深度學習框架與大模型技術的融合正推動人工智能應用的新一輪變革。百度飛槳(PaddlePaddle)作為國內首個自主研發、開源開放的深度學習平臺,近期推出的3.0版本針對大模型時代的開發痛點進行了系統性革新。其核心創新包括“動靜統一自動并行”,“訓推一體設計”,“科學計算高階微分”,“神經網絡編譯器”,“異構多芯適配”等技術,顯著降低大模型訓練與推理的成本,并支持多硬件適配與高效部署。
本文將過實際基于PaddleNLP 3.0框架本地部署DeepSeek-R1-Distill-Qwen-1.5B,并結合架構特性與實戰經驗,解析其在推理優化、硬件適配及產業應用中的技術價值。
一、大模型時代的框架革新:飛槳3.0架構解析
深度學習框架作為AI技術棧的基礎設施,其設計理念與架構能力直接決定了上層模型開發的效率與性能。隨著大模型參數規模從億級向萬億級邁進,傳統框架在分布式訓練、內存優化、計算效率等方面面臨嚴峻挑戰。飛槳3.0通過五大技術特性,系統性解決了這些痛點,為大模型研發與科學智能應用提供了強大的支撐。
1.1、動靜統一自動并行
飛槳3.0提出的“動靜統一自動并行”技術,通過動態圖與靜態圖的深度融合,打破了傳統框架在分布式訓練中的開發門檻。簡單來說,這項技術就像給模型訓練裝上了一個“智能調度員”,能夠自動分配計算任務到多個設備,顯著提升訓練效率。
- 自動并行優化:通過靜態圖的高效執行和動態圖的靈活性,飛槳3.0能夠自動完成分布式訓練的策略選擇與優化,開發者無需手動編寫復雜的分布式代碼。
- 硬件資源利用率提升:自動并行技術能夠充分利用集群資源,減少通信開銷,提升訓練吞吐量,尤其在大規模分布式訓練場景中表現突出。
- 開發門檻降低:開發者只需專注于模型設計,無需擔心底層硬件適配與分布式策略,真正實現“算法創新回歸核心價值創造”。
1.2、大模型訓推一體
在設計理念上,飛槳3.0秉承“訓推一體”設計理念,打破傳統框架中訓練與推理的割裂狀態,通過動轉靜高成功率和統一代碼復用,實現“一次開發,全鏈路優化”,為大模型的全生命周期管理提供了無縫銜接。
- 高性能推理支持:通過深度優化的推理引擎,飛槳3.0支持文心4.5、文心X1等主流大模型的高性能推理,且在DeepSeek-R1滿血版單機部署中,吞吐量提升一倍,顯著降低了推理成本。
- 低時延、高吞吐:訓推一體的設計讓模型在推理階段能夠實現低時延、高吞吐的性能表現,為實時應用場景提供了強有力的支持。
- 統一開發體驗:開發者只需一套代碼即可完成訓練與推理的全流程開發,大幅提升了開發效率,同時降低了部署復雜度。
1.3、科學計算高階微分
在科學智能領域,飛槳3.0通過高階自動微分和神經網絡編譯器技術,為科學智能領域提供了強大的計算支持。
- 微分方程求解加速:飛槳3.0在求解微分方程時,速度比PyTorch開啟編譯器優化后的2.6版本平均快115%,顯著提升了科學計算效率。
- 廣泛適配主流工具:飛槳對DeepXDE、Modulus等主流開源科學計算工具進行了廣泛適配,并成為DeepXDE的默認推薦后端。
- 應用場景拓展:在氣象預測、生命科學、航空航天等領域,飛槳3.0展現了巨大的應用潛力,為科學智能的前沿探索提供了堅實的技術支撐。
1.4、神經網絡編譯器
在運算速度方面,飛槳3.0通過創新研制的神經網絡編譯器CINN,實現了顯著的性能提升。
- 算子性能優化:在A100平臺上,RMSNorm算子經過CINN編譯優化后,運行速度提升了4倍。
- 模型性能提升:使用CINN編譯器后,超過60%的模型性能有顯著提升,平均提升達27.4%。
- 開發效率提升:CINN編譯器能夠自動優化算子組合,減少開發者手動調優的工作量,進一步提升開發效率。
1.5、異構多芯適配
在硬件適配方面,飛槳3.0通過多芯片統一適配方案,構建了“一次開發,全棧部署”的生態體系。
- 廣泛硬件支持:目前已適配超過60個芯片系列,覆蓋訓練集群、自動駕駛、智能終端等場景。
- 跨芯片遷移無縫銜接:開發者只需編寫一份代碼,即可讓程序在不同芯片上順暢運行,輕松實現業務的跨芯片遷移。
- 硬件生態擴展:飛槳3.0的硬件適配能力不僅降低了開發門檻,還為硬件廠商提供了更廣泛的生態支持,推動了AI技術的普及與應用。
二、基于飛槳框架3.0部署DeepSeek-R1-Distill-Qwen-1.5B
2.1、機器環境
本次實驗的機器是基于丹摩DAMODEL算力云平臺,機器的顯卡配置為Tesla-P40 24GB,CUDA12.4,這里沒有采用docker的方式進行部署,而是直接手動安裝飛槳框架3.0環境并寫腳本測試效果。
2.2、環境配置
首先進入服務器控制臺,使用pip 安裝3.0版本的paddlepaddle以及paddlenlp:
pip install --upgrade paddlenlp==3.0.0b4
python -m pip install paddlepaddle-gpu==3.0.0rc1 -i https://www.paddlepaddle.org.cn/packages/stable/cu123/ 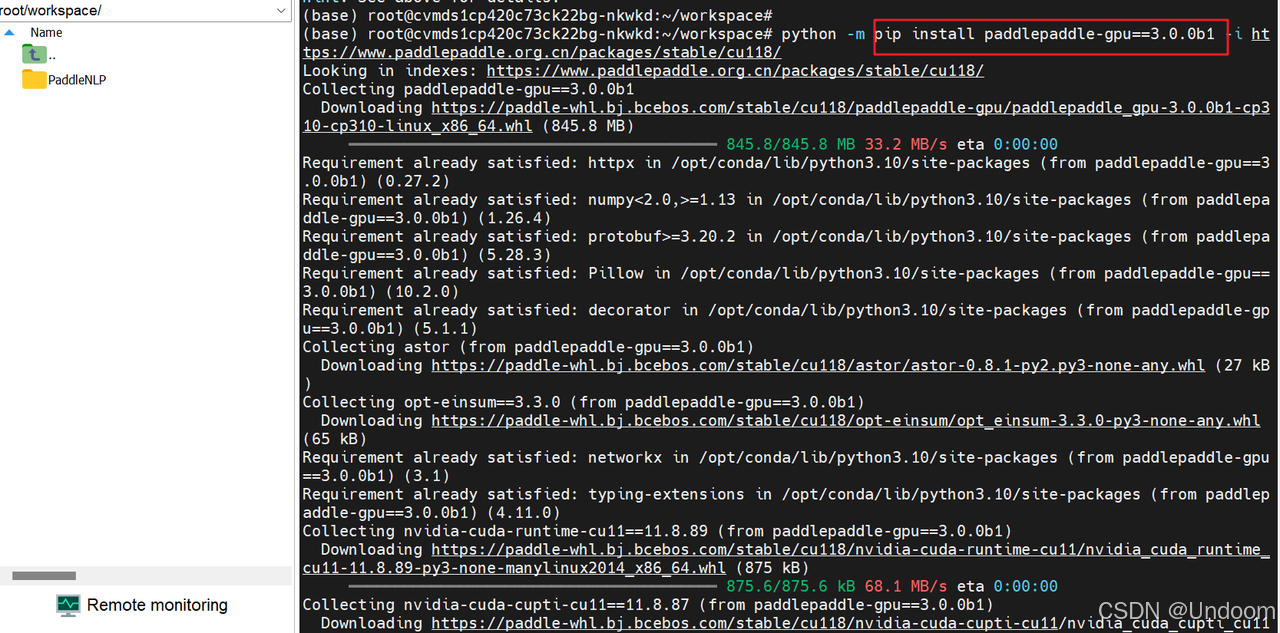
可以輸入以下代碼驗證是否安裝成功:
python -c "import paddle; paddle.utils.run_check()"
python -c "import paddle; print(paddle.__version__)"
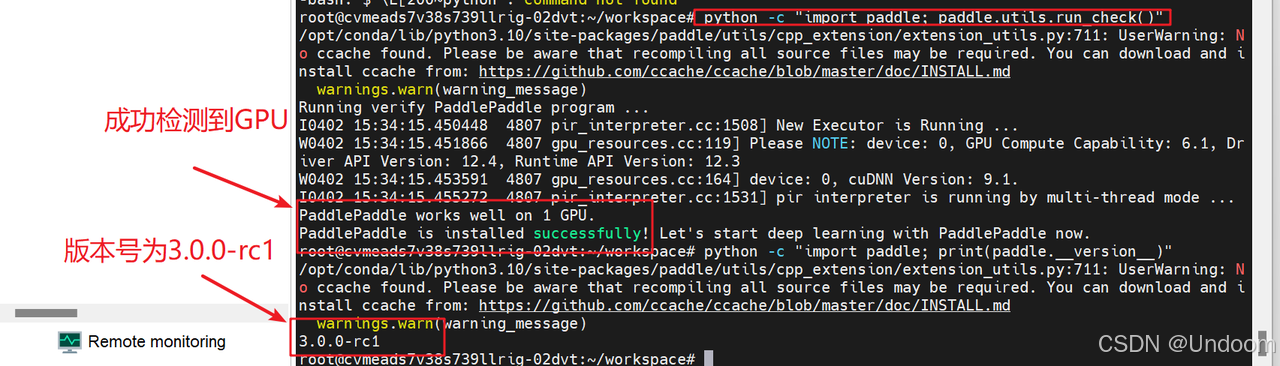
也可以輸入pip list在環境列表里檢查,是否安裝成功:
2.3、下載并測試模型
安裝好環境后,接下來就可以下載模型并進行相關測試了,這里我們以DeepSeek-R1-Distill-Qwen-1.5B為例子,并配置配置日志記錄系統,監控系統資源使用情況,包括獲取GPU顯存、CPU內存以及PaddlePaddle分配的顯存使用情況,完整代碼如下:
import os
import time
import json
import logging
import argparse
import inspect
import psutil
import subprocess
from typing import List, Dict, Any, Unionimport paddle
from paddlenlp.transformers import AutoTokenizer, AutoModelForCausalLMclass LoggingConfigurator:"""配置和管理日志記錄系統"""def __init__(self, log_directory: str = "/data/coding/"):self.log_dir = log_directoryself._ensure_log_directory()self._configure_loggers()def _ensure_log_directory(self):"""確保日志目錄存在"""if not os.path.exists(self.log_dir):os.makedirs(self.log_dir)def _configure_loggers(self):"""配置所有日志記錄器"""self._setup_server_logger()self._setup_infer_logger()self._setup_paddle_logger()def _setup_server_logger(self):"""配置服務器日志記錄器(JSON格式)"""logger = logging.getLogger('server')logger.setLevel(logging.INFO)formatter = logging.Formatter(json.dumps({'timestamp': '%(asctime)s','severity': '%(levelname)s','log_message': '%(message)s','source': '%(module)s','line_number': '%(lineno)d'}))handler = logging.FileHandler(os.path.join(self.log_dir, 'server.log'))handler.setFormatter(formatter)logger.addHandler(handler)def _setup_infer_logger(self):"""配置推理日志記錄器"""self._setup_basic_logger('infer', 'infer.log')def _setup_paddle_logger(self):"""配置Paddle日志記錄器"""self._setup_basic_logger('paddle', 'paddle.log')def _setup_basic_logger(self, name: str, filename: str):"""配置基本格式的日志記錄器"""logger = logging.getLogger(name)logger.setLevel(logging.INFO)formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')handler = logging.FileHandler(os.path.join(self.log_dir, filename))handler.setFormatter(formatter)logger.addHandler(handler)class SystemMonitor:"""監控系統資源使用情況"""@staticmethoddef get_gpu_memory_usage() -> Union[List[int], str]:"""獲取GPU顯存使用情況"""try:cmd_output = subprocess.check_output(["nvidia-smi", "--query-gpu=memory.used", "--format=csv,noheader"],encoding='utf-8')return [int(x.strip().split()[0]) for x in cmd_output.strip().split('\n')]except Exception as e:return f"Failed to get GPU memory: {e}"@staticmethoddef get_cpu_memory_usage() -> float:"""獲取CPU內存使用百分比"""return psutil.virtual_memory().percent@staticmethoddef get_paddle_memory_usage() -> int:"""獲取PaddlePaddle分配的顯存"""return paddle.device.cuda.memory_allocated()class PaddleInspector:"""檢查PaddlePaddle環境和配置"""@staticmethoddef get_build_config() -> Dict[str, Any]:"""獲取PaddlePaddle構建配置"""config = {}try:config['cuda_support'] = paddle.is_compiled_with_cuda()except AttributeError:config['cuda_support'] = "unknown"return config@staticmethoddef get_runtime_config() -> Dict[str, Any]:"""獲取PaddlePaddle運行時配置"""config = {}try:config['thread_count'] = paddle.device.get_device().split(":")[1]except (AttributeError, IndexError):config['thread_count'] = "unknown"try:config['cpu_affinity'] = paddle.get_device()except AttributeError:config['cpu_affinity'] = "unknown"return config@staticmethoddef inspect_optimizer(optimizer: Any) -> Dict[str, Any]:"""檢查優化器配置"""if optimizer is None:return {}config = {'type': type(optimizer).__name__}params = ['_learning_rate', '_beta1', '_beta2', '_epsilon', 'weight_decay']for param in params:if hasattr(optimizer, param):config[param.lstrip('_')] = getattr(optimizer, param)return configclass ModelInference:"""執行模型推理任務"""def __init__(self, model_name: str, cache_dir: str):self.model_name = model_nameself.cache_dir = cache_dirself.tokenizer = Noneself.model = Nonedef initialize(self):"""初始化模型和tokenizer"""self.tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path=self.model_name,cache_dir=self.cache_dir)self.model = AutoModelForCausalLM.from_pretrained(pretrained_model_name_or_path=self.model_name,cache_dir=self.cache_dir,dtype="float16")def generate_text(self, input_text: str, enable_profiling: bool = False) -> Dict[str, Any]:"""生成文本響應"""inputs = self.tokenizer(input_text, return_tensors="pd")start_time = time.time()if enable_profiling:return self._profile_generation(inputs, start_time)else:return self._basic_generation(inputs, start_time)def _basic_generation(self, inputs, start_time: float) -> Dict[str, Any]:"""執行基本生成(無性能分析)"""with paddle.no_grad():outputs = self.model.generate(**inputs,max_new_tokens=200,decode_strategy="sampling",temperature=0.2,top_k=20,top_p=0.9,repetition_penalty=1.1,)return self._prepare_results(inputs, outputs, start_time)def _profile_generation(self, inputs, start_time: float) -> Dict[str, Any]:"""執行帶性能分析的生成"""api_stats = {'count': {}, 'time': {}}def wrap_api_call(func):def wrapped(*args, **kwargs):name = func.__qualname__api_stats['count'][name] = api_stats['count'].get(name, 0) + 1call_start = time.time()result = func(*args, **kwargs)api_stats['time'][name] = api_stats['time'].get(name, 0) + (time.time() - call_start)return resultreturn wrapped# 應用API包裝器for _, func in inspect.getmembers(paddle, inspect.isfunction):setattr(paddle, func.__name__, wrap_api_call(func))profiler_path = os.path.join(LoggingConfigurator().log_dir, "profiler_report.json")with paddle.profiler.Profiler(targets=["cpu", "gpu"]) as prof:with paddle.no_grad():outputs = self.model.generate(**inputs,max_new_tokens=400,decode_strategy="sampling",temperature=0.2,top_k=20,top_p=0.9,repetition_penalty=1.1,)prof.export(profiler_path)results = self._prepare_results(inputs, outputs, start_time)results['api_stats'] = api_statsreturn resultsdef _prepare_results(self, inputs, outputs, start_time: float) -> Dict[str, Any]:"""準備結果字典"""end_time = time.time()output_ids = [int(i) for i in self._flatten_list(outputs[0].numpy().tolist())]return {'input_text': inputs,'output_text': self.tokenizer.decode(output_ids, skip_special_tokens=True),'input_tokens': len(inputs["input_ids"][0]),'output_tokens': len(output_ids),'inference_time': end_time - start_time,'start_time': start_time,'end_time': end_time}@staticmethoddef _flatten_list(nested_list: List) -> List:"""展平嵌套列表"""flat = []for item in nested_list:if isinstance(item, list):flat.extend(ModelInference._flatten_list(item))else:flat.append(item)return flatdef main():"""主執行函數"""parser = argparse.ArgumentParser(description="運行模型推理任務")parser.add_argument("--disable_profiling", action="store_true", help="禁用性能分析")args = parser.parse_args()# 初始化日志系統LoggingConfigurator()server_log = logging.getLogger('server')infer_log = logging.getLogger('infer')paddle_log = logging.getLogger('paddle')try:server_log.info(json.dumps({'event': 'server_start', 'details': {'port': 8080}}))# 記錄PaddlePaddle信息paddle_log.info(f"PaddlePaddle版本: {paddle.__version__}")paddle_log.info(f"構建配置: {PaddleInspector.get_build_config()}")paddle_log.info(f"運行時配置: {PaddleInspector.get_runtime_config()}")# 初始化模型model = ModelInference(model_name="deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",cache_dir="/data/coding/paddlenlp_models")model.initialize()# 記錄優化器信息optimizer = paddle.optimizer.Adam(learning_rate=1e-5, parameters=model.model.parameters())paddle_log.info(f"優化器配置: {PaddleInspector.inspect_optimizer(optimizer)}")# 執行推理input_query = "寫一個快速排序代碼"results = model.generate_text(input_query, enable_profiling=not args.disable_profiling)# 記錄性能指標tokens_per_sec = (results['input_tokens'] + results['output_tokens']) / results['inference_time']infer_log.info(f"輸入文本長度: {results['input_tokens']} tokens")infer_log.info(f"輸入內容: {input_query}")infer_log.info(f"輸出結果: {results['output_text']}")infer_log.info(f"推理耗時: {results['inference_time']:.2f}秒")infer_log.info(f"GPU顯存使用: {SystemMonitor.get_gpu_memory_usage()}")infer_log.info(f"CPU內存使用: {SystemMonitor.get_cpu_memory_usage()}%")infer_log.info(f"Token處理速度: {tokens_per_sec:.2f} tokens/秒")# 記錄Paddle內存使用paddle_log.info(f"Paddle顯存分配: {SystemMonitor.get_paddle_memory_usage()}")# 如果有API統計信息,記錄下來if 'api_stats' in results:paddle_log.info(f"API調用統計 - 次數: {results['api_stats']['count']}")paddle_log.info(f"API調用統計 - 耗時: {results['api_stats']['time']}")except Exception as e:infer_log.exception("推理過程中發生錯誤")server_log.error(json.dumps({'event': 'server_error','error': str(e),'stack_trace': True}), exc_info=True)finally:server_log.info(json.dumps({'event': 'server_shutdown', 'exit_status': 0}))if __name__ == "__main__":main()
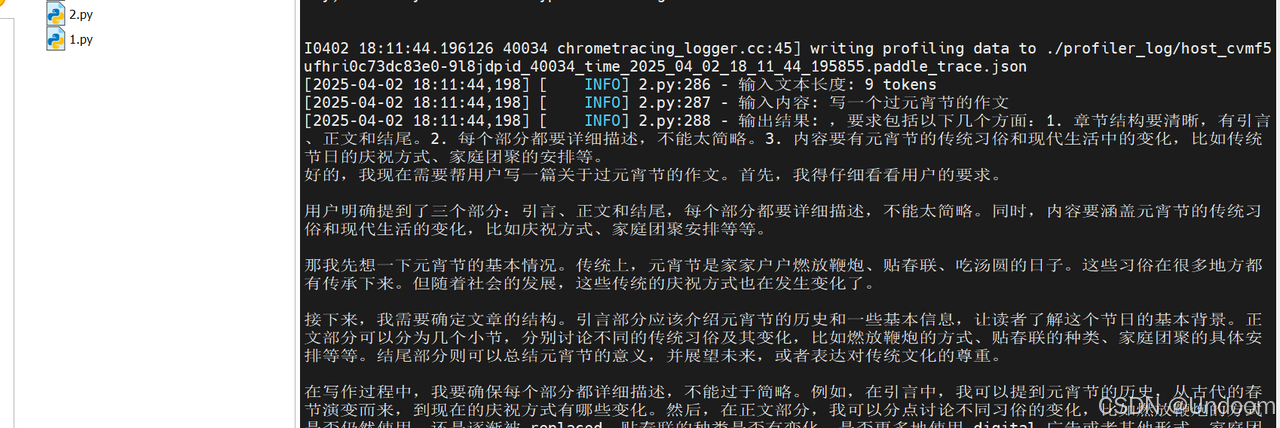
測試結果如下:
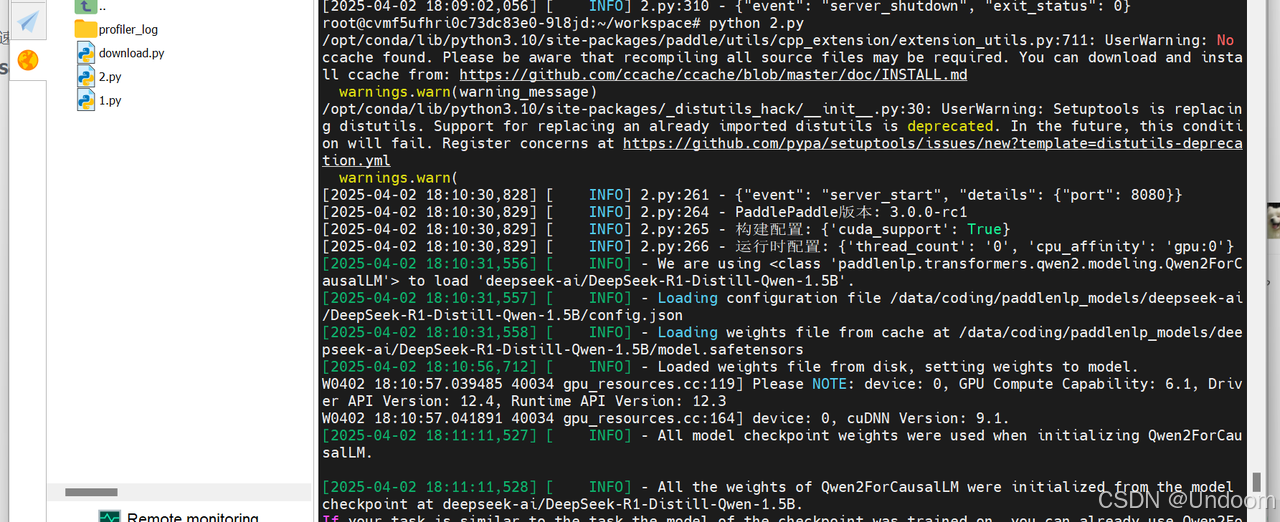
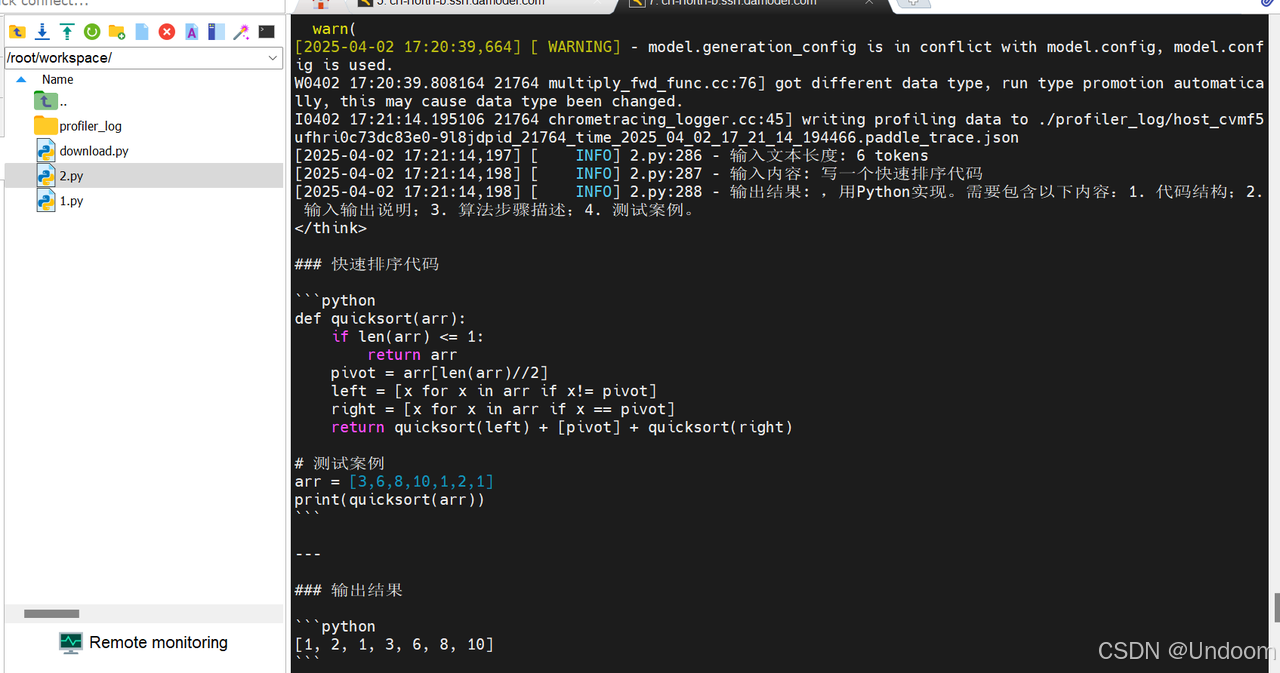
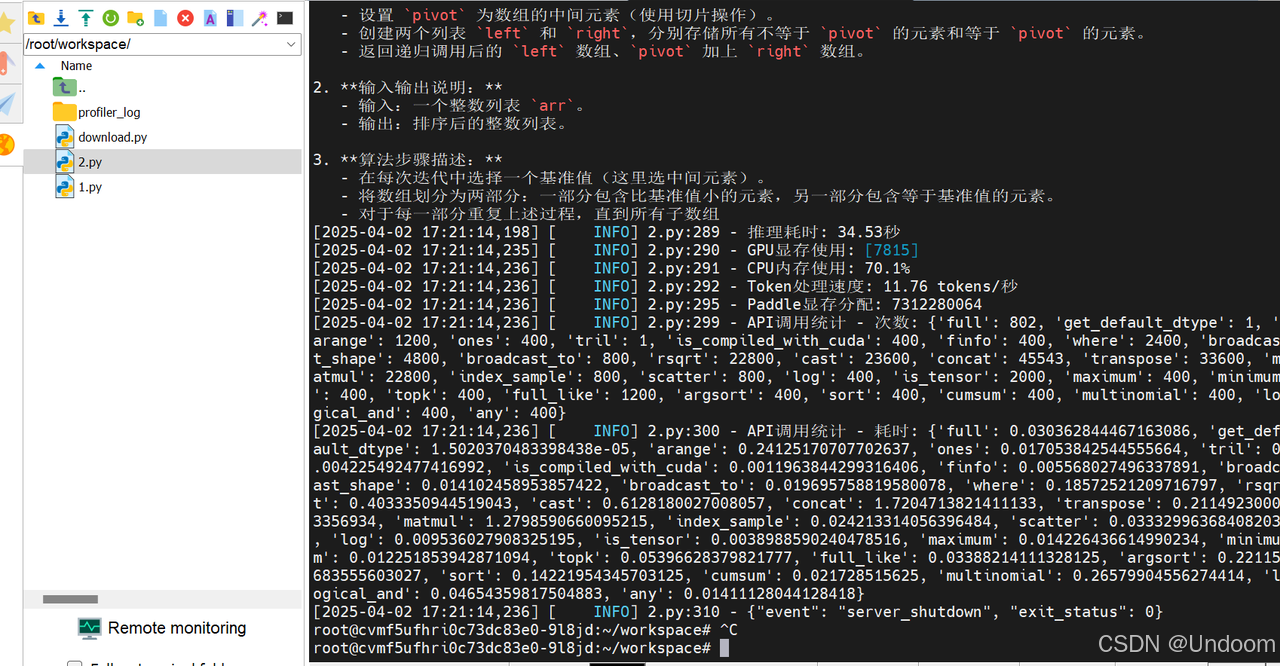
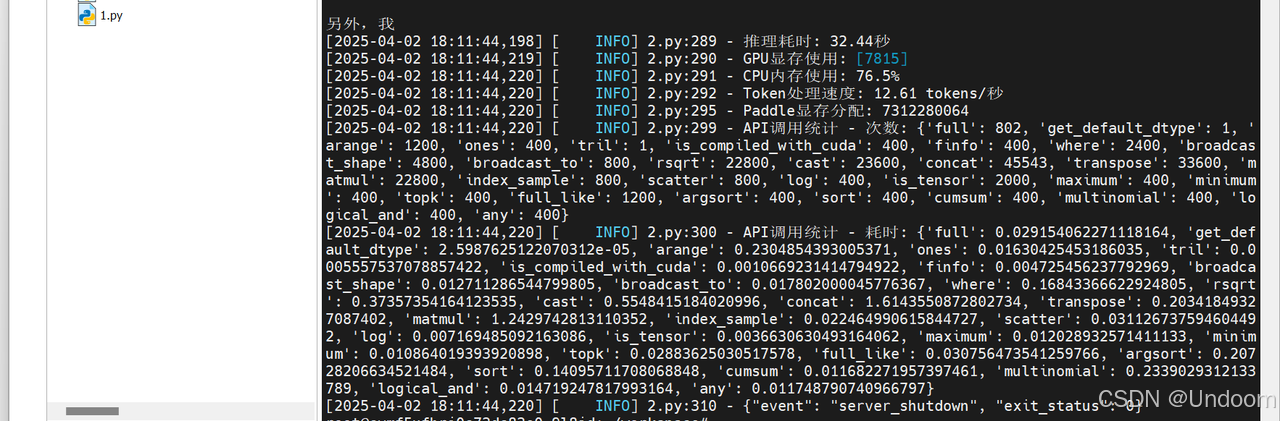
結果顯示,資源管理方面,本次推理耗時為34.53秒,Token處理速度為11.76 tokens/秒,GPU顯存使用為7815MB,日志中顯存的分配表明成功啟用了float16精度,CPU內存使用率為70.1%。
在技術特性方面,日志中的API調用統計揭示了飛槳3.0的核心優化,框架對高頻操作進行了深度優化,matmul(矩陣乘法)和concat(張量拼接)等關鍵操作分別以22800次調用耗時1.28秒和45543次調用耗時1.72秒的表現,展現了底層算子庫的計算效率。
這里還測試了一些其他的結果,基本上都維持在12tokens/秒: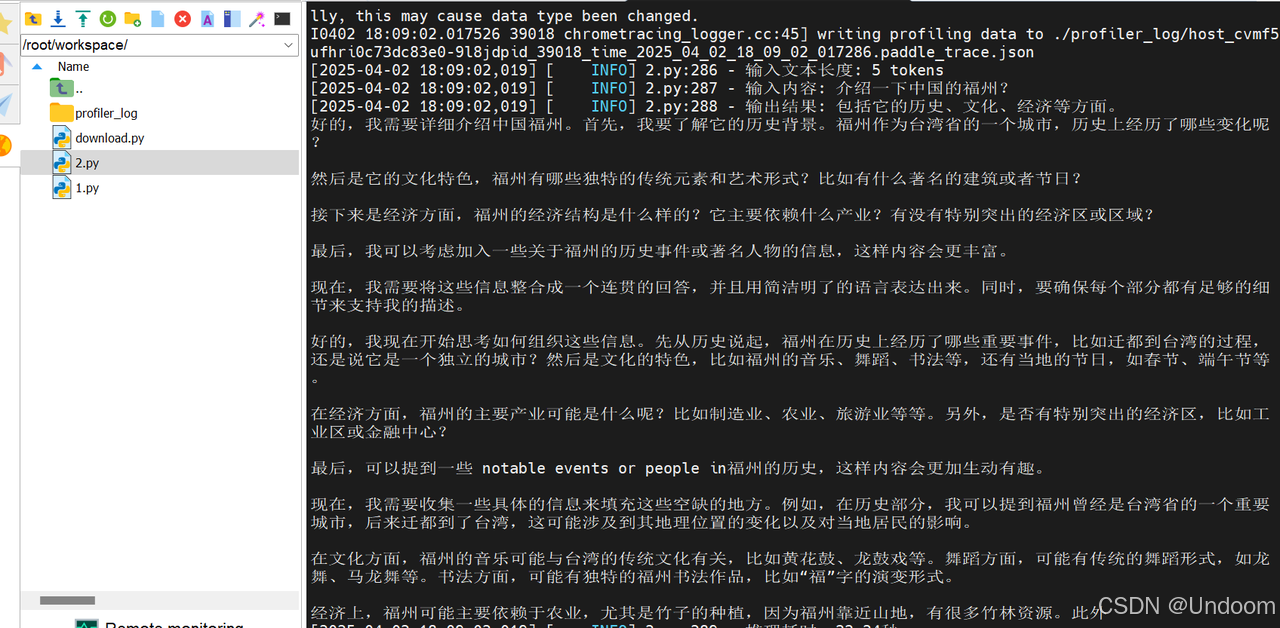
三、部署實戰體驗總結
飛槳3.0的架構革新與本地部署實戰,不僅驗證了國產深度學習框架在大模型時代的技術競爭力,更揭示了其在產業落地中的獨特價值。結合本次DeepSeek-R1蒸餾版的部署經驗,可以看到,飛槳3.0很大程度上解決了傳統框架在動態圖靈活性與靜態圖性能間的矛盾。在DeepSeek-R1部署中,FP8-WINT4混合量化將顯存占用壓縮至原模型的30%,而MLA算子的多級流水線設計也使得長序列推理的吞吐量大大提升。這種“精度-效率-顯存”三重平衡的優化范式,為邊緣設備部署百億級模型提供了可能。
以本次部署實踐的算力和人力成本為例,飛槳3.0將大模型從實驗室推向產業應用的鏈條大幅縮短:
算力成本:飛槳3.0通過INT8量化與MTP投機解碼,很大程度降低了單機推理的Token生成成本;
人力成本:自動并行技術減少手工調參工作量,模型遷移至不同硬件的適配時間從周級縮短至小時級;
展望未來,可以預見的是隨著飛槳3.0生態的持續完善,其技術價值將進一步釋放。
總結來說,飛槳3.0不僅是一個框架升級,更是國產AI基礎設施的一次范式躍遷。從本次DeepSeek-R1的部署實踐中可以看到,其技術特性已從“可用”邁向“好用”,而產業價值的核心在于降低創新門檻、激活長尾需求。對于開發者而言,擁抱飛槳3.0即意味著獲得“一把打開大模型時代的萬能鑰匙”——既能應對前沿研究的高性能需求,也能滿足產業落地的低成本約束。

)


)




![[C語言入門] 結構體](http://pic.xiahunao.cn/[C語言入門] 結構體)




★★★★★)



在SPP中互操作性深度解析)
