前言
? ? ? ? 上章深入分析了幀循環中呈現階段的具體實現。本章將分析多線程下的記錄與提交,進一步剖析vsg幀循環過程中的同步機制,并揭露信號量(VkSemaphore)和圍欄(VkFence)以及vsg::FrameBlock與vsg::Barrier在其中的作用。
目錄
- 1 信號量(VkSemaphore)、柵欄(VkFence)、vsg::FrameBlock與vsg::Barrier
- 2?多線程記錄與提交
1 信號量(VkSemaphore)、圍欄(VkFence)與vsg::FrameBlock、vsg::Barrier
? ? ? ? vsg::Semaphore封裝了VkSaphore,用于將vulkan命令的完成與其他vulkan命令提交的開始同步,為GPU內部的同步;vsg::Fence封裝了vkFence,用于同步Vulkan命令提交到隊列的完成情況,用于應用程序(CPU端)與Vulkan命令提交到隊列的完成情況(GPU端)的同步;vsg::FrameBlock提供了一種機制,用于同步等待新幀開始的線程;vsg::Barrier提供了一種同步多個線程的方法,一旦指定數量的線程加入Barrier,這些線程就會一起釋放。
1.1 vsg::Semaphore
Semaphore::Semaphore(Device* device, VkPipelineStageFlags pipelineStageFlags, void* pNextCreateInfo) :_pipelineStageFlags(pipelineStageFlags),_device(device)
{VkSemaphoreCreateInfo semaphoreInfo = {};semaphoreInfo.sType = VK_STRUCTURE_TYPE_SEMAPHORE_CREATE_INFO;semaphoreInfo.pNext = pNextCreateInfo;VkResult result = vkCreateSemaphore(*device, &semaphoreInfo, _device->getAllocationCallbacks(), &_semaphore);if (result != VK_SUCCESS){throw Exception{"Error: Failed to create semaphore.", result};}
}? ? ? ? vsg::Semaphore構造函數使用vkCreateSemaphore創建信號量VkSemaphore,信號量的創建與某一邏輯設備綁定,即信號量可用于GPU內部同一隊列或同一邏輯設備的不同隊列間的同步。
Semaphore::~Semaphore()
{if (_semaphore){vkDestroySemaphore(*_device, _semaphore, _device->getAllocationCallbacks());}
}? ? ? ? vsg::Semaphore析構函數使用vkDestroySemaphore釋放信號量VkSemaphore。
1.2 vsg::Fence
Fence::Fence(Device* device, VkFenceCreateFlags flags) :_device(device)
{VkFenceCreateInfo createFenceInfo = {};createFenceInfo.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO;createFenceInfo.flags = flags;createFenceInfo.pNext = nullptr;if (VkResult result = vkCreateFence(*device, &createFenceInfo, _device->getAllocationCallbacks(), &_vkFence); result != VK_SUCCESS){throw Exception{"Error: Failed to create Fence.", result};}
}? ? ? ? vsg::Fence構造函數使用vkCreateFence創建VkFence,圍欄的創建與某一邏輯設備綁定。
Fence::~Fence()
{if (_vkFence){vkDestroyFence(*_device, _vkFence, _device->getAllocationCallbacks());}
}? ? ? ? vsg::Fence析構函數使用vkDestroyFence釋放圍欄。
VkResult Fence::wait(uint64_t timeout) const
{return vkWaitForFences(*_device, 1, &_vkFence, VK_TRUE, timeout);
}? ? ? ? vsg::Fence在應用層(CPU端)的使用通過調用wait函數,其通過封裝vkWaitForFences實現。
VkResult Fence::reset() const
{return vkResetFences(*_device, 1, &_vkFence);
}? ? ?vsg::Fence在GPU端使用時,需重置為無信號狀態,否則可能會導致應用層調用vkWaitForFences卡死。
1.3 vsg::FrameBlock
? ? ? ? vsg::FrameBlock提供了一種機制,用于同步等待新幀開始的線程。
std::mutex _mutex;std::condition_variable _cv;ref_ptr<FrameStamp> _value;ref_ptr<ActivityStatus> _status;? ? ? ? 上述代碼為vsg::FrameBlock的成員變量,其通過對std::mutex和std::condition_variable的封裝實現了一種針對vsg::FrameStamp是否變化的阻塞能力,即同步所有等待新幀開始的線程,而變量_status(vsg::ActivityStatus類型)用于標記vsg::FrameBlock的阻塞能力是否有效。
bool wait_for_change(ref_ptr<FrameStamp>& value){std::unique_lock lock(_mutex);while (_value == value && _status->active()){_cv.wait(lock);}value = _value;return _status->active();}? ? ? ? 通過調用wait_for_change接口,當傳入的vsg::FrameStamp對象與已有的一致時,阻塞應用程序所在線程。
void set(ref_ptr<FrameStamp> frameStamp){std::scoped_lock lock(_mutex);_value = frameStamp;_cv.notify_all();}? ? ? ? 當設置vsg::FrameStamp對象后,則通知所有阻塞線程解除阻塞。
1.4?vsg::Barrier
? ? ? ? vsg::Barrier提供了一種同步多個線程的方法,一旦指定數量的線程加入Barrier,這些線程就會一起釋放。
const uint32_t _num_threads;uint32_t _num_arrived;uint32_t _phase;std::mutex _mutex;std::condition_variable _cv;? ? ? ? vsg::Barrier同樣是封裝std::mutex和std::condition_variable實現,輔以_num_theads(同步的線程數)和_num_arrived(到達的線程數)實現多線程同步。
void arrive_and_wait(){std::unique_lock lock(_mutex);if (++_num_arrived == _num_threads){_release();}else{auto my_phase = _phase;_cv.wait(lock, [this, my_phase]() { return this->_phase != my_phase; });}}
? ? ? ? 如上代碼為arrive_and_wait函數實現,當到達的線程數與總線程數一致時,則釋放所有線程,否則阻塞且記錄當前階段my_phase。
void _release(){_num_arrived = 0;++_phase;_cv.notify_all();}
? ? ? ? 釋放所有線程的代碼如上所示,同時更新當前的階段(++_phase),將當前到達的線程數_num_arrived置為0。
? ? ? ? void arrive_and_drop(){std::unique_lock lock(_mutex);if (++_num_arrived == _num_threads){_release();}}? ? ? ? arrive_and_drop會更新當前到達的線程數,同時判斷,當到達線程數等于所有線程數時,則釋放所有線程,但不阻塞當前線程。
2?多線程記錄與提交
#if 1if (_threading)
#else// The following is a workaround for an odd "Possible data race during write of size 1" warning that valgrind tool=helgrind reports// on the first call to vkBeginCommandBuffer despite them being done on independent command buffers. This could well be a driver bug or a false positive.// If you want to quieten this warning then change the #if above to #if 0 as rendering the first three frames single threaded avoids the warning.if (_threading && _frameStamp->frameCount > 2)
#endif{_frameBlock->set(_frameStamp);_submissionCompleted->arrive_and_wait();}else{for (auto& recordAndSubmitTask : recordAndSubmitTasks){recordAndSubmitTask->submit(_frameStamp);}}? ? ? ? 上述代碼為Viewer.cpp中的821-838行,當標記_threading為true時,執行多線程提交。首先更新當前幀(上述代碼第9行),接著等待提交的完成(上述代碼第10行)。其中_frameBlock和_submissionComplete分別為vsg::FrameBlock和vsg::Barrier對象,其初始化在vsg::Viewer::setupThreading函數中完成。vsg::Viewer::setupThreading的執行可分為多線程同步變量初始化、創建多線程兩部分。
uint32_t numValidTasks = 0;for (const auto& task : recordAndSubmitTasks){if (!task->commandGraphs.empty()){++numValidTasks;}}// check if there is any point in setting up threadingif (numValidTasks == 0){return;}status->set(true);_threading = true;_frameBlock = FrameBlock::create(status);_submissionCompleted = Barrier::create(1 + numValidTasks);? ? ? ? 上述代碼首先統計有效的提交任務數,接著創建vsg::FrameBlock和vsg::Barrier對象,其中vsg::Barrier對象_submissionCompleted傳入的線程數為有效任務數+1,其中'+1'代表主線程,即主線程調用其arrive_and_wait方法并阻塞,當所有提交線程完成時,則釋放主線程。
? ? ? ? 創建多線程部分以vsg::RecordAndSubmitTask為粒度創建,vsg::RecordAndSubmitTask與vsg::CommandGraph和vsg::TransferTask關系如下:
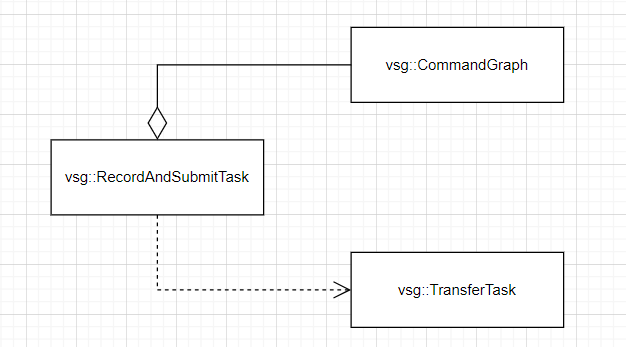
? ? ? ? 線程的創建分兩種情況,當vsg::RecordAndSubmitTask對象中包含的CommandGraph數組數量為1且vsg::TransferTask對象為空時,則僅創建一個任務提交線程,否則需同時創建數據傳輸線程。
if (task->commandGraphs.size() == 1 && !task->transferTask){// task only contains a single CommandGraph so keep thread simpleauto run = [](ref_ptr<RecordAndSubmitTask> viewer_task, ref_ptr<FrameBlock> viewer_frameBlock, ref_ptr<Barrier> submissionCompleted, const std::string& threadName) {auto local_instrumentation = shareOrDuplicateForThreadSafety(viewer_task->instrumentation);if (local_instrumentation) local_instrumentation->setThreadName(threadName);auto frameStamp = viewer_frameBlock->initial_value;// wait for this frame to be signaledwhile (viewer_frameBlock->wait_for_change(frameStamp)){CPU_INSTRUMENTATION_L1_NC(local_instrumentation, "Viewer run", COLOR_RECORD);viewer_task->submit(frameStamp);submissionCompleted->arrive_and_drop();}};threads.emplace_back(run, task, _frameBlock, _submissionCompleted, make_string("Viewer run thread"));}
? ? ? ?上述代碼為,當vsg::RecordAndSubmitTask對象中包含的CommandGraph數組數量為1且vsg::TransferTask對象為空時,僅創建一個提交線程,線程中主要調用vsg::RecordAndSubmitTask的submit方法執行提交任務。其中線程為std::thread。
else if (!task->commandGraphs.empty())
{// we have multiple CommandGraphs in a single Task so set up a thread per CommandGraphstruct SharedData : public Inherit<Object, SharedData>{SharedData(ref_ptr<RecordAndSubmitTask> in_task, ref_ptr<FrameBlock> in_frameBlock, ref_ptr<Barrier> in_submissionCompleted, uint32_t numThreads) :task(in_task),frameBlock(in_frameBlock),submissionCompletedBarrier(in_submissionCompleted){recordedCommandBuffers = RecordedCommandBuffers::create();recordStartBarrier = Barrier::create(numThreads);recordCompletedBarrier = Barrier::create(numThreads);}// shared between all threadsref_ptr<RecordAndSubmitTask> task;ref_ptr<FrameBlock> frameBlock;ref_ptr<Barrier> submissionCompletedBarrier;// shared between threads associated with each taskref_ptr<RecordedCommandBuffers> recordedCommandBuffers;ref_ptr<Barrier> recordStartBarrier;ref_ptr<Barrier> recordCompletedBarrier;};uint32_t numThreads = static_cast<uint32_t>(task->commandGraphs.size());if (task->transferTask) ++numThreads;ref_ptr<SharedData> sharedData = SharedData::create(task, _frameBlock, _submissionCompleted, numThreads);auto run_primary = [](ref_ptr<SharedData> data, ref_ptr<CommandGraph> commandGraph, const std::string& threadName) {auto local_instrumentation = shareOrDuplicateForThreadSafety(data->task->instrumentation);if (local_instrumentation) local_instrumentation->setThreadName(threadName);auto frameStamp = data->frameBlock->initial_value;// wait for this frame to be signaledwhile (data->frameBlock->wait_for_change(frameStamp)){CPU_INSTRUMENTATION_L1_NC(local_instrumentation, "Viewer primary", COLOR_RECORD);// primary thread starts the taskdata->task->start();data->recordStartBarrier->arrive_and_wait();//vsg::info("run_primary");commandGraph->record(data->recordedCommandBuffers, frameStamp, data->task->databasePager);data->recordCompletedBarrier->arrive_and_wait();// primary thread finishes the task, submitting all the command buffers recorded by the primary and all secondary threads to its queuedata->task->finish(data->recordedCommandBuffers);data->recordedCommandBuffers->clear();data->submissionCompletedBarrier->arrive_and_wait();}};auto run_secondary = [](ref_ptr<SharedData> data, ref_ptr<CommandGraph> commandGraph, const std::string& threadName) {auto local_instrumentation = shareOrDuplicateForThreadSafety(data->task->instrumentation);if (local_instrumentation) local_instrumentation->setThreadName(threadName);auto frameStamp = data->frameBlock->initial_value;// wait for this frame to be signaledwhile (data->frameBlock->wait_for_change(frameStamp)){CPU_INSTRUMENTATION_L1_NC(local_instrumentation, "Viewer secondary", COLOR_RECORD);data->recordStartBarrier->arrive_and_wait();commandGraph->record(data->recordedCommandBuffers, frameStamp, data->task->databasePager);data->recordCompletedBarrier->arrive_and_wait();}};auto run_transfer = [](ref_ptr<SharedData> data, ref_ptr<TransferTask> transferTask, TransferTask::TransferMask transferMask, const std::string& threadName) {auto local_instrumentation = shareOrDuplicateForThreadSafety(data->task->instrumentation);if (local_instrumentation) local_instrumentation->setThreadName(threadName);auto frameStamp = data->frameBlock->initial_value;// wait for this frame to be signaledwhile (data->frameBlock->wait_for_change(frameStamp)){CPU_INSTRUMENTATION_L1_NC(local_instrumentation, "Viewer transfer", COLOR_RECORD);data->recordStartBarrier->arrive_and_wait();//vsg::info("run_transfer");if (auto transfer = transferTask->transferData(transferMask); transfer.result == VK_SUCCESS){if (transfer.dataTransferredSemaphore){data->task->earlyDataTransferredSemaphore = transfer.dataTransferredSemaphore;}}data->recordCompletedBarrier->arrive_and_wait();}};for (uint32_t i = 0; i < task->commandGraphs.size(); ++i){if (i == 0)threads.emplace_back(run_primary, sharedData, task->commandGraphs[i], make_string("Viewer primary thread"));elsethreads.emplace_back(run_secondary, sharedData, task->commandGraphs[i], make_string("Viewer seconary thread ", i));}if (task->transferTask){threads.emplace_back(run_transfer, sharedData, task->transferTask, TransferTask::TRANSFER_BEFORE_RECORD_TRAVERSAL, make_string("Viewer early transferTask thread"));}
}? ? ? ?其它情況創建的線程,需針對vsg::TransferTask對象創建傳輸線程,當存在多個CommandGraph時,創建的提交線程的方式需區分。線程使用std::thread,通過lambda表達式封裝線程的執行函數。
SharedData(ref_ptr<RecordAndSubmitTask> in_task, ref_ptr<FrameBlock> in_frameBlock, ref_ptr<Barrier> in_submissionCompleted, uint32_t numThreads) :task(in_task),frameBlock(in_frameBlock),submissionCompletedBarrier(in_submissionCompleted){recordedCommandBuffers = RecordedCommandBuffers::create();recordStartBarrier = Barrier::create(numThreads);recordCompletedBarrier = Barrier::create(numThreads);}? ? ? ?上述代碼為SharedData的構造函數,提交線程和數據傳輸線程的同步通過上述recordStartBarrier和recordCompletedBarrier兩個vsg::Barrier對象實現。
auto run_primary = [](ref_ptr<SharedData> data, ref_ptr<CommandGraph> commandGraph, const std::string& threadName) {auto local_instrumentation = shareOrDuplicateForThreadSafety(data->task->instrumentation);if (local_instrumentation) local_instrumentation->setThreadName(threadName);auto frameStamp = data->frameBlock->initial_value;// wait for this frame to be signaledwhile (data->frameBlock->wait_for_change(frameStamp)){CPU_INSTRUMENTATION_L1_NC(local_instrumentation, "Viewer primary", COLOR_RECORD);// primary thread starts the taskdata->task->start();data->recordStartBarrier->arrive_and_wait();//vsg::info("run_primary");commandGraph->record(data->recordedCommandBuffers, frameStamp, data->task->databasePager);data->recordCompletedBarrier->arrive_and_wait();// primary thread finishes the task, submitting all the command buffers recorded by the primary and all secondary threads to its queuedata->task->finish(data->recordedCommandBuffers);data->recordedCommandBuffers->clear();data->submissionCompletedBarrier->arrive_and_wait();}};auto run_secondary = [](ref_ptr<SharedData> data, ref_ptr<CommandGraph> commandGraph, const std::string& threadName) {auto local_instrumentation = shareOrDuplicateForThreadSafety(data->task->instrumentation);if (local_instrumentation) local_instrumentation->setThreadName(threadName);auto frameStamp = data->frameBlock->initial_value;// wait for this frame to be signaledwhile (data->frameBlock->wait_for_change(frameStamp)){CPU_INSTRUMENTATION_L1_NC(local_instrumentation, "Viewer secondary", COLOR_RECORD);data->recordStartBarrier->arrive_and_wait();commandGraph->record(data->recordedCommandBuffers, frameStamp, data->task->databasePager);data->recordCompletedBarrier->arrive_and_wait();}};auto run_transfer = [](ref_ptr<SharedData> data, ref_ptr<TransferTask> transferTask, TransferTask::TransferMask transferMask, const std::string& threadName) {auto local_instrumentation = shareOrDuplicateForThreadSafety(data->task->instrumentation);if (local_instrumentation) local_instrumentation->setThreadName(threadName);auto frameStamp = data->frameBlock->initial_value;// wait for this frame to be signaledwhile (data->frameBlock->wait_for_change(frameStamp)){CPU_INSTRUMENTATION_L1_NC(local_instrumentation, "Viewer transfer", COLOR_RECORD);data->recordStartBarrier->arrive_and_wait();//vsg::info("run_transfer");if (auto transfer = transferTask->transferData(transferMask); transfer.result == VK_SUCCESS){if (transfer.dataTransferredSemaphore){data->task->earlyDataTransferredSemaphore = transfer.dataTransferredSemaphore;}}data->recordCompletedBarrier->arrive_and_wait();}};? ? ? ?如上代碼為三個lambda函數,run_primary、run_secondary、run_transfer,分別對應第一個提交線程、其它提交線程、數據傳輸線程的執行函數。其將主體執行內容放置在recordStartBarrier->arrive_and_wait() 和?recordCompletedBarrier->arrive_and_wait()之間,實現線程間的同步,采用如下的模式實現線程和主線程的同步:
while (data->frameBlock->wait_for_change(frameStamp)){//執行內容data->submissionCompletedBarrier->arrive_and_wait();}? ? ? ?vulkanscenegraph顯示傾斜模型(6.2)-記錄與提交-CSDN博客中將任務提交的具體實現分為開始、recordTraversal前的數據傳輸、record、完成四個部分,而run_primary獨自負責任務的開始、recordTraversal前的數據傳輸、完成三個部分,run_primary與run_secondary共同負責record部分。通過run_primary函數的實現可看出,當前幀所有數據傳輸完成、命令錄制完成,最后調用finish方法提交任務到隊列。
文末:本章深入分析了幀循環中多線程下的記錄與提交,首先深入剖析了vsg中與多線程同步相關的封裝:vsg::Semaphore、vsg::Fence、vsg::FrameBlock、vsg::Barrier,接著進一步分析了記錄與提交過程中的多線程機制。下章將分析vsg::DatabasePager在更新場景圖過程中的作用。
待分析項:vsg::DatabasePager在更新場景圖過程中的作用。





: 環形熱圖繪制)

)

)






)


