在企業數字化加速的背景下,越來越多的組織開始意識到:傳統的數據系統正逐漸成為增長的“瓶頸”而非“助力”。其中,SQL Server 作為許多企業IT架構中曾經的中堅力量,正面臨前所未有的挑戰。它曾以穩定、易用、成本可控等優勢,在企業各大業務系統中廣泛部署。但隨著數據規模的指數級增長與使用方式的全面升級,企業正逐步走到這樣一個轉折點:SQL Server,不夠用了。
本文將系統解析企業在面對SQL Server瓶頸時,如何構建面向未來的分布式數據架構,并分享某客戶海外業務如何從SQL Server遷移到分布式大數據平臺。

SQL Server為何“失效”?
SQL Server本質上并未失效,仍以其“高穩定、低門檻、生態豐富”而廣泛應用于中小型數據量場景中。“失效”是因為面對高復雜、高并發、高頻次數據場景時,原有架構已經“吃不動了”。SQL Server 本質上是一種典型的單體關系型數據庫系統,它適合結構化數據、事務處理和中低并發的數據操作。但隨著企業實際業務演進中,以下問題愈發凸顯:
-
數據體量突破億級,查詢變得緩慢且不穩定;
-
查詢任務越來越復雜,涉及多表join、大量邏輯判斷與計算操作;
-
查詢任務運行時間長(往往需數小時),嚴重占用計算資源,阻塞其他任務;
-
報表時效性要求提升,從天級逐漸逼近小時甚至分鐘級;
-
數據來源多樣化,SQL Server難以對接流數據、對象存儲、異構數據源。
這些問題的本質,是SQL Server的架構范式——以單體、集中式、強耦合為核心,已難以支撐“高并發、高復雜度、高異構”的現代數據需求。

遷移的底層邏輯:從“優化SQL”到“重構計算架構”
很多企業在SQL任務變慢時,第一反應往往是“調SQL”、“加索引”、“擴內存”,但效果有限。真正的出路是架構轉換——邁向分布式計算平臺。
其核心邏輯包括:
-
存儲計算解耦:將數據存儲于分布式文件系統(如HDFS、對象存儲),計算任務則由獨立計算引擎按需調度;
-
任務并行拆解:原本串行執行的大SQL語句,被拆解為多個子任務并發執行;
-
多源適配與統一治理:構建統一的數據接入層,支持關系型、半結構化、流數據等異構數據源;
-
調度與監控能力升級:實現任務級調度編排、失敗重試、運行監控、指標埋點等平臺級能力;
-
應用標準化與服務化:為后續構建指標平臺、智能洞察等高級數智應用服務能力奠定基礎。

從SQL Server到分布式大數據平臺遷移方案設計
以袋鼠云方案為例,典型的SQL Server遷移解決方案由以下五個核心步驟組成:
產品部署
目標:構建高可用、可擴展的計算與存儲平臺。
關鍵動作:
-
通過部署大數據存儲計算平臺?EasyMR?和離線平臺 BatchWorks,快速搭建分布式運行底座;
-
滿足批量計算、資源隔離、彈性擴展等企業級需求。
數據接入
目標:快速適配多種數據源,實現統一采集能力。
關鍵動作:
-
支持主流關系型數據庫(如 SQL Server、Oracle)、非關系型數據庫(如 MongoDB)、消息隊列(如 Kafka)等;
-
通過標準化連接器配置方式,實現數據源快速打通及連通性驗證。
數據同步
目標:實現歷史數據與實時數據的高效同步與治理。
關鍵動作:
-
全量同步:支持一次性將 SQL Server 中的歷史數據導入 Hive,效率可控、過程可監控;
-
增量同步:支持分鐘級的多表增量調度,保障數據實時性,適配日常運行需求。
業務SQL拆解
目標:重構 SQL 執行邏輯,提升計算效率與并發處理能力。
關鍵動作:
-
將傳統單體大 SQL 拆解為多個可并行的子任務,自動映射為 Trino 等計算引擎中的執行單元;
-
結合任務依賴關系構建工作流,支持串聯與并聯組合執行;
-
利用 MPP 架構與聯邦查詢,提升多源計算與跨表分析能力。
任務調度
目標:提供靈活穩定的調度機制,保障數據服務可靠輸出。
關鍵動作:
-
支持 Cron 表達式與多粒度調度策略,覆蓋分鐘級到小時級的調度需求;
-
調度作業可視化監控,提供實時運行狀態、資源使用情況等指標;
-
配置自動重試與告警機制,提升系統穩定性與任務成功率。

某客戶海外業務SQL Server遷移實踐:查詢任務耗時從 4?小時縮短至 20?分鐘
為應對日益增長的數據處理需求,某客戶海外業務在近期的數字化升級過程中,完成了核心數據任務從 SQL Server 向袋鼠云離線平臺 BatchWorks+大數據存儲計算平臺 EasyMR 的成功遷移,原先需運行?3-4 小時的復雜 SQL 查詢任務,現已穩定控制在?20 分鐘以內,顯著提升了運營效率與數據響應能力
業務挑戰
某客戶海外業務日常運營高度依賴數據支撐。然而,部分核心數據處理任務依然運行于傳統的 SQL Server 等關系型數據庫平臺。在任務數量龐大、邏輯復雜的情況下,大型查詢任務不僅耗時極長,還會嚴重占用系統資源,進一步影響其他任務的執行效率。
尤其典型的是某個用于運營分析的查詢任務,SQL 長度逾千行、涉及數十張數據表、字段數百不等,處理數據規模從百萬至億級。該任務每日必須執行,單次運行耗時超過 3 小時,并頻繁阻塞其他關鍵任務,成為數據系統性能的瓶頸,也限制了業務部門對關鍵指標的及時獲取。
客戶希望在不影響現有系統穩定性的前提下,通過更先進的技術架構,將該類任務耗時控制在半小時以內。
解決方案
針對客戶需求,袋鼠云基于數棧離線開發平臺與自主研發的 EMR 產品,設計并交付了一套完整的 SQL Server 向分布式平臺遷移方案,覆蓋從數據接入、任務拆解到調度執行的全流程,具體包括以下五個階段:
產品部署
構建高可用的分布式計算環境。部署 3 節點 Trino EMR 集群(6 核 CPU、32GB 內存、500GB 磁盤),配合離線開發平臺,實現統一管理與任務開發。
數據接入
接入 SQL Server 數據源,配置連接器并驗證連通性。同時預留對 MongoDB、Kafka 等多源接入能力,支持未來多樣化的數據場景。

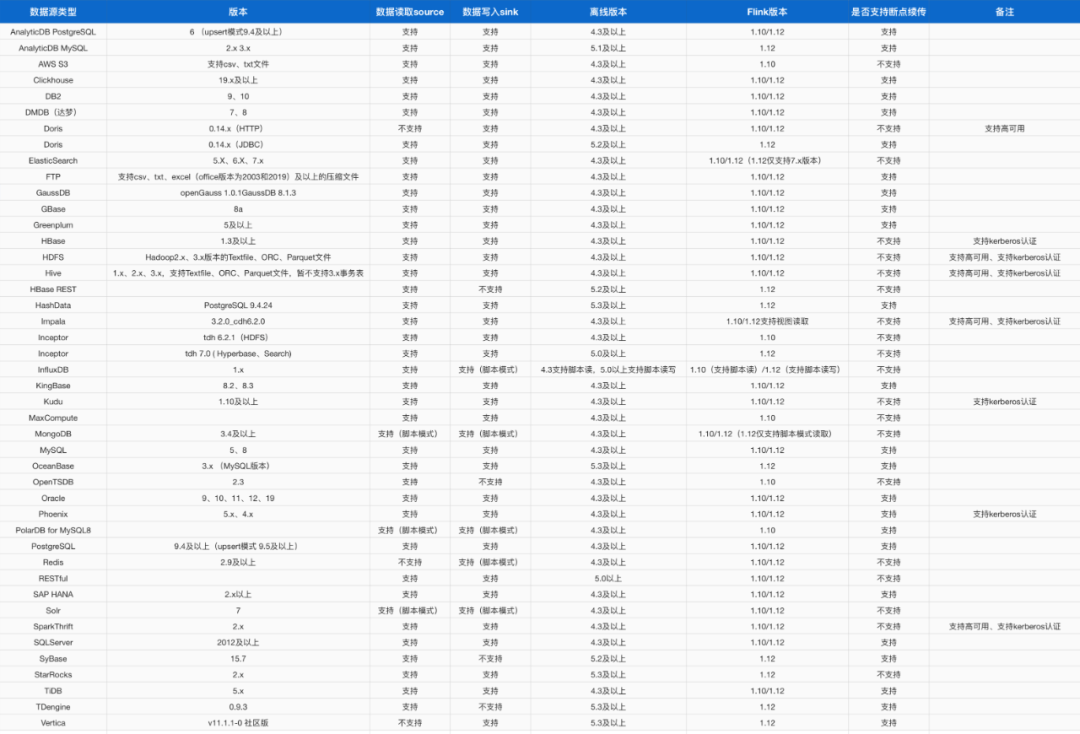
袋鼠云適配數據源清單
數據同步
一次性完成歷史數據全量同步至 Hive 表(耗時約 1 小時),后續通過日調度任務實現分鐘級增量同步,保障數據的持續更新。
業務 SQL 拆解與并行重構
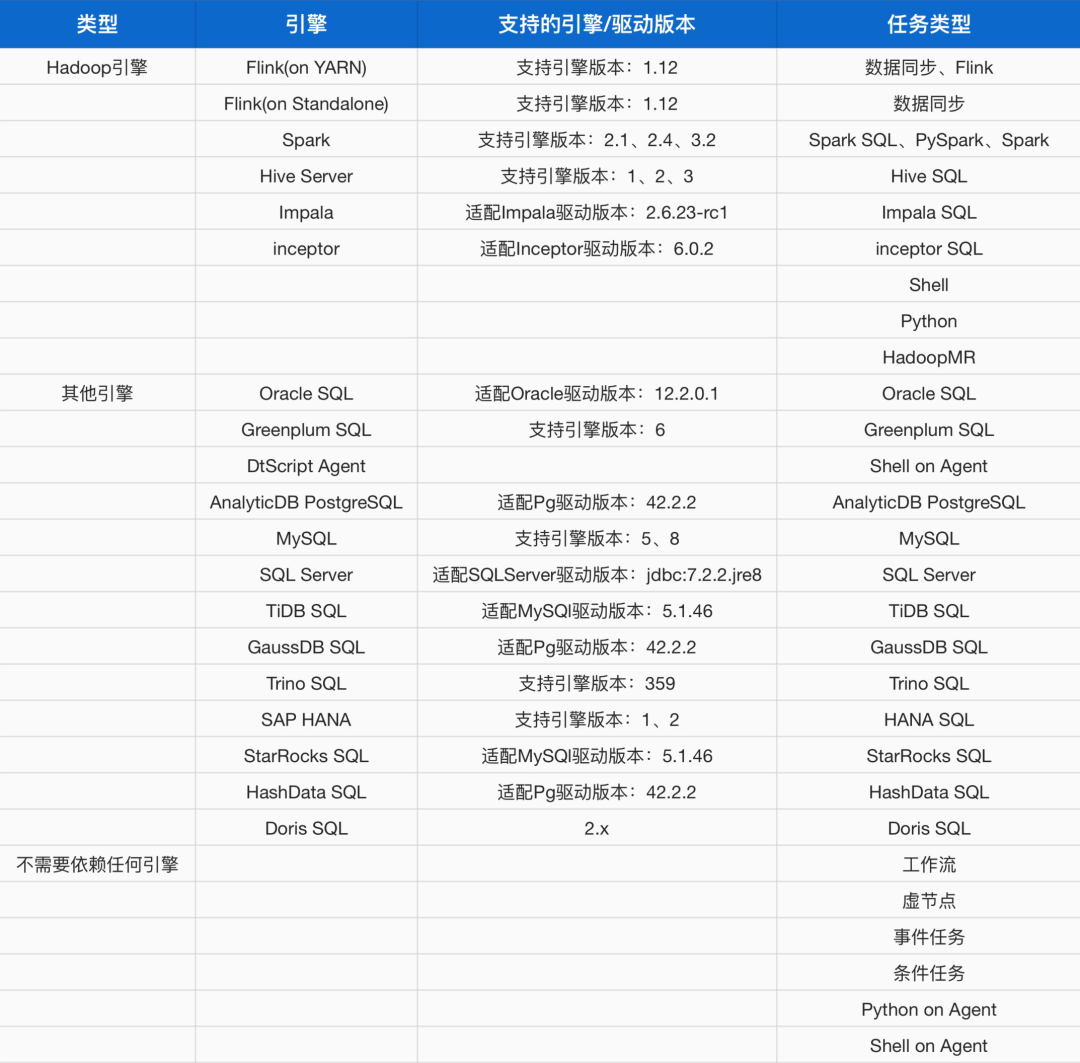
遷移后使用袋鼠EMR Trino底層計算引擎,通過Trino查詢同步到Hive中的數據,即可達到原來相同效果。同時Trino相對于 SQL Server 有如下優勢:大規模并行處理能力、多數據源聯邦查詢、彈性擴展、任務資源使用限制。離線產品不僅可以對接我們EMR中的Trino引擎,還支持對接以下引擎:
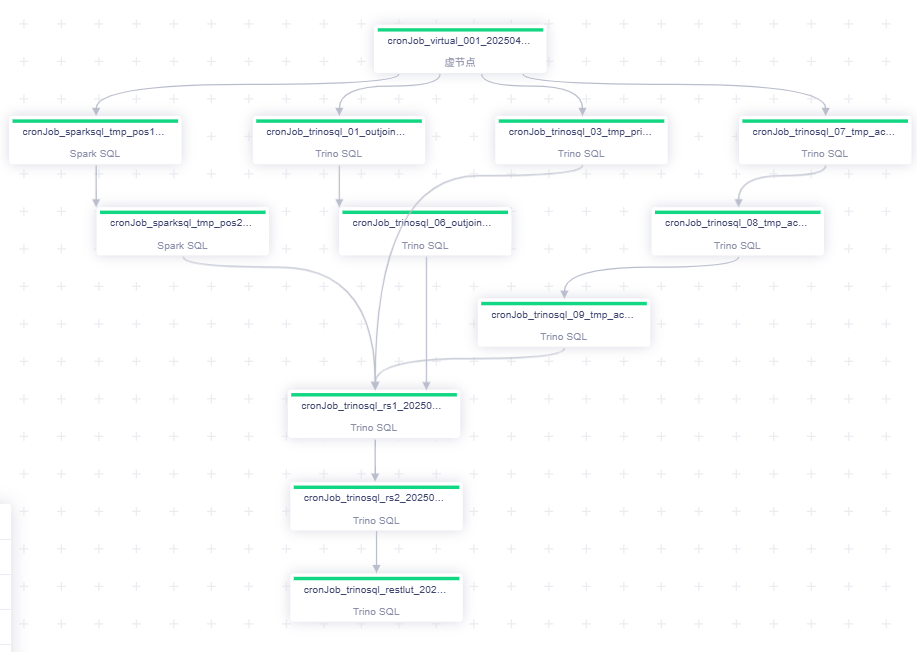
將原有復雜 SQL 按依賴關系拆解為多個子任務,通過 Trino 引擎并行執行。
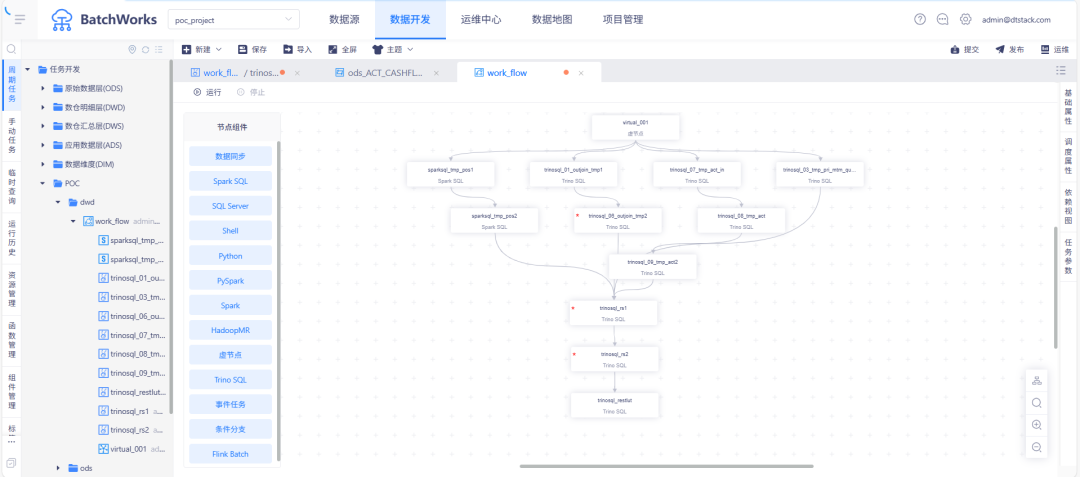
結合離線平臺的工作流定義能力,實現串并聯組合,顯著提升執行效率。
任務調度與可視化監控
基于離線平臺支持多顆粒度調度策略(分鐘/小時/天/周/Cron 等),實現任務準時運行、狀態追蹤、自動告警與失敗重試,確保數據按時產出。

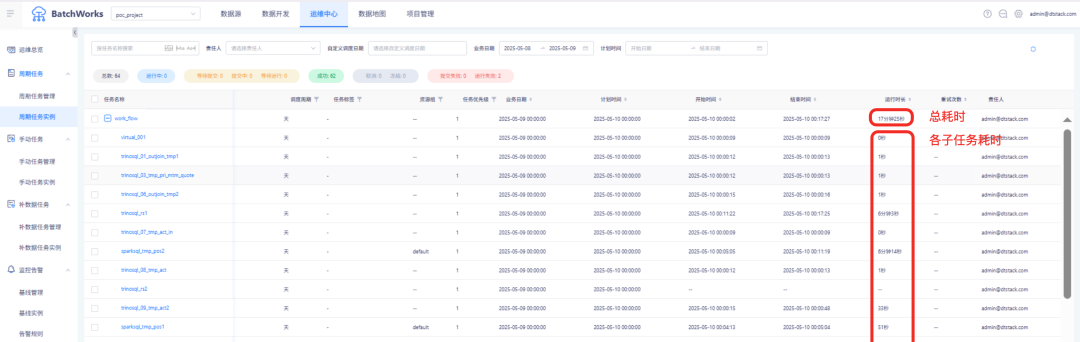
遷移成效
通過本次技術改造,該客戶海外業務的關鍵數據任務運行耗時從 3-4 小時大幅縮短至 20 分鐘以內,不僅釋放了計算資源,提升了整體任務并發能力,也為運營分析、業務決策提供了更加及時的數據支持。更重要的是,客戶團隊對新平臺的可操作性、可維護性及拓展能力給予高度認可,為后續更多業務場景的遷移與數據治理奠定了堅實基礎。



















