作者:來自騰訊云劉忠奇
2025 年 1 月,騰訊云 ES 團隊上線了 Elasticsearch 8.16.1 AI 搜索增強版,此發布版本重點提升了向量搜索、混合搜索的能力,為 RAG 類的 AI Search 場景保駕護航。除了緊跟 ES 官方在向量搜索上的大幅優化動作外,騰訊云 ES 還在此版本上默認內置了一個全新的插件 —— v-pack 插件。v-pack 名字里的 "v" 是 vector 的意思,旨在提供更加豐富、強大的向量、混合搜索能力。本文將對該版本 v-pack 插件所包含的功能做大體的介紹。
騰訊云 ES AI 搜索優化實踐 劉忠奇 20250605
一、存儲優化:突破向量搜索的存儲瓶頸
1.1 行存裁剪:無損瘦身節省 70% 存儲
技術原理
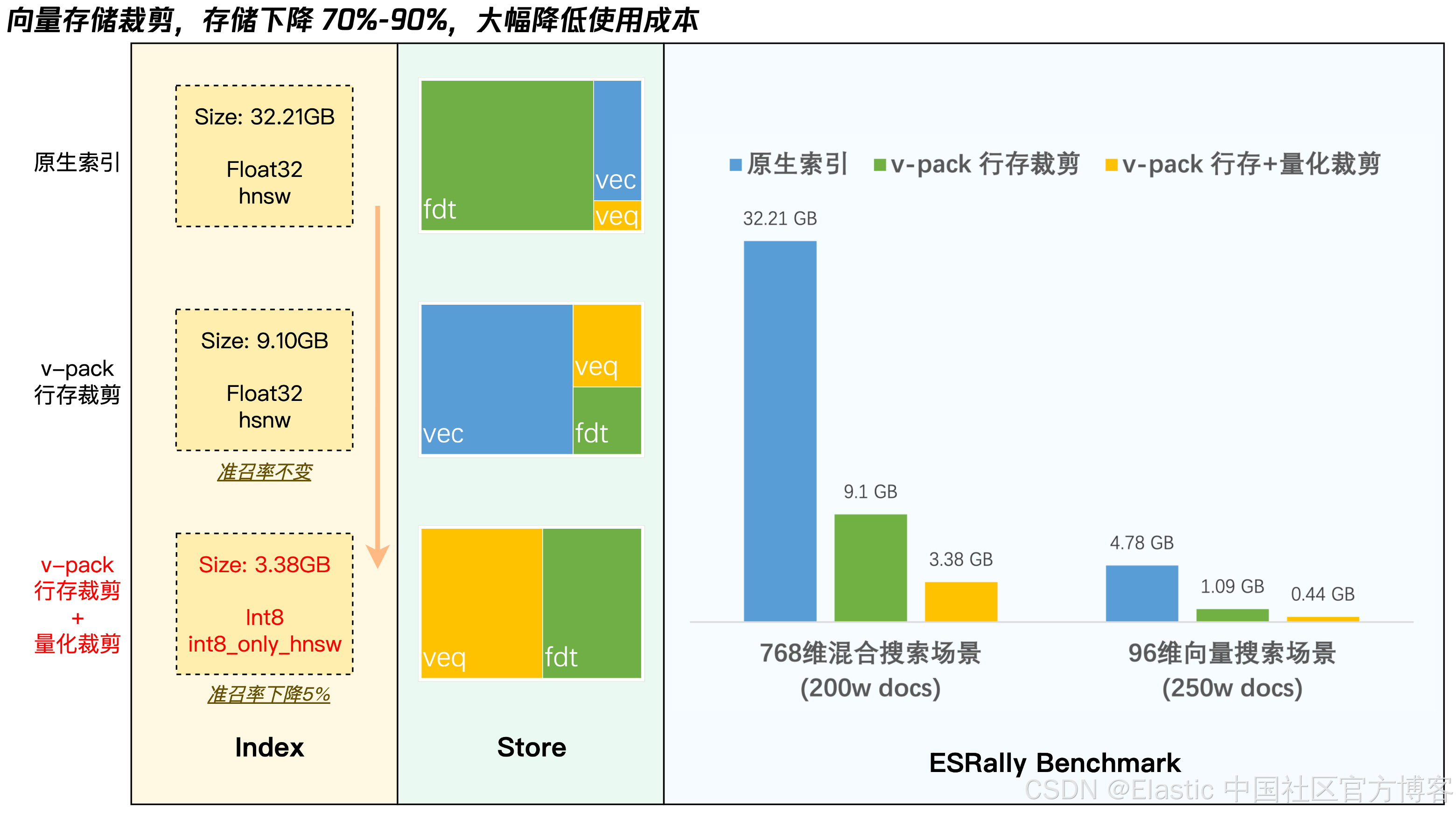
傳統 Elasticsearch 默認將向量數據同時存儲在行存?_source(.fdt)?和列存?doc_value(.dvd/.vec)?中,造成冗余。利用騰訊云 ES 貢獻給社區的向量列存讀取能力(PR #114484),在安裝了 v-pack 插件的集群上,默認無損排除?_source?中的向量(dense_vector)字段,實現存儲空間的高效利用。
技術亮點
- 動態開關:通過集群級參數?
vpack.auto_exclude_dense_vector?控制(默認開啟) - 無損兼容:通過?
docvalue_fields?語法仍可獲取原始向量值(用于業務開發調試、reindex 等操作)
實測效果
| 場景 | 原始存儲 | 優化后存儲 | 節省比例 |
|---|---|---|---|
| 純向量場景(250w條) | 4.78GB | 1.09GB | 77% |
| 混合場景(200w條) | 32.21GB | 9.10GB | 72% |
使用方法
無需手動啟用,安裝了 v-pack 插件的集群即生效。v-pack 會在創建新索引時,自動在索引 settings 中擴增 index.mapping.source.auto_exclude_types 參數來裁剪向量字段。
如需關閉,可關閉集群維度的動態開關,此后新創建的索引則不會做裁剪。
PUT _cluster/settings
{"persistent": {"vpack.auto_exclude_dense_vector": false}
}場景建議
所有生產場景
1.2 量化裁剪:極致瘦身節省 90% 存儲
技術原理
量化實際是將原始高位向量壓縮成低位向量的一種算法,如果把量化比作 “脫水”,那這類算法函數的逆運算,就可以實現反向 “復水” 得到原來的向量。當然由于低位不能完全表示高位,在精度上會有一定損失,但它帶來的是磁盤存儲的進一步下降,對于存儲有強烈需求的客戶仍然具有很高的實際意義。在上文行存裁剪的基礎上,進一步節省存儲到 90%。
技術亮點
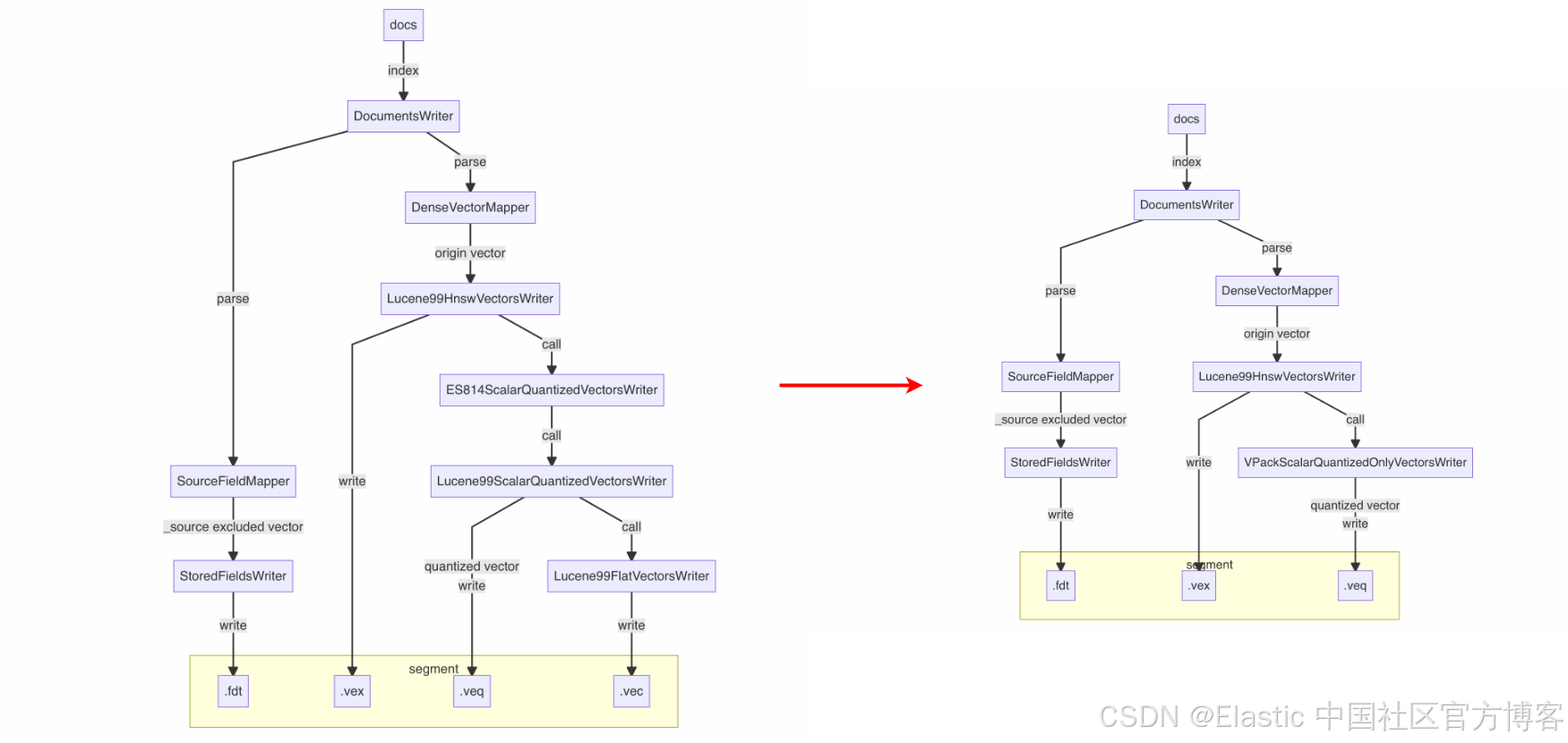
在社區標量量化技術int8_hnsw基礎上,首創int8_only_hnsw索引類型:
- “脫水”存儲:僅保留量化后的 int8 向量(
.veq文件) - 動態“復水”:merge 時通過量化參數還原近似原始向量
實測效果
| 場景 | 原始存儲 | 優化后存儲 | 節省比例 |
|---|---|---|---|
| 純向量場景(250w條) | 4.78GB | 0.44GB | 90% |
| 混合場景(200w條) | 32.21GB | 1.09GB | 91% |
技術對比
使用方法
在安裝了 v-pack 插件的集群,創建索引時,將?index_options.type?設置為?int8_only_hnsw?索引類型
PUT product_vector_index
{"mappings": {"properties": {"embedding": {"type": "dense_vector","dims": 768,"index_options": {"type": "int8_only_hnsw","m": 32,"ef_construction": 100}}}}
}場景建議
- 搜推系統:對存儲敏感的場景
- RAG 應用:海量的知識庫數據
1.3 小結
下圖展示了 v-pack 的兩種向量存儲裁剪的效果。詳細的技術方案解析詳見:《ES8向量功能窺探系列(二):向量數據的存儲與優化》
二、排序優化:多策略融合的靈活組合
2.1 權重可調 RRF 融合:
算法演進
在標準 RRF(Reciprocal Rank Fusion)公式中引入權重因子:
加權得分 = Σ( weight_i / (k + rank_i) )突破傳統多路召回等權融合的限制,支持業務自定義權重策略。
混合排序示例
GET news/_search
{"retriever": {"rank_fusion": {"retrievers": [{"standard": {"query": {"match": {"title": "人工智能"}}}},{"knn": {"field": "vector","query_vector": [...],"k": 50}}],"weights": [2, 1],"rank_constant": 20}}
}適用場景
- 電商搜索:提升關鍵詞權重(權重比 3:1 或更大)
- 內容推薦:增強語義相關性(權重比 1:2 或更大)
- 知識庫檢索:平衡語義與關鍵詞(權重比 1:1 微調)
2.2 歸一化 Score 融合
算法原理
通過動態歸一化將不同評分體系統一到 0,1 區間:
- BM25 歸一化:
(score - min_score)/(max_score - min_score) - 向量相似度歸一化:
cosine_similarity + 1 / 2
混合排序示例
{"retriever": {"score_fusion": {"retrievers": [...],"weights": [1.5, 1]}}
}適用場景
- 結果可解釋性強
- 多維度加權評分的精排搜索
2.3 基于模型的 Rerank 融合
算法原理
借助騰訊云智能搜索的原子能力,騰訊云 ES 8.16.1 搜索增強版,已支持調用第三方 rerank 模型對混合搜索的結果進行重排。當前已支持內置下列重排序模型,這些模型都部署在 GPU 上,性能有極大提升。
| 原子服務 | token限制 | 維度 | 語言 | 備注 |
|---|---|---|---|---|
| bge-reranker-large | 514 | 1024 | 中文、英文 | bge經典模型 |
| bge-reranker-v2-m3 | 8194 | 1024 | 多語言 | bge經典模型 |
| bge-reranker-v2-minicpm-layerwise | 2048 | 2304 | 多語言 | 在英語和中文水平上均表現良好,可以自由選擇輸出層,有助于加速推理 |
使用示例
PUT _inference/rerank/tencentcloudapi_bge-reranker-large
{"service": "tencent_cloud_ai_search","service_settings": {"secret_id": "xxx","secret_key": "xxx","url": "https://aisearch.internal.tencentcloudapi.com","model_id": "bge-reranker-large","region": "ap-beijing","language": "zh-CN","version": "2024-09-24"}
}POST _inference/rerank/tencentcloudapi_bge-reranker-large
{"query": "中國","input": ["美國","中國","英國"]
}{"rerank": [{"index": 1,"relevance_score": 0.99990976,"text": "中國"},{"index": 0,"relevance_score": 0.013636836,"text": "美國"},{"index": 2,"relevance_score": 0.00941259,"text": "英國"}]
}混合排序示例
{"retriever": {"tencent_cloud_ai_reranker": {"retrievers": [...],"model_id": "tencentcloudapi_bge-reranker-large", "rank_field": "content","rank_text": "nice day","rank_window_size": 10, "min_score": 0.6}}
}適用場景
- 對語義相關性有更高需求的場景
- 對準召率有更高需求的場景
2.4 小結
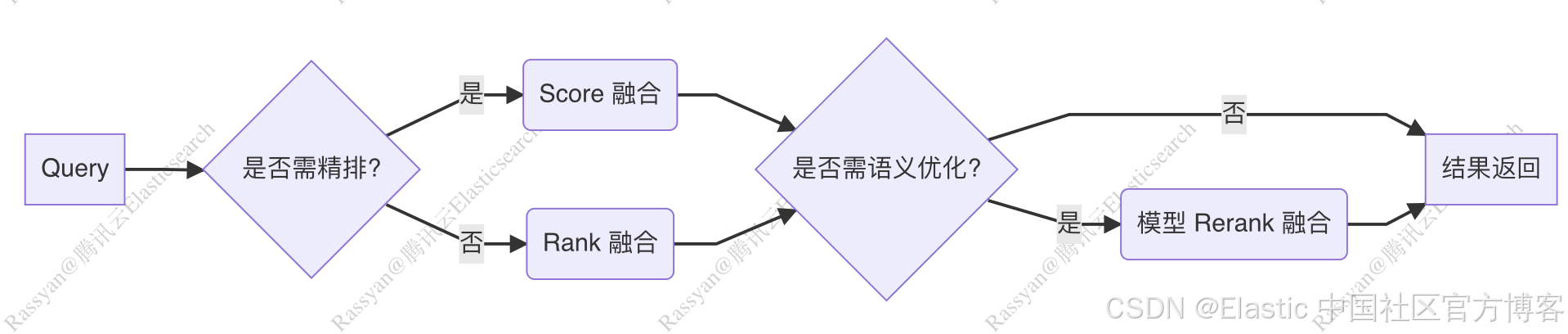
下圖展示了 v-pack 提供的多種融合排序算法,所帶來的更豐富的準召率提升手段。

v-pack 提供的融合算法,支持自定義的靈活組合,可以參考如下的做法來組合使用。
三、推理飛躍:無縫連接最強模型
3.1 對話推理:一鍵接入滿血 Deepseek 大模型
借助騰訊云智能搜索的 LLM 生成服務,騰訊云 ES 8.16.1 搜索增強版亦可以一鍵接入 DeepSeek 以及混元系列大模型進行推理。
| 模型類型 | 模型名稱(model) | Tokens | 特性 |
|---|---|---|---|
| deepseek-r1 | 最大輸入128k | 最大輸出8k | 擅長復雜需求拆解、技術方案直譯,提供精準結構化分析及可落地方案,實現了與GPT-4o和Claude Sonnet 3.5等頂尖模型相媲美的性能 |
| deepseek-v3 | 最大輸入128k | 最大輸出8k | 通用型AI模型,擁有龐大參數規模及強大多任務泛化能力,擅長開放域對話、知識問答、創意生成等多樣化需求 |
| deepseek-r1-distill-qwen-32b | 最大輸入128k | 最大輸出8k | r1-36b參數蒸餾版,效果沒有r1好,但響應速度更快,資源成本更低 |
| hunyuan-turbo | 最大輸入28k | 最大輸出4k | 騰訊新一代旗艦大模型,混元Turbo模型,在語言理解、文本創作、數學、推理和代碼等領域都有較大提升,具備強大的知識問答能力 |
| ... |
使用示例
PUT _inference/completion/deepseek
{"service": "tencent_cloud_ai_search","service_settings": {"secret_id": "xxx","secret_key": "xxx","url": "https://aisearch.internal.tencentcloudapi.com","model_id": "deepseek-v3","region": "ap-beijing","language": "zh-CN","version": "2024-09-24"}
}POST _inference/completion/deepseek
{"input": "你是誰?"
}{"completion": [{"result": "我是DeepSeek Chat,一個由深度求索公司開發的智能助手,旨在通過自然語言處理和機器學習技術來提供信息查詢、對話交流和解答問題等服務。"}]
}我們可以借助該能力,使用 Deepseek 代替 OpenAI 實現官方最佳實踐中的相關功能:https://www.elastic.co/search-labs/blog/elasticsearch-openai-completion-support
3.2 嵌入推理:接入 GPU embedding 消除推理高延遲
借助騰訊云智能搜索的 LLM 生成服務,騰訊云 ES 8.16.1 搜索增強版支持內網無縫推理,目前支持以下主流的 embedding 模型。
| 原子服務 | token限制 | 維度 | 語言 | 備注 |
|---|---|---|---|---|
| bge-base-zh-v1.5 | 512 | 768 | 中文 | bge經典模型 |
| bge-m3 | 8194 | 1024 | 多語言 | bge經典模型 |
| conan-embedding-v1 | 512 | 1792 | 中文 | 騰訊自研,在MTEB榜單一度綜合排第一 |
使用示例
PUT _inference/text_embedding/tencentcloudapi_bge_base_zh-v1.5
{"service": "tencent_cloud_ai_search","service_settings": {"secret_id": "xxx","secret_key": "xxx","url": "https://aisearch.internal.tencentcloudapi.com","model_id": "bge-base-zh-v1.5","region": "ap-beijing", "language": "zh-CN","version": "2024-09-24"}
}PUT semantic_text_index
{"mappings": {"properties": {"content": {"type": "semantic_text","inference_id": "tencentcloudapi_bge_base_zh-v1.5"}}}
}3.3 小結
借助騰訊云智能搜索的原子服務,騰訊云 ES 允許用戶將 ES 作為 AI Search 的服務中樞,成為向量、文本、模型的統一引擎,all in one 一站式地完成整套 RAG 場景的搜索和推理需求。
四、持續進化:社區貢獻與自研特性齊頭并進
騰訊云 ES 團隊持續投入開源生態建設,覆蓋最新的向量場景:
- 核心貢獻:累計提交 200+ 社區PR,向量相關 10+
讓技術回歸本質,用創新驅動價值
騰訊云 ES 將持續深耕 AI Search 基礎設施,致力服務好當今日益增長的 RAG 與多模態搜索需求,與開發者共同探索搜索技術的無限可能。

)





,支持插入 Latex 數學公式)





工程系統性學習指南:從理論基礎到實戰應用的完整體系)





