目錄
1. 前言
2. Double DQN的核心思想
3. Double DQN 實例:倒立擺
4. Double DQN的關鍵改進點
5. 雙重網絡更新策略
6. 總結
1. 前言
在強化學習領域,深度Q網絡(DQN)開啟了利用深度學習解決復雜決策問題的新篇章。然而,標準DQN存在一個顯著問題:Q值的過估計。為解決這一問題,Double DQN應運而生,它通過引入兩個網絡來減少Q值的過估計,從而提高策略學習的穩定性和性能。本文將深入淺出地介紹Double DQN的核心思想,并通過一個完整python實現案例,幫助大家全面理解強化這一學習算法。
2. Double DQN的核心思想
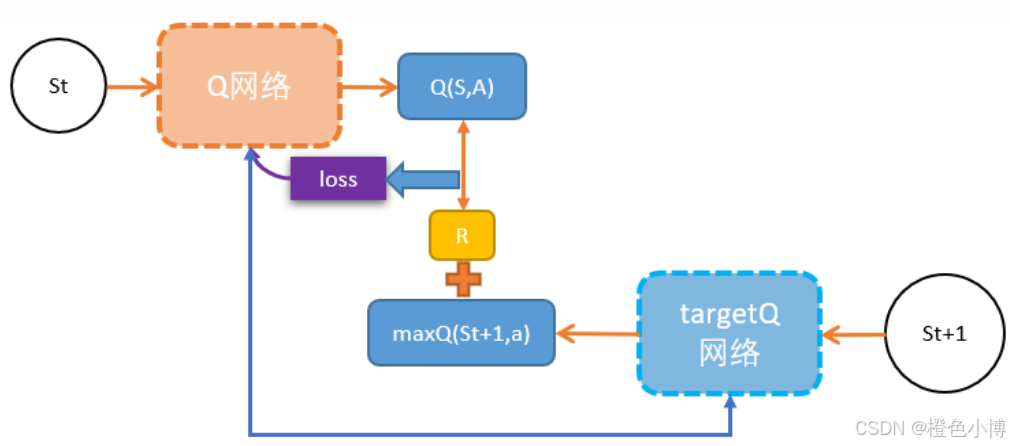
標準DQN使用同一個網絡同時選擇動作和評估動作價值,這容易導致Q值的過估計。Double DQN通過將動作選擇和價值評估分離到兩個不同的網絡來解決這個問題:
-
一個網絡(在線網絡)用于選擇當前狀態下的最佳動作
-
另一個網絡(目標網絡)用于評估這個動作的價值
這種分離減少了自舉過程中動作選擇和價值評估的關聯性,從而有效降低了Q值的過估計。
結構如下:
3. Double DQN 實例:倒立擺
接下來,我們將實現一個完整的Double DQN,解決CartPole平衡問題。這個例子包含了所有關鍵組件:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import gym
import random
from collections import deque# 1. 定義DQN網絡結構
class DQN(nn.Module):def __init__(self, state_dim, action_dim):super(DQN, self).__init__()self.fc1 = nn.Linear(state_dim, 128)self.fc2 = nn.Linear(128, 128)self.fc3 = nn.Linear(128, action_dim)def forward(self, x):x = torch.relu(self.fc1(x))x = torch.relu(self.fc2(x))x = self.fc3(x)return x# 2. 經驗回放緩沖區
class ReplayBuffer:def __init__(self, capacity):self.buffer = deque(maxlen=capacity)def add(self, state, action, reward, next_state, done):self.buffer.append((state, action, reward, next_state, done))def sample(self, batch_size):samples = random.sample(self.buffer, batch_size)states, actions, rewards, next_states, dones = zip(*samples)return states, actions, rewards, next_states, donesdef __len__(self):return len(self.buffer)# 3. Double DQN代理
class DoubleDQNAgent:def __init__(self, state_dim, action_dim):self.policy_net = DQN(state_dim, action_dim)self.target_net = DQN(state_dim, action_dim)self.target_net.load_state_dict(self.policy_net.state_dict())self.target_net.eval()self.optimizer = optim.Adam(self.policy_net.parameters(), lr=0.001)self.replay_buffer = ReplayBuffer(10000)self.batch_size = 64self.gamma = 0.99 # 折扣因子self.epsilon = 1.0 # 探索率self.epsilon_decay = 0.995self.min_epsilon = 0.01self.action_dim = action_dim# 根據ε-greedy策略選擇動作def select_action(self, state):if random.random() < self.epsilon:return random.randint(0, self.action_dim - 1)else:with torch.no_grad():return self.policy_net(torch.FloatTensor(state)).argmax().item()# 存儲經驗def store_transition(self, state, action, reward, next_state, done):self.replay_buffer.add(state, action, reward, next_state, done)# 更新網絡def update(self):if len(self.replay_buffer) < self.batch_size:return# 從經驗回放中采樣states, actions, rewards, next_states, dones = self.replay_buffer.sample(self.batch_size)# 轉換為PyTorch張量states = torch.FloatTensor(states)actions = torch.LongTensor(actions)rewards = torch.FloatTensor(rewards)next_states = torch.FloatTensor(next_states)dones = torch.FloatTensor(dones)# 計算當前Q值current_q = self.policy_net(states).gather(1, actions.unsqueeze(1)).squeeze(1)# 計算目標Q值(使用Double DQN方法)# 使用策略網絡選擇動作,目標網絡評估價值with torch.no_grad():# 從策略網絡中選擇最佳動作policy_actions = self.policy_net(next_states).argmax(dim=1)# 從目標網絡中評估這些動作的值next_q = self.target_net(next_states).gather(1, policy_actions.unsqueeze(1)).squeeze(1)target_q = rewards + self.gamma * next_q * (1 - dones)# 計算損失并優化loss = nn.MSELoss()(current_q, target_q)self.optimizer.zero_grad()loss.backward()self.optimizer.step()# 更新目標網絡(軟更新)for target_param, policy_param in zip(self.target_net.parameters(), self.policy_net.parameters()):target_param.data.copy_(0.001 * policy_param.data + 0.999 * target_param.data)# 減少探索率self.epsilon = max(self.min_epsilon, self.epsilon * self.epsilon_decay)# 訓練過程def train_double_dqn():# 創建環境env = gym.make('CartPole-v1')state_dim = env.observation_space.shape[0]action_dim = env.action_space.n# 創建代理agent = DoubleDQNAgent(state_dim, action_dim)# 訓練參數episodes = 500max_steps = 500# 訓練循環for episode in range(episodes):state, _ = env.reset()total_reward = 0for step in range(max_steps):action = agent.select_action(state)next_state, reward, done, _, _ = env.step(action)# 修改獎勵以加速學習reward = reward if not done else -10agent.store_transition(state, action, reward, next_state, done)agent.update()total_reward += rewardstate = next_stateif done:break# 每10個episodes更新一次目標網絡if episode % 10 == 0:agent.target_net.load_state_dict(agent.policy_net.state_dict())print(f"Episode: {episode + 1}, Total Reward: {total_reward}, Epsilon: {agent.epsilon:.2f}")env.close()# 執行訓練
if __name__ == "__main__":train_double_dqn()
4. Double DQN的關鍵改進點
-
雙網絡結構:通過將動作選擇(策略網絡)和價值評估(目標網絡)分離,減少了Q值的過估計。
-
經驗回放:通過存儲和隨機采樣歷史經驗,打破了數據的相關性,提高了學習穩定性。
-
ε-greedy策略:平衡探索與利用,隨著訓練進行逐漸減少探索概率。
目標網絡在Double DQN中扮演著非常重要的角色:
-
它為策略網絡提供穩定的目標Q值
-
通過延遲更新,減少了目標Q值的波動
-
與策略網絡共同工作,實現了動作選擇和價值評估的分離
5. 雙重網絡更新策略
在Double DQN中,我們使用了軟更新(soft update)策略來更新目標網絡:
for target_param, policy_param in zip(self.target_net.parameters(), self.policy_net.parameters()):target_param.data.copy_(0.001 * policy_param.data + 0.999 * target_param.data)這種軟更新方式比傳統的目標網絡定期硬更新(hard update)更平滑,有助于訓練過程的穩定。
6. 總結
本文通過詳細講解Double DQN的原理,并提供了完整的python實現代碼,展示了如何應用這一先進強化學習算法解決實際問題。與標準DQN相比,Double DQN通過引入雙網絡結構,有效解決了Q值過估計問題,提高了策略學習的穩定性和最終性能。Double DQN是強化學習領域的一個重要進步,為后續更高級的算法(如Dueling DQN、C51、Rainbow DQN等)奠定了基礎。通過理解Double DQN的原理和實現,讀者可以為進一步探索復雜強化學習算法打下堅實基礎。在實際應用中,可以根據具體任務調整網絡結構、超參數(如學習率、折扣因子、經驗回放緩沖區大小等)以及探索策略,以獲得最佳性能。

)







)


)






