今天,我們的課程開始進入一個新的主題了,那就是語音識別。過去幾周我們介紹的ChatGPT雖然很強大,但是只能接受文本的輸入。而在現實生活中,很多時候我們并不方便停下來打字。很多內容比如像播客也沒有文字版,所以這個時候,我們就需要一個能夠將語音內容轉換成文本的能力。
作為目前AI界的領導者,OpenAI自然也不會放過這個需求。他們不僅發表了一個通用的語音識別模型 Whisper,還把對應的代碼開源了。在今年的1月份,他們也在API里提供了對應的語音識別服務。那么今天,我們就一起來看看Whisper這個語音識別的模型可以怎么用。
Whisper API 101
我自己經常會在差旅的過程中聽播客。不過,篩選聽什么播客的時候,有一個問題,就是光看標題和簡介其實不是特別好判斷里面的內容我是不是真的感興趣。所以,在看到Whisper和ChatGPT這兩個產品之后,我自然就想到了可以通過組合這兩個API,讓AI來代我聽播客。 我想通過Whisper把想要聽的播客轉錄成文字稿,再通過ChatGPT做個小結,看看AI總結的小結內容是不是我想要聽的。
我前一陣剛聽過一個 關于 ChatGPT 的播客,我們不妨就從這個開始。我們可以通過 listennotes 這個網站來搜索播客,還能夠下載到播客的源文件。而且,這個網站還有一個很有用的功能,就是可以直接切出播客中的一段內容,創建出一個切片(clip)。
我們先拿一個小的切片來試試Whisper的API,對應的切片的 鏈接 我也放在這里了。課程Github的data目錄里也有已經下載好的MP3文件。
OpenAI提供的Whisper的API非常簡單,你只要調用一下transcribe函數,就能將音頻文件轉錄成文字。
import openai, osopenai.api_key = os.getenv("OPENAI_API_KEY")audio_file= open("./data/podcast_clip.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
print(transcript['text'])輸出結果:
歡迎來到 Onboard 真實的一線經驗 走新的投資思考 我是 Monica 我是高寧 我們一起聊聊軟件如何改變世界 大家好 歡迎來到 Onboard 我是 Monica 自從OpenAI發布的ChatGBT 掀起了席卷世界的AI熱潮 不到三個月就積累了 超過一億的越貨用戶 超過1300萬的日貨用戶 真的是展現了AI讓人驚訝的 也讓很多人直呼 這就是下一個互聯網的未來 有不少觀眾都說 希望我們再做一期AI的討論 于是這次硬核討論就來了 這次我們請來了 Google Brain的研究員雪芝 她是Google大語言模型PALM Pathway Language Model的作者之一 要知道這個模型的參數量 是GPT-3的三倍還多 另外還有兩位AI產品大牛 一位來自著名的StableDM 背后的商業公司Stability AI 另一位來自某硅谷科技大廠 也曾在吳恩達教授的Landing AI中 擔任產品負責人 此外 莫妮凱還邀請到一位 一直關注AI的投資人朋友Bill 當做我的特邀共同主持嘉賓 我們主要討論幾個話題 一方面從研究的視角 最前沿的研究者在關注什么 現在技術的天花板 和未來大的變量可能會在哪里 第二個問題是 未來大的變量可能會在哪里 從產品和商業的角度 什么是一個好的AI產品 整個生態可能隨著技術 有怎樣的演變 更重要的 我們又能從上一波 AI的創業熱潮中學到什么 最后 莫妮凱和Bill還會從投資人的視角 做一個回顧 總結和暢想 這里還有一個小的update 在本集發布的時候 Google也對爆發式增長的 Chad GPT做出了回應 正在測試一個基于Lambda 模型的聊天機器人 ApprenticeBot 正式發布后會有怎樣的驚喜 我們都拭目以待 AI無疑是未來幾年 最令人興奮的變量之一 莫妮凱也希望未來能邀請到更多 一線從業者 從不同角度討論這個話題 不論是想要做創業 研究 產品 還是投資的同學 希望這些對話 對于大家了解這些技術演進 商業的可能 甚至未來對于我們每個人 每個社會意味著什么 都能引發一些思考 提供一些啟發 這次的討論有些技術硬核 需要各位對生成式AI 大模型都有一些基礎了解 討論中涉及到的論文和重要概念 也會總結在本集的簡介中 供大家復習參考 幾位嘉賓在北美工作生活多年 夾雜英文在所難免 也請大家體諒了 歡迎來到未來 希望大家enjoy從轉錄的結果來看,有一個好消息和一個壞消息。好消息是,語音識別的轉錄效果非常好。我們看到盡管播客里面混雜著中英文,但是Whisper還是很好地識別出來了。壞消息是,轉錄出來的內容只有空格的分隔符,沒有標點符號。
不過,這個問題也并不難解決。我們只要在前面的代碼里面,增加一個Prompt參數就好了。
audio_file= open("./data/podcast_clip.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file,prompt="這是一段中文播客內容。")
print(transcript['text'])輸出結果:
歡迎來到 Onboard,真實的一線經驗,走新的投資思考。 我是 Monica。 我是高寧。我們一起聊聊軟件如何改變世界。 大家好,歡迎來到 Onboard,我是 Monica。 自從 OpenAI 發布的 ChatGBT 掀起了席卷世界的 AI 熱潮, 不到三個月就積累了超過一億的越活用戶,超過一千三百萬的日活用戶。 真的是展現了 AI 讓人驚嘆的能力, 也讓很多人直呼這就是下一個互聯網的未來。 有不少觀眾都說希望我們再做一期 AI 的討論, 于是這次硬核討論就來了。 這次我們請來了 Google Brain 的研究員雪芝, 她是 Google 大語言模型 PAMP,Pathway Language Model 的作者之一。 要知道,這個模型的參數量是 GPT-3 的三倍還多。 另外還有兩位 AI 產品大牛,一位來自著名的 Stable Diffusion 背后的商業公司 Stability AI, 另一位來自某硅谷科技大廠,也曾在吳恩達教授的 Landing AI 中擔任產品負責人。 此外,Monica 還邀請到一位一直關注 AI 的投資人朋友 Bill 當作我的特邀共同主持嘉賓。 我們主要討論幾個話題,一方面從研究的視角,最前沿的研究者在關注什么? 現在技術的天花板和未來大的變量可能會在哪里? 從產品和商業的角度,什么是一個好的 AI 產品? 整個生態可能隨著技術有怎樣的演變? 更重要的,我們又能從上一波 AI 的創業熱潮中學到什么? 最后,Monica 和 Bill 還會從投資人的視角做一個回顧、總結和暢想。 這里還有一個小的 update,在本集發布的時候, Google 也對爆發式增長的ChatGPT 做出了回應, 正在測試一個基于 Lambda 模型的聊天機器人 ApprenticeBot。 正式發布后會有怎樣的驚喜?我們都拭目以待。 AI 無疑是未來幾年最令人興奮的變量之一, Monica 也希望未來能邀請到更多一線從業者從不同角度討論這個話題。 不論是想要做創業、研究、產品還是投資的同學, 希望這些對話對于大家了解這些技術演進、商業的可能, 甚至未來對于我們每個人、每個社會意味著什么, 都能引發一些思考,提供一些啟發。 這次的討論有些技術硬核,需要各位對生成式 AI 大模型都有一些基礎了解。 討論中涉及到的論文和重要概念,也會總結在本集的簡介中,供大家復習參考。 幾位嘉賓在北美工作生活多年,夾雜英文在所難免,也請大家體諒了。 歡迎來到未來,大家 enjoy!我們在transcribe函數被調用的時候,傳入了一個Prompt參數。里面是一句引導Whisper模型的提示語。在這里,我們的Prompt里用了一句中文介紹,并且帶上了標點符號。你就會發現,transcribe函數轉錄出來的內容也就帶上了正確的標點符號。
不過,轉錄出來的內容還有一點小小的瑕疵。那就是中英文混排的內容里面,英文前后會多出一些空格。那我們就再修改一下Prompt,在提示語里面也使用中英文混排并且不留空格。
audio_file= open("./data/podcast_clip.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file,prompt="這是一段Onboard播客的內容。")
print(transcript['text'])輸出結果:
歡迎來到Onboard,真實的一線經驗,走新的投資思考。 我是Monica,我是高寧,我們一起聊聊軟件如何改變世界。 大家好,歡迎來到Onboard,我是Monica。 自從OpenAI發布的ChatGBT掀起了席卷世界的AI熱潮, 不到三個月就積累了超過一億的越活用戶,超過1300萬的日活用戶。 真的是展現了AI讓人驚嘆的能力,也讓很多人直呼這就是下一個互聯網的未來。 有不少觀眾都說希望我們再做一期AI的討論,于是這次硬核討論就來了。 這次我們請來了Google Brain的研究員雪芝, 她是Google大語言模型POM,Pathway Language Model的作者之一。 要知道這個模型的參數量是GPT-3的三倍還多。 另外還有兩位AI產品大牛,一位來自著名的Stable Diffusion背后的商業公司Stability AI, 另一位來自某硅谷科技大廠,也曾在吳恩達教授的Landing AI中擔任產品負責人。 此外,Monica還邀請到一位一直關注AI的投資人朋友Bill,當做我的特邀共同主持嘉賓。 我們主要討論幾個話題,一方面從研究的視角,最前沿的研究者在關注什么? 現在的技術的天花板和未來大的變量可能會在哪里? 從產品和商業的角度,什么是一個好的AI產品? 整個生態可能隨著技術有怎樣的演變? 更重要的,我們又能從上一波AI的創業熱潮中學到什么? 最后,Monica和Bill還會從投資人的視角做一個回顧、總結和暢想。 這里還有一個小的update,在本集發布的時候, Google也對爆發式增長的ChatGPT做出了回應, 正在測試一個基于Lambda模型的聊天機器人ApprenticeBot。 正式發布后會有怎樣的驚喜?我們都拭目以待。 AI無疑是未來幾年最令人興奮的變量之一, Monica也希望未來能邀請到更多一線從業者從不同角度討論這個話題。 不論是想要做創業、研究、產品還是投資的同學, 希望這些對話對于大家了解這些技術演進、商業的可能, 甚至未來對于我們每個人、每個社會意味著什么, 都能引發一些思考,提供一些啟發。 這次的討論有些技術硬核,需要各位對生成式AI、大模型都有一些基礎了解。 討論中涉及到的論文和重要概念,也會總結在本集的簡介中,供大家復習參考。 幾位嘉賓在北美工作生活多年,夾雜英文在所難免,也請大家體諒了。 歡迎來到未來,大家enjoy!可以看到,輸出結果的英文前后也就沒有空格了。 能夠在音頻內容的轉錄之前提供一段Prompt,來引導模型更好地做語音識別,是Whisper模型的一大亮點。 如果你覺得音頻里面會有很多專有名詞,模型容易識別錯,你就可以在Prompt里加上對應的專有名詞。比如,在上面的內容轉錄里面,模型就把ChatGPT也聽錯了,變成了ChatGBT。Google的PALM模型也給聽錯了,聽成了POM。對應的全稱Pathways Language Model也少了一個s。而針對這些錯漏,我們只要再修改一下Prompt,它就能夠轉錄正確了。
audio_file= open("./data/podcast_clip.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file,prompt="這是一段Onboard播客,里面會聊到ChatGPT以及PALM這個大語言模型。這個模型也叫做Pathways Language Model。")
print(transcript['text'])輸出結果:
歡迎來到Onboard,真實的一線經驗,走新的投資思考。我是Monica。 我是高寧。我們一起聊聊軟件如何改變世界。 大家好,歡迎來到Onboard,我是Monica。 自從OpenAI發布的ChatGPT掀起了席卷世界的AI熱潮,不到三個月就積累了超過一億的越活用戶,超過1300萬的日活用戶。 真的是展現了AI讓人驚嘆的能力,也讓很多人直呼這就是下一個互聯網的未來。 有不少觀眾都說希望我們再做一期AI的討論,于是這次硬核討論就來了。 這次我們請來了Google Brain的研究員雪芝,她是Google大語言模型PALM Pathways Language Model的作者之一。 要知道,這個模型的參數量是GPT-3的三倍還多。 另外還有兩位AI產品大牛,一位來自著名的Stable Diffusion背后的商業公司Stability AI, 另一位來自某硅谷科技大廠,也曾在吳恩達教授的Landing AI中擔任產品負責人。 此外,Monica還邀請到一位一直關注AI的投資人朋友Bill當作我的特邀共同主持嘉賓。 我們主要討論幾個話題,一方面從研究的視角,最前沿的研究者在關注什么? 現在的技術的天花板和未來大的變量可能會在哪里? 從產品和商業的角度,什么是一個好的AI產品? 整個生態可能隨著技術有怎樣的演變? 更重要的,我們又能從上一波AI的創業熱潮中學到什么? 最后,Monica和Bill還會從投資人的視角做一個回顧、總結和暢想。 這里還有一個小的update,在本集發布的時候,Google也對爆發式增長的Chat GPT做出了回應。 正在測試一個基于Lambda模型的聊天機器人ApprenticeBot。 證實發布后會有怎樣的驚喜,我們都拭目以待。 AI無疑是未來幾年最令人興奮的變量之一。 Monica也希望未來能邀請到更多一線從業者從不同角度討論這個話題。 不論是想要做創業、研究、產品還是投資的同學, 希望這些對話對于大家了解這些技術演進、商業的可能,甚至未來對于我們每個人、每個社會意味著什么都能引發一些思考,提供一些啟發。 這次的討論有些技術硬核,需要各位對生成式AI大模型都有一些基礎了解。 討論中涉及到的論文和重要概念也會總結在本集的簡介中,供大家復習參考。 幾位嘉賓在北美工作生活多年,夾雜英文在所難免,也請大家體諒了。 歡迎來到未來,大家enjoy!出現這個現象的原因,主要和Whisper的模型原理相關,它也是一個和GPT類似的模型,會用前面轉錄出來的文本去預測下一幀音頻的內容。通過在最前面加上文本Prompt,就會影響后面識別出來的內容的概率,也就是能夠起到給專有名詞“糾錯”的作用。
除了模型名稱、音頻文件和Prompt之外,transcribe接口還支持這樣三個參數。
- response_format,也就是返回的文件格式,我們這里是默認值,也就是JSON。實際你還可以選擇TEXT這樣的純文本,或者SRT和VTT這樣的音頻字幕格式。這兩個格式里面,除了文本內容,還會有對應的時間信息,方便你給視頻和音頻做字幕。你可以直接試著運行一下看看效果。
- temperature,這個和我們之前在ChatGPT類型模型里的參數含義類似,就是采樣下一幀的時候,如何調整概率分布。這里的參數范圍是0-1之間。
- language,就是音頻的語言。提前給模型指定音頻的語言,有助于提升模型識別的準確率和速度。
這些參數你都可以自己試著改一下,看看效果。
audio_file= open("./data/podcast_clip.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file, response_format="srt",prompt="這是一段Onboard播客,里面會聊到PALM這個大語言模型。這個模型也叫做Pathways Language Model。")
print(transcript)輸出結果:
1
00:00:01,000 --> 00:00:07,000
歡迎來到Onboard,真實的一線經驗,走新的投資思考。我是Monica。
2
00:00:07,000 --> 00:00:11,000
我是高寧。我們一起聊聊軟件如何改變世界。
3
00:00:15,000 --> 00:00:17,000
大家好,歡迎來到Onboard,我是Monica。
4
00:00:17,000 --> 00:00:28,000
自從OpenAI發布的ChatGBT掀起了席卷世界的AI熱潮,不到三個月就積累了超過一億的越活用戶,超過1300萬的日活用戶。
5
00:00:28,000 --> 00:00:34,000
真的是展現了AI讓人驚嘆的能力,也讓很多人直呼這就是下一個互聯網的未來。
6
00:00:34,000 --> 00:00:41,000
有不少觀眾都說希望我們再做一期AI的討論,于是這次硬核討論就來了。
7
...
歡迎來到未來,大家enjoy!轉錄的時候順便翻譯一下
除了基本的音頻轉錄功能,Whisper的API還額外提供了一個叫做translation的接口。這個接口可以在轉錄音頻的時候直接把語音翻譯成英文,我們不妨來試一下。
audio_file= open("./data/podcast_clip.mp3", "rb")
translated_prompt="""This is a podcast discussing ChatGPT and PaLM model.
The full name of PaLM is Pathways Language Model."""
transcript = openai.Audio.translate("whisper-1", audio_file,prompt=translated_prompt)
print(transcript['text'])輸出結果:
Welcome to Onboard. Real first-line experience. New investment thinking. I am Monica. I am Gao Ning. Let's talk about how software can change the world. Hello everyone, welcome to Onboard. I am Monica. Since the release of ChatGPT by OpenAI, the world's AI has been in a frenzy. In less than three months, it has accumulated more than 100 million active users, and more than 13 million active users. It really shows the amazing ability of AI. It also makes many people say that this is the future of the next Internet. Many viewers said that they wanted us to do another AI discussion. So this discussion came. This time we invited a researcher from Google Brain, Xue Zhi. He is one of the authors of Google's large-scale model PaLM, Pathways Language Model. You should know that the number of parameters of this model is three times more than ChatGPT-3. In addition, there are two AI product big cows. One is from the famous company behind Stable Diffusion, Stability AI. The other is from a Silicon Valley technology factory. He was also the product manager in Professor Wu Wenda's Landing AI. In addition, Monica also invited a friend of AI who has been paying attention to AI, Bill, as my special guest host. We mainly discuss several topics. On the one hand, from the perspective of research, what are the most cutting-edge researchers paying attention to? Where are the cutting-edge technologies and the large variables of the future? From the perspective of products and business, what is a good AI product? What kind of evolution may the whole state follow? More importantly, what can we learn from the previous wave of AI entrepreneurship? Finally, Monica and Bill will also make a review, summary and reflection from the perspective of investors. Here is a small update. When this issue was released, Google also responded to the explosive growth of ChatGPT. We are testing an Apprentice Bot based on Lambda model. What kind of surprises will be released? We are looking forward to it. AI is undoubtedly one of the most exciting variables in the coming years. Monica also hopes to invite more first-line entrepreneurs to discuss this topic from different angles. Whether you want to do entrepreneurship, research, product or investment, I hope these conversations will help you understand the possibilities of these technical horizons and business. Even in the future, it can cause some thoughts and inspire us to think about what it means to each person and each society. This discussion is a bit technical, and requires you to have some basic understanding of the biometric AI model. The papers and important concepts involved in the discussion will also be summarized in this episode's summary, which is for your reference. You have worked in North America for many years, and you may have some English mistakes. Please understand. Welcome to the future. Enjoy. Let me give you a brief introduction. Some of your past experiences. A fun fact. Using an AI to represent the world is now palped.這個接口只能把內容翻譯成英文,不能變成其他語言。所以對應的,Prompt也必須換成英文。只能翻譯成英文對我們來說稍微有些可惜了。如果能夠指定翻譯的語言,很多英文播客,我們就可以直接轉錄成中文來讀了。現在我們要做到這一點,就不得不再花一份錢,讓ChatGPT來幫我們翻譯。
通過分割音頻來處理大文件
剛才我們只是嘗試轉錄了一個3分鐘的音頻片段,那接下來我們就來轉錄一下整個音頻。不過,我們沒法把整個150分鐘的播客一次性轉錄出來,因為OpenAI限制Whisper一次只能轉錄25MB大小的文件。所以我們要先把大的播客文件分割成一個個小的片段,轉錄完之后再把它們拼起來。我們可以選用OpenAI在官方文檔里面提供的 PyDub 的庫 來分割文件。
不過,在分割之前,我們先要通過FFmpeg把從listennotes下載的MP4文件轉換成MP3格式。你不了解FFmpeg或者沒有安裝也沒有關系,對應的命令我是讓ChatGPT寫的。轉換后的文件我也放到了 課程 Github 庫 里的網盤地址了。
ffmpeg -i ./data/podcast_long.mp4 -vn -c:a libmp3lame -q:a 4 ./data/podcast_long.mp3分割MP3文件的代碼也很簡單,我們按照15分鐘一個片段的方式,把音頻切分一下就好了。通過PyDub的AudioSegment包,我們可以把整個長的MP3文件加載到內存里面來變成一個數組。里面每1毫秒的音頻數據就是數組里的一個元素,我們可以很容易地將數組按照時間切分成每15分鐘一個片段的新的MP3文件。
先確保我們安裝了PyDub包。
%pip install -U pydub代碼:
from pydub import AudioSegmentpodcast = AudioSegment.from_mp3("./data/podcast_long.mp3")# PyDub handles time in milliseconds
ten_minutes = 15 * 60 * 1000total_length = len(podcast)start = 0
index = 0
while start < total_length:end = start + ten_minutesif end < total_length:chunk = podcast[start:end]else:chunk = podcast[start:]with open(f"./data/podcast_clip_{index}.mp3", "wb") as f:chunk.export(f, format="mp3")start = endindex += 1在切分完成之后,我們就一個個地來轉錄對應的音頻文件,對應的代碼就在下面。
prompt = "這是一段Onboard播客,里面會聊到ChatGPT以及PALM這個大語言模型。這個模型也叫做Pathways Language Model。"
for i in range(index):clip = f"./data/podcast_clip_{i}.mp3"audio_file= open(clip, "rb")transcript = openai.Audio.transcribe("whisper-1", audio_file,prompt=prompt)# mkdir ./data/transcripts if not existsif not os.path.exists("./data/transcripts"):os.makedirs("./data/transcripts")# write to filewith open(f"./data/transcripts/podcast_clip_{i}.txt", "w") as f:f.write(transcript['text'])# get last sentence of the transcriptsentences = transcript['text'].split("。")prompt = sentences[-1]在這里,我們對每次進行轉錄的Prompt做了一個小小的特殊處理。我們把前一個片段轉錄結果的最后一句話,變成了下一個轉錄片段的提示語。這樣,我們可以讓后面的片段在進行語音識別的時候,知道前面最后說了什么。這樣做,可以減少錯別字的出現。
通過開源模型直接在本地轉錄
通過OpenAI的Whisper API來轉錄音頻是有成本的,目前的定價是 0.006 美元/分鐘。比如我們上面的150分鐘的音頻文件,只需要不到1美元,其實已經很便宜了。不過,如果你不想把對應的數據發送給OpenAI,避免任何數據泄露的風險,你還有另外一個選擇,那就是直接使用OpenAI開源出來的模型就好了。
不過使用開源模型你還是需要一塊GPU,如果沒有的話,你仍然可以使用免費的Colab的Notebook環境。
先安裝openai-whisper的相關的依賴包。
%pip install openai-whisper
%pip install setuptools-rust代碼本身很簡單,我們只是把原先調用OpenAI的API的地方,換成了加載Whisper的模型,然后在transcribe的參數上,有一些小小的差異。其他部分的代碼和前面我們調用OpenAI的Whisper API的代碼基本上是一致的。
import whispermodel = whisper.load_model("large")
index = 11 # number of fidef transcript(clip, prompt, output):result = model.transcribe(clip, initial_prompt=prompt)with open(output, "w") as f:f.write(result['text'])print("Transcripted: ", clip)original_prompt = "這是一段Onboard播客,里面會聊到ChatGPT以及PALM這個大語言模型。這個模型也叫做Pathways Language Model。\n\n"
prompt = original_prompt
for i in range(index):clip = f"./drive/MyDrive/colab_data/podcast/podcast_clip_{i}.mp3"output = f"./drive/MyDrive/colab_data/podcast/transcripts/local_podcast_clip_{i}.txt"transcript(clip, prompt, output)# get last sentence of the transcriptwith open(output, "r") as f:transcript = f.read()sentences = transcript.split("。")prompt = original_prompt + sentences[-1]有一個點你可以注意一下,Whisper的模型和我們之前看過的其他開源模型一樣,有好幾種不同尺寸。你可以通過 load_model 里面的參數來決定加載什么模型。這里我們選用的是最大的 large 模型,它大約需要10GB的顯存。因為Colab提供的GPU是英偉達的T4,有16G顯存,所以是完全夠用的。
如果你是使用自己電腦上的顯卡,顯存沒有那么大,你可以選用小一些的模型,比如small或者base。如果你要轉錄的內容都是英語的,還可以直接使用small.en這樣僅限于英語的模型。這種小的或者限制語言的模型,速度還更快。不過,如果是像我們這樣轉錄中文為主,混雜了英文的內容,那么盡可能選取大一些的模型,轉錄的準確率才會比較高。
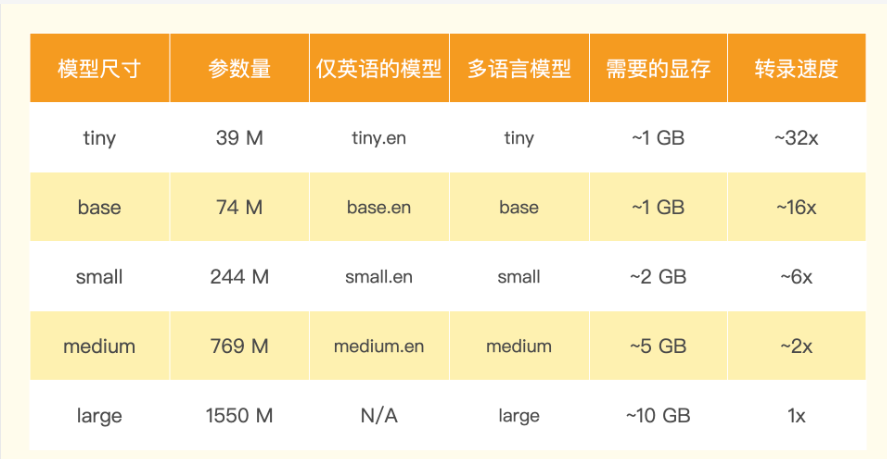
Whisper項目: https://github.com/openai/whisper
結合ChatGPT做內容小結
無論是使用API還是通過本地的GPU進行文本轉錄,我們都會獲得轉錄之后的文本。要給這些文本做個小結,其實我們在 第 10 講 講解llama-index的時候就給過示例了。我們把那個代碼稍微改寫一下,就能得到對應播客的小結。
from langchain.chat_models import ChatOpenAI
from langchain.text_splitter import SpacyTextSplitter
from llama_index import GPTListIndex, LLMPredictor, ServiceContext, SimpleDirectoryReader
from llama_index.node_parser import SimpleNodeParser# define LLM
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=1024))text_splitter = SpacyTextSplitter(pipeline="zh_core_web_sm", chunk_size = 2048)
parser = SimpleNodeParser(text_splitter=text_splitter)
documents = SimpleDirectoryReader('./data/transcripts').load_data()
nodes = parser.get_nodes_from_documents(documents)service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)list_index = GPTListIndex(nodes=nodes, service_context=service_context)
response = list_index.query("請你用中文總結一下我們的播客內容:", response_mode="tree_summarize")
print(response)輸出結果:
這個播客討論了人工智能和深度學習領域的高級技術和最新發展,包括穩定性人工智能、語言模型的預訓練方法、圖像生成模型的訓練和優化,以及各種機器學習模型的比較和應用場景。同時,我們探討了開源社區的作用和趨勢,以及開源商業化的優缺點及如何應對。我們還討論了人工智能在各個領域的應用和未來發展趨勢,并強調了找到實際應用場景和解決實際問題的重要性。最后,我們提醒說,未來值得期待的AI應用將是能夠真正跟人交互的產品,對于創業公司來說,需要從用戶實際的痛點出發去考慮如何更好地應用AI技術。基于這里的代碼,你完全可以開發一個自動抓取并小結你訂閱的播客內容的小應用。一般的播客也就是40-50分鐘一期,轉錄并小結一期的成本也就在5塊人民幣上下。
小結
好了,這一講到這里也就結束了。
OpenAI的Whisper模型,使用起來非常簡單方便。無論是通過API還是使用開源的模型,只要一行代碼調用一個transcribe函數,就能把一個音頻文件轉錄成對應的文本。而且即使對于多語言混雜的內容,它也能轉錄得很好。而通過傳入一個Prompt,它不僅能夠在整個文本里,加上合適的標點符號,還能夠根據Prompt里面的專有名詞,減少轉錄中這些內容的錯漏。雖然OpenAI的API接口限制了單個轉錄文件的大小,但是我們可以很方便地通過PyDub這樣的Python包,把音頻文件切分成多個小的片段來解決問題。
對于轉錄后的結果,我們可以很容易地使用之前學習過的ChatGPT和llama-index來進行相應的文本小結。通過組合Whisper和ChatGPT,我們就可以快速地讓機器自動幫助我們將播客、Youtube訪談,變成一段文本小結,能夠讓我們快速瀏覽并判定是否有必要深入去聽一下原始的內容。
🔥運維干貨分享
-
系統規劃與管理師備考經驗分享
-
軟考高級系統架構設計師備考學習資料
-
軟考中級數據庫系統工程師學習資料
-
軟考高級網絡規劃設計師備考學習資料
-
Kubernetes CKA認證學習資料分享
-
AI大模型學習資料合集
-
免費文檔翻譯工具(支持word、pdf、ppt、excel)
-
PuTTY中文版安裝包
-
MobaXterm中文版安裝包
-
pinginfoview網絡診斷工具中文版
-
Xshell、Xsftp、Xmanager中文版安裝包
-
辦公室摸魚神器,偽裝電腦系統更新中
-
Typora簡單易用的Markdown編輯器
-
Window進程監控工具,能自動重啟進程和卡死檢測
-
畢業設計高質量畢業答辯 PPT 模板分享
-
IT行業工程師面試簡歷模板分享




和函數(function))









)
和pow()的區別)


善于利用指針)
授權碼模式的單點登錄流程、代碼實現與安全設計)