文章目錄
- 前言
- 一、案例
- 二、破解流程
- 1.原理
- 2.找到woff文件
- 3.分析woff文件
- 4.代碼實現
- 1.轉化woff文件
- 2.繪圖并ocr識別
- 3.映射數據
- 三、總結
前言
有時我們在進行網頁抓取采集數據時,有些重要的數據比如說價格,數量等信息會進行加密,通過復制或者簡單的采集是無法采集到編碼后的文字內容的,現在貌似有不少網站都有采用這種反爬機制,作為爬蟲工程師,還是要了解甚至掌握這個技巧的。
一、案例

在某網站商品價格展示,打開F12 ,數字和符號是做了替換,顯示為???????,所以如果我們想獲取所看到的價格就要花些功夫。
二、破解流程
1.原理
其實這就是CSS反爬,CSS字體反爬是一種通過使用自定義字體和字符映射來保護頁面內容的技術。在這類技術中,網頁上的文本并非直接展示為標準字符,而是通過特殊設計的字體顯示。這樣,即使爬蟲抓取到頁面源代碼,獲得的卻是字體文件的引用,而不是實際的字符內容。
通常,這些字體文件是通過 JavaScript 動態加載的,而且在字體文件中,每個字符與其對應的可視形態之間存在一個映射關系。只有瀏覽器能夠正確渲染這些映射,爬蟲則無法直接讀取到有效的文本內容,需要我們間接獲取解析處理。
2.找到woff文件
第一種方法,通過標簽class的屬性值,例如上圖中class值:fontf04dfc98 全局搜索:

第二種方法:也是全局搜索font-face,也是同樣的效果
3.分析woff文件
把上圖帶有woff字樣的鏈接下載到本地,使用FontEditor打開woff文件,鏈接地址:https://font.qqe2.com/index.html?src=www.jspoo.com

發現這上面的字符串跟網頁的???????不一樣,那我們嘗試點擊預覽按鈕,切換eot字體如下圖:

會彈出另一個窗口,兩個窗口內容進行比較

我們是不是已經發現了網頁的不規范數字1對應?,這是不是就對應上了,接下來就是代碼實現這個流程的問題
4.代碼實現
1.轉化woff文件
from fontTools.ttLib import TTFont
font = TTFont('tansoole.woff')
font.saveXML('tansoole.xml')
運行代碼并打開部分標簽,如圖:
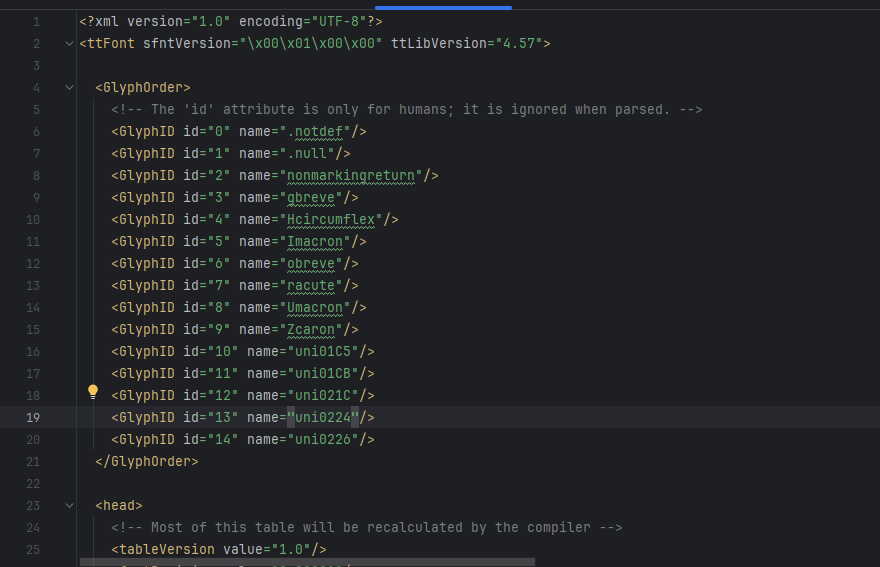
# 可以轉化獲取name值def extract_font_data_from_woff(woff_file_path):font = TTFont(woff_file_path)cmap = font.getBestCmap()code_to_name = {}for code, name in cmap.items():code_to_name[code] = namereturn code_to_namewoff_file_path = 'tansoole.woff'unicode_mapping = extract_font_data_from_woff(woff_file_path)print(unicode_mapping)#打印信息# {0: '.null', 29: '.null', 287: 'gbreve', 292: 'Hcircumflex', 298: 'Imacron', 335: 'obreve', 341: 'racute', 362: 'Umacron', 381: 'Zcaron', 453: 'uni01C5', 459: 'uni01CB', 540: 'uni021C', 548: 'uni0224', 550: 'uni0226'}# 轉化對應eot對應關系
Mapping_tables = {}
for code, mapping in unicode_mapping.items():character_key = chr(code)character_value = mappingMapping_tables[character_key] = character_value
print(Mapping_tables)
# 打印信息
# {'\x00': '.null', '\x1d': '.null', '?': 'gbreve', '?': 'Hcircumflex', 'ī': 'Imacron', '?': 'obreve', '?': 'racute', 'ū': 'Umacron', '?': 'Zcaron', '?': 'uni01C5', '?': 'uni01CB', '?': 'uni021C', '?': 'uni0224', '?': 'uni0226'}2.繪圖并ocr識別
import os
import timeimport ddddocrfrom fontTools.ttLib.ttFont import TTFont
from fontTools.pens.svgPathPen import SVGPathPen
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.path import Path
import matplotlib._color_data as mcddef ttf_to_char(font_file, glyph_set_name=None, temp_png_path="./"):# %matplotlib inline# 加載字體font = TTFont(font_file)# 7.1 生成PNG圖片# 7.1.1 第一步提取繪制命令語句# 獲取包含字形名稱和字形對象的--字形集對象glyphsetglyphset = font.getGlyphSet()# print(glyphset.keys())# 獲取pen的基類pen = SVGPathPen(glyphset)# 查找"馬"的字形對象glyph = glyphset[glyph_set_name]# 繪制"馬"的字形對象glyph.draw(pen)# 提取"馬"的繪制語句commands = pen._commands# print(commands)total_commands = []command = []for i in commands:# 每一個命令語句if i == 'Z':# 以閉合路徑指令Z區分不同輪廓線command.append(i)total_commands.append(command)command = []else:command.append(i)# 從'head'表中提取所有字形的邊界框xMin = font['head'].xMinyMin = font['head'].yMinxMax = font['head'].xMaxyMax = font['head'].yMax# print("所有字形的邊界框: xMin = {}, xMax = {}, yMin = {}, yMax = {}".format(xMin, xMax, yMin, yMax))# 所有字形的邊界框: xMin = -12, xMax = 264, yMin = -47, yMax = 220preX = 0.0preY = 0.0# 筆的起始位置startX = 0.0startY = 0.0# 所有輪廓點total_verts = []# 所有指令total_codes = []# 轉換命令for i in total_commands:# 每一條輪廓線verts = []codes = []for command in i:# 每一條輪廓線中的每一個命令code = command[0] # 第一個字符是指令vert = command[1:].split(' ') # 其余字符是坐標點,以空格分隔# M = 路徑起始 - 參數 - 起始點坐標 (x y)+if code == 'M':codes.append(Path.MOVETO) # 轉換指令verts.append((float(vert[0]), float(vert[1]))) # 提取x和y坐標# 保存筆的起始位置startX = float(vert[0])startY = float(vert[1])# 保存筆的當前位置(由于是起筆,所以當前位置就是起始位置)preX = float(vert[0])preY = float(vert[1])# Q = 繪制二次貝塞爾曲線 - 參數 - 曲線控制點和終點坐標(x1 y1 x y)+elif code == 'Q':codes.append(Path.CURVE3) # 轉換指令verts.append((float(vert[0]), float(vert[1]))) # 提取曲線控制點坐標codes.append(Path.CURVE3) # 轉換指令verts.append((float(vert[2]), float(vert[3]))) # 提取曲線終點坐標# 保存筆的當前位置--曲線終點坐標x和ypreX = float(vert[2])preY = float(vert[3])# C = 繪制三次貝塞爾曲線 - 參數 - 曲線控制點1,控制點2和終點坐標(x1 y1 x2 y2 x y)+elif code == 'C':codes.append(Path.CURVE4) # 轉換指令verts.append((float(vert[0]), float(vert[1]))) # 提取曲線控制點1坐標codes.append(Path.CURVE4) # 轉換指令verts.append((float(vert[2]), float(vert[3]))) # 提取曲線控制點2坐標codes.append(Path.CURVE4) # 轉換指令verts.append((float(vert[4]), float(vert[5]))) # 提取曲線終點坐標# 保存筆的當前位置--曲線終點坐標x和ypreX = float(vert[4])preY = float(vert[5])# L = 繪制直線 - 參數 - 直線終點(x, y)+elif code == 'L':codes.append(Path.LINETO) # 轉換指令verts.append((float(vert[0]), float(vert[1]))) # 提取直線終點坐標# 保存筆的當前位置--直線終點坐標x和ypreX = float(vert[0])preY = float(vert[1])# V = 繪制垂直線 - 參數 - 直線y坐標 (y)+elif code == 'V':# 由于是垂直線,x坐標不變,提取y坐標x = preXy = float(vert[0])codes.append(Path.LINETO) # 轉換指令verts.append((x, y)) # 提取直線終點坐標# 保存筆的當前位置--直線終點坐標x和ypreX = xpreY = y# H = 繪制水平線 - 參數 - 直線x坐標 (x)+elif code == 'H':# 由于是水平線,y坐標不變,提取x坐標x = float(vert[0])y = preYcodes.append(Path.LINETO) # 轉換指令verts.append((x, y)) # 提取直線終點坐標# 保存筆的當前位置--直線終點坐標x和ypreX = xpreY = y# Z = 路徑結束,無參數elif code == 'Z':codes.append(Path.CLOSEPOLY) # 轉換指令verts.append((startX, startY)) # 終點坐標就是路徑起點坐標# 保存筆的當前位置--起點坐標x和ypreX = startXpreY = startY# 有一些語句指令為空,當作直線處理else:codes.append(Path.LINETO) # 轉換指令verts.append((float(vert[0]), float(vert[1]))) # 提取直線終點坐標# 保存筆的當前位置--直線終點坐標x和ypreX = float(vert[0])preY = float(vert[1])# 整合所有指令和坐標total_verts.append(verts)total_codes.append(codes)color_list = list(mcd.CSS4_COLORS)# 獲取所有的輪廓坐標點total_x = []total_y = []for contour in total_verts:# 每一條輪廓曲線x = []y = []for i in contour:# 輪廓線上每一個點的坐標(x,y)x.append(i[0])y.append(i[1])total_x.append(x)total_y.append(y)if total_x == [[186.0, 186.0, 391.0, 391.0, 186.0]]:return '.'if total_x == [[0.0, 425.0, 569.0, 145.0, 0.0]]:return '/'# 創建畫布窗口fig, ax = plt.subplots()# 按照'head'表中所有字形的邊界框設定x和y軸上下限ax.set_xlim(xMin, xMax)ax.set_ylim(yMin, yMax)# 設置畫布1:1顯示ax.set_aspect(1)# 添加網格線# ax.grid(alpha=0.8,linestyle='--')# 畫圖# print(f"{glyph_set_name}======繪制圖片=======")for i in range(len(total_codes)):# (1)繪制輪廓線# 定義路徑path = Path(total_verts[i], total_codes[i])# 創建形狀,無填充,邊緣線顏色為color_list中的顏色,邊緣線寬度為2patch = patches.PathPatch(path, facecolor='none', edgecolor=color_list[i + 10], lw=2)# 將形狀添到圖中ax.add_patch(patch)# (2)繪制輪廓點--黑色,點大小為10# ax.scatter(total_x[i], total_y[i], color='black',s=10)# 保存圖片temp_path = f"{temp_png_path}/temp{int(time.time()*100000)}.png"plt.savefig(temp_path)plt.close()# print(f"{glyph_set_name}======保存圖片=======")with open(temp_path, "rb") as f:content = f.read()# print(f"{glyph_set_name}=====DdddOcr開始識別文字=======")dddd = ddddocr.DdddOcr(show_ad=False)text = dddd.classification(content)if os.path.exists(temp_path):os.remove(temp_path)return textif __name__ == '__main__':# glyph_set_name 就是上圖中的name值 這樣映射關系都對應上了res = ttf_to_char('tansoole.woff',glyph_set_name='gbreve')print(res)
3.映射數據
最后將上圖代碼流程已經結果字典映射對應就有了我們所看到的值,如圖所示:

三、總結
在字體反爬的路還有很長的路要走,本文也是筆者一些經驗和不成熟的見解,也歡迎跟各位大佬一起交流學習!







)


的使用規范)







)
特別推薦)