在Mysql數據存儲或性能瓶頸時,采用冷熱數據分離的方式通常是一種選擇。ClickHouse和Elasticsearch(ES)是兩個常用的組件,但具體使用哪種組件取決于冷數據的存儲目的、查詢模式和業務需求等方面。
1、核心對比
(1)、ClickHouse
- 適用場景:
- OLAP分析:適合需要快速處理大規模數據的聚合查詢(如統計、分析歷史數據)。
- 結構化數據:適合高度結構化的數據(如日志、訂單、交易記錄等)。
- 列式存儲:列式存儲設計使其在聚合查詢(如SUM, COUNT, GROUP BY)中性能極佳。
- 批量寫入:適合批量導入冷數據(如定時任務遷移的批量數據)。
- 優點:
- 查詢性能:在復雜分析場景中顯著優于MySQL和ES。
- 擴展性:支持水平擴展,適合處理PB級數據。
- 成本:開源免費,硬件成本可控(但需優化配置)。
- 高效的壓縮率,減少存儲成本。
- 缺點:
- 寫入模式:不擅長高頻率的小批量寫入(適合批量導入冷數據)。
- 事務支持:不支持傳統事務,適合分析型場景。
- 學習成本:SQL語法和生態相對復雜。
- 數據更新操作(如刪除、修改)效率較低。
(2)、Elasticsearch (ES)
- 適用場景:
- 全文搜索:適合需要快速全文檢索的場景(如日志、文本內容搜索)。
- 實時分析:適合半結構化數據(如日志、JSON文檔)的實時查詢和統計。
- 高并發寫入:支持高吞吐量的寫入(如實時日志收集)。
- 優點:
- 全文檢索:強大的全文搜索和模糊匹配能力。
- 實時性:數據寫入后可立即查詢,適合近實時分析。
- 靈活性:支持動態Schema,適合非結構化或半結構化數據。
- 擴展性:分布式架構,易于水平擴展。
- 缺點:
- 聚合性能:復雜聚合查詢(如多維度統計)可能不如ClickHouse高效。
- 存儲成本:存儲成本較高(需較多資源存儲倒排索引)。
- 數據模型限制:不適合強事務和復雜關聯查詢。
2、冷數據存儲的典型場景選擇
(1)、選擇ClickHouse的場景
- 冷數據用途:
需要頻繁的聚合分析(如統計過去一年的用戶行為、訂單趨勢、日志分析等)。 - 數據類型:
結構化數據(如訂單表、日志表、交易記錄等)。 - 示例:
- 將MySQL中超過6個月的訂單數據遷移到ClickHouse,用于生成歷史銷售報告。
- 將系統日志數據存入ClickHouse,用于分析用戶行為趨勢。
(2)、選擇ES的場景
- 冷數據用途:
需要全文搜索或實時日志分析(如日志檢索、文本內容分析)。- 例如:搜索過去一年中包含特定關鍵詞的日志條目。
- 數據類型:
非結構化或半結構化數據(如日志、JSON文檔、文本內容等)。 - 示例:
- 將MySQL中歷史聊天記錄遷移到ES,支持用戶搜索歷史對話中的關鍵詞。
- 將系統日志存入ES,用于快速定位錯誤日志。
(3)、混合使用場景
- 冷數據同時需要分析和搜索:
可將結構化數據(如訂單金額、用戶ID)存入ClickHouse,非結構化數據(如訂單備注、日志內容)存入ES。 - 分層存儲:
- 熱數據:MySQL(實時事務處理)。
- 冷數據:
- ClickHouse(結構化數據(如:具體的數值,金額,年齡等)的分析)。
- ES(非結構化數據(文檔,文本,JSON)的搜索)。
3、冷數據遷移方案設計
(1)、定義冷數據規則:
- 時間維度:如超過6個月未更新的數據。
- 訪問頻率:如過去3個月未被查詢的數據。
(2)、數據遷移工具:
- ClickHouse:使用clickhouse-copier或自定義ETL工具批量導入。
- ES:使用Logstash或Bulk API批量導入。
(3)、查詢邏輯改造:
- 業務查詢時,優先查詢MySQL(熱數據),若未命中則查詢冷數據源(ClickHouse/ES)。
4、具體場景示例
場景:電商平臺訂單數據
- 熱數據:
MySQL存儲最近3個月的訂單數據,用于實時下單、支付等操作。 - 冷數據:
- ClickHouse:存儲超過3個月的訂單數據,用于生成銷售報告(如按地區統計GMV)。
- ES:存儲訂單備注中的文本內容,支持用戶搜索歷史訂單中的關鍵詞(如“紅色T恤”)。
技術選型依據:
- ClickHouse:
訂單金額、用戶ID、時間戳等結構化數據的聚合分析(如SUM(order_amount))。 - ES:
訂單備注、用戶評價等文本內容的全文檢索。
5、ClickHouse和ES建議對比
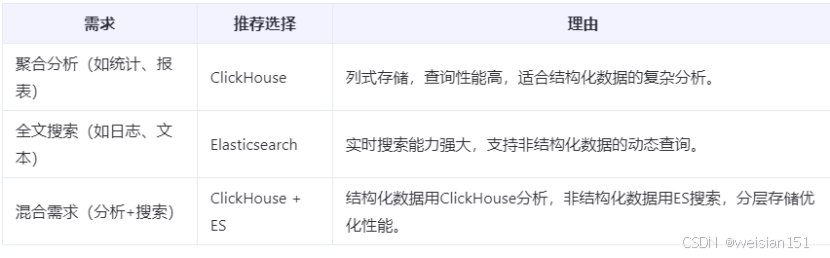
6、其他替代組件的推薦
(1)、對象存儲(如AWS S3、阿里云OSS)
適用場景:
- 歸檔類冷數據:長期存儲(如1年以上)且極少訪問的數據。
- 低成本存儲:通過Parquet、ORC 等列式格式存儲,配合Spark/Flink進行批量分析。
優勢:
- 存儲成本低,適合冷數據的長期歸檔。
- 適合離線分析(如生成月報、年報)。
(2)、HBase或HDFS
適用場景:
- 半結構化/非結構化數據:如日志、事件日志、需要高擴展性的冷數據。
- 時序數據:通過時間戳分區存儲,支持范圍查詢。
優勢:
- HBase支持高并發讀寫,適合部分冷數據仍需少量更新的場景。
- HDFS適合離線批處理(如 Hadoop 分析)。
(3)、分布式數據庫(如TiDB、CockroachDB)
適用場景:
- 混合冷熱數據:需要同時支持 OLTP(熱數據)和 OLAP(冷數據)的場景。
- 強一致性要求:冷數據仍需少量更新或跨庫事務。
優勢:
- 自動水平擴展,支持 HTAP(混合事務與分析處理)。
(4)、時序數據庫(如 InfluxDB、TimescaleDB)
適用場景:
- 時間序列數據:如 IoT 設備數據、監控指標、傳感器數據。
- 按時間范圍查詢:支持自動過期(TTL)和壓縮。
優勢:
- 針對時序數據優化,查詢效率高,存儲成本低。
7、其他組件對比
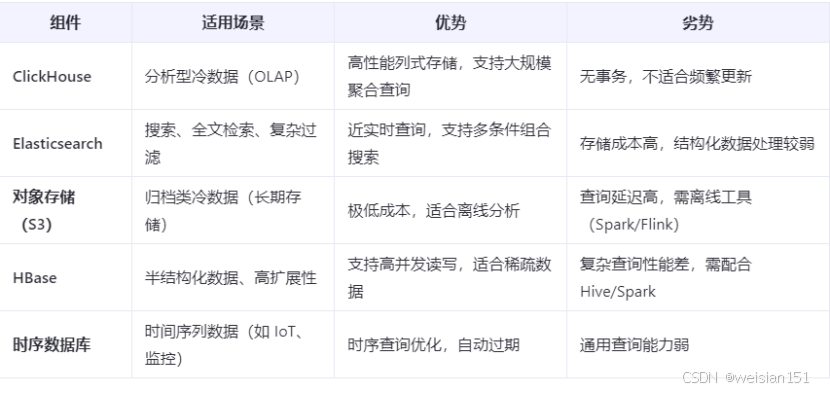
8、最佳實踐建議
(1)、根據冷數據的用途選擇組件
- 僅需分析(如報表、趨勢) → ClickHouse
- 需要搜索或全文檢索(如日志、評論) → ES
- 長期歸檔且極少訪問 → 對象存儲(S3)
- 時間序列數據(按時間查詢) → InfluxDB
(2)、混合架構方案
- 熱數據:保留在 MySQL(或分庫分表優化)。
- 冷數據:
- 分析需求 → ClickHouse(主) + 對象存儲S3(歸檔)。
- 搜索需求 → ES(主) + 對象存儲S3(歸檔)。
(3)、數據遷移策略
- 觸發條件:
- 時間維度(如3個月前)或狀態維度(如訂單已完結)。
- 可通過定時任務或觸發器遷移。
- 遷移工具:
- MySQL → ClickHouse:用INSERT SELECT或工具(如 Maxwell、Debezium)。
- MySQL → ES:用Logstash、Flink 或自定義ETL。
(4)、成本優化
- 存儲分層:
- 熱數據 → SSD 存儲(高性能 MySQL 實例)。
- 冷數據 → HDD 存儲(低成本 ClickHouse 集群或對象存儲)。
逆風成長,Dare To Be!!!










)








