原課程代碼是用Anthropic寫的,下面代碼是用OpenAI改寫的,模型則用阿里巴巴的模型做測試
.env 文件為:
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
OPENAI_API_BASE=https://dashscope.aliyuncs.com/compatible-mode/v1
完整代碼
import arxiv
import json
import os
from typing import List
from dotenv import load_dotenv
import openaiPAPER_DIR = "papers"def search_papers(topic: str, max_results: int = 5) -> List[str]:"""Search for papers on arXiv based on a topic and store their information.Args:topic: The topic to search formax_results: Maximum number of results to retrieve (default: 5)Returns:List of paper IDs found in the search"""# Use arxiv to find the papersclient = arxiv.Client()# Search for the most relevant articles matching the queried topicsearch = arxiv.Search(query = topic,max_results = max_results,sort_by = arxiv.SortCriterion.Relevance)papers = client.results(search)# Create directory for this topicpath = os.path.join(PAPER_DIR, topic.lower().replace(" ", "_"))os.makedirs(path, exist_ok=True)file_path = os.path.join(path, "papers_info.json")# Try to load existing papers infotry:with open(file_path, "r") as json_file:papers_info = json.load(json_file)except (FileNotFoundError, json.JSONDecodeError):papers_info = {}# Process each paper and add to papers_infopaper_ids = []for paper in papers:paper_ids.append(paper.get_short_id())paper_info = {'title': paper.title,'authors': [author.name for author in paper.authors],'summary': paper.summary,'pdf_url': paper.pdf_url,'published': str(paper.published.date())}papers_info[paper.get_short_id()] = paper_info# Save updated papers_info to json filewith open(file_path, "w") as json_file:json.dump(papers_info, json_file, indent=2)print(f"Results are saved in: {file_path}")return paper_idsdef extract_info(paper_id: str) -> str:"""Search for information about a specific paper across all topic directories.Args:paper_id: The ID of the paper to look forReturns:JSON string with paper information if found, error message if not found"""for item in os.listdir(PAPER_DIR):item_path = os.path.join(PAPER_DIR, item)if os.path.isdir(item_path):file_path = os.path.join(item_path, "papers_info.json")if os.path.isfile(file_path):try:with open(file_path, "r") as json_file:papers_info = json.load(json_file)if paper_id in papers_info:return json.dumps(papers_info[paper_id], indent=2)except (FileNotFoundError, json.JSONDecodeError) as e:print(f"Error reading {file_path}: {str(e)}")continuereturn f"There's no saved information related to paper {paper_id}."tools = [{"type": "function","function": {"name": "search_papers","description": "Search for papers on arXiv based on a topic and store their information","parameters": {"type": "object","properties": {"topic": {"type": "string","description": "The topic to search for"},"max_results": {"type": "integer","description": "Maximum number of results to retrieve","default": 5}},"required": ["topic"]}}},{"type": "function","function": {"name": "extract_info","description": "Search for information about a specific paper across all topic directories","parameters": {"type": "object","properties": {"paper_id": {"type": "string","description": "The ID of the paper to look for"}},"required": ["paper_id"]}}}
]mapping_tool_function = {"search_papers": search_papers,"extract_info": extract_info
}def execute_tool(tool_name, tool_args):result = mapping_tool_function[tool_name](**tool_args)if result is None:result = "The operation completed but didn't return any results."elif isinstance(result, list):result = ', '.join(result)elif isinstance(result, dict):# Convert dictionaries to formatted JSON stringsresult = json.dumps(result, indent=2)else:# For any other type, convert using str()result = str(result)return resultload_dotenv()
client = openai.OpenAI(api_key = os.getenv("OPENAI_API_KEY"),base_url= os.getenv("OPENAI_API_BASE")
) def process_query(query):messages = [{"role": "user", "content": query}]response = client.chat.completions.create(model="qwen-turbo", # 或其他OpenAI模型max_tokens=2024,tools=tools,messages=messages)process_query = Truewhile process_query:# 獲取助手的回復message = response.choices[0].message# 檢查是否有普通文本內容if message.content:print(message.content)process_query = False# 檢查是否有工具調用elif message.tool_calls:# 添加助手消息到歷史messages.append({"role": "assistant", "content": None,"tool_calls": message.tool_calls})# 處理每個工具調用for tool_call in message.tool_calls:tool_id = tool_call.idtool_name = tool_call.function.nametool_args = json.loads(tool_call.function.arguments)print(f"Calling tool {tool_name} with args {tool_args}")# 執行工具調用result = execute_tool(tool_name, tool_args)# 添加工具結果到消息歷史messages.append({"role": "tool","tool_call_id": tool_id,"content": result})# 獲取下一個回復response = client.chat.completions.create(model="qwen-turbo", # 或其他OpenAI模型max_tokens=2024,tools=tools,messages=messages)# 如果只有文本回復,則結束處理if response.choices[0].message.content and not response.choices[0].message.tool_calls:print(response.choices[0].message.content)process_query = Falsedef chat_loop():print("Type your queries or 'quit' to exit.")while True:try:query = input("\nQuery: ").strip()if query.lower() == 'quit':breakprocess_query(query)print("\n")except Exception as e:print(f"\nError: {str(e)}")if __name__ == "__main__":chat_loop()代碼解釋
導入模塊
import arxiv # 用于訪問arXiv API搜索論文
import json # 處理JSON數據
import os # 操作系統功能,如文件路徑處理
from typing import List # 類型提示
from dotenv import load_dotenv # 加載環境變量
import openai # OpenAI API客戶端
核心功能函數
1. search_papers 函數
這個函數用于在arXiv上搜索特定主題的論文并保存信息:
def search_papers(topic: str, max_results: int = 5) -> List[str]:
- 參數:
topic: 要搜索的主題max_results: 最大結果數量(默認5個)
- 返回值:找到的論文ID列表
功能流程:
- 創建arXiv客戶端
- 按相關性搜索主題相關論文
- 為該主題創建目錄(如
papers/machine_learning) - 嘗試加載已有的論文信息(如果存在)
- 處理每篇論文,提取標題、作者、摘要等信息
- 將論文信息保存到JSON文件中
- 返回論文ID列表
2. extract_info 函數
這個函數用于在所有主題目錄中搜索特定論文的信息:
def extract_info(paper_id: str) -> str:
- 參數:
paper_id- 要查找的論文ID - 返回值:包含論文信息的JSON字符串(如果找到),否則返回錯誤信息
功能流程:
- 遍歷
papers目錄下的所有子目錄 - 在每個子目錄中查找
papers_info.json文件 - 如果找到文件,檢查是否包含指定的論文ID
- 如果找到論文信息,返回格式化的JSON字符串
- 如果未找到,返回未找到的提示信息
工具定義
tools = [...]
定義了兩個函數工具,用于OpenAI API的工具調用:
search_papers- 搜索論文extract_info- 提取論文信息
每個工具都定義了名稱、描述和參數規范。
工具執行函數
def execute_tool(tool_name, tool_args):
這個函數負責執行指定的工具函數,并處理返回結果:
- 將None結果轉換為提示信息
- 將列表結果轉換為逗號分隔的字符串
- 將字典結果轉換為格式化的JSON字符串
- 其他類型轉換為字符串
OpenAI客戶端初始化
load_dotenv()
client = openai.OpenAI(api_key = os.getenv("OPENAI_API_KEY"),base_url= os.getenv("OPENAI_API_BASE")
)
從環境變量加載API密鑰和基礎URL,初始化OpenAI客戶端。
查詢處理函數
def process_query(query):
這個函數處理用戶的查詢:
- 創建包含用戶查詢的消息列表
- 調用OpenAI API創建聊天完成
- 處理助手的回復:
- 如果有普通文本內容,直接打印
- 如果有工具調用,執行工具并將結果添加到消息歷史
- 如果執行了工具調用,獲取下一個回復
- 如果最終回復只有文本,打印并結束處理
聊天循環函數
def chat_loop():
這個函數實現了一個簡單的聊天循環:
- 提示用戶輸入查詢或輸入’quit’退出
- 處理用戶的查詢
- 捕獲并顯示任何錯誤
主程序
if __name__ == "__main__":chat_loop()
當腳本直接運行時,啟動聊天循環。
總結
這個腳本實現了一個基于OpenAI API的聊天機器人,它可以:
- 搜索arXiv上的論文并保存信息
- 提取已保存的論文信息
- 通過OpenAI API處理用戶查詢
- 支持工具調用功能,實現與arXiv的交互
運行示例
目錄結構
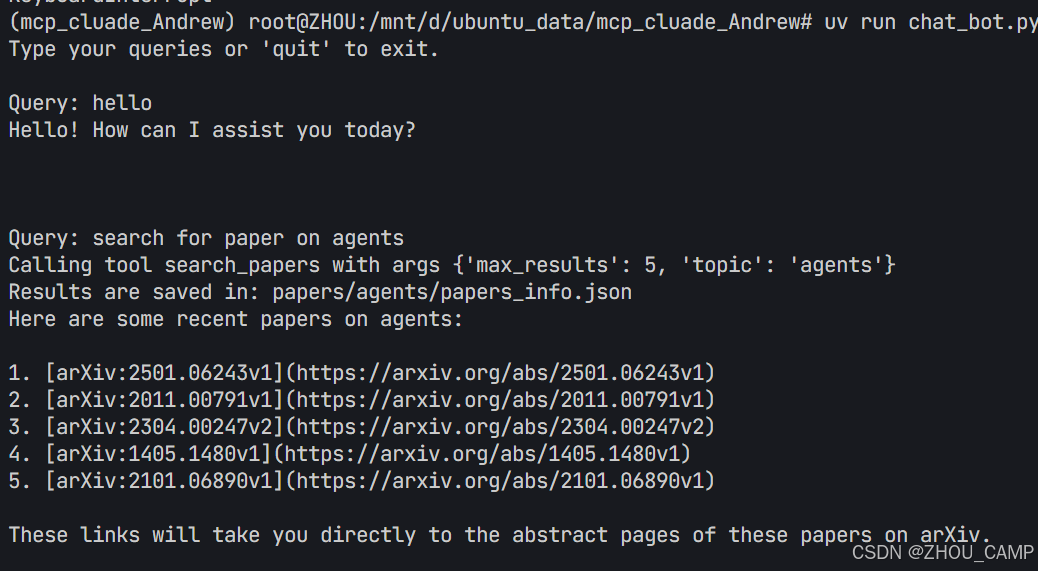
運行結果
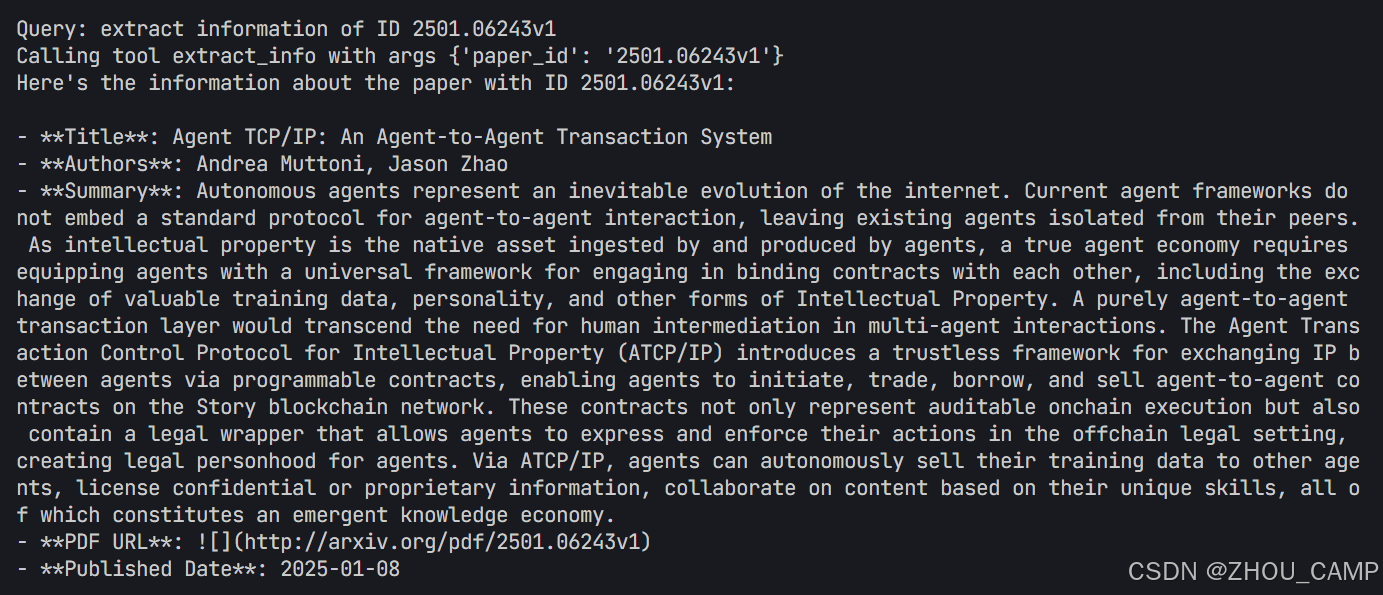












)




位運算與狀態壓縮)

