多場景游戲AI新突破!Divide-Fuse-Conquer如何激發大模型"頓悟時刻"?
大語言模型在強化學習中偶現的"頓悟時刻"引人關注,但多場景游戲中訓練不穩定、泛化能力差等問題亟待解決。Divide-Fuse-Conquer方法,通過分組訓練、參數融合等策略,在18款TextArena游戲中實現與Claude3.5相當的性能,為多場景強化學習提供新思路。
論文標題
Divide-Fuse-Conquer: Eliciting “Aha Moments” in Multi-Scenario Games
來源
arXiv:2505.16401v1 [cs.LG] + https://arxiv.org/abs/2505.16401
文章核心
研究背景
近年來,大語言模型(LLMs)在強化學習(RL)中展現出令人矚目的推理能力,在數學、編程、視覺等領域通過簡單的基于結果的獎勵,就能觸發類似人類“頓悟時刻”的能力突破。
盡管RL在單場景任務中成效顯著,但在多場景游戲領域卻面臨嚴峻挑戰。游戲場景中,規則、交互模式和環境復雜度的多樣性,導致策略常出現“此長彼消”的泛化困境——在某一場景表現優異,卻難以遷移至其他場景。而簡單合并多場景進行訓練,還會引發訓練不穩定、性能不佳等問題,這使得多場景游戲成為檢驗RL與LLMs結合成效的關鍵領域,也亟需新的方法來突破現有瓶頸。
研究問題
1. 訓練不穩定性:多場景游戲中任務分布異質性強,直接應用強化學習易導致訓練崩潰,如DeepSeek-R1在場景增多時性能顯著下降。
2. 泛化能力不足:簡單合并多場景訓練時,模型在某一場景表現良好,卻難以遷移到其他場景,出現"顧此失彼"的情況。
3. 效率與性能矛盾:統一訓練所有場景時,模型可能優先學習簡單任務,忽視復雜任務,導致整體優化效率低下且最終性能不佳。
主要貢獻
1. 提出Divide-Fuse-Conquer框架:通過啟發式分組、參數融合和漸進式訓練,系統性解決多場景強化學習中的訓練不穩定和泛化問題,這與傳統單一訓練或簡單合并訓練的方式有本質區別。
2. 創新技術組合提升訓練質量:集成格式獎勵塑造、半負采樣、混合優先級采樣等技術,從穩定性、效率和性能三方面優化訓練過程,如半負采樣通過過濾一半負樣本防止梯度主導,就像在嘈雜環境中過濾掉部分干擾信號。
3. 多場景游戲驗證與性能突破:在18款TextArena游戲中,使用Qwen2.5-32B-Align模型訓練后,與Claude3.5對戰取得7勝4平7負的成績,證明該框架能有效激發大模型在多場景游戲中的"頓悟時刻"。
方法論精要
框架設計:Divide-Fuse-Conquer的三級遞進策略
分組(Divide):根據游戲規則(如固定/隨機初始狀態)和難度(基礎模型勝率是否為零),將18款TextArena游戲劃分為4個組。例如,ConnectFour-v0等固定初始狀態且基礎模型可獲勝的游戲歸為一組,而LiarsDice-v0等隨機初始狀態且初始勝率為零的游戲歸為另一組,如同將復雜任務按類型和難度分類拆解。
融合(Fuse):采用參數平均策略融合各組最優策略。具體而言,第 k k k組策略參數 θ ( π k ) \theta^{(\pi_k)} θ(πk?)與前 k ? 1 k-1 k?1組合并后的參數 θ ( π ( k ? 1 ) ) ) \theta^{(\pi{(k-1)})}) θ(π(k?1)))按 θ ( π ( k ) ) = 1 2 ( θ π ( k ? 1 ) + θ π k ) \theta^{(\pi{(k)})} = \frac{1}{2}(\theta^{\pi{(k-1)}} + \theta^{\pi_k}) θ(π(k))=21?(θπ(k?1)+θπk?)融合,使新模型繼承跨組知識,類似將不同領域的專家經驗整合為“全能選手”。
征服(Conquer):通過GRPO算法對融合模型持續訓練,結合多維度優化技術,逐步提升跨場景泛化能力。


核心技術:多維度訓練優化組合
獎勵機制重構:
格式獎勵 ( R format ) (R_{\text{format}}) (Rformat?):對無效動作(如格式錯誤)施加-2懲罰,確保模型輸出合規,如同考試中規范答題格式。
環境獎勵 ( R env ) (R_{\text{env}}) (Renv?):按游戲結果賦予1(勝)、0(平)、-1(負),直接反饋游戲勝負。
倉促動作懲罰 ( R step ) (R_{\text{step}}) (Rstep?):在獲勝場景中,根據軌跡步數 n T n_T nT?縮放獎勵(如TowerOfHanoi中高效解法獲更高分),引導模型避免短視決策。

樣本與探索優化:
半負采樣(Half-Negative Sampling):隨機丟棄50%負樣本,防止負梯度主導訓練,類似在嘈雜數據中過濾干擾。
混合優先級采樣(MPS):動態分配采樣權重,優先訓練中低勝率游戲,如學生重點攻克薄弱科目。
? \epsilon ?-greedy擾動與隨機種子:以概率 ? \epsilon ?隨機選擇動作,并隨機初始化環境種子,增強探索多樣性,避免陷入局部最優。
實驗驗證:多場景與基線對比設計
數據集:TextArena平臺18款游戲,包括4款單玩家(如TowerOfHanoi-v0)和14款雙玩家(如Poker-v0、ConnectFour-v0),覆蓋規則簡單到復雜的場景。
基線方法:
- Naive-MSRL:直接多場景RL訓練;
- Naive-SSRL:單場景RL訓練;
- Claude3.5:先進大模型基線。
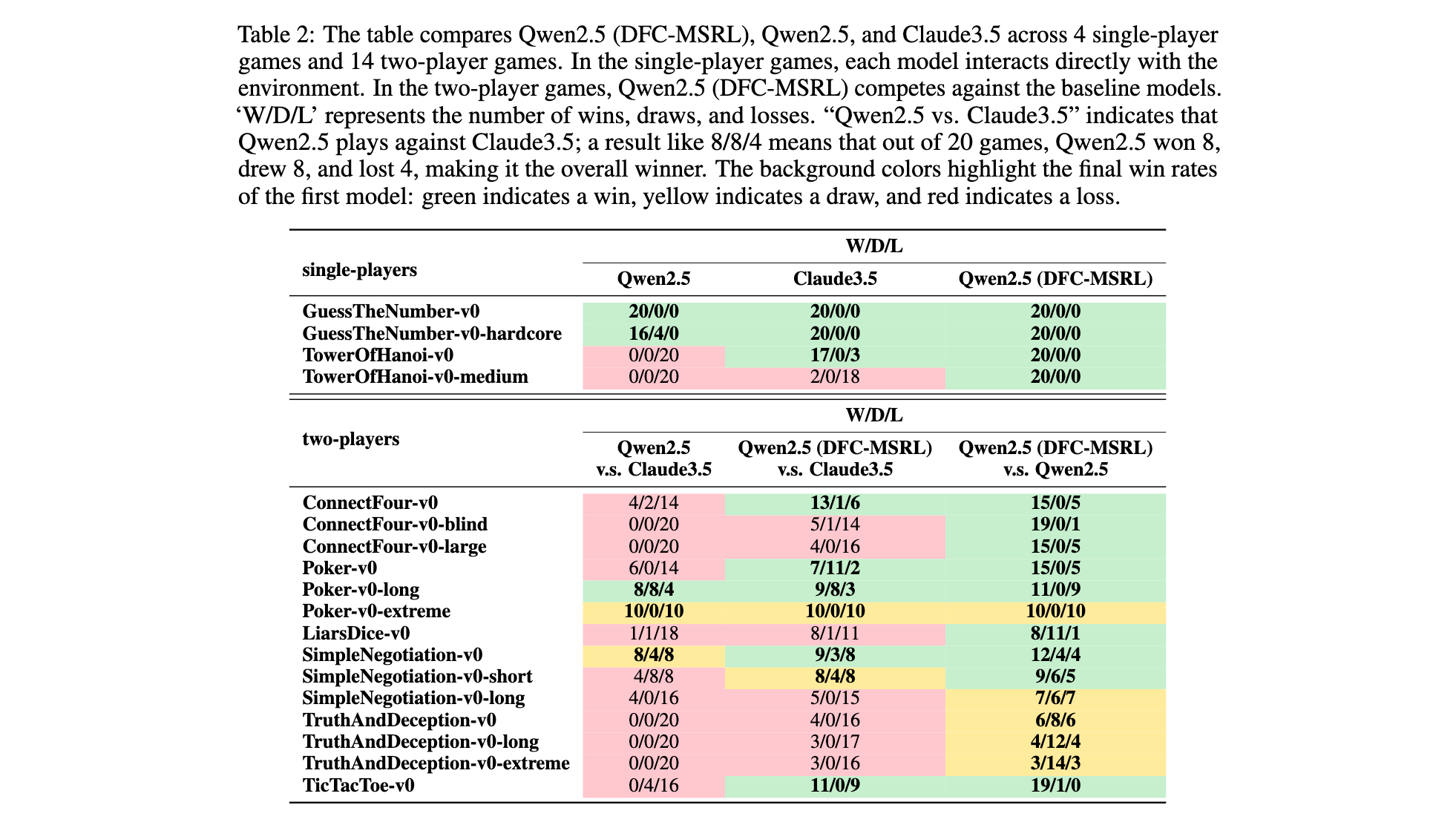
實施細節:使用64張A100 GPU,batch size=1,學習率2e-6,訓練100輪,每輪通過自玩收集軌跡數據,結合GRPO算法更新策略,最終以勝率(W/D/L)評估跨場景性能。
實驗洞察
跨場景性能突破:Qwen2.5與Claude3.5的對戰表現
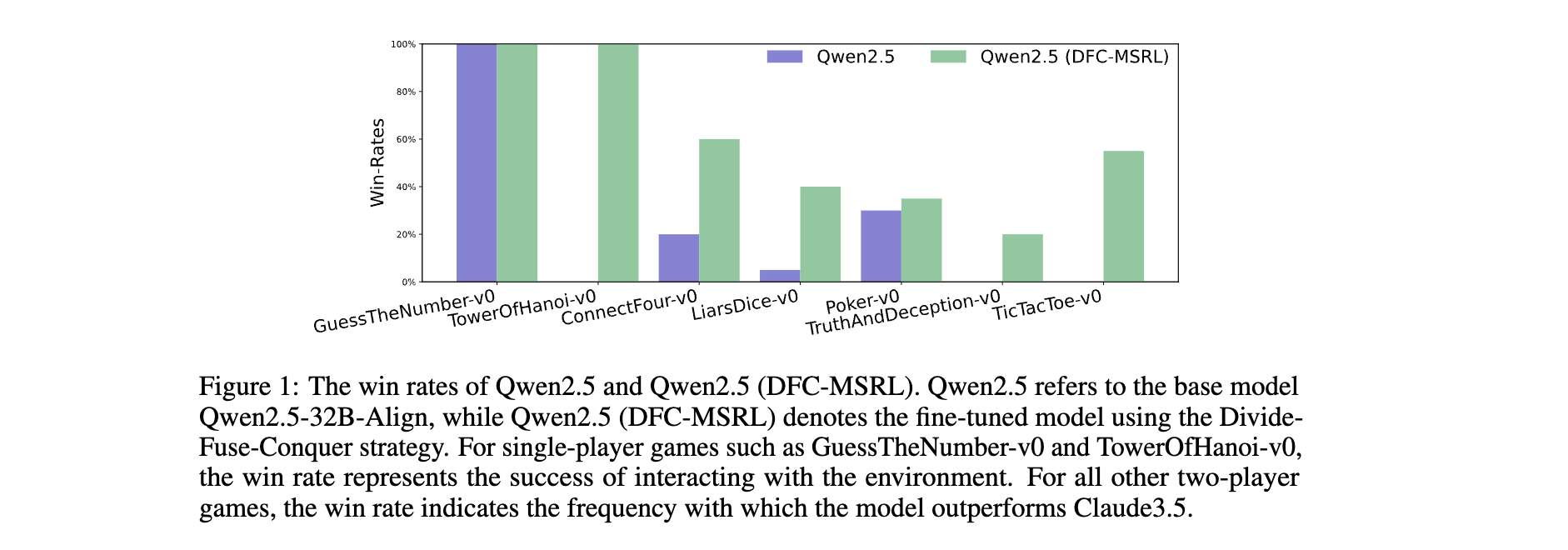
在18款TextArena游戲中,采用Divide-Fuse-Conquer(DFC-MSRL)訓練的Qwen2.5-32B-Align模型展現出顯著提升:
- 單玩家游戲全勝突破:在TowerOfHanoi-v0-medium等場景中,模型從基礎版本的0勝率提升至100%勝率,如3層漢諾塔問題中,通過策略優化實現7步內完成移動(傳統解法最優步數)。
- 雙玩家游戲競爭力:與Claude3.5對戰時,取得7勝4平7負的戰績。其中在ConnectFour-v0中以13勝1平6負顯著超越基礎模型(4勝2平14負);在Poker-v0中以7勝11平2負實現平局率提升,證明在策略博弈中具備動態決策能力。
效率驗證:訓練收斂速度與資源優化
- 對比單/多場景訓練:DFC-MSRL在ConnectFour-v0中僅用10輪迭代就達到65%勝率,而Naive-MSRL需30輪才收斂至40%,訓練效率提升約3倍。這得益于分組訓練減少了跨場景干擾,類似分階段攻克知識點的學習模式。
- 采樣策略的效率優勢:混合優先級采樣(MPS)使TowerOfHanoi-v0-medium的有效訓練樣本增加40%,模型在20輪內即穩定至100%勝率,而均勻采樣基線需40輪,驗證了“優先攻克薄弱場景”策略的高效性。
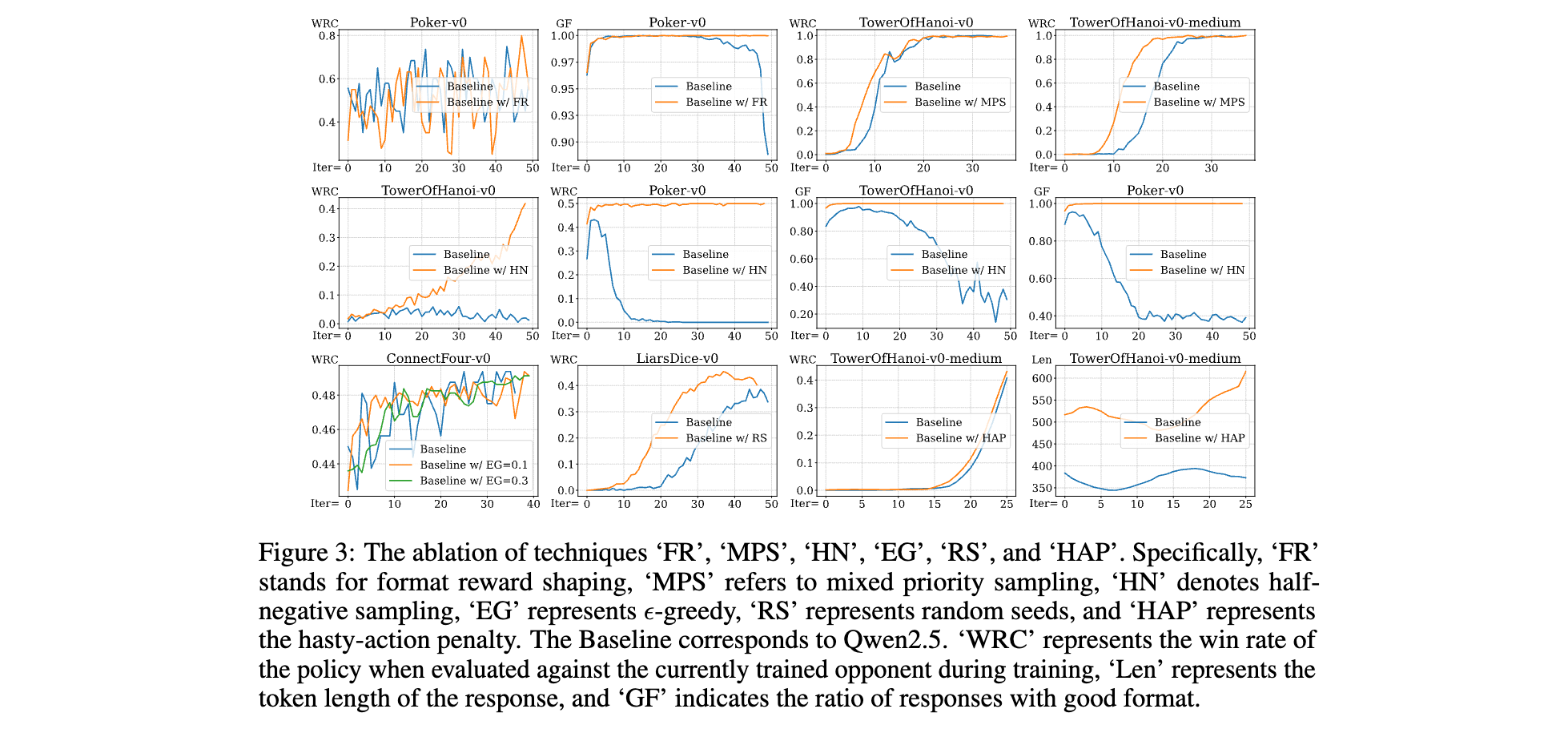
消融研究:核心技術的有效性拆解
穩定性優化技術
- 格式獎勵塑造(FR):在Poker-v0中,FR使模型輸出有效動作比例(GF)始終維持1.0,而無FR的基線模型在10輪后GF驟降至0.6,出現大量格式錯誤(如未按“[Action]”格式輸出),證明格式約束是訓練基石。
- 半負采樣(HN):在TowerOfHanoi-v0中,HN將訓練初期的勝率波動從±30%降至±5%,避免負樣本主導導致的策略崩潰,如同在學習中過濾掉過多錯誤示例的干擾。
探索與采樣技術
- ε-greedy擾動(EG):在ConnectFour-v0中,EG=0.3時模型從持續輸給Claude3.5(0勝20負)轉變為可獲勝(5勝1平14負),證明隨機探索能幫助模型發現“四子連線”的關鍵策略,而純貪心策略易陷入固定思維。
- 隨機種子初始化(RS):在LiarsDice-v0中,RS使模型面對不同初始骰子分布時勝率提升25%,從基線的40%升至65%,驗證了多樣化初始狀態對策略泛化的重要性。
獎勵機制優化
- 倉促動作懲罰(HAP):在TowerOfHanoi-v0-medium中,HAP使模型平均決策步數從12步降至8步(接近最優解),軌跡長度減少33%,表明懲罰機制有效抑制了“盲目試錯”行為,引導模型追求高效策略。
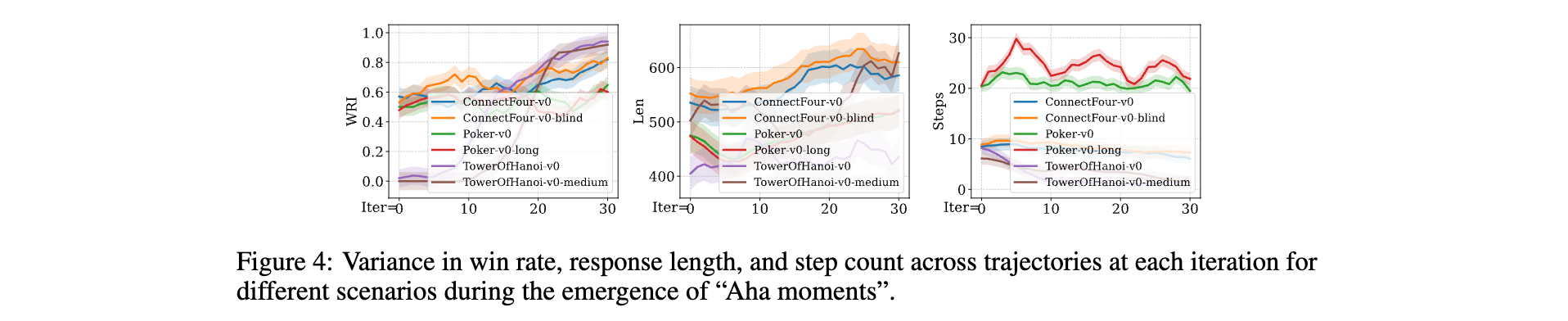
Aha Moment
在TextArena游戲中應用GRPO訓練時,模型偶現“Aha moments”。表現為勝率顯著提升,如ConnectFour-v0從4勝到13勝;響應更深入,token長度增30%;結合懲罰后執行步數減25%,如TowerOfHanoi-v0-medium達最優解,體現從試錯到策略推理的突破。









)

)



坐標系!)




)