物體檢測
目標檢測和圖片分類的區別:
圖像分類(Image Classification)
目的:圖像分類的目的是識別出圖像中主要物體的類別。它試圖回答“圖像是什么?”的問題。
輸出:通常輸出是一個標簽或一組概率值,表示圖像屬于各個預定義類別的可能性。例如,對于一張包含貓的圖片,分類器可能會輸出“貓”這個標簽。
應用場景:適用于只需要了解圖像整體內容的場景,如識別照片中的動物種類、區分不同的風景類型等。
目標檢測(Object Detection)
目的:目標檢測不僅需要識別圖像中所有感興趣物體的類別,還需要確定每個物體在圖像中的具體位置。它試圖回答“圖像中有什么?它們在哪里?”的問題。
輸出:除了給出物體的類別外,還會輸出物體所在的邊界框(bounding box),即用矩形框標記出每個物體的位置。例如,在自動駕駛場景下,系統不僅要能識別出行人、車輛等物體,還要精確地定位它們的位置以便做出安全決策。
應用場景:適合于需要知道圖像內特定對象位置的情況,比如視頻監控、自動駕駛汽車、醫學影像分析等領域。
邊緣框
- 一個邊緣框可以通過 4 個數字定義
- (左上 x,左上 y,右下 x,右下 y)
- (左上 x,左上 y,寬,高)

目標檢測數據集
- 每行表示一個物體
- 圖片文件名,物體類別,邊緣框
- COCO (cocodataset.org)
- 80 物體,330K 圖片,1.5M 物體
總結
- 物體檢測識別圖片里的多個物體的類別和位置
- 位置通常用邊緣框表示。
邊緣框實現
%matplotlib inline
import torch
from d2l import torch as d2ld2l.set_figsize()
img = d2l.plt.imread('../img/catdog.jpg')
d2l.plt.imshow(img);

定義在這兩種表示法之間進行轉換的函數
#@save
def box_corner_to_center(boxes):"""從(左上,右下)轉換到(中間,寬度,高度)"""x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]cx = (x1 + x2) / 2cy = (y1 + y2) / 2w = x2 - x1h = y2 - y1boxes = torch.stack((cx, cy, w, h), axis=-1)return boxes#@save
def box_center_to_corner(boxes):"""從(中間,寬度,高度)轉換到(左上,右下)"""cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]x1 = cx - 0.5 * wy1 = cy - 0.5 * hx2 = cx + 0.5 * wy2 = cy + 0.5 * hboxes = torch.stack((x1, y1, x2, y2), axis=-1)return boxes
定義圖像中狗和貓的邊界框
# bbox是邊界框的英文縮寫
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]boxes = torch.tensor((dog_bbox, cat_bbox))
box_center_to_corner(box_corner_to_center(boxes)) == boxes
將邊界框在圖中畫出
#@save
def bbox_to_rect(bbox, color):# 將邊界框(左上x,左上y,右下x,右下y)格式轉換成matplotlib格式:# ((左上x,左上y),寬,高)return d2l.plt.Rectangle(xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],fill=False, edgecolor=color, linewidth=2)fig = d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'));

數據集
李沐老師收集并標記了一個小型數據集,下面首先是下載該數據集:
%matplotlib inline
import os
import pandas as pd
import torch
import torchvision
from d2l import torch as d2l#@save
d2l.DATA_HUB['banana-detection'] = (d2l.DATA_URL + 'banana-detection.zip','5de26c8fce5ccdea9f91267273464dc968d20d72')
讀取香蕉檢測數據集
#@save
def read_data_bananas(is_train=True):"""讀取香蕉檢測數據集中的圖像和標簽"""data_dir = d2l.download_extract('banana-detection')csv_fname = os.path.join(data_dir, 'bananas_train' if is_trainelse 'bananas_val', 'label.csv')csv_data = pd.read_csv(csv_fname)csv_data = csv_data.set_index('img_name')images, targets = [], []for img_name, target in csv_data.iterrows():images.append(torchvision.io.read_image(os.path.join(data_dir, 'bananas_train' if is_train else'bananas_val', 'images', f'{img_name}')))# 這里的target包含(類別,左上角x,左上角y,右下角x,右下角y),# 其中所有圖像都具有相同的香蕉類(索引為0)targets.append(list(target))return images, torch.tensor(targets).unsqueeze(1) / 256
創建一個自定義 Dataseet 實例:
#@save
class BananasDataset(torch.utils.data.Dataset):"""一個用于加載香蕉檢測數據集的自定義數據集"""def __init__(self, is_train):self.features, self.labels = read_data_bananas(is_train)print('read ' + str(len(self.features)) + (f' training examples' ifis_train else f' validation examples'))def __getitem__(self, idx):return (self.features[idx].float(), self.labels[idx])def __len__(self):return len(self.features)
為訓練集和測試集返回兩個數據加載器實例
#@save
def load_data_bananas(batch_size):"""加載香蕉檢測數據集"""train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True),batch_size, shuffle=True)val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False),batch_size)return train_iter, val_iter
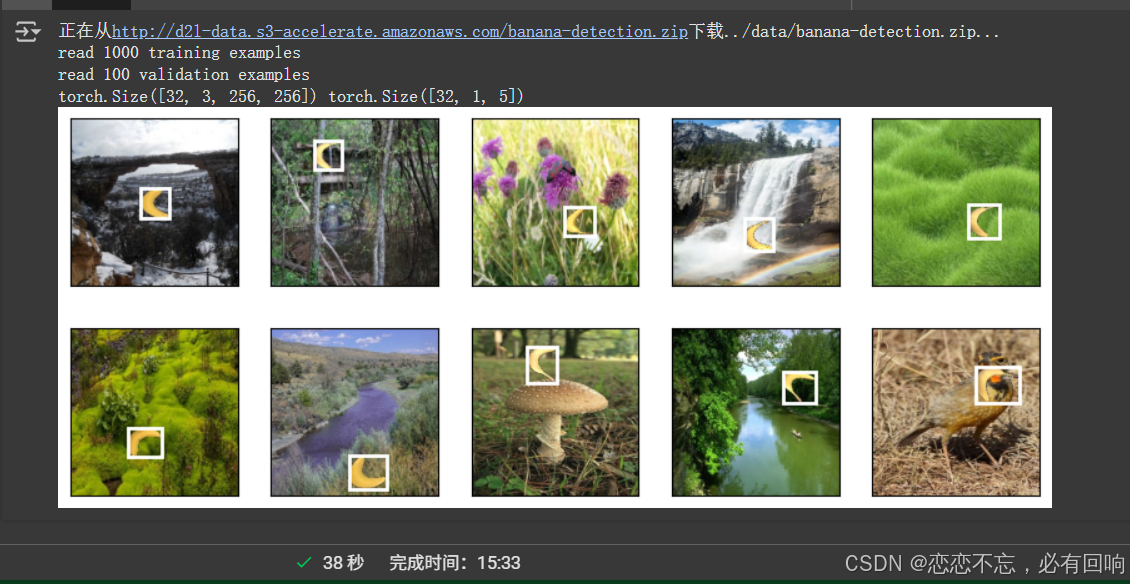
讀取一個小批量,并打印其中的圖像和標簽的形狀
batch_size, edge_size = 32, 256
train_iter, _ = load_data_bananas(batch_size)
batch = next(iter(train_iter))
batch[0].shape, batch[1].shape

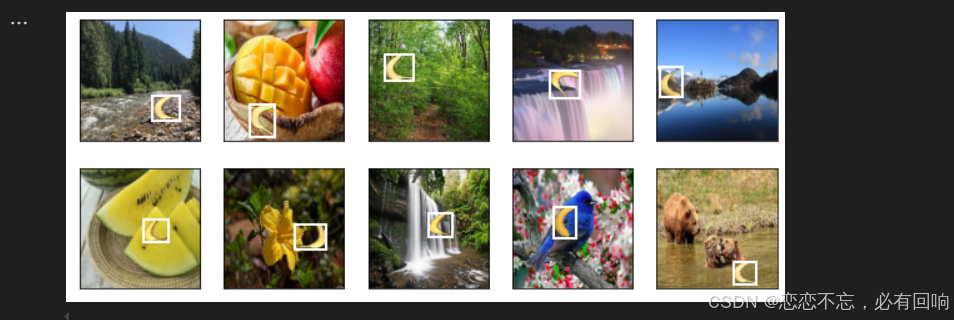
演示:
imgs = (batch[0][0:10].permute(0, 2, 3, 1)) / 255
axes = d2l.show_images(imgs, 2, 5, scale=2)
for ax, label in zip(axes, batch[1][0:10]):d2l.show_bboxes(ax, [label[0][1:5] * edge_size], colors=['w'])
QA 思考
Q1:如果在工業檢測中數據集非常小(近百張),除了進行數據增強外,還有什么更好的方法嗎?
A1:遷移學習:找一個非常好的,在一個比較大的目標檢測數據集上訓練的比較好的模型,然后拿過來進行微調。近百張其實也不算小的了,只是說模型訓練出來不是很好。數據增強的話,對圖像進行處理,對應的框也必須要相應的變化一下,這是比較麻煩的點。
后記
自己實現了一遍,然后也是使用的李沐老師在課件中提供的狗貓圖片:
import torch
from matplotlib import pyplot as plt
from PIL import Imagedef set_image_display_size():plt.figure(figsize=(8, 6))def load_image(img_path):return Image.open(img_path)def show_single_image(img):plt.imshow(img)plt.axis('on') # 顯示坐標軸plt.show()def box_corner_to_center(boxes):x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]cx = (x1 + x2) / 2cy = (y1 + y2) / 2w = x2 - x1h = y2 - y1boxes = torch.stack((cx, cy, w, h), axis=-1)return boxesdef box_center_to_corner(boxes):# 這里向左和向上都是減小的cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]x1 = cx - 0.5 * wy1 = cy - 0.5 * hx2 = cx + 0.5 * wy2 = cy + 0.5 * hboxes = torch.stack((x1, y1, x2, y2), axis=-1)return boxesdef bbox_to_rect(bbox, color):# 將邊界框(左上x, 左上y, 右下x, 右下y)格式轉換成matplotlib格式:# ((左上x, 左上y), 寬, 高)return plt.Rectangle(xy=(bbox[0], bbox[1]), width=bbox[2] - bbox[0], height=bbox[3] - bbox[1],fill=False, edgecolor=color, linewidth=2)if __name__ == "__main__":# 設置圖像顯示大小set_image_display_size()# 加載圖像img_path = '../image/catdog.jpg' # 確保路徑正確img = load_image(img_path)show_single_image(img)# dog, cat 邊界框dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]# 轉換為張量并測試轉換函數是否正確boxes = torch.tensor((dog_bbox, cat_bbox))converted_boxes = box_center_to_corner(box_corner_to_center(boxes))# torch.allclose,判斷兩個張量是否在一定容差范圍內相等。print("轉換是否一致:", torch.allclose(converted_boxes, boxes))# 顯示圖像并繪制邊界框,imshow 將 img 顯示在畫布上fig = plt.imshow(img)# add_patch 是 matplotlib 中用于在坐標軸上添加圖形元素(如矩形、圓形等)的函數fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue')) # 狗的邊界框fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red')) # 貓的邊界框plt.show()
我在colab上跑了一下下面的代碼,發現可以,下載不了的可能需要一點 “魔法”
import hashlib
import os
import tarfile
import zipfile
import pandas as pd
import requests
import torch
import torchvisionfrom matplotlib import pyplot as plt"""這段代碼本身并沒有包含訓練過程。它只是加載了已經標注好的香蕉檢測數據集,并可視化了圖像及其對應的邊界框。這些邊界框信息是預先標注好的(存儲在 CSV 文件中),而不是通過模型訓練得到的。read_data_bananas 函數讀取數據集中的圖像和標簽:圖像存儲在文件夾中(如 bananas_train/images/)。標簽存儲在 CSV 文件中(如 bananas_train/label.csv)。每個標簽包括圖像名稱、目標類別(香蕉類別的索引為 0)、以及邊界框坐標。zip 結構類似如下:banana-detection/├── bananas_train/│ ├── images/│ │ ├── image1.jpg│ │ ├── image2.jpg│ │ └── ...│ └── label.csv # 包含每張圖像的標注信息(即邊界框和類別)└── bananas_val/├── images/│ ├── image1.jpg│ ├── image2.jpg│ └── ...└── label.csv
"""
DATA_HUB = dict()
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'DATA_HUB['banana-detection'] = (DATA_URL + 'banana-detection.zip','5de26c8fce5ccdea9f91267273464dc968d20d72')def download(name, cache_dir=os.path.join('..', 'data')):"""下載一個DATA_HUB中的文件,返回本地文件名"""# assert 條件, 錯誤信息assert name in DATA_HUB, f"{name} 不存在于 {DATA_HUB}""""url:文件的下載地址。 http://d2l-data.s3-accelerate.amazonaws.com/banana-detection.zipsha1_hash:文件內容的 SHA-1 校驗值,用于驗證文件完整性。5de26c8fce5ccdea9f91267273464dc968d20d72"""url, sha1_hash = DATA_HUB[name]"""遞歸創建目錄:包括所有必要的父目錄。避免重復創建導致的錯誤:如果目錄已經存在,不會拋出異常。"""os.makedirs(cache_dir, exist_ok=True)"""url.split('/')[-1]:提取 URL 路徑的最后一部分(通常是文件名)。os.path.join(cache_dir, ...):將緩存目錄和文件名組合成完整的本地文件路徑。"""fname = os.path.join(cache_dir, url.split('/')[-1]) # fname = ../data/banana-detection.zipif os.path.exists(fname): # 文件存在,進入校驗流程# 創建一個 SHA-1 哈希對象,用于計算文件的哈希值。sha1 = hashlib.sha1()# 以二進制模式讀取文件with open(fname, 'rb') as f:while True:# 每次讀取 1MB 數據(1048576 字節),更新哈希對象。data = f.read(1048576)# 為空,退出循環if not data:break# 將讀取的數據塊逐步添加到哈希計算中sha1.update(data)"""計算哈希值:調用 sha1.hexdigest() 獲取最終的 SHA-1 哈希值(40 個字符的十六進制字符串)。校驗哈希值:將計算得到的哈希值與預期的哈希值 sha1_hash 進行比較。如果兩者相等,說明文件完整且未被篡改,直接返回文件路徑(命中緩存)。否則,繼續執行下載邏輯。"""if sha1.hexdigest() == sha1_hash:return fname # 命中緩存print(f'正在從{url}下載{fname}...')"""使用 requests.get 方法發送 HTTP 請求,從遠程服務器下載文件。參數說明:stream=True:以流式方式下載文件,避免一次性加載整個文件到內存中。verify=True:啟用 SSL 證書驗證,確保安全連接。"""r = requests.get(url, stream=True, verify=True)"""打開本地文件 fname,以二進制寫入模式('wb')創建或覆蓋文件。將下載的內容 r.content 寫入文件。下載完成后,關閉文件。"""with open(fname, 'wb') as f:f.write(r.content)return fnamedef download_extract(name, folder=None):"""下載并解壓zip/tar文件"""fname = download(name) # 下載文件的完整路徑"""os.path.dirname(fname):提取文件所在的目錄路徑(即父目錄)。例如,如果 fname 是 '../data/example.zip',則 base_dir 是 '../data'。os.path.splitext(fname):將文件路徑拆分為文件名和擴展名。例如,如果 fname 是 '../data/example.zip',則 data_dir 是 '../data/example',ext 是 '.zip'。"""base_dir = os.path.dirname(fname)data_dir, ext = os.path.splitext(fname)if ext == '.zip':fp = zipfile.ZipFile(fname, 'r')elif ext in ('.tar', '.gz'):fp = tarfile.open(fname, 'r')else:assert False, '只有zip/tar/gz 文件可以被解壓縮'# 解壓文件到指定的目錄 base_dirfp.extractall(base_dir)"""如果 folder 參數存在:返回 os.path.join(base_dir, folder),即解壓后目錄下的指定子目錄。如果 folder 參數不存在:返回 data_dir,即解壓后的默認目錄。"""return os.path.join(base_dir, folder) if folder else data_dirdef read_data_bananas(is_train=True):"""讀取香蕉檢測數據集中的圖像和標簽"""data_dir = download_extract('banana-detection')"""根據 is_train 參數,確定加載訓練集還是驗證集的標注文件:如果 is_train=True,加載 'bananas_train/label.csv'。如果 is_train=False,加載 'bananas_val/label.csv'。使用 pandas 庫的 read_csv 方法讀取 CSV 文件內容。將 img_name 列設置為索引列(方便后續按圖像名稱訪問數據)。"""csv_fname = os.path.join(data_dir, 'bananas_train' if is_trainelse 'bananas_val', 'label.csv') # for example: ../data/banana-detection/banana_train/label.csvcsv_data = pd.read_csv(csv_fname) # 讀取 csv 文件# 將 img_name 列設置為索引列csv_data = csv_data.set_index('img_name')"""images:用于存儲讀取的圖像數據。targets:用于存儲每張圖像對應的標注信息。"""images, targets = [], []"""img_name:當前行的索引值(即圖像名稱)。target:當前行的數據(即標注信息)。"""for img_name, target in csv_data.iterrows():images.append(torchvision.io.read_image(os.path.join(data_dir, 'bananas_train' if is_train else'bananas_val', 'images', f'{img_name}')))# 這里的target包含(類別,左上角x,左上角y,右下角x,右下角y),# 其中所有圖像都具有相同的香蕉類(索引為0)targets.append(list(target))"""images:圖像數據列表。torch.tensor(targets).unsqueeze(1) / 256:將 targets 轉換為 PyTorch 張量。使用 unsqueeze(1) 在維度 1 上增加一個維度,使其形狀變為 (N, 1, 5),其中 N 是樣本數量,5 是每個標注信息的長度。所有邊界框坐標除以 256,進行歸一化處理(假設圖像大小為 256x256)。"""return images, torch.tensor(targets).unsqueeze(1) / 256class BananasDataset(torch.utils.data.Dataset):"""一個用于加載香蕉檢測數據集的自定義數據集"""def __init__(self, is_train):self.features, self.labels = read_data_bananas(is_train)print('read ' + str(len(self.features)) + (f' training examples' ifis_train else f' validation examples'))# such as : read 1000 training examplesdef __getitem__(self, idx):return self.features[idx].float(), self.labels[idx]def __len__(self):return len(self.features)def load_data_bananas(batch_size):"""加載香蕉檢測數據集"""train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True),batch_size, shuffle=True)val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False),batch_size)return train_iter, val_iterdef show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):figsize = (num_cols * scale, num_rows * scale)"""_:表示整個圖形對象(這里用下劃線忽略)axes:表示所有子圖的數組"""_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)axes = axes.flatten()for i, (ax, img) in enumerate(zip(axes, imgs)):if torch.is_tensor(img):ax.imshow(img.numpy())else:ax.imshow(img)ax.axes.get_xaxis().set_visible(False)ax.axes.get_yaxis().set_visible(False)if titles:ax.set_title(titles[i])return axesdef bbox_to_rect(bbox, color):"""將邊界框(左上x,左上y,右下x,右下y)格式轉換成matplotlib格式:((左上x,左上y),寬,高)"""return plt.Rectangle(xy=(bbox[0], bbox[1]), width=bbox[2] - bbox[0], height=bbox[3] - bbox[1],fill=False, edgecolor=color, linewidth=2)# 定義一個名為 numpy 的函數,它能夠將 PyTorch 張量轉換為 NumPy 數組,并且自動處理張量的梯度信息
numpy = lambda x, *args, **kwargs: x.detach().numpy(*args, **kwargs)def show_bboxes(axes, bboxes, labels=None, colors=None):"""顯示所有邊界框""""""功能:將輸入對象轉換為列表形式。如果 obj 是 None,返回默認值 default_values。如果 obj 不是列表或元組,則將其包裝成單元素列表。否則,直接返回 obj。作用:確保 labels 和 colors 參數始終是列表形式,以便后續迭代操作。"""def _make_list(obj, default_values=None):if obj is None:obj = default_valueselif not isinstance(obj, (list, tuple)):obj = [obj]return obj"""將 labels 轉換為列表形式。如果未提供標簽,則返回空列表。將 colors 轉換為列表形式。如果未提供顏色,則使用默認顏色列表 ['b', 'g', 'r', 'm', 'c'](藍色、綠色、紅色、洋紅色、青色)。"""labels = _make_list(labels)colors = _make_list(colors, ['b', 'g', 'r', 'm', 'c'])"""遍歷 bboxes 列表中的每個邊界框 bbox。根據索引 i,從 colors 列表中循環選擇顏色(防止顏色不足時重復使用)。調用 bbox_to_rect 函數,將邊界框坐標轉換為 Matplotlib 的矩形對象。假設 bbox_to_rect 是一個已定義的函數,用于將邊界框坐標轉換為 matplotlib.patches.Rectangle 對象。numpy(bbox):將邊界框數據轉換為 NumPy 數組(假設 bbox 是 PyTorch 張量)。使用 axes.add_patch(rect) 將矩形添加到繪圖區域中。"""for i, bbox in enumerate(bboxes):color = colors[i % len(colors)]rect = bbox_to_rect(numpy(bbox), color)axes.add_patch(rect)"""檢查是否提供了標簽,并且當前索引 i 在標簽范圍內。根據邊界框顏色選擇標簽文字的顏色:如果邊界框顏色為白色('w'),標簽文字顏色為黑色('k')。否則,標簽文字顏色為白色('w')。使用 axes.text 方法,在邊界框的左上角位置添加標簽文本。rect.xy[0] 和 rect.xy[1]:矩形左上角的 x 和 y 坐標。va='center' 和 ha='center':設置文本垂直和水平居中對齊。fontsize=9:設置字體大小為 9。color=text_color:設置文本顏色。bbox=dict(facecolor=color, lw=0):為文本添加背景框,背景顏色與邊界框一致,邊框寬度為 0。"""if labels and len(labels) > i:text_color = 'k' if color == 'w' else 'w'axes.text(rect.xy[0], rect.xy[1], labels[i],va='center', ha='center', fontsize=9, color=text_color,bbox=dict(facecolor=color, lw=0))if __name__ == "__main__":batch_size, edge_size = 32, 256train_iter, _ = load_data_bananas(batch_size)"""使用 iter(train_iter) 創建一個迭代器對象。調用 next() 獲取迭代器的第一個批次的數據。"""batch = next(iter(train_iter))"""torch.Size([32, 3, 256, 256]):表示 32 張 RGB 圖像,每張圖像大小為 256x256。torch.Size([32, num_boxes, 5]):表示每張圖像有 num_boxes 個邊界框,每個邊界框包含 5 個值(類別 + 坐標)。 """print(batch[0].shape, batch[1].shape)"""功能:batch[0][0:10]:從 batch[0] 中提取前 10 張圖像。.permute(0, 2, 3, 1):調整張量的維度順序,將 (N, C, H, W) 轉換為 (N, H, W, C),即從 PyTorch 的默認格式轉換為適合顯示的格式。/ 255:將像素值歸一化到 [0, 1] 范圍(假設原始像素值范圍是 [0, 255])。結果:imgs 是一個形狀為 (10, 256, 256, 3) 的張量,表示 10 張歸一化的 RGB 圖像。"""imgs = (batch[0][0:10].permute(0, 2, 3, 1)) / 255axes = show_images(imgs, 2, 5, scale=2)for ax, label in zip(axes, batch[1][0:10]):"""label[0][1:5]:提取第一個邊界框的坐標信息([x_min, y_min, x_max, y_max])。* edge_size:將歸一化的坐標值還原為原始像素坐標。show_bboxes(ax, ...):在子圖 ax 上繪制邊界框,顏色為白色 ('w')。"""show_bboxes(ax, [label[0][1:5] * edge_size], colors=['w'])plt.show()
"""
歸一化是為了模型訓練:確保輸入數據在合理的范圍內,加速收斂并提高穩定性。
還原是為了可視化:將數據轉換回原始范圍,以便人類可以直觀地理解圖像和標注信息。
"""


)
)





create_shape_model_xld)









