路徑問題
????????相對路徑與絕對路徑:建議使用絕對路徑,避免復制粘貼導致的錯誤,必要時將斜杠改為雙反斜杠。
數據處理與展示
SQL 風格語法:創建臨時視圖并使用 SQL?風格語法查詢數據。
DSL 風格語法:使用 DSL 風格語法查詢?user?表中的?user name?和?age?列。
http://【Spark-SQL核心編程 - CSDN App】https://blog.csdn.net/2401_84627304/article/details/147227309?sharetype=blog&shareId=147227309&sharerefer=APP&sharesource=2401_84627304&sharefrom=link
(我的博客文章? spark-SQL核心編程??? ?目錄中能找到? ? ? ? ????)
利用IDEA開發Spark-SQL
????????導入的包
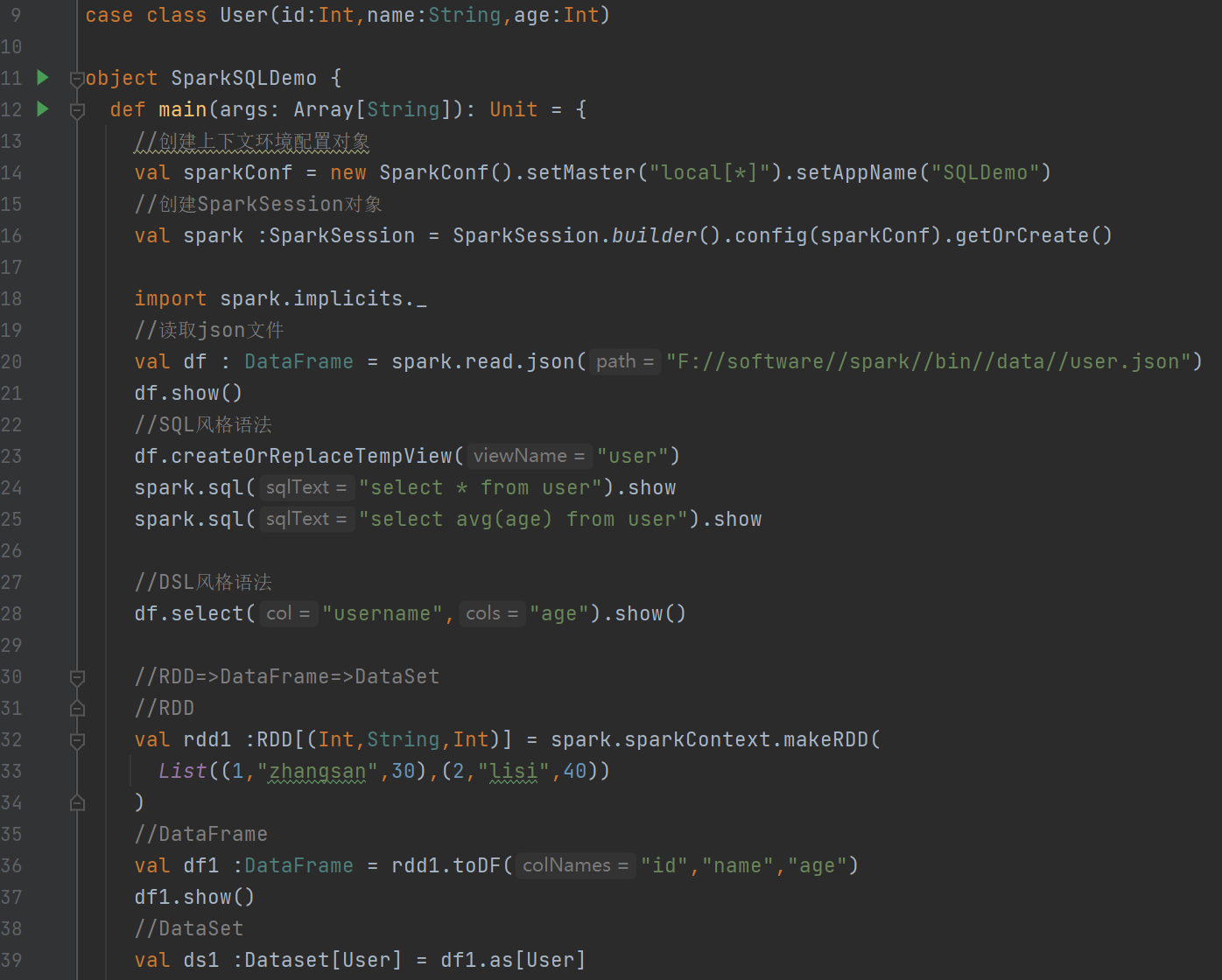
?下面的代碼 (
val df : DataFrame后面的地址是自己放的文檔的地址
)
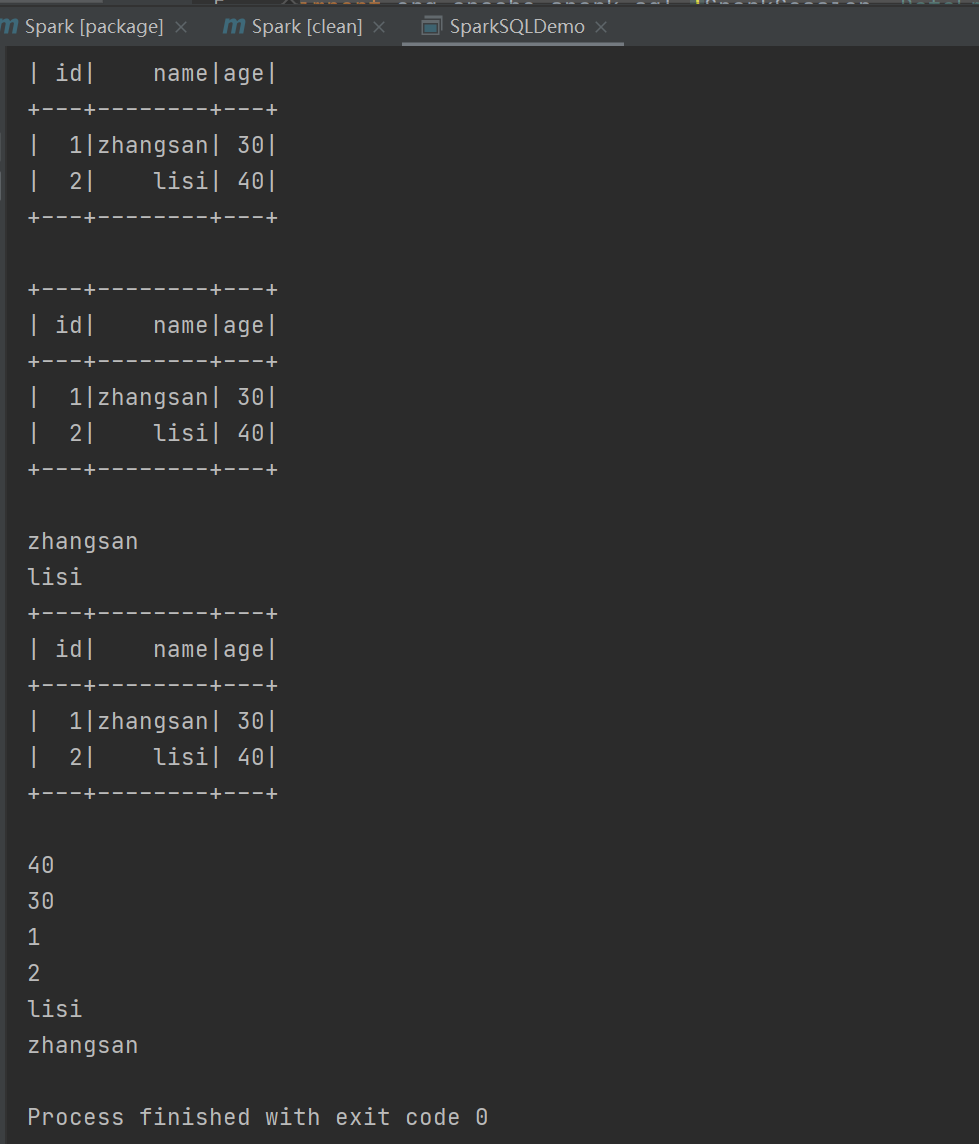
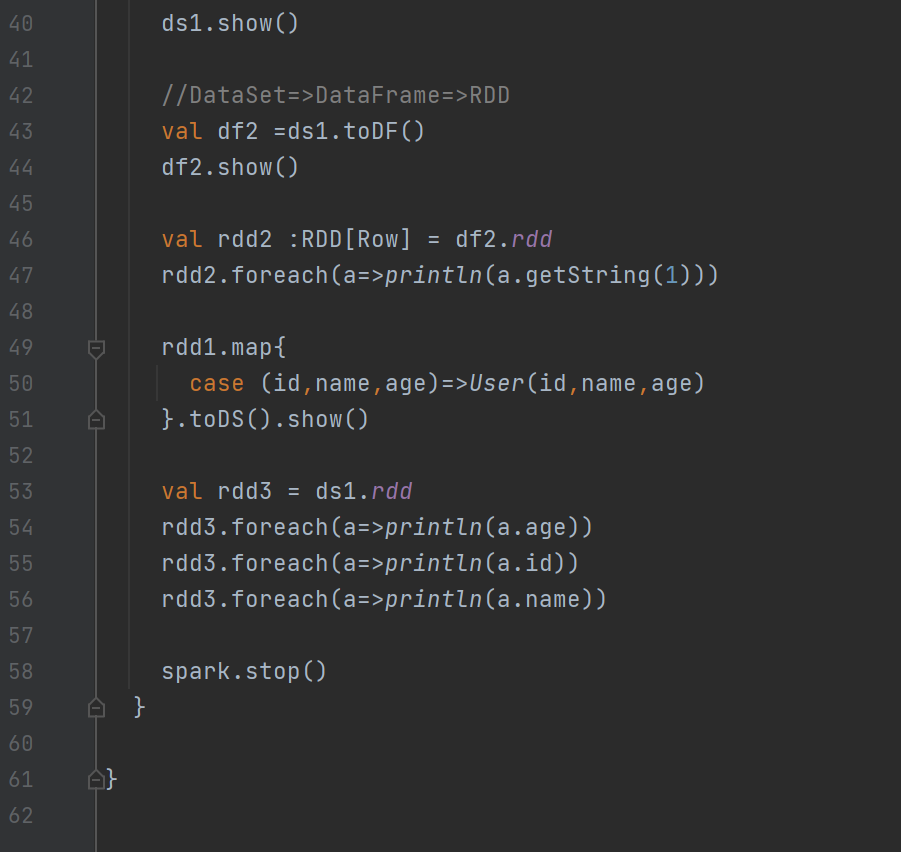 ?運行結果:
?運行結果:
自定義函數:
UDF
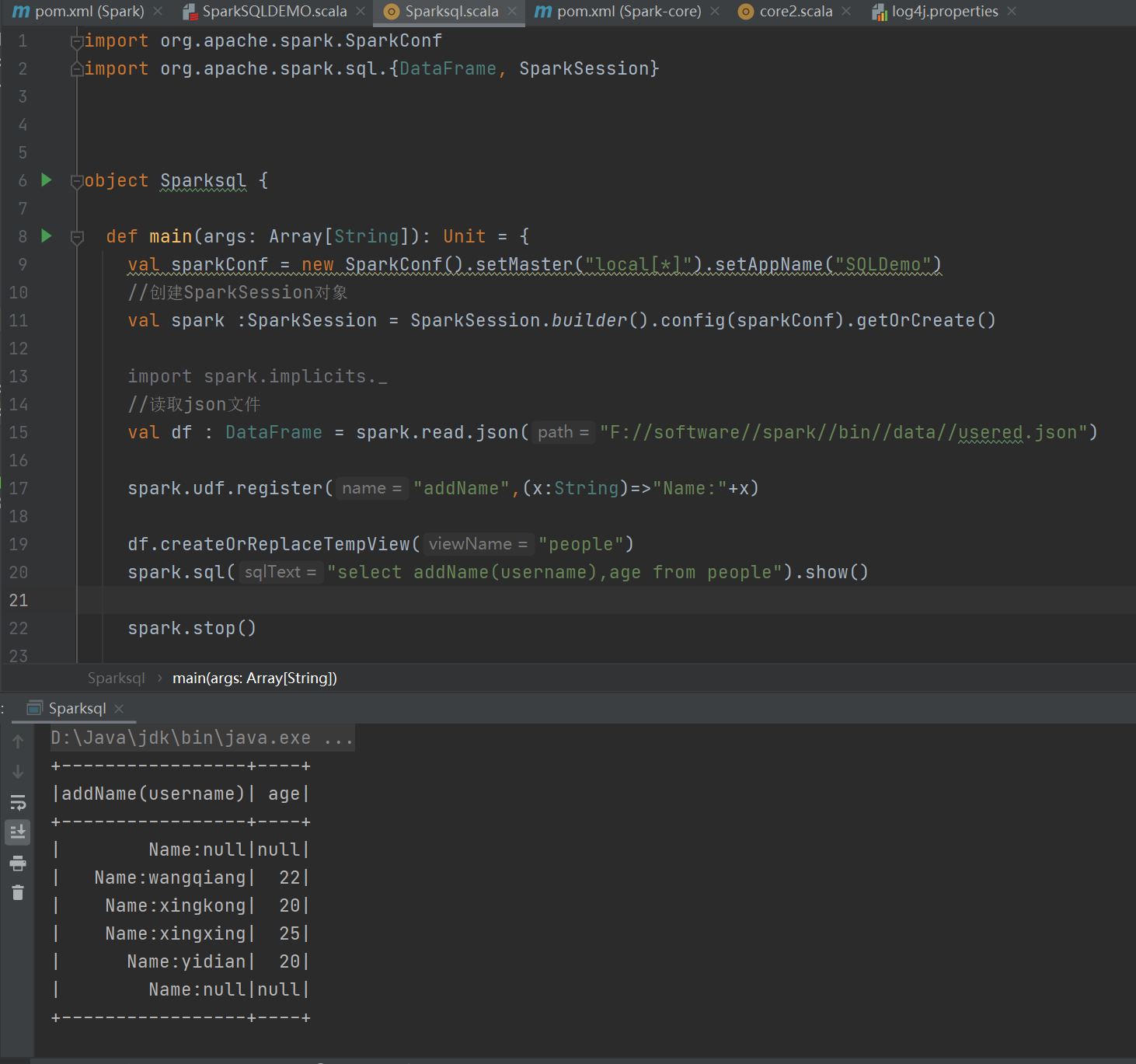
UDAF(自定義聚合函數)
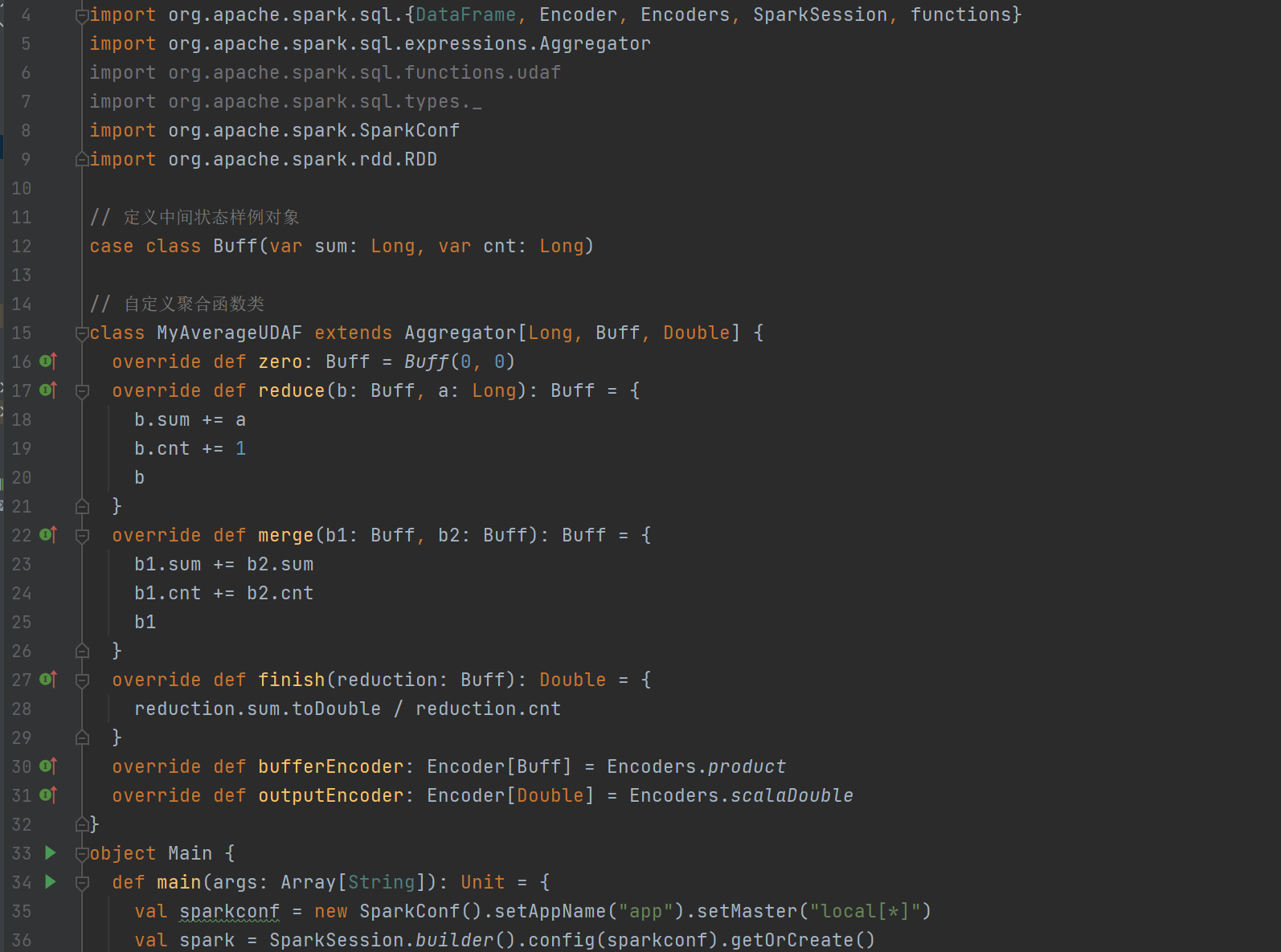
????????強類型的 Dataset 和弱類型的 DataFrame 都提供了相關的聚合函數, 如 count(),countDistinct(),avg(),max(),min()。除此之外,用戶可以設定自己的自定義聚合函數。Spark3.0之前我們使用的是UserDefinedAggregateFunction作為自定義聚合函數,從 Spark3.0 版本后可以統一采用強類型聚合函數 Aggregator
實驗需求:計算平均工資
?實現方式一:RDD
RDD 實現:通過 RDD 進行薪資數據的映射和聚合,計算平均工資。
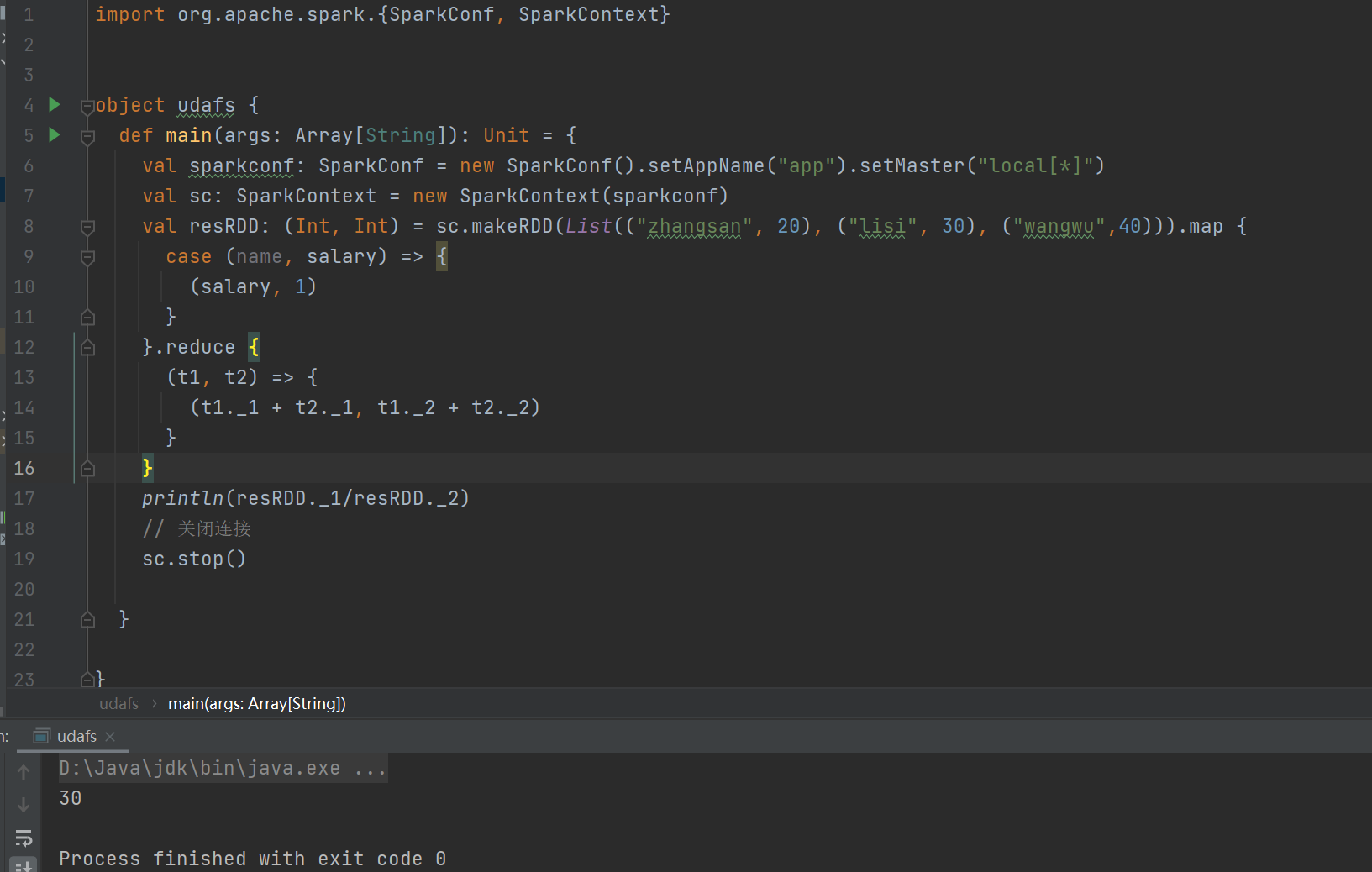
case (name, salary) => {
??? (salary, 1)
? }
這個代碼是為了弱化沒有關系的東西,比如這個平均薪資中名字不重要
實現方式二:弱類型 UDAF 實現:
通過創建類和函數,封裝并調用自定義聚合函數,計算平均工資。
class MyAverageUDAF extends UserDefinedAggregateFunction{def inputSchema: StructType =StructType(Array(StructField("salary",IntegerType)))// 聚合函數緩沖區中值的數據類型(salary,count)def bufferSchema: StructType = {StructType(Array(StructField("sum",LongType),StructField("count",LongType)))}// 函數返回值的數據類型def dataType: DataType = DoubleType// 穩定性:對于相同的輸入是否一直返回相同的輸出。def deterministic: Boolean = true// 函數緩沖區初始化def initialize(buffer: MutableAggregationBuffer): Unit = {// 存薪資的總和buffer(0) = 0L// 存薪資的個數buffer(1) = 0L}// 更新緩沖區中的數據def update(buffer: MutableAggregationBuffer,input: Row): Unit = {if (!input.isNullAt(0)) {buffer(0) = buffer.getLong(0) + input.getInt(0)buffer(1) = buffer.getLong(1) + 1}}// 合并緩沖區def merge(buffer1: MutableAggregationBuffer,buffer2: Row): Unit = {buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)}// 計算最終結果def evaluate(buffer: Row): Double = buffer.getLong(0).toDouble /buffer.getLong(1)}
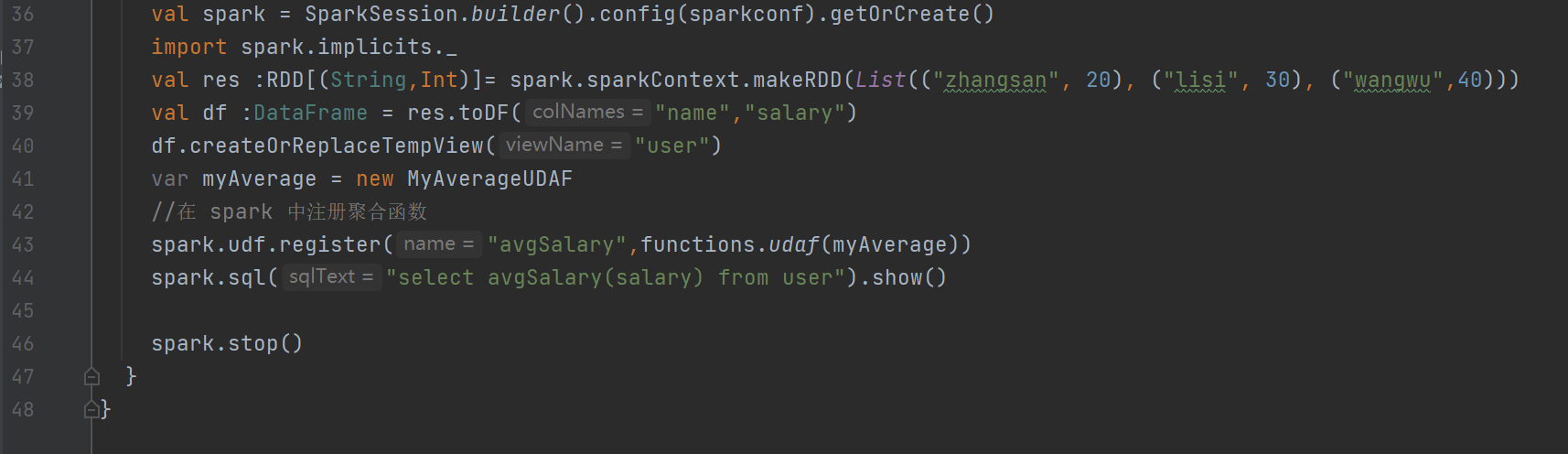
val sparkconf: SparkConf = new SparkConf().setAppName("app").setMaster("local[*]")val spark:SparkSession = SparkSession.builder().config(conf).getOrCreate()import spark.implicits._val res :RDD[(String,Int)]= spark.sparkContext.makeRDD(List(("zhangsan", 20), ("lisi", 30), ("wangwu",40)))val df :DataFrame = res.toDF("name","salary")df.createOrReplaceTempView("user")var myAverage = new MyAverageUDAF//在 spark 中注冊聚合函數spark.udf.register("avgSalary",myAverage)spark.sql("select avgSalary(salary) from user").show()// 關閉連接spark.stop()
? ? ? ?注意:
?????????第一行帶下劃線的如果運用代碼出現刪除線,這個能用,只是提醒你有別的最新的法
實現方式三:強類型UDAF
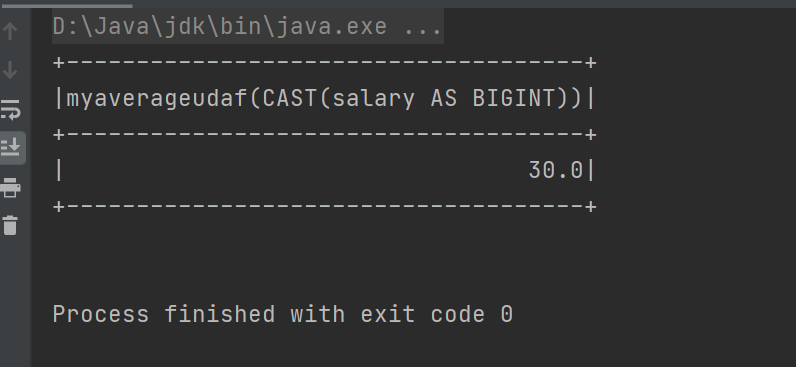 ?
?

微服務保護和分布式事務)
![洛谷P1312 [NOIP 2011 提高組] Mayan 游戲](http://pic.xiahunao.cn/洛谷P1312 [NOIP 2011 提高組] Mayan 游戲)






——圖像的透視變換)


)


適配器模式)



