文章目錄
- 一、什么是數據湖?
- 起源
- 數據湖的特征
- 二、為什么要用數據湖?
- 三、數據湖與數據倉庫的區別
- 數據倉庫和數據湖的對比
- 四、數據湖本質
- 數據存儲架構
- 數據處理工具:三類
- 第一類工具
- 第二類工具
- 第三類工具
- 小結
- 五、總結
- 六、參考資料
一、什么是數據湖?
起源
數據湖的概念最早由Pentaho的創始人兼CTO詹姆斯·迪克森(James Dixon)于2010年10月在紐約Hadoop World大會上提出。然而,在國內,數據湖的概念直到2019年Iceberg、Hudi和Delta Lake三大數據湖開源后才真正流行起來。
讓我們先看看維基百科對數據湖的介紹:
數據湖(英語:Data Lake)是指以其原始格式(如BLOB或文件等)存儲的數據存儲庫或系統[1]。數據湖通常會將所有數據統一存儲,包括源系統數據、傳感器數據、社交數據等的原始副本,以及用于報表、可視化、數據分析和機器學習等流程中轉換后的數據。數據湖還可能包括關系數據庫的結構化數據(行與列)、半結構化的數據(CSV、日志、XML、JSON)及非結構化數據(電子郵件、文件、PDF)和二進制數據(圖像、音頻、視頻)等。數據湖可能是“on premises”(指在組織的數據中心里),也可能放在云端(使用Amazon、微軟或Google的云端服務)。
一言以蔽之:數據湖是一個理論上只要是可以轉化成二進制的數據均可存儲的數據存儲管理系統
數據湖的特征
數據湖具有以下特點:
-
容量大
數據湖匯聚各個業務數據源,容納散落在各處的數據,理論上存儲空間巨大。 -
格式多
數據湖架構面向多數據源的信息存儲,可以快速高效地采集、存儲、處理大量來源不同、格式各異的原始數據,包括文本、圖片、視頻、音頻、網頁等各類無序的非結構化數據。數據湖能將不同種類的數據匯聚存儲在一起,并對匯聚后的數據進行管理,建立數據之間的關聯關系,具有很強的兼容性。 -
處理速度快
數據湖技術能將各類原始數據快速轉化為可直接提取、分析、使用的標準格式,統一優化數據結構并對數據進行分類存儲。根據業務需求,數據湖可以對存儲的數據進行快速的查詢、挖掘、關聯和處理,并實時傳輸給終端用戶。 -
分布式體系
由于Hadoop也能基于分布式文件系統來存儲和處理多類型數據,因此許多人認為Hadoop的工作機制就是數據湖的處理機制。當然,Hadoop基于其分布式、可橫向擴展的文件系統架構,可以管理和處理海量數據,但它無法提供數據湖所需的復雜元數據管理功能。最直觀的表現是,數據湖的體系結構表明數據湖是由多個組件構成的生態系統,而Hadoop僅提供了其中的部分組件功能。
注意:嚴格來說數據湖沒有跟具體哪個技術綁定
二、為什么要用數據湖?
要回答這個問題,我們需要先回顧一下數據庫和數據倉庫的概念。
數據庫的基本概念大家應該都不陌生。如今但凡是個業務系統,都或多或少需要用到數據庫。即便我們不直接跟數據庫打交道,它們也在背后默默地為我們服務,比如刷個卡、取個錢,后臺都是數據庫在運行。
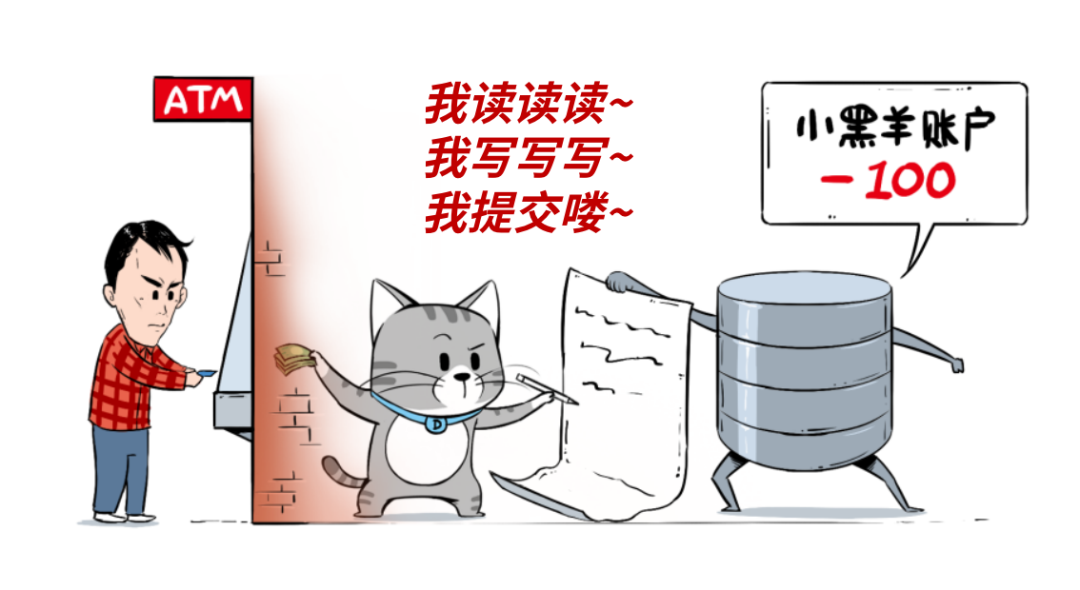
數據庫用于聯機事務處理,通常處理的是小數據量的高頻讀寫操作。
當企業的數據越來越多,開始希望基于業務數據進行決策分析時,便有了 數據倉庫 的出現。數據庫等原始數據經過 ETL(Extract, Transform, Load)加工后,被裝進數據倉庫。數據倉庫主要用于聯機分析業務,通常處理大數據量的讀取。

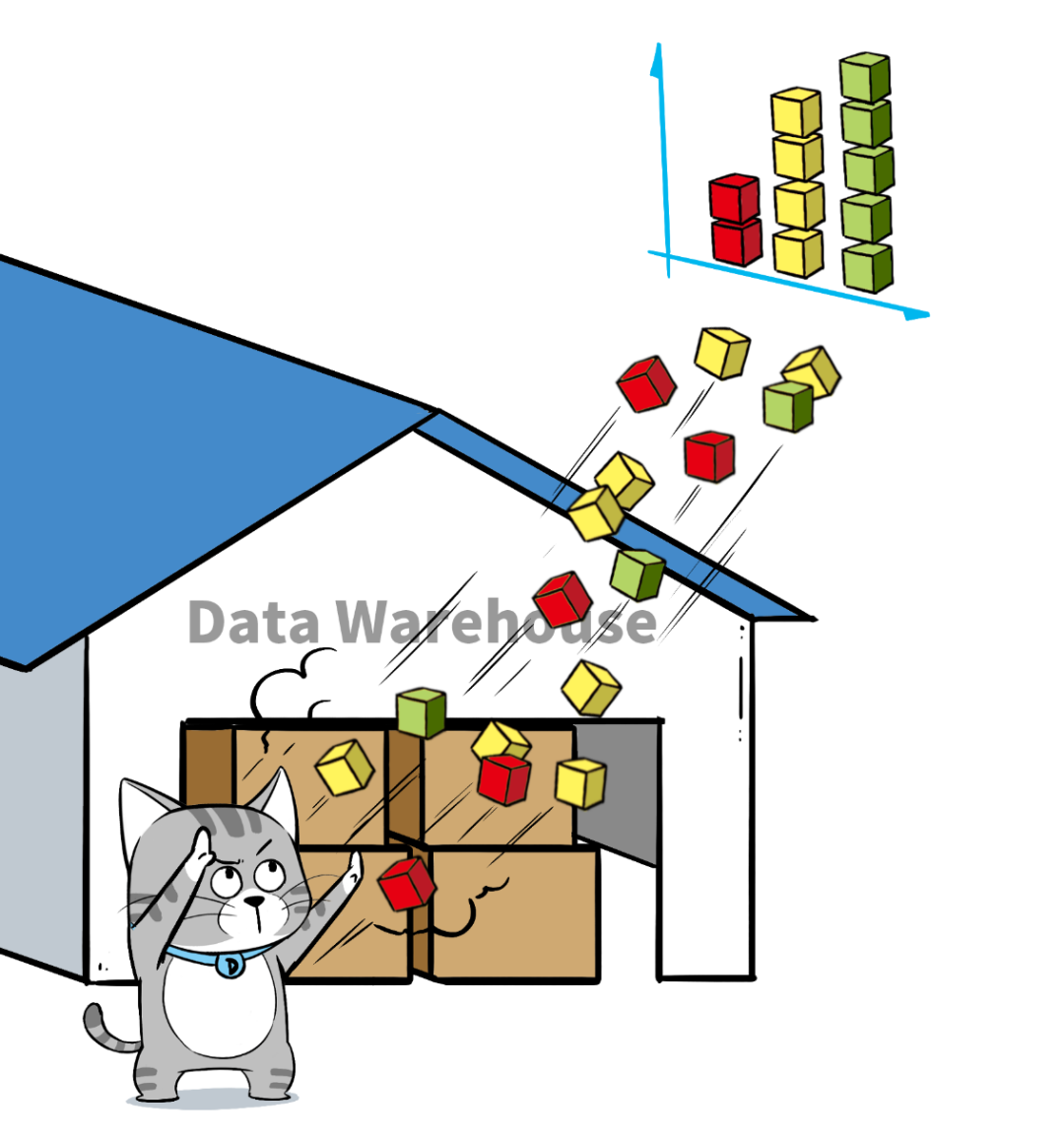
以上是數據庫和數據倉庫的簡單介紹。盡管它們的應用場景不同,但它們都處理 結構化數據。在相當長的一段時間內,數據庫和數據倉庫聯合起來,共同滿足企業的實時“交易”型業務和聯機“分析性”業務需求。
然而,隨著時代的發展,數據的類型變得越來越多樣化,人們對數據的需求也越來越復雜。

企業希望把生產經營中的所有相關數據,歷史的、實時的,在線的、離線的,內部的、外部的,結構化的、非結構化的,都能完整保存下來,方便“沙中淘金”。
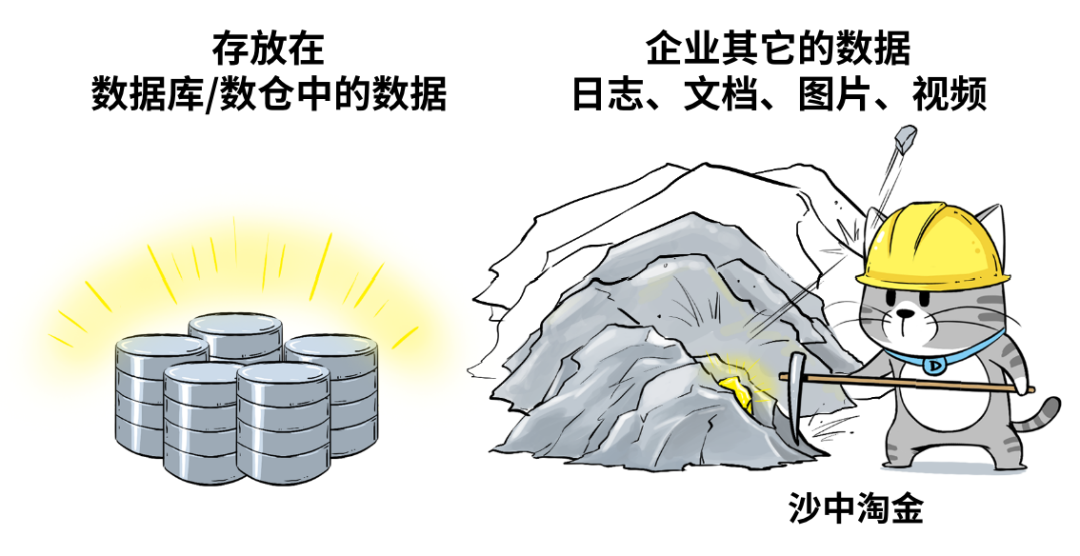
企業越來越重視 “大數據” 的價值,希望能夠存儲并有效利用這些數據。
這些數據種類繁多,五花八門,數據庫和數據倉庫都無法勝任這項任務,怎么辦呢?
索性挖個大坑吧!

這就是數據湖的原型。
簡單來說,數據湖就像一個“大水坑”,是一種將各類異構數據進行集中存儲的架構。數據湖能夠存儲結構化、半結構化和非結構化數據,使企業可以在一個統一的平臺上存儲、管理和分析各種類型的數據。這不僅能夠降低數據存儲的成本,還能提高數據分析的靈活性和效率,幫助企業更好地挖掘數據價值,做出更明智的業務決策。
三、數據湖與數據倉庫的區別
數據倉庫和數據湖的對比

從數據含金量來比,數據倉庫里的數據價值密度更高一些,數據的抽取和Schema的設計,都有非常強的針對性,便于業務分析師迅速獲取洞察結果,用與決策支持。
而數據湖更有一種“兜底”的感覺,甭管當下有用沒有/或者暫時沒想好怎么用,先保存著、沉淀著,將來想用的時候,盡管翻牌子就是了,反正都原汁原味的留存了下來。

而從產品形態看,數據倉庫可以是獨立的標準化產品,數據湖則是一種解決方案,通常是圍繞對象存儲為“湖底座”的大數據管理方案組合。
四、數據湖本質
數據湖的本質:是由 數據存儲架構 和 數據處理工具 組成的 解決方案。而不是某個單一獨立產品。
數據存儲架構
數據存儲架構需要具備足夠的擴展性和可靠性,確保企業能夠存儲所有原始數據,并且長期保存。這些存儲系統包括:
- Hadoop 的 HDFS
- 對象存儲系統,如 Amazon Web Services(亞馬遜云科技)
數據處理工具:三類
第一類工具
解決的問題是:如何將數據“搬到”湖里,即 ETL(Extract, Transform, Load)。

第二類工具
解決的問題是:數據管理。如果元數據缺失,數據湖中的數據質量將無法保證,各種數據無序堆積,最終會導致數據湖變成 數據沼澤。

第三類工具
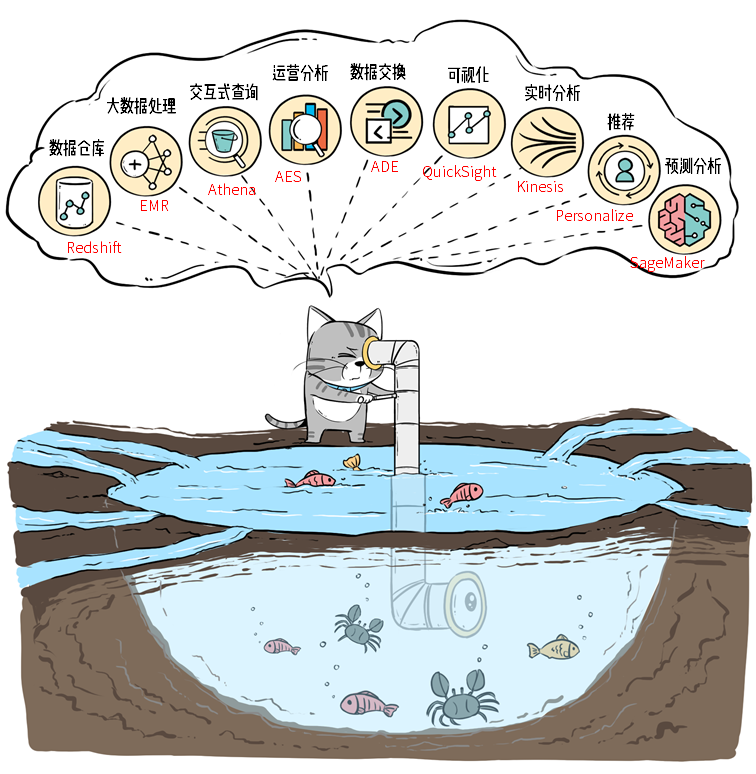
解決的問題是:從湖中的海量數據中“淘金”。數據存儲在數據湖中并不是終點,還需要對數據進行分析、挖掘和利用。例如,對湖中的數據進行查詢,同時將數據提供給機器學習和數據科學類的業務,以便實現“點石成金”。

小結
數據湖不僅僅是一個“囤積”數據的“大水坑”。除了存儲技術構建的湖底座以外,還包含一系列的數據入湖、數據出湖、數據管理和數據應用工具集,共同組成了數據湖解決方案。
五、總結
數據湖的概念最早由詹姆斯·迪克森在2010年提出,隨著2019年Iceberg、Hudi和Delta Lake等開源項目在國內流行起來。數據湖是一種多功能系統,能夠存儲各種類型的數據,包括結構化、半結構化和非結構化數據,具備高容量存儲和快速處理多種數據格式的能力。
與傳統的數據庫和數據倉庫不同,數據湖不僅可以保存原始數據,還能支持快速的查詢、數據分析和機器學習應用,幫助企業更有效地挖掘數據的潛力。數據湖由數據存儲架構和多種數據處理工具組成,而不是單一的獨立產品。
數據湖解決方案還包括ETL工具、元數據管理和數據分析工具,這些工具的使用確保了數據湖的高效管理和利用,防止其變成無序的“數據沼澤”。
在下一篇文章中,我們將深入探討市面上熱門的數據湖開源框架,以及這些開源框架是否能夠滿足數據湖的基本概念和功能要求。
六、參考資料
- 從數據倉庫到數據湖(下):數據湖領域熱門的開源框架
- 從數據庫到數據倉庫:數據倉庫導論
- 開源框架DeltaLake、Hudi、Iceberg深度對比
- 數據湖這個大坑,是怎么挖的?
![[運維平臺]泛微運維平臺](http://pic.xiahunao.cn/[運維平臺]泛微運維平臺)




)











)
)
