#AI夏令營 #Datawhale #夏令營
賽題
一句話介紹賽題任務可以這樣理解賽題:
【訓練時序預測模型助力電力需求預測】
電力需求的準確預測對于電網的穩定運行、能源的有效管理以及可再生能源的整合至關重要。
賽題任務
給定多個房屋對應電力消耗歷史 N 天的相關序列數據等信息,預測房屋對應電力的消耗。
賽題數據簡介
賽題數據由訓練集和測試集組成,為了保證比賽的公平性,將每日日期進行脫敏,用 1-N 進行標識。
即 1 為數據集最近一天,其中 1-10 為測試集數據。
數據集由字段 id(房屋 id)、 dt(日標識)、type(房屋類型)、target(實際電力消耗)組成。
下面進入 baseline 代碼
# 1. 導入需要用到的相關庫
# 導入 pandas 庫,用于數據處理和分析
import pandas as pd
# 導入 numpy 庫,用于科學計算和多維數組操作
import numpy as np# 2. 讀取訓練集和測試集
# 使用 read_csv() 函數從文件中讀取訓練集數據,文件名為 'train.csv'
train = pd.read_csv('./data/data283931/train.csv')
# 使用 read_csv() 函數從文件中讀取測試集數據,文件名為 'train.csv'
test = pd.read_csv('./data/data283931/test.csv')# 3. 計算訓練數據最近11-20單位時間內對應id的目標均值
target_mean = train[train['dt']<=20].groupby(['id'])['target'].mean().reset_index()# 4. 將target_mean作為測試集結果進行合并
test = test.merge(target_mean, on=['id'], how='left')# 5. 保存結果文件到本地
test[['id','dt','target']].to_csv('submit.csv', index=None)Step1:報名賽事!(點擊即可跳轉)
賽事鏈接:2024 iFLYTEK AI開發者大賽-訊飛開放平臺2024 iFLYTEK AI開發者大賽-訊飛開放平臺
https://challenge.xfyun.cn/h5/detail?type=electricity-demand&ch=dw24_uGS8Gs
Step2:5 分鐘體驗一站式 baseline!(點擊即可跳轉)
項目鏈接:從零入門機器學習競賽-Baseline - 飛槳AI Studio星河社區- 飛槳AI Studio星河社區![]() https://aistudio.baidu.com/projectdetail/8151133
https://aistudio.baidu.com/projectdetail/8151133
跑通baseline
根據task1跑通baseline
注冊賬號
直接注冊或登錄百度賬號,etc
fork 項目
從零入門機器學習競賽-Baseline - 飛槳AI Studio星河社區- 飛槳AI Studio星河社區![]() https://aistudio.baidu.com/projectdetail/8151133
https://aistudio.baidu.com/projectdetail/8151133
啟動項目?
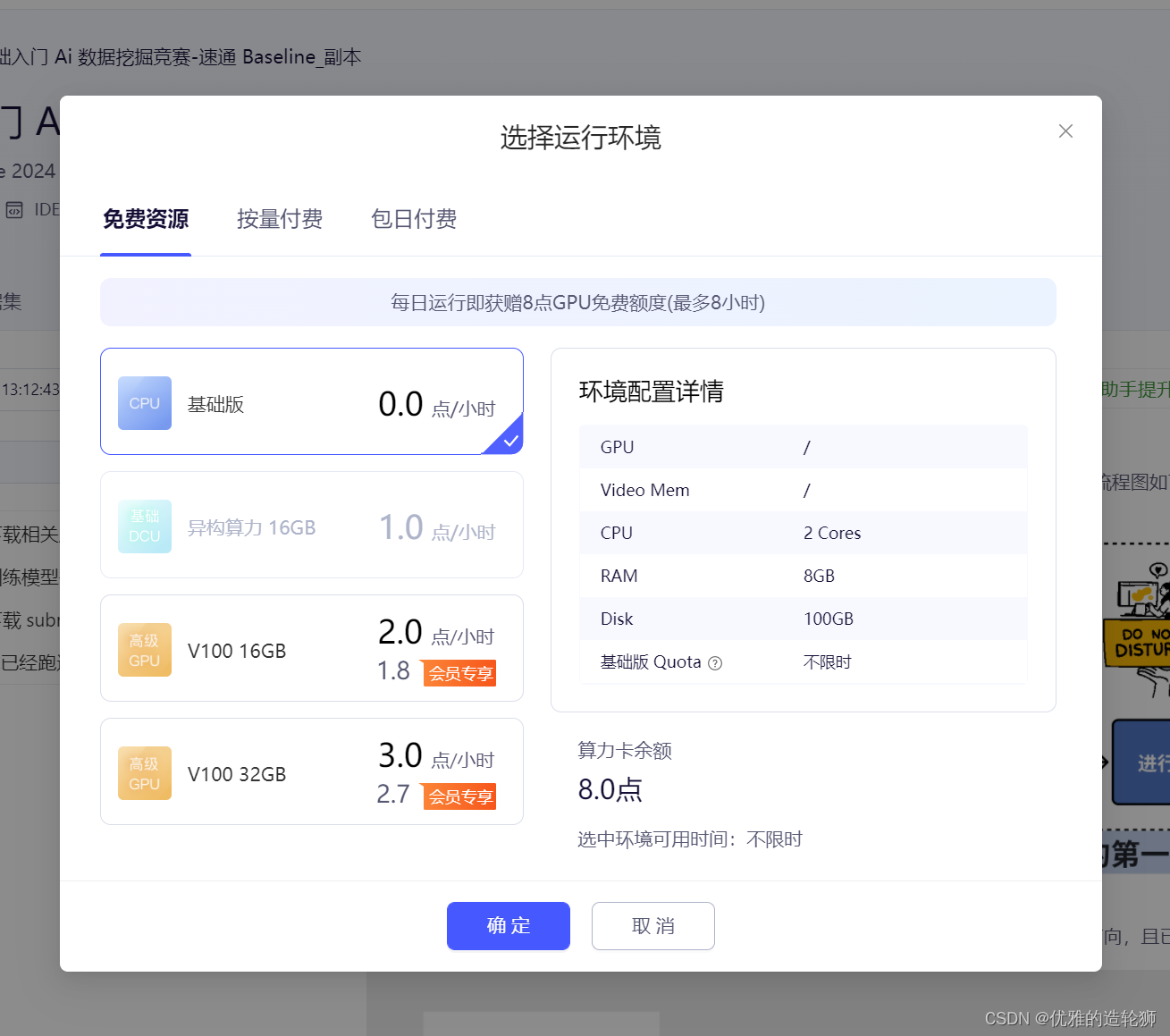
 選擇運行環境,并點擊確定,沒有特殊要求就默認的基礎版就可以了
選擇運行環境,并點擊確定,沒有特殊要求就默認的基礎版就可以了
等待片刻,等待在線項目啟動
 運行項目代碼
運行項目代碼

點擊 運行全部Cell

程序運行完生成文件 submit.csv

這個文件就最終提交的文件。
提交并獲取分數
| 1 | 返回分數 | 373.89846 | submit.csv | baseline | 1gszwJaV | 2024-07-11 16:57:27 |
知識點:
常見的時間序列場景有:
金融領域:股票價格預測、利率變動、匯率預測等。
氣象領域:溫度、降水量、風速等氣候指標的預測。
銷售預測:產品或服務的未來銷售額預測。
庫存管理:預測庫存需求,優化庫存水平。
能源領域:電力需求預測、石油價格預測等。
醫療領域:疾病爆發趨勢預測、醫療資源需求預測。
時間序列問題的數據往往有如下特點:
時間依賴性:數據點之間存在時間上的連續性和依賴性。
非平穩性:數據的統計特性(如均值、方差)隨時間變化。
季節性:數據表現出周期性的模式,如年度、月度或周度。
趨勢:數據隨時間推移呈現長期上升或下降的趨勢。
周期性:數據可能存在非固定周期的波動。
隨機波動:數據可能受到隨機事件的影響,表現出不確定性。
時間序列分析在很多領域中具有重要的應用價值。通過對時間序列數據的分析和建模,可以得到對未來趨勢的預測和預測誤差的估計,為決策提供依據。
時間序列預測問題可以通過多種建模方法來解決,包括傳統的時間序列模型、機器學習模型和深度學習模型。
傳統時間序列模型
用于分析和預測時間序列數據的統計模型。
它假設數據點之間存在一定的時間關系,即后一個數據點的值可以根據前一個數據點的值和其他相關因素預測得出。
常見的時間序列模型包括
- AR模型(自回歸模型)
- MA模型(滑動平均模型)
- ARMA模型(自回歸滑動平均模型)
- ARIMA模型(差分自回歸滑動平均模型)
- SARIMA模型(季節性差分自回歸滑動平均模型)等。
這些模型基于不同的假設和參數設置,可以根據數據的特點選擇合適的模型進行建模和預測。
時間序列模型可以用于不同領域的數據分析和預測,如經濟學中的金融時間序列分析、氣象學中的氣象預測、生態學中的生態系統變化預測等。它們可以幫助我們理解數據的時間規律,發現趨勢和周期性變化,以及預測未來的走勢。
機器學習模型
在時間序列預測中,機器學習模型可以通過將時間序列數據轉化為特征和目標變量的組合來進行建模和預測。
以下是一些常用的機器學習時間序列模型:
- 自回歸模型(AR):自回歸模型基于時間序列數據的歷史值來預測未來值。AR模型假設未來值與過去的若干個值有線性相關性。
- 移動平均模型(MA):移動平均模型基于時間序列數據的過去誤差來預測未來值。MA模型假設未來值與過去的若干個誤差有相關性。
- 自回歸移動平均模型(ARMA):ARMA模型是AR模型和MA模型的組合。它結合了過去的時間序列值和誤差來進行預測。
- 差分自回歸移動平均模型(ARIMA):ARIMA模型在ARMA模型的基礎上增加了對時間序列數據進行差分的步驟,用于處理非平穩數據。
- 季節性ARIMA模型(SARIMA):SARIMA模型是ARIMA模型在考慮季節性因素的基礎上進行建模的一種擴展模型。
- 支持向量機(SVM):支持向量機是一種常用的機器學習模型,在時間序列預測中可以用于線性回歸、非線性回歸和分類問題。
- 隨機森林(Random Forest):隨機森林是一種集成學習模型,通過多個決策樹的組合來進行預測。在時間序列預測中,可以利用隨機森林進行回歸和分類問題的預測
深度學習模型
深度學習模型在時間序列預測問題上表現出色,尤其是在處理大規模數據和復雜模式時。
以下是一些常用的深度學習時間序列模型:
- 循環神經網絡(RNN):RNN是一種能夠處理序列數據的神經網絡。它具有記憶能力,可以在處理每個時間步時將之前的信息傳遞給下一個時間步,從而捕捉到時間序列的依賴關系。
- 長短期記憶網絡(LSTM):LSTM是一種RNN的變體,通過引入“門控”機制來解決傳統RNN中的梯度消失和梯度爆炸問題。LSTM對于長期依賴關系的建模能力更強,適用于處理長時間序列數據。
- 門控循環單元(GRU):GRU也是一種RNN的變體,類似于LSTM,它通過引入“門控”機制來記憶和更新信息。GRU相對于LSTM具有更簡單的結構,參數量更小,計算效率更高。
- 卷積神經網絡(CNN):CNN在處理時間序列數據時常用于提取局部特征。通過卷積和池化操作,CNN可以捕捉時間序列中的局部模式,并提取有用的特征,用于預測未來值或分類問題。
- 注意力機制(Attention):注意力機制在深度學習中很有用,尤其是在處理長時間序列數據時。它可以將模型的注意力集中在序列中最重要的部分,提高預測的準確性。
這些深度學習時間序列模型具有強大的建模能力,能夠處理復雜的時間序列數據,但同時也需要大量的訓練數據和計算資源。
各種模型之間的對比
| 模型類型 | 特點 | 適用場景 |
|---|---|---|
| 傳統時間序列模型 | 基于統計分析的方法,對時間序列數據的基本特性進行建模,如自相關性、季節性等 | 非常適合處理具有明顯的趨勢和季節性的數據。 對于相對簡單的時間序列數據,建模和預測效果較好。 例如AR、MA、ARIMA、SARIMA模型 |
| 機器學習模型 | 基于機器學習算法,通過對時間序列數據的樣本特征進行訓練建模,學習數據的模式和規律 | 適用于數據較為復雜、特征較多的時間序列問題。 需要手動提取和選擇合適的特征。 常用的機器學習模型包括線性回歸、決策樹、隨機森林、支持向量機等 |
| 深度學習模型 | 基于神經網絡的模型,通過多層次的神經網絡結構進行特征提取和模式學習 | 適用于大規模數據、復雜特征的時間序列預測問題。 自動學習數據中的特征和模式,無需手動提取。 常見的深度學習模型包括循環神經網絡(RNN)、長短時記憶網絡(LSTM)、卷積神經網絡(CNN)等 |
- 如果數據具有明顯的趨勢和季節性,且相對簡單,可以使用傳統時間序列模型進行建模和預測。
- 如果數據較為復雜,特征較多,可以考慮使用機器學習模型進行建模。
- 對于大規模數據、復雜特征和自動學習特征的需求,可以考慮使用深度學習模型。
)

)

Broker存儲Message流程解析)






![[手機Linux PostmarketOS]三, Alpine Linux命令使用](http://pic.xiahunao.cn/[手機Linux PostmarketOS]三, Alpine Linux命令使用)







