精度; -
查詢層:通過Redis Query Engine實現混合查詢,支持向量相似度計算與標量過濾條件組合。
HNSW算法復雜度公式:
構建復雜度:
查詢復雜度:
內存占用:
其中為向量數量。
與獨立向量數據庫相比,Redis 8.0的獨特優勢在于亞毫秒級延遲和實時數據更新能力。傳統向量數據庫如Milvus的索引構建往往需要秒級甚至分鐘級時間,而Redis的Vector Set支持增量更新,新插入向量立即可查,這對實時推薦、對話式AI等場景至關重要。此外,Redis原生支持的TTL(Time-To-Live)機制使其天然適合作為語義緩存層,緩存頻繁查詢的RAG結果,顯著降低大模型API調用成本。
與傳統向量數據庫的對比分析
性能指標對比
通過基準測試數據對比Redis 8.0與主流向量數據庫的關鍵指標:
| 數據庫 | 查詢延遲 | 寫入吞吐 | 最大數據規模 | 索引構建時間 | 召回率@10 |
|---|---|---|---|---|---|
| Redis 8.0 | <1ms | 50K ops/s | 千萬級 | 實時更新 | 0.92 |
| Milvus | 5-10ms | 10K ops/s | 百億級 | 分鐘級 | 0.98 |
| Pinecone | 10-20ms | 5K ops/s | 十億級 | 秒級 | 0.95 |
| Elasticsearch | 10-30ms | 3K ops/s | 億級 | 分鐘級 | 0.90 |
| Chroma | 5-10ms | 1K ops/s | 百萬級 | 秒級 | 0.85 |
從表中可見,Redis在低延遲和高吞吐場景具有明顯優勢,但在超大規模數據集(十億級以上)和召回率指標上略遜于專用向量數據庫。這種差異源于技術架構的不同選擇:Redis優先保證實時性和簡單性,而Milvus等系統通過更復雜的分布式架構和索引算法追求極限規模和精度。
功能特性對比
除基礎向量搜索外,不同解決方案在高級功能上各具特色:
混合查詢能力:
-
Redis 8.0:支持向量搜索與JSON字段過濾組合,如“查找相似商品且價格<100元”
-
Elasticsearch:提供關鍵詞(BM25)與向量混合檢索,通過公式組合兩種分數:
- Milvus:支持復雜的標量過濾表達式,如“人臉相似度>0.8且年齡在20-30歲之間”
多模態支持:
-
Pinecone:專為多模態設計,支持文本、圖像、音頻的統一向量空間
-
Weaviate:內置多種嵌入模型,自動處理不同模態的向量生成
-
Redis:目前主要依賴外部模型生成向量,再存入Vector Set
擴展性與分布式:
-
Milvus:原生分布式設計,計算與存儲分離,支持K8s擴縮容
-
Pinecone:全托管Serverless架構,自動彈性擴展
-
Redis:集群模式下可水平擴展,但向量搜索性能隨分片數增加可能下降
資源消耗與成本模型
向量數據庫的成本構成復雜,需考慮計算資源、存儲開銷和運維人力三個方面:
內存占用:以存儲1億個768維(float32)向量為例
-
原始需求:1億 x 768 x 4字節 ≈ 293GB
-
Redis:啟用壓縮后約176GB9
-
Milvus:使用IVF_PQ索引約88GB
-
VSAG(螞蟻優化算法):僅需29GB
計算資源:
-
Redis:單核處理10K QPS約需8CU(1CU=1核CPU+8GB內存)
-
Milvus:同等QPS下GPU加速需2卡T4,成本高但吞吐量提升10倍
-
Pinecone:Serverless按查詢計費,$0.10/1000次查詢
總擁有成本(TCO)估算公式:
TCO = (內存成本 × 容量 + CPU成本 × 計算單元 + GPU成本 × 卡數) × 時間 + 運維人力成本
運維復雜度:
-
Redis:成熟工具鏈,但向量功能較新,監控指標不全
-
Milvus:分布式部署復雜,需專業團隊維護
-
Pinecone:免運維但失去控制權,不適合數據敏感場景
場景化選型策略
實時性優先場景
典型場景:在線推薦系統、對話式AI、欺詐檢測
推薦方案:Redis 8.0 + 語義緩存層
優勢分析:
-
亞毫秒延遲滿足實時交互需求
-
TTL機制自動淘汰過期特征,如用戶短期興趣變化
-
與現有緩存架構無縫整合,降低系統復雜度
實施建議:
-
熱數據駐留Redis,冷數據歸檔至Milvus/Pinecone
-
使用混合查詢過濾敏感內容,如“相似商品但排除競品”
-
監控
vector_search_qps和avg_response_time指標
實時推薦系統架構示例:
用戶請求 → Redis實時特征檢索 → 召回Top100 → 精排模型 → 返回結果
? ? ? ? ? ?↑
? ? ? ?特征更新流(Kafka)
超大規模知識庫
典型場景:企業文檔檢索、跨模態搜索、視頻去重
推薦方案:Milvus分布式集群 + Redis前端緩存
優勢分析:
-
百億級向量支持,計算存儲分離架構
-
多索引支持(HNSW/IVF/DiskANN),適應不同查詢模式
-
GPU加速顯著提升批量搜索吞吐
實施建議:
-
按業務分片,如不同產品線使用獨立collection
-
熱分片配置HNSW索引,冷分片使用DiskANN降低內存占用
-
寫入批量化為100-1000條/批次,提高吞吐
分片策略公式:
shard_key = hash(vector_id) % shard_count ?// 均勻分布
或
shard_key = business_unit ? ? ? ? ? ? ? ?// 業務局部性
快速迭代與原型開發
典型場景:創業公司MVP、學術研究、算法驗證
推薦方案:Chroma(本地開發)→ Pinecone(生產部署)
優勢分析:
-
Chroma零依賴,
pip install即可開始 -
Pinecone一鍵托管,免去運維負擔
-
兩者API相似,遷移成本低
實施建議:
-
開發環境使用Chroma+SentenceTransformers快速驗證
-
生產環境切換Pinecone,利用命名空間隔離測試數據
-
通過
recall@k指標評估不同嵌入模型效果
原型驗證代碼示例:
# Chroma本地開發
client = chromadb.Client()
collection = client.create_collection("prototype")
collection.add(embeddings=embeds, documents=docs)# 遷移至Pinecone
pinecone.init(api_key="xxx")
index = pinecone.Index("production")
index.upsert(vectors=zip(ids, embeds))混合檢索需求場景
典型場景:電商搜索、日志分析、合規審查
推薦方案:Elasticsearch + 向量插件
優勢分析:
-
關鍵詞與語義搜索無縫融合
-
成熟的分析功能(聚合、分組、統計)
-
與現有ELK棧兼容,學習曲線平緩
實施建議:
- 先使用BM25獲取初步結果,再用向量搜索擴展召回
- 自定義評分公式平衡兩種相關性:
-
對高維向量啟用
index: true提升搜索效率
遷移與演進路徑
從傳統方案過渡到Redis 8.0
對于已使用其他向量數據庫的系統,遷移至Redis 8.0需分階段進行:
并行運行階段:
- 保持原有向量庫作為主存儲
- 將熱點數據同步到Redis Vector Set
- 查詢時先訪問Redis,未命中則回源
流量切換階段:
-
逐步提高Redis查詢比例(如10%→50%→100%)
-
監控
cache_hit_rate和p99_latency -
針對長尾查詢優化HNSW參數(增加
efSearch)
完全遷移階段:
-
驗證召回率差異(Redis vs 原系統)
-
遷移剩余冷數據,停用原集群
-
實施監控告警(如
vector_memory_usage)
遷移驗證指標:
召回率差異 = |recall_redis - recall_original| / recall_original
延遲降低比 = (latency_original - latency_redis) / latency_original
從Redis擴展至專業向量數據庫
當Redis無法滿足增長需求時,可平滑演進至分布式方案:
容量不足時:
-
先啟用Redis集群模式分散數據
-
對低重要性數據啟用量化壓縮(float32→int8)
-
最終遷移至Milvus分布式集群
查詢復雜時:
-
簡單查詢保留在Redis
-
復雜混合查詢路由到Elasticsearch
-
通過API網關統一入口
多模態需求時:
-
文本向量保留在Redis
-
圖像/音頻向量存儲在Pinecone多模態索引
-
應用層統一結果排序
分層存儲架構示例:

未來趨勢與選型前瞻
向量數據庫技術仍在快速發展,幾個可能影響選型決策的趨勢值得關注:
-
統一查詢語言:類似SQL的標準化向量查詢語法出現,減少鎖定風險
-
智能壓縮:如VSAG的10倍壓縮比技術普及,大幅降低成本
-
邊緣計算:輕量級向量數據庫(如Qdrant)在端側部署成為可能
-
Redis生態擴展:預計Redis將增強分布式向量搜索和GPU支持
-
多模態LLM:需要數據庫原生支持跨模態聯合檢索
選型決策樹:
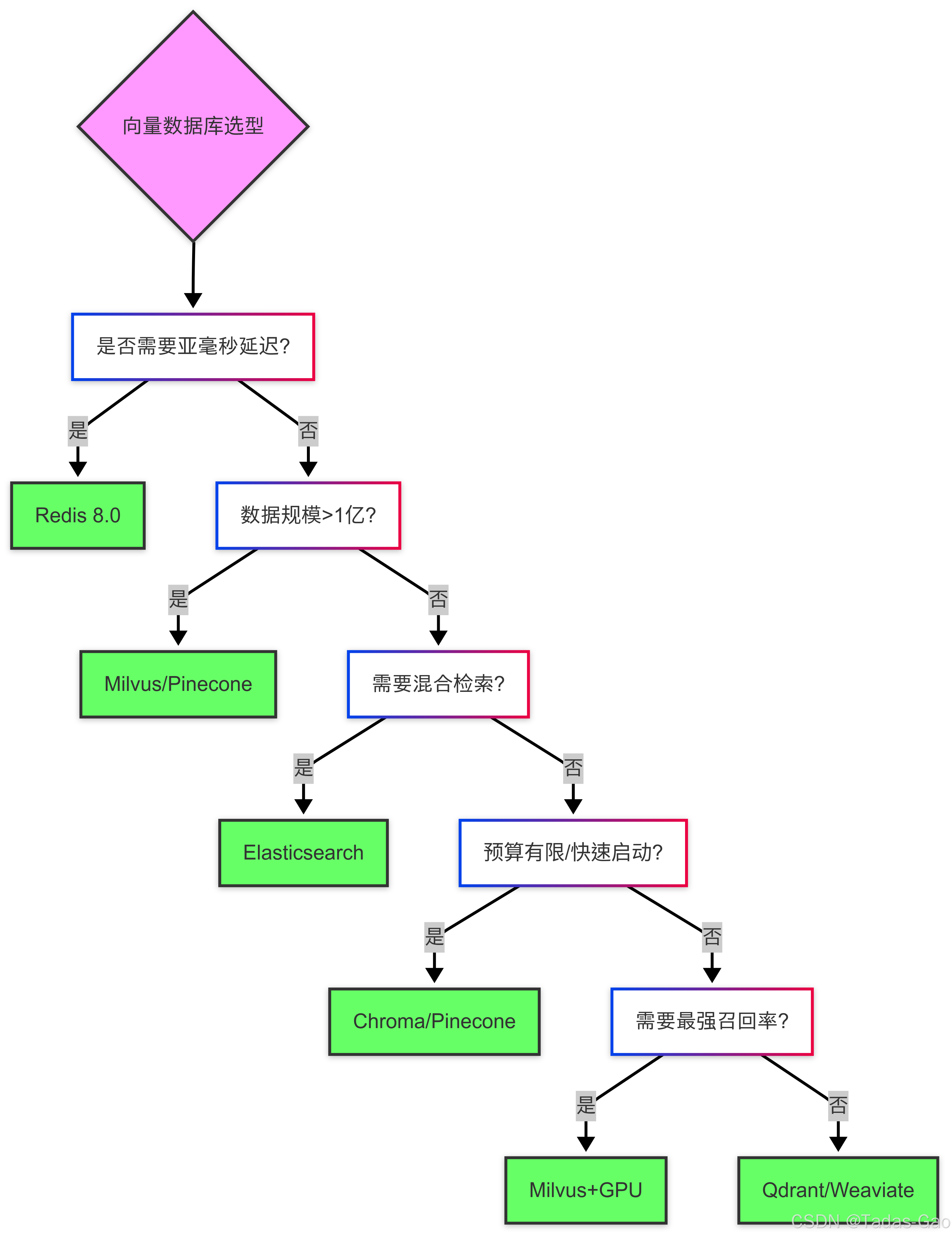
無論選擇何種技術棧,建議通過抽象層(如Repository模式)封裝向量操作,保持系統靈活性,以應對快速演進的技術。定期重新評估選型(如每6個月),確保與業務需求持續匹配。











:Nginx)


)



強化學習專題(6))
——詳解Parallel垃圾回收器)