💡 Agent可以理解為某種能自主理解、規劃決策、執行復雜任務的智能體。Agent 是讓 LLM 具備目標實現的能力,并通過自我激勵循環來實現這個目標。它可以是并行的(同時使用多個提示,試圖解決同一個目標)和單向的(無需人類參與對話)。
Agent = LLM+Planning+Feedback+Tool use
決策流程:感知(Perception)→ 規劃(Planning)→ 行動(Action)
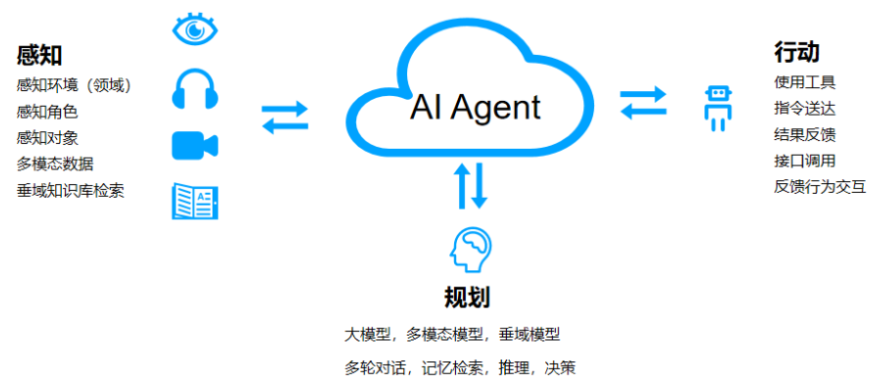
Agent創建一個目標或主任務后,主要分為以下三個步驟:
- 獲取第一個未完成的任務
- 收集中間結果并儲存到向量數據庫中
- 創建新的任務,并重新設置任務列表的優先級
 AI Agent主流框架
AI Agent主流框架
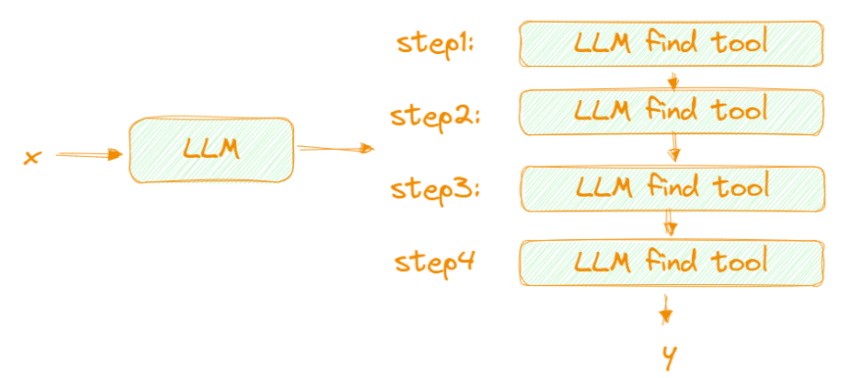
1. 微軟的Jarvis
step1: 規劃:利用好LLM 的推理規劃能力,對用戶輸入進行任務拆解;
step2: 決策:利用LLM的決策能力,判斷每個拆解的子任務,我們可以用什么方案解決
step3: 行動:通過決策得出的推薦工具(API,model,插件)去解決每個問題
step4: 總結輸出最終解決方案和結果給用戶
缺點:需要頻繁調用LLM,token數量巨大帶來高昂成本
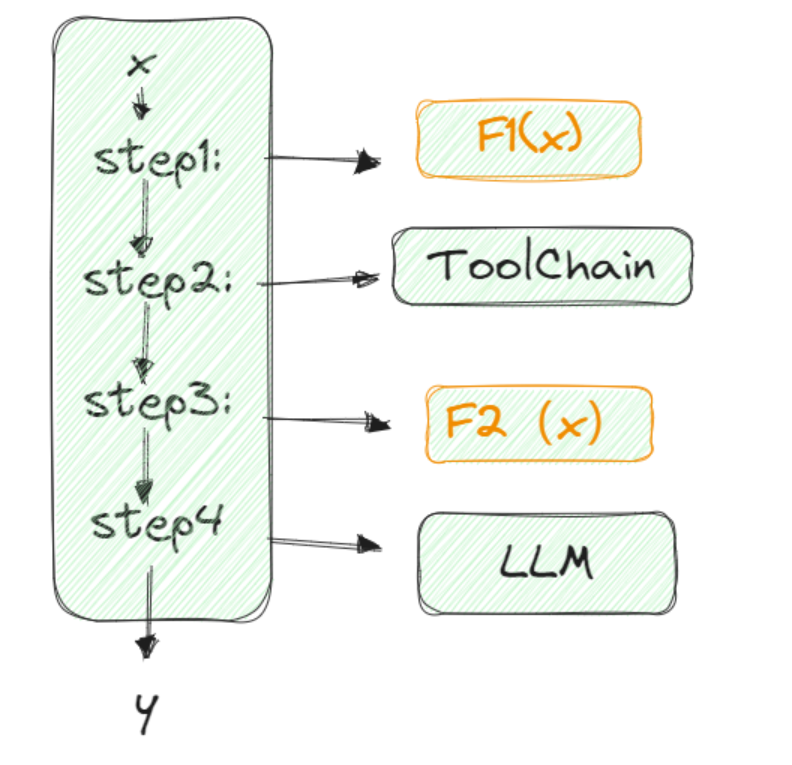
2 微軟的promptFlow
step1: 任務拆分,可以是人工拆分,也可以是LLM拆分,自定義~
反正從輸入到輸出就是一個任務流。我們只需要定義好每個步驟的輸入和輸出是什么。
step2: 每個task使用LLM去決策如何執行,也可以人工實現邏輯,也可以使用成熟插件,自定義~
step3:總結輸出給用戶
整個思路就是每個步驟都可控,輸入,輸出以及f(x)是什么都是我自己定義,我們通過評估使用LLM或者按傳統思路實現邏輯,都很靈活。最好這個任務流可以可視化,方便我們理清思路。
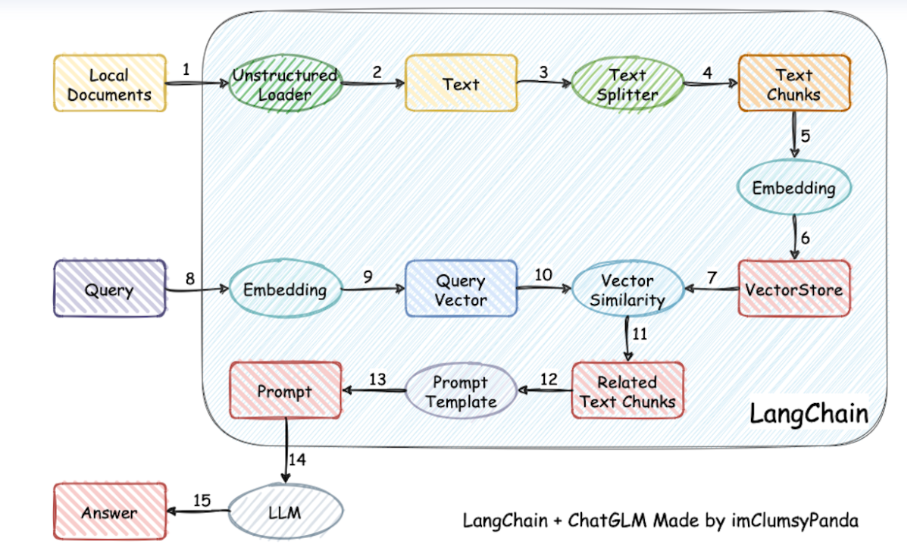
3. Langchain
Langchain也是AI Agenthttps://github.com/langchain-ai/langchain。langchain開發的初衷是讓開發者能夠快速的構建一個LLM原型應用。Langchain主要組件有:
Models:模型,各個類型的LLM模型集成,比如GPT-4
Prompts:提示,在提示詞中引入變量以適應用戶輸入,包括提示模版管理,優化和序列化。
Memory:記憶,用來保存模型交互的上下文
Indexes:索引,用來結構化文檔,外掛知識庫就是索引的一個功能應用
Chains:鏈, 對模型的一系列組件工具的鏈式調用,以上一個輸出為下一個輸入的一部分。
Agents: 代理,決定模型采取哪些行動,應該選哪個工具,執行并觀察流程
Multi-Agent:多個Agent共享一部分記憶,自主分工相互協作。
對于Langchain我們用的最多的就是利用他進行外掛知識庫,但是這其實知識Indexes這個組件的應用,Langchain的功能遠不止此;其中Chains的思路其實就是promptFlow;Agents里面的AgentAction就是Jarvis的思路。
缺點:Langchain才是功能和工具最齊全的框架,但是Langchain功能太多,導致整個框架太重,極其不靈活;大家通常只用他的一個組件功能
相關案例
斯坦福的虛擬小鎮
代碼已開源:https://github.com/joonspk-research/generative_agents
一個agent就是一個虛擬人物,25個agents之間的故事
架構

記憶(Memory)
短期記憶:在上下文中(prompt)學習。它是短暫有限的,因為它受到Transformer的上下文窗口長度的限制。
長期記憶:代理在查詢時可以注意到的外部向量存儲,可以通過快速檢索訪問。
反思(Reflection)
反思是由代理生成的更高級別、更抽象的思考。因為反思也是一種記憶,所以在檢索時,它們會與其他觀察結果一起被包含在內。反思是周期性生成的;當代理感知到的最新事件的重要性評分之和超過一定閾值時,就會生成反思。
- 讓代理確定要反思什么
- 生成的問題作為檢索的查詢
計劃(Plan)
計劃是為了做更長時間的規劃。像反思一樣,計劃也被儲存在記憶流中(第三種記憶),并被包含在檢索過程中。這使得代理能夠在決定如何行動時,同時考慮觀察、反思和計劃。如果需要,代理可能在中途改變他們的計劃(即響應,reacting)。
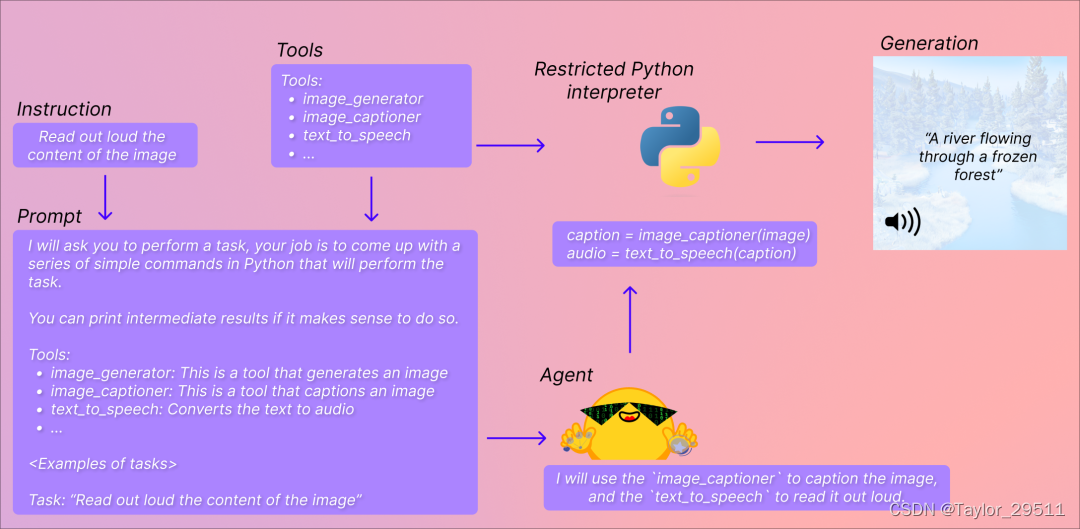
Huggingface:Transformers Agents 發布
它在 Transformers 的基礎上提供了一個自然語言 API,來 “讓 Transformers 可以做任何事情”。
這其中有兩個概念:一個是 Agent (代理),另一個是 Tools (工具),我們定義了一系列默認的工具,讓代理去理解自然語言并使用這些工具。
- 代理:這里指的是大語言模型 (LLM),你可以選擇使用 OpenAI 的模型 (需要提供密鑰),或者開源的 StarCoder 和 OpenAssistant 的模型,我們會提示讓代理去訪問一組特定的工具。
- 工具:指的是一個個單一的功能,我們定義了一系列工具,然后使用這些工具的描述來提示代理,并展示它將如何利用工具來執行查詢中請求的內容。
目前在 transformers 中集成的工具 包括:文檔問答、文本問答、圖片配文、圖片問答、圖像分割、語音轉文本、文本轉語音、零樣本文本分類、文本摘要、翻譯等。
總結
觀點1:Agent特點
- Agent本身是類似于DM的升級版,能夠充分利用對環境的感知,進行決策規劃,充分調用LLM的能力。
- 私有化部署時,集成到企業工作流中,面臨的邊際成本很難降低,且沒有通用性。
- Agent需要調用外部工具,調用工具最好的方式就是輸出類Makedown代碼
由LLM大腦輸出一種可執行的代碼,像是一個語義分析器,由它理解每句話的含義,然后將其轉換成一種機器指令,再去調用外部的工具來執行或生成答案。盡管現在的 Function Call 形式還有待改進,但是這種調用工具的方式是非常必要的,是解決幻覺問題的最徹底的手段。
觀點2:Agent落地的瓶頸
Agent本身用到兩部分能力,一部分是由LLM作為其“智商”或“大腦”的部分,另一部分是基于LLM,其外部需要有一個控制器,由它去完成各種Prompt,如通過檢索增強Memory,從環境獲得Feedback,怎樣做Reflection等。
Agent既需要大腦,也要外部支撐
- LLM本身的問題:自身的“智商”不夠,可進行LLM升級為GPT-5;Prompt的方式不對,問題要無歧義。
- 外部工具:系統化程度不夠,需要調用外部的工具系統,這是一個長期待解決的問題。
通用AGI:現階段Agent的落地,除了LLM本身足夠通用之外,也需要實現一個通用的外部邏輯框架。不只是“智商”問題,還需要如何借助外部工具,從專用抵達通用——而這是更重要的問題。
解決特定場景的特定問題:將LLM作為一個通用大腦,通過Prompt設計為不同的角色,以完成專用的任務,而非普適性的應用。但是面臨的關鍵問題,即Feedback將成為Agent落地實現的一大制約因素,對于復雜的Tools應用,成功概率會很低。
觀點3:多模態在Agent的發展
多模態只能解決Agent感知上的問題,而無法解決認知的問題。
多模態是必然趨勢,未來的大模型必然是多模態的大模型,未來的Agent也一定是多模態世界中的Agent。
觀點4:Agent從專用到通用的實現路徑
假設Agent最終將落地于100種不同的環境,在目前連最簡單的外部應用都難以實現的前提下,最終能否抽象出一個框架模型來解決所有外部通用性問題?
先將某一場景下的Agent做到極致——足夠穩定且魯棒,再逐步將它變成通用框架,也許這是實現通用Agent的路徑之一。。



![[vite] Pre-transform error: Cannot find package pnpm路徑過長導致運行報錯](http://pic.xiahunao.cn/[vite] Pre-transform error: Cannot find package pnpm路徑過長導致運行報錯)
 A~C)














