HashMap基于哈希表的Map接口實現,是以key-value存儲形式存在,即主要用來存放鍵值對。HashMap的實現不是同步的,這意味著它不是線程安全的。它的key、value都可以為null。此外,HashMap中的映射不是有序的。
???????JDK1.8 之前?HashMap由數組+鏈表組成的,數組是?HashMap的主體,鏈表則是主要為了解決哈希沖突(兩個對象調用的hashCode方法計算的哈希碼值一致導致計算的數組索引值相同)而存在的(“拉鏈法”解決沖突)。
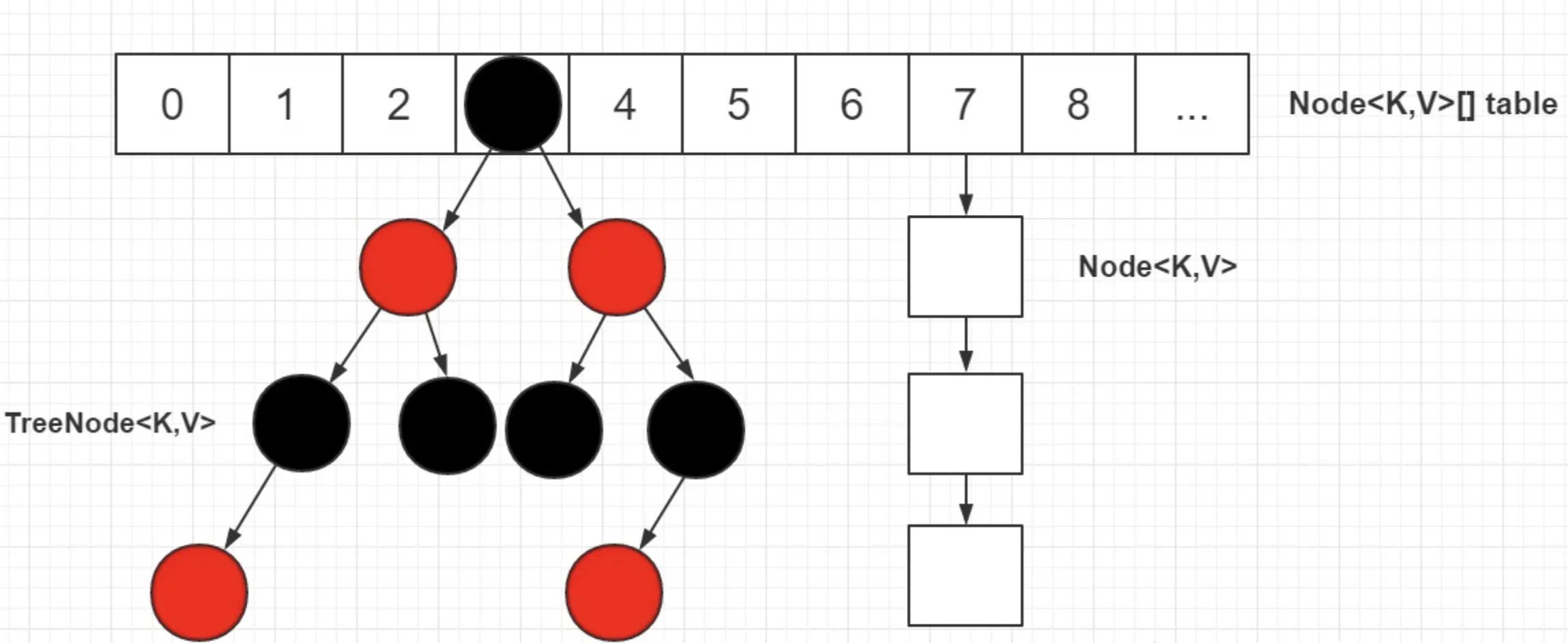
JDK1.8 以后在解決哈希沖突時有了較大的變化,當鏈表長度大于閾值(或者紅黑樹的邊界值,默認為 8)并且當前數組的長度大于64時,此時此索引位置上的所有數據改為使用紅黑樹存儲。當鏈表長度小于等于 6 時,轉為鏈表。
???????這樣做的目的是因為數組比較小,盡量避開紅黑樹結構,這種情況下變為紅黑樹結構,反而會降低效率,因為紅黑樹需要進行左旋,右旋,變色這些操作來保持平衡 。同時數組長度小于64時,搜索時間相對要快些。所以綜上所述為了提高性能和減少搜索時間。
/*** The default initial capacity - MUST be a power of two.*/static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //默認容量大小(必須是二的n次冪)/*** The maximum capacity, used if a higher value is implicitly specified* by either of the constructors with arguments.* MUST be a power of two <= 1<<30.*/static final int MAXIMUM_CAPACITY = 1 << 30; //最大容量(必須是二的n次冪)/*** The load factor used when none specified in constructor.*/static final float DEFAULT_LOAD_FACTOR = 0.75f; //默認負載因子(默認的0.75)/*** The bin count threshold for using a tree rather than list for a* bin. Bins are converted to trees when adding an element to a* bin with at least this many nodes. The value must be greater* than 2 and should be at least 8 to mesh with assumptions in* tree removal about conversion back to plain bins upon* shrinkage.*/static final int TREEIFY_THRESHOLD = 8; //當鏈表的值超過8則會轉紅黑樹(1.8新增)/*** The bin count threshold for untreeifying a (split) bin during a* resize operation. Should be less than TREEIFY_THRESHOLD, and at* most 6 to mesh with shrinkage detection under removal.*/static final int UNTREEIFY_THRESHOLD = 6; //當鏈表的值小于6則會從紅黑樹轉回鏈表/*** The smallest table capacity for which bins may be treeified.* (Otherwise the table is resized if too many nodes in a bin.)* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts* between resizing and treeification thresholds.*///當Map里面的容量(即表長度)超過這個值時,鏈表才能進行樹形化 ,否則元素太多時會擴容,而不是樹形化 //為了避免進行擴容、樹形化選擇的沖突,這個值不能小于 4 * TREEIFY_THRESHOLD(因此樹形化有兩個條件,表長度 > 64 and 鏈表長度 > 8)static final int MIN_TREEIFY_CAPACITY = 64; /* ---------------- Fields -------------- *//*** The table, initialized on first use, and resized as* necessary. When allocated, length is always a power of two.* (We also tolerate length zero in some operations to allow* bootstrapping mechanics that are currently not needed.)*/transient Node<K,V>[] table; // table用來初始化,類似容器來存放元素(必須是二的n次冪)/*** Holds cached entrySet(). Note that AbstractMap fields are used* for keySet() and values().*/transient Set<Map.Entry<K,V>> entrySet; // 用來存放緩存/*** The number of key-value mappings contained in this map.*/transient int size; // Map中存儲的元素數量/*** The number of times this HashMap has been structurally modified* Structural modifications are those that change the number of mappings in* the HashMap or otherwise modify its internal structure (e.g.,* rehash). This field is used to make iterators on Collection-views of* the HashMap fail-fast. (See ConcurrentModificationException).*/transient int modCount; // 用來記錄HashMap的修改次數/*** The next size value at which to resize (capacity * load factor).** @serial*/// (The javadoc description is true upon serialization.// Additionally, if the table array has not been allocated, this// field holds the initial array capacity, or zero signifying// DEFAULT_INITIAL_CAPACITY.)int threshold; // 閾值,用來調整大小下一個容量的值(計算方式為容量*負載因子)/*** The load factor for the hash table.** @serial*/final float loadFactor; // 負載因子,創建HashMap也可調整,比如你希望用更多的空間換取時間,可以把負載因子調的更小一些,減少碰撞。HashMap在樹形化時需要滿足以下兩個條件:
-
表長度(數組長度)必須大于或等于64。
-
鏈表長度必須大于或等于8。
這兩個條件的設定是基于性能優化和內存管理的考慮。
(1)表長度大于或等于64
表長度是指哈希表的數組長度。當表長度較小時(小于64),HashMap會優先選擇擴容而不是樹形化。原因如下:
-
擴容的代價較小:當表長度較小時,擴容操作(即重新分配數組并重新哈希所有鍵值對)的代價相對較小。擴容可以更均勻地分布鍵值對,減少鏈表長度,從而避免樹形化的開銷。
-
避免過早樹形化:如果表長度較小時就進行樹形化,可能會導致內存浪費,因為樹形化需要額外的內存來存儲紅黑樹的節點結構。
(2)鏈表長度大于或等于8
鏈表長度是指某個桶中鏈表的節點數量。當鏈表長度較小時(小于8),樹形化的收益較小,因為鏈表的查找時間復雜度O(n)在這種情況下已經足夠高效。只有當鏈表長度較長時(大于或等于8),樹形化才能顯著提升性能。
擴容機制
觸發條件:
-
容量(capacity):HashMap 內部用來存儲數據的數組大小。初始時,默認的容量為?
16。 -
負載因子(load factor):負載因子是一個表示 HashMap 充滿程度的參數。當 HashMap 中存儲的元素數量達到容量乘以負載因子時,HashMap 會進行擴容操作。默認的負載因子是?
0.75。 -
當向 HashMap 中添加元素時,如果元素的數量(size)超過了負載因子乘以當前容量(即?
size > loadFactor * capacity),HashMap 就會進行擴容操作。 -
擴容操作會將 HashMap 中的數組容量翻倍,并且重新計算每個元素在新數組中的位置。這個過程涉及到重新計算哈希值,并將元素放入新的數組位置。
-
擴容操作比較耗時,因為需要重新計算哈希值,并且可能涉及到大量的數據復制。因此,盡量在使用 HashMap 時給定一個合適的初始容量,以減少擴容次數,提高性能。
?
hash函數
計算方式
對于key的hashCode做hash操作,無符號右移(>>>)16位然后做異或(^)運算。
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}hash碰撞
???????只要兩個元素的key計算的哈希碼值相同就會發生哈希碰撞。jdk8前使用鏈表解決哈希碰撞。jdk8之后使用鏈表+紅黑樹解決哈希碰撞。
???????因為HashMap是由數組加鏈表/紅黑樹組成。平時存儲的元素都是在這個數組中。我們也稱之為“hash桶”,那么計算出兩個相同的hash值,我們就需要使用equals比較內容,如果兩個內容不同。我們就需要在同一個位置存儲。按照常規思路是不可能實現的。于是乎,在每個hash桶的位置存放鏈表或者紅黑樹。以此來存儲我們的數據。當然如果equals相同,那么就覆蓋之前的值即可。
那為什么數組的容量總是2的n次冪
??當向HashMap中添加一個元素的時候,需要根據key的hash值,去確定其在數組中的具體位置。 HashMap為了存取高效,要盡量較少碰撞,就是要盡量把數據分配均勻,每個鏈表長度大致相同,這個實現就在把數據存到哪個鏈表中的算法。
???????這個算法實際就是取模,hash%length,計算機中直接求余效率不如位移運算。所以源碼中做了優化,使用 hash&(length-1),而實際上hash%length等于hash&(length-1)的前提是length是2的n次冪。
???????為什么這樣能均勻分布減少碰撞呢?2的n次方實際就是1后面n個0,2的n次方-1 實際就是n個1;
按位與運算:相同的二進制數位上,都是1的時候,結果為1,否則為零。
如果創建HashMap對象時,輸入的數組長度是10,不是2的冪,HashMap通過位移運算和或運算得到的肯定是2的冪次數,并且是離那個數最近的數字。
?
增加方法
put方法是比較復雜的,實現步驟大致如下:
-
先通過hash值計算出key映射到哪個桶;
-
如果桶上沒有碰撞沖突,則直接插入;
-
如果出現碰撞沖突了,則需要處理沖突:
a:如果該桶使用紅黑樹處理沖突,則調用紅黑樹的方法插入數據;
b:否則采用傳統的鏈式方法插入。如果鏈的長度達到臨界值,則把鏈轉變為紅黑樹;
-
如果桶中存在重復的鍵,則為該鍵替換新值value;
-
如果size大于閾值threshold,則進行擴容;
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}/*** Implements Map.put and related methods.** @param hash hash for key* @param key the key* @param value the value to put* @param onlyIfAbsent if true, don't change existing value* @param evict if false, the table is in creation mode.* @return previous value, or null if none*/final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;}???????HashMap只提供了put用于添加元素,putVal方法只是給put方法調用的一個方法,并沒有提供給用戶使用。 所以我們重點看putVal方法。
???????我們可以看到在putVal()方法中key在這里執行了一下hash()方法,來看一下Hash方法是如何實現的。
static final int hash(Object key) {int h;/*1)如果key等于null:可以看到當key等于null的時候也是有哈希值的,返回的是0.2)如果key不等于null:首先計算出key的hashCode賦值給h,然后與h無符號右移16位后的二進制進行按位異或得到最后的 hash值*/return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}???????從上面可以得知HashMap是支持Key為空的,而HashTable是直接用Key來獲取HashCode所以key為空會拋異常。
???????其實上面就已經解釋了為什么HashMap的長度為什么要是2的冪因為HashMap 使用的方法很巧妙,它通過 hash & (table.length -1)來得到該對象的保存位,前面說過 HashMap 底層數組的長度總是2的n次方,這是HashMap在速度上的優化。
???????當 length 總是2的n次方時,hash & (length-1)運算等價于對 length 取模,也就是hash%length,但是&比%具有更高的效率。比如 n % 32 = n & (32 -1)。
我們先研究下key的哈希值是如何計算出來的。key的哈希值是通過上述方法計算出來的。
???????這個哈希方法首先計算出key的hashCode賦值給h,然后與h無符號右移16位后的二進制進行按位異或得到最后的 hash值。計算過程如下所示:
static final int hash(Object key) {int h;/*1)如果key等于null:可以看到當key等于null的時候也是有哈希值的,返回的是0.2)如果key不等于null:首先計算出key的hashCode賦值給h,然后與h無符號右移16位后的二進制進行按位異或得到最后的 hash值*/return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}在putVal函數中使用到了上述hash函數計算的哈希值:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {。。。。。。。。。。。。。。if ((p = tab[i = (n - 1) & hash]) == null)//這里的n表示數組長度16。。。。。。。。。。。。。。}










)



)



