主要操作兩個對象:一維帶標簽數組?和?二維表格DataFrame
一維帶標簽數組Series
pd.Series([1, 3, 5, np.nan, 6, 8])? ,結果如下:
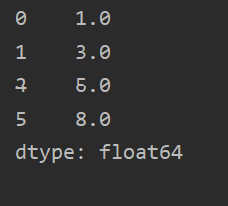
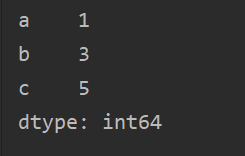
?可指定索引,pd.Series([1, 3, 5], index=['a', 'b', 'c']) ?
二維表格DataFrame
創建時需要指定列名,如
字典創建
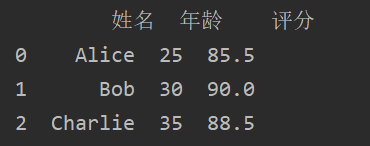
data = {'姓名': ['Alice', 'Bob', 'Charlie'],'年齡': [25, 30, 35],'評分': [85.5, 90.0, 88.5]
}
df = pd.DataFrame(data)
列表創建
列表不像字典,需額外指定列名
data = [['Alice', 25, 85.5],['Bob', 30, 90.0],['Charlie', 35, 88.5]
]
columns = ['姓名', '年齡', '評分']
df = pd.DataFrame(data, columns=columns,index=[索引內容])?index:指定行索引,為一個列表類型,長度要匹配,可以省去。默認行索引為0,1,2......
上面兩種方式結果都如下
表格數據統計
head(n)? ? ? ? ? ? ? ? 查看前n行數據
tail(n)? ? ? ? ? ? ? ?查看后n行數據
shape? ? ? ? ? ? ? ? ? 查看行數、列數
cloumns? ? ? ? ? ? ? ?查看列名
describe()? ? ? ? 統計摘要(計數、均值、標準差等)
info()? ? ? ? ? ? ? ? 查看基本信息
corr()? ? ? ? ? ? ? ? 列與列的相關系數
簡單可視化實現(用到pyplot)
將表中的單獨一行,或單獨一列數據拿出來繪制圖表
df['?列名?'].plot()? ? ? ? ? ? ? ? ? #找出某行數據,以行為x軸
df.loc[' 行索引 '].plot? ? ? ? ? ?#找出某行數據,以列為x軸
最后plt.show()即可
表格數據篩選與過濾?
索引查找
按列名索引? ? ? ? ? ? ? ? df [ '年齡' ]
按位置索引(整數)? ?? ?df.iloc [ '0' ] #第一行???????df.iloc [ 1:3,0:2?]? #第2-3行,第1-2列(左閉右開)
按標簽索引????????????????df.loc [df['年齡'] > 30] ? ? ? ? ?# 篩選年齡>30的行
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? df.loc [ :, ['姓名', '評分']] ? ? ?# 選取指定列?
按指定位置索引? ? ? ? ?df.loc ['行索引', ['A', 'B']]? ? ? #指定行+列,若表數據未指定行索引,? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? #默認按?0,1,2.....來
?篩選查找
年齡>30且評分>88的
filtered = df[(df['年齡'] > 30) & (df['評分'] > 88)]
上面方法查找到的數據,定位到之后可直接進行賦值修改
唯一值與去重
unique_names = df['姓名'].unique() # 列中唯一值
df.drop_duplicates(subset=['姓名']) # 按列去重
sort_values(by= '評分' ,ascending=False)? ? ? ? ? ? ? ? ?按評分降序排列,為True時升序
數據清洗
查找無效值,并填充NaN
isnull()? ? ? ? 顯示無效值信息
fillna(value=0, inplace=True)? ? ? 填充缺失值,inplace=False時默認填充NAN,也可以value='NaN'
刪除缺失信息的行
dropna(subset=[ '評分' ])
依次檢測subset中的列?,將每列中有NaN值存在的所在行進行刪除
一般要先進行數據清洗,將表中的空值和None值 轉換為NaN,dropna只針對NaN值進行刪除
?drop(columns=['年齡差值'], inplace=True)? ? ? ? ? ?刪除整列
df[ '年齡' ].astype( 'int' )? ? ? ? 轉換為整數類型
df.[ '評分' ].round(1)? ? ? ? ? ? ? 保留1位小數
df['年齡差值'] = df['年齡'] - df['年齡'].min()????????????????新增列(基于現有列計算)
分組
groupby( '年齡' )? ? ? ? ? ? ? ? 按年齡進行分組
df.groupby('年齡')['評分'].mean() #在年齡這一組,計算評分的平均值?groupby( '年齡' ).agg? ? ? ? ? ? ? ? 按年齡這一組,進行多列分組聚合
df.groupby('年齡').agg({'評分': 'mean','姓名': 'count'
})?表格關聯合并
表單數據進行合并連接,這里使用內連接為例,數據庫內連接、外連接不懂得可以去自行查閱
merge(df1, df2, on = 'ID'?,how = 'inner' )
df1 = pd.DataFrame({'ID': [1, 2, 3], '姓名': ['Alice', 'Bob', 'Charlie']})
df2 = pd.DataFrame({'ID': [2, 3, 4], '成績': [90, 85, 95]})# 內連接(基于ID列)
merged = pd.merge(df1, df2, on='ID', how='inner')強拼接,按維度直接進行強拼接(比較生硬)
concat([ df1, df2 ], axis =0)? ? ? ? ? ? ? ? 按行進行拼接,axis=1 為按列
導出/讀入數據
- to_csv( '文件路徑+名稱?.csv', index = False?)? ? ? ?
- 保存為csv文件,index=False表示不保存行索引
- to_excel( '文件路徑+名稱 .xlsx' , sheet_name = '表名', index = False)
- sheet_name 設置表格的名稱,默認為Sheet1,index 表示是否保存行索引
- read_csv( '文件路徑+名稱?.csv' )
- read_excel( '文件路徑+名稱 .xlsx' , sheet_name = '表名')
- sheet_name:指定為文件中的哪一個工作表
-泛型)
)




才生效的原因)




![simulink有無現成模塊可以實現將三個分開的輸入合并為一個[1*3]的行向量輸出?](http://pic.xiahunao.cn/simulink有無現成模塊可以實現將三個分開的輸入合并為一個[1*3]的行向量輸出?)
數組乘積)
:主題模型(LDA))





