文末有福利!
一、新算效——重塑計算架構
1.1 下一代 AI 芯片設計思路
以 GPU 為 代 表 的 高 性 能 并 行 計 算 芯 片 架 構 和 以 針 對 AI 領 域 專 用 加 速(DSA, Domain Specific Architecture,DSA)為代表的芯片架構是目前兩大主流 AI 芯片設計思路。GPU 設
計初衷是為了接替 CPU 進行圖形渲染,圖形處理涉及到相當多的重復計算量,因此 GPU 芯片上排布了數以千計的,專為同時處理多重任務而設計的小計算核心。隨著 AI 深度學習算法的逐漸成熟,GPU 芯片開始引入 AI Core/Tensor Core 等電路來實現矩陣乘運算的加速。
因此,GPU 比 CPU 擁有更強的大規模并行計算和浮點運算能力。不同于 GPU,AI DSA 芯片是一種針對神經網絡計算的專用處理器,主要功能是加速神經網絡的數據處理、傳遞和反向傳播等操作,因
1.2 存算一體構建新型計算范式
存算一體作為新型計算范式,基于在存儲原位實現計算的本質,打破了馮諾依曼存算分離架構,避免了頻繁的數據訪問和搬運帶來的功耗激增的問題,大大緩解了 AI 芯片性能提升的瓶頸。
同時,由于新型智算中心承載的 CNN、Transformer 等主流模型架構,矩陣乘加運算占據了大量算力(Transformer 中 45-60%,CNN 中 90% 以上的運算均為矩陣乘加),存算一體的架構成為高效完成矩陣乘加的重要選擇。
存算一體可通過 RRAM、SRAM、MRAM、Nor Flash 等介質實現,多介質共存可以發揮不同介質在成熟度、讀寫次數等方面的優勢 。
存算一體通過模擬計算或數字計算或二者相結合的方式提供存算能力,如圖 3-13 所示:
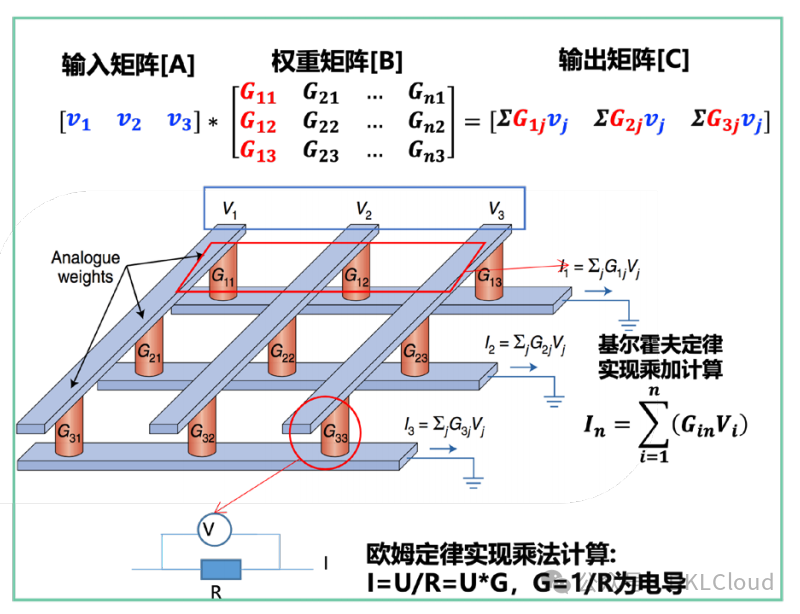
a) 模擬存算一體


b) 數字存算一體
圖 3-13 模擬和數字存算一體
存算一體在 NICC 的主要應用是大模型推理。考慮到不同的模型結構,存算一體充分利用非規則稀疏性,以達到與存算陣列的最佳適配,并實現能效最大化。以復旦大學 ISSCC 2023發布的論文為例 ,其應用了基于蝶形數據分配網絡的稀疏前饋計算架構(如圖 3-14),結合對應的存內陣列設計和電路實現,能夠在 28nm 工藝下,達到現有 Transformer 加速器 3.2 倍至 9.7 倍的能效。
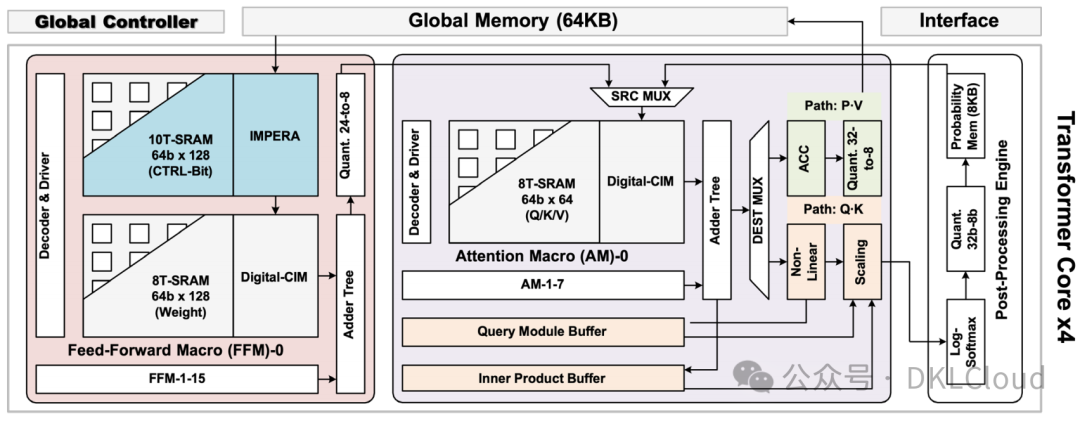
圖 3-14 Transformer 加速器的存算一體實現示意
當前,面向智算中心多核、多芯片的存算一體架構方案將成為未來存算一體研究和商用落地的重點方向。在此場景下,有以下三點問題需重點解決:
-
如何與算法結構協同:通過改進的存算一體陣列架構更好的適配稀疏 Transformer,使用分塊結構化稀疏、動態激活值稀疏以及特定 Transformer 稀疏等方式,選擇參與計算的存算單元,并結合定制的加法樹電路減小面積,提升計算能效,從而提升推理效率。
-
如何與精度需求協同:通過可變精度存算一體陣列架構更好適配大模型推理的精度需求,使用數字存內計算和模擬存內計算混合、雙生多 bit 等方法,實現 INT8 和 BF16 等混合精度計算。
3)如何與封裝能力協同:通過 Chiplet 技術同時滿足存算一體專用高性能、通用可擴展要求,提升算力和 IO 帶寬,減少訪存瓶頸;通過 3D 堆疊等封裝技術將存內計算(CIM)與近存(PNM)和存內處理(PIM)技術結合,為訪存密集型應用提供大容量高帶寬的計算能力。
現階段的存算一體芯片在介質優化、集成規模、工具鏈支持、算法適配、產業生態等方面還面臨諸多挑戰,導致應用普及較慢,建議錨定智算核心應用,推出樣板產品,突破上述關鍵挑戰,在成熟工藝實現性能反超。
1.3 DPU 實現計算、存儲和網絡的深度協同
DPU 作為 CPU、GPU 之后的數據中心第三顆大芯片,本質是圍繞數據處理提供網絡、存儲、安全、管理等基礎設施虛擬化能力的專用處理器。面對智算業務場景,中大規模模型訓練和推理任務對網絡和存儲 I/O 的時延提出了更極致的性能需求,DPU 可在智算領域解決三大關鍵問題,與計算、網絡、存儲深度協同,助力算效提升。
-
統一云化管理:智算服務場景存在裸金屬、容器、 虛機多種方式部署需求,如何實現 AI節點并池管理提高計算資源利用效率,成為關鍵的業務痛點,DPU 是最佳的解決方案。通過 DPU 可提供計算資源快速發放和回收等底層支撐能力,使彈性裸金屬特性和虛機一致,支持云盤啟動,完成靈活的存儲分配,實現存儲多租戶隔離并縮短容災時間,交付效率提高10 倍。
-
高性能存儲卸載及加速:大模型訓練推理業務的模型本身以及訓推所需的數據需要 PB 級儲存,本地存儲性價比低,遠端存儲集群成為最優選擇。分布式存儲設備面對上千計算節點,需要滿足多用戶并行使用時產生的海量數據讀取及加速數據收斂需求,單節點存儲帶寬疊加后對存儲系統提出更高的性能要求。DPU 產品可以提供專用的高速存儲單元來處理和管理大量的數據,提供高帶寬和低延遲的存儲訪問,實現 NVMe-OF 存儲加速,同時可配合訓練框架進行文件系統卸載,實現訓練數據格式統一化,實現不同來源的數據接入,進一步加速訓練和推理過程。
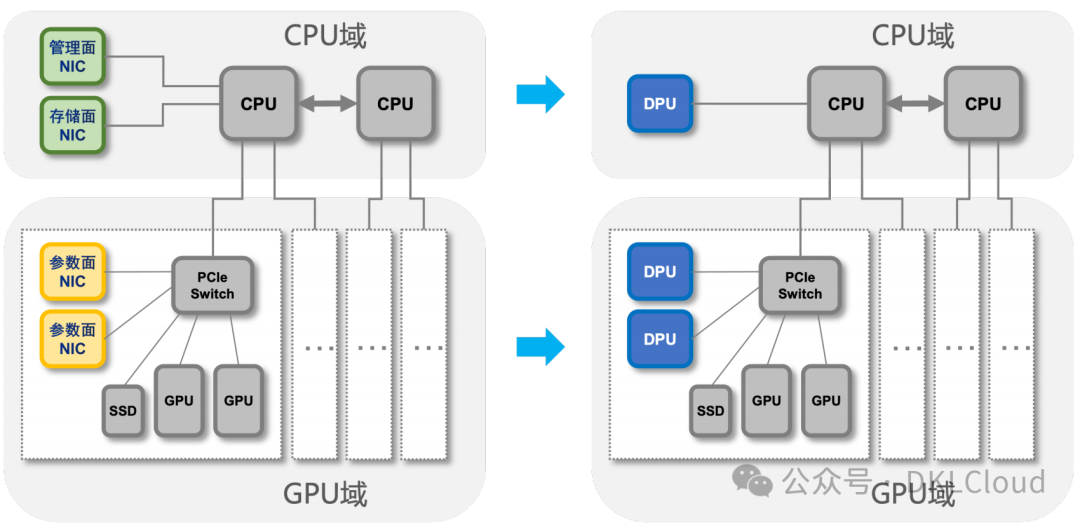
圖 3-15 智算中心引入 DPU 兩種模式
面對 DPU 在智算場景的試驗試點及規模應用,當前仍面臨三大核心挑戰:
在云平臺側,DPU 軟硬融合層的標準化是制約 DPU 通用化的主要問題。DPU 本質是云化、虛擬化技術從軟件實現向軟硬結合發展的結果,技術架構與云計算關系密切,存在耦合,DPU 虛擬化技術棧在技術迭代中差異化發展,不同產品的同一技術的實現路徑多樣,軟件實現方式差異大。亟需解決業界異廠家 DPU 與云平臺軟件定向開發適配成本高的問題。建議圍繞管理、網絡、存儲、計算、安全五大軟件系統,推動 DPU 軟件功能要求和交互接口標準化,并分階段推進。
在網絡側,網絡技術創新需要與 DPU 深度協同。智算業務要求零丟包、低時延、高吞吐的網絡能力,RDMA 網絡是智算中心高性能網絡的首選,頭部企業紛紛布局自研 RDMA 協議棧及無損網絡相關技術。DPU 作為服務器的 IO 出入口,是網絡與存儲必經之路,網絡技術創新需要與 DPU 深度協同,實現算力無損,助力算效提升。
在硬件側,亟需優先引導服務器整機層及 DPU 部件層標準化及通用化。重點圍繞服務器結構及供電、散熱、帶外納管方案、上下電策略四大方向進行統一,為 DPU 與上層軟件的深度整合及生態繁榮提供底層支撐。
二、新存儲——挖掘數據價值
2.1 計算與存儲的交互過程
大模型訓練是一項復雜而耗時的任務,類似 GPT-3 級別的模型訓練數據集通常很大,無法完全加載到內存中,需要分批次的從外部分布式存儲中讀取數據并加載到 GPU 的 HBM 上。
如圖 3-16 所示,從用戶上傳原始數據集到最終完成模型訓練,并對用戶提供已訓練模型結果,整個過程存在著計算與存儲系統密切的數據交互。
1)數據上傳:大模型預訓練階段首先需要獲取訓練數據集,這些來自互聯網、書籍、論文的數據需要進行預處理和清洗,包括分詞、去除噪聲和非常見詞匯,以確保訓練數據是高質量且可靠的。數據集準備好之后上傳到存儲系統中。由于對象存儲具有普遍的 API 支持,可以提供靈活的數據訪問方式,數據集通常會上傳到對象存儲中。大模型訓練的數據集可達TB 量級,且主要以大文件大 IO 寫入為主,存儲系統需要保證足夠和穩定的吞吐性能。
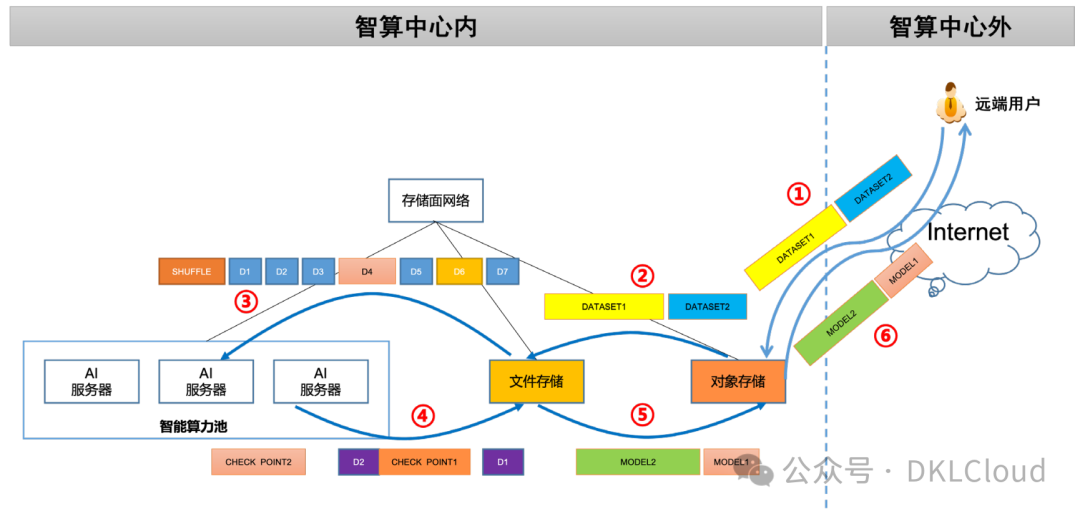
圖 3-16 大模型訓練計算與存儲的交互過程
2)數據轉移:由于文件存儲具有更高的 IO 性能,對于小文件和隨機 IO 有較好的支持,且與 TensorFlow、PyTorch 等訓練框架的兼容性更好,適合在訓練過程中進行高效的讀取和寫入操作,因此在模型訓練開始之前,需要把數據集從對象存儲復制到文件存儲中,這個過程中,IO 類型以大文件大 IO 順序讀寫為主。
3)數據讀取:數據集放入文件存儲后,還需要進行進一步預處理。CV 類數據集通常需要先對圖片序列化并添加類別標簽、圖像尺寸等元數據,自然語音類數據集則需要對語音文件進行切分,轉換為訓練框架實現代碼期望的采樣率和格式,例如 16K 采樣 wav 格式。數據集準備就緒后,模型將基于隨機初始化的權重啟動訓練。整個數據集會被隨機打散,稱之為shuffle,然后數據被分成多個小的批次(batch),后續計算節點將以批次為單位從文件存儲系統讀取數據,并緩存到 GPU 的 HBM 中。
4)歸檔寫回:由于 HBM 是易失性存儲,一旦在訓練過程中發生意外中斷,訓練數據將全部丟失,因此基于 Checkpoint 的“斷點續訓”機制非常關鍵,我們需要將模型訓練過程中的數據周期性地保存到外部持久性存儲中,一旦發生中斷可以從最后一次保存的參數處重新開始訓練,從而節省大量的時間和經濟成本。此外,文件存儲還用于跟蹤記錄模型訓練過程中的各種指標,包括損失函數的變化、準確率的提升等,以便后續支持可視化的模型訓練策略優化分析。保存 checkpoint 和過程文件等操作,主要負載是大文件大 IO 寫操作,對文件存儲壓力不大。
5)模型復制:模型訓練完成后,最終的模型權重會被寫入到文件存儲中保存,用于模型推理或者以 MaaS 的服務模式給外部用戶使用。由于對象存儲便于對外共享,模型需要從文件存儲復制到對象存儲上,這個環節 IO 類型以寫入大文件為主。
6)模型下載:用戶基于自身應用特點,從對象存儲下載訓練好的模型。
那么,如何系統的去學習大模型LLM?
我在一線互聯網企業工作十余年里,指導過不少同行后輩。幫助很多人得到了學習和成長。
作為一名熱心腸的互聯網老兵,我意識到有很多經驗和知識值得分享給大家,也可以通過我們的能力和經驗解答大家在人工智能學習中的很多困惑,所以在工作繁忙的情況下還是堅持各種整理和分享。
但苦于知識傳播途徑有限,很多互聯網行業朋友無法獲得正確的資料得到學習提升,故此將并將重要的AI大模型資料包括AI大模型入門學習思維導圖、精品AI大模型學習書籍手冊、視頻教程、實戰學習等錄播視頻免費分享出來。
所有資料 ?? ,朋友們如果有需要全套 《LLM大模型入門+進階學習資源包》,掃碼獲取~ , 【保證100%免費】

篇幅有限,部分資料如下:
👉LLM大模型學習指南+路線匯總👈
💥大模型入門要點,掃盲必看!

💥既然要系統的學習大模型,那么學習路線是必不可少的,這份路線能幫助你快速梳理知識,形成自己的體系。

👉大模型入門實戰訓練👈
💥光學理論是沒用的,要學會跟著一起做,要動手實操,才能將自己的所學運用到實際當中去,這時候可以搞點實戰案例來學習。

👉國內企業大模型落地應用案例👈
💥《中國大模型落地應用案例集》 收錄了52個優秀的大模型落地應用案例,這些案例覆蓋了金融、醫療、教育、交通、制造等眾多領域,無論是對于大模型技術的研究者,還是對于希望了解大模型技術在實際業務中如何應用的業內人士,都具有很高的參考價值。 (文末領取)

💥《2024大模型行業應用十大典范案例集》 匯集了文化、醫藥、IT、鋼鐵、航空、企業服務等行業在大模型應用領域的典范案例。

👉LLM大模型學習視頻👈
💥觀看零基礎學習書籍和視頻,看書籍和視頻學習是最快捷也是最有效果的方式,跟著視頻中老師的思路,從基礎到深入,還是很容易入門的。 (文末領取)

👉640份大模型行業報告👈
💥包含640份報告的合集,涵蓋了AI大模型的理論研究、技術實現、行業應用等多個方面。無論您是科研人員、工程師,還是對AI大模型感興趣的愛好者,這套報告合集都將為您提供寶貴的信息和啟示。

👉獲取方式:
這份完整版的大模型 LLM 學習資料已經上傳CSDN,朋友們如果需要可以微信掃描下方CSDN官方認證二維碼免費領取【保證100%免費】
😝有需要的小伙伴,可以Vx掃描下方二維碼免費領取🆓




















