Deep-Learning-Interview-Book/docs/深度學習.md at master · amusi/Deep-Learning-Interview-Book · GitHub
?網上相關總結:
小菜雞寫一寫基礎深度學習的問題(復制大佬的,自己復習用) - 知乎 (zhihu.com)
CV面試問題準備持續更新貼 - 知乎 (zhihu.com)
Epoch
- Epoch?是指完成一次完整的數據集訓練的過程。
- 比如,有一個數據集有1000個樣本,當網絡用這些樣本訓練一次后,這就是一個epoch。
Iteration
- Iteration?是指在一個epoch中,使用一個batch進行訓練的次數。
- 如果你的數據集有1000個樣本,batch size是100,那么一個epoch就會有10次iteration(1000/100=10)。
Batch Size
- Batch Size?是指每次iteration中用于訓練的樣本數量。
- 如果你的batch size是100,每次訓練就使用100個樣本。
反向傳播(BP)推導
假設我們有一個簡單的三層神經網絡(輸入層、隱藏層和輸出層):
- 輸入層: xxx
- 隱藏層: hhh
- 輸出層: yyy
前向傳播
-
輸入到隱藏層: h=f(Wxhx+bh)h = f(W_{xh} x + b_h)h=f(Wxh?x+bh?) 其中 WxhW_{xh}Wxh? 是輸入到隱藏層的權重矩陣,bhb_hbh? 是隱藏層的偏置向量,fff 是激活函數。
-
隱藏層到輸出層: y^=g(Whyh+by)\hat{y} = g(W_{hy} h + b_y)y^?=g(Why?h+by?) 其中 WhyW_{hy}Why? 是隱藏層到輸出層的權重矩陣,byb_yby? 是輸出層的偏置向量,ggg 是輸出層的激活函數,通常在分類問題中是softmax函數。
損失函數
假設我們使用均方誤差損失函數:![]()
其中 yyy 是實際輸出,y^\hat{y}y^? 是預測輸出。
反向傳播
我們需要計算損失 LLL 對每個權重和偏置的梯度,然后更新這些參數。我們從輸出層開始,逐層向后推導。
-
輸出層梯度:
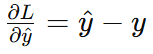
-
隱藏層到輸出層權重梯度:
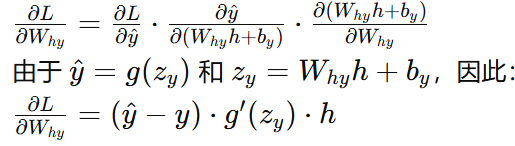
-
隱藏層到輸出層偏置梯度:
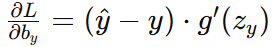
-
隱藏層誤差:
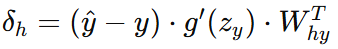
-
輸入層到隱藏層權重梯度:
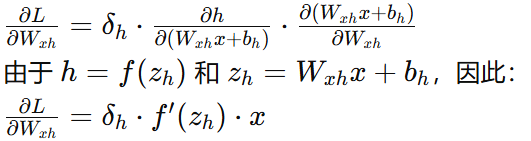
-
輸入層到隱藏層偏置梯度:

參數更新
使用梯度下降法更新權重和偏置:
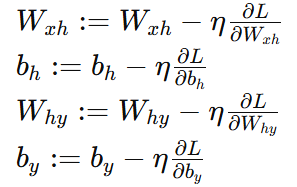
其中 η 是學習率。
?深度神經網絡(DNN)反向傳播算法(BP) - 劉建平Pinard - 博客園 (cnblogs.com)

感受野計算
如何計算感受野(Receptive Field)——原理 - 知乎 (zhihu.com)
池化?
1. 池化的作用
池化的主要作用有兩個:
- 降低計算復雜度:通過減少特征圖的尺寸,減少后續卷積層和全連接層的計算量。
- 減小過擬合:通過降低特征圖的分辨率,可以使模型更具魯棒性,對輸入數據的小變化不那么敏感。
2. 池化類型
池化操作通常有兩種類型:
- 最大池化(Max Pooling):從池化窗口中選擇最大值。
- 平均池化(Average Pooling):從池化窗口中選擇平均值。
?池化(Pooling)的種類與具體用法——基于Pytorch-CSDN博客
一圖讀懂-神經網絡14種池化Pooling原理和可視化(MAX,AVE,SUM,MIX,SOFT,ROI,CROW,RMAC )_圖池化-CSDN博客
卷積神經網絡(CNN)反向傳播算法 - 劉建平Pinard - 博客園 (cnblogs.com)
Sobel邊緣檢測
是圖像處理中常用的技術,它使用卷積核(濾波器)來突出圖像中的邊緣。Sobel算子通過計算圖像灰度值的梯度來檢測邊緣。
1. Sobel算子
Sobel算子有兩個卷積核,一個用于檢測水平方向的邊緣,另一個用于檢測垂直方向的邊緣。
水平Sobel卷積核(Gx)
diff
復制代碼
-1 0 1 -2 0 2 -1 0 1
垂直Sobel卷積核(Gy)
diff
復制代碼
-1 -2 -1 0 0 0 1 2 1
2. Sobel卷積操作
通過將這兩個卷積核分別與圖像進行卷積操作,可以得到圖像在水平方向和垂直方向上的梯度圖。
卷積計算過程
假設有一個3x3的圖像塊:
css
復制代碼
a b c d e f g h i
水平方向的梯度計算(Gx):
css
復制代碼
Gx = (c + 2f + i) - (a + 2d + g)
垂直方向的梯度計算(Gy):
css
復制代碼
Gy = (g + 2h + i) - (a + 2b + c)
3. 組合梯度
最終的梯度強度可以通過組合Gx和Gy計算得到:
scss
復制代碼
G = sqrt(Gx^2 + Gy^2)
梯度計算
通過這些卷積核,我們可以計算圖像在水平方向和垂直方向的梯度。梯度表示圖像灰度值的變化速率,變化速率大的地方就是邊緣。具體來說:
- 水平方向梯度(Gx):表示圖像從左到右的變化。如果有明顯的水平邊緣,Gx會有大的值。
- 垂直方向梯度(Gy):表示圖像從上到下的變化。如果有明顯的垂直邊緣,Gy會有大的值。
4. 組合梯度
最終,通過組合水平方向和垂直方向的梯度(通常使用歐幾里得距離),我們可以得到圖像的梯度強度:
計算力(flops)和參數(parameters)數量
(31 封私信 / 80 條消息) CNN 模型所需的計算力(flops)和參數(parameters)數量是怎么計算的? - 知乎 (zhihu.com)


參數共享的卷積環節



不可導的激活函數如何處理



BN
BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm、SwitchableNorm總結_四維layernormal-CSDN博客
Batch Normalization原理與實戰 - 知乎 (zhihu.com)
Normalization操作我們雖然緩解了ICS問題,讓每一層網絡的輸入數據分布都變得穩定,但卻導致了數據表達能力的缺失。BN又引入了兩個可學習(learnable)的參數?𝛾?與?𝛽?。這兩個參數的引入是為了恢復數據本身的表達能力,對規范化后的數據進行線性變換?

重點最后一句





感受野計算?
卷積神經網絡物體檢測之感受野大小計算 - machineLearning - 博客園 (cnblogs.com)
卷積神經網絡的感受野 - 知乎 (zhihu.com)


資源 | 從ReLU到Sinc,26種神經網絡激活函數可視化 (qq.com)
非線性激活函數的線性區域


從 SGD 到 Adam —— 深度學習優化算法概覽(一) - 知乎 (zhihu.com)
一個框架看懂優化算法之異同 SGD/AdaGrad/Adam - 知乎 (zhihu.com)
指數移動平均公式
EMA指數滑動平均(Exponential Moving Average)-CSDN博客

動量梯度下降法(Momentum)
Adagrad
RMSprop
Adam
Adam那么棒,為什么還對SGD念念不忘 (2)—— Adam的兩宗罪 - 知乎 (zhihu.com)
dropout
深度學習-Dropout詳解_深度學習dropout-CSDN博客
Dropout的深入理解(基礎介紹、模型描述、原理深入、代碼實現以及變種)-CSDN博客
一文看盡12種Dropout及其變體-騰訊云開發者社區-騰訊云 (tencent.com)
Pytorch——dropout的理解和使用 - Circle_Wang - 博客園 (cnblogs.com)
1x1卷積?
?(31 封私信 / 80 條消息) 卷積神經網絡中用1*1 卷積有什么作用或者好處呢? - 知乎 (zhihu.com)
深度學習筆記(六):1x1卷積核的作用歸納和實例分析_1x1卷積降維-CSDN博客
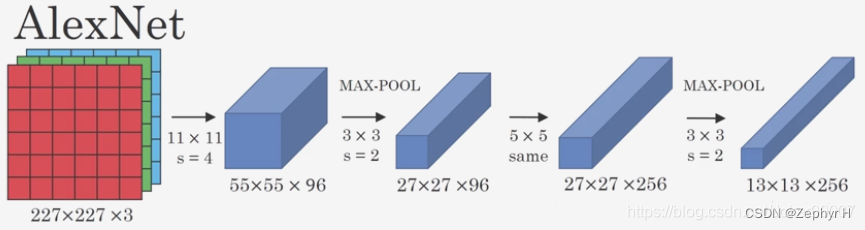



AlexNet網絡結構詳解(含各層維度大小計算過程)與PyTorch實現-CSDN博客
深度學習——VGG16模型詳解-CSDN博客
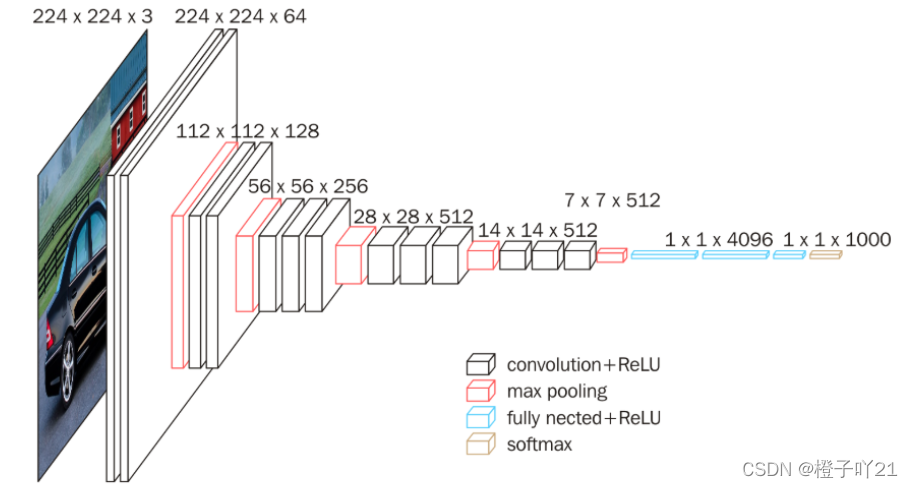

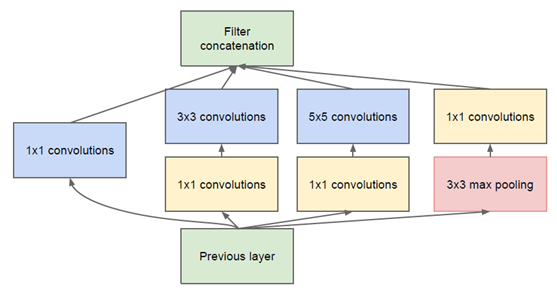
3乘3卷積代替5乘5卷積


經典卷積神經網絡算法(4):GoogLeNet - 奧辰 - 博客園 (cnblogs.com)
1x1卷積降維再接3x3卷積
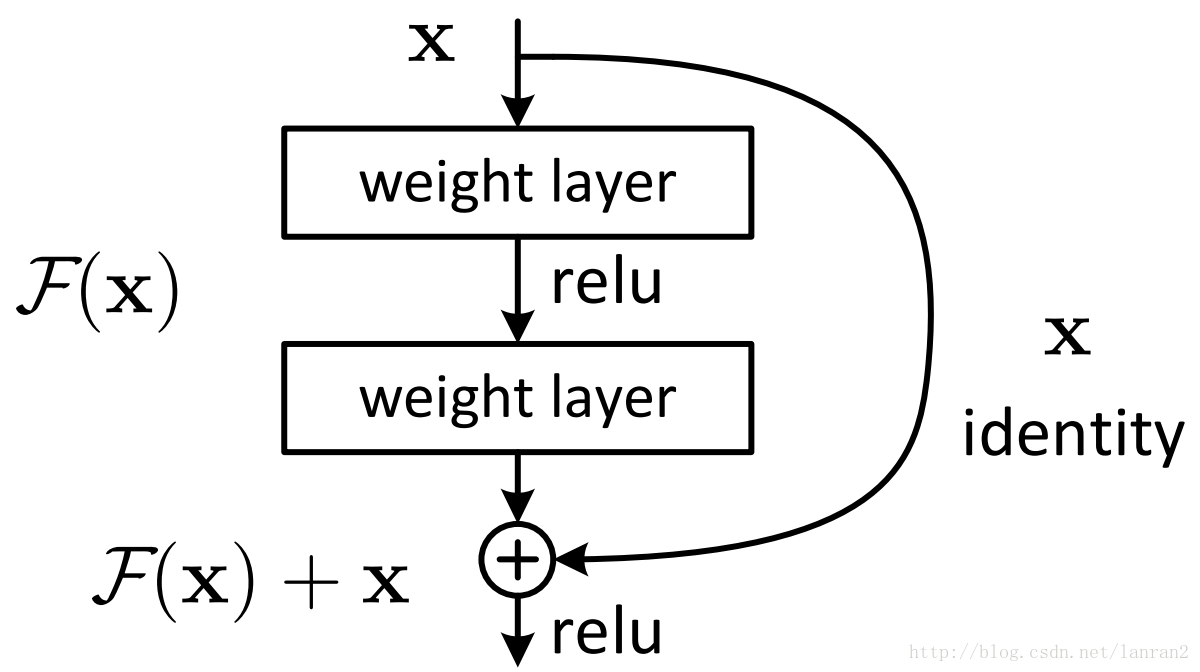
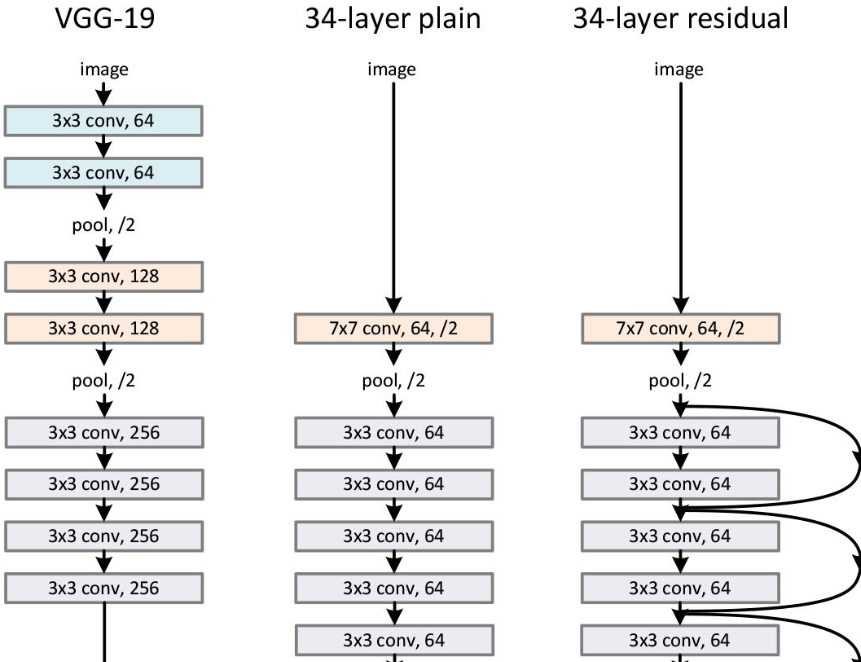
resnet
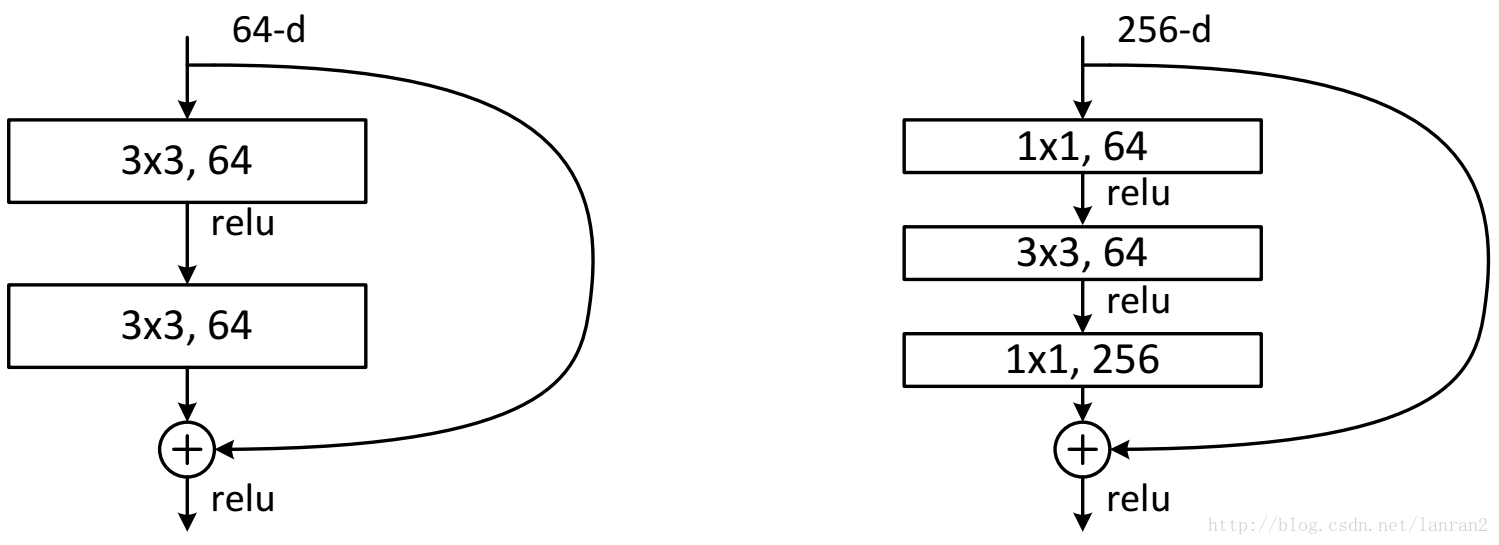
兩種ResNet設計
channel不同怎么相加
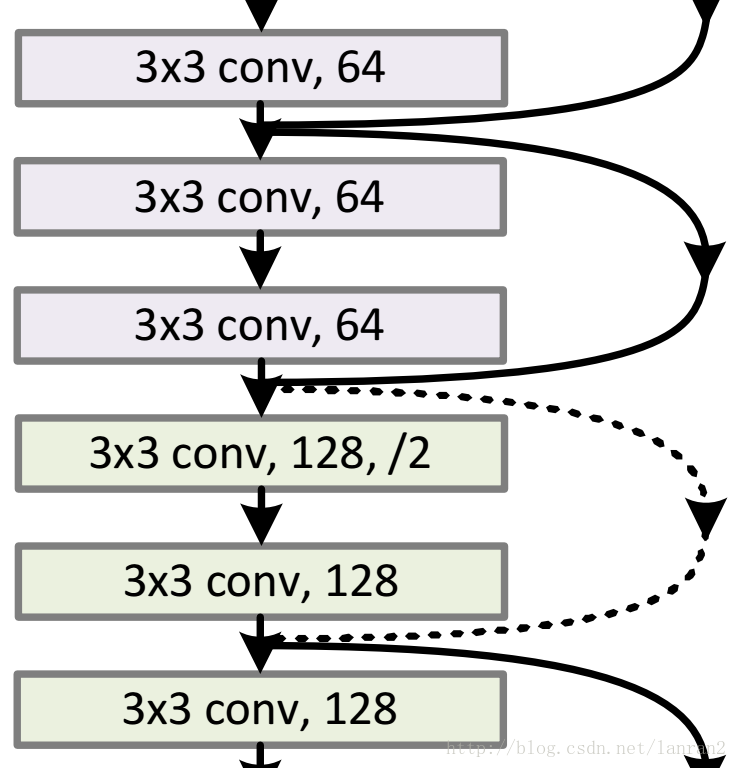 通過卷積調整
通過卷積調整
ResNet解析-CSDN博客


(31 封私信 / 80 條消息) resnet(殘差網絡)的F(x)究竟長什么樣子? - 知乎 (zhihu.com)

(31 封私信 / 80 條消息) Resnet到底在解決一個什么問題呢? - 知乎 (zhihu.com)

殘差連接使梯度穩定


ResNet中的恒等映射是一種直接將輸入添加到輸出的操作方式,確保了信息和梯度可以穩定地傳遞。它通過保持梯度的穩定性,防止了梯度消失和爆炸問題,從而使得訓練非常深的網絡成為可能。

(31 封私信 / 80 條消息) ResNet為什么不用Dropout? - 知乎 (zhihu.com)

人工智能 - [ResNet系] 002 ResNet-v2 - G時區@深度學習 - SegmentFault 思否
DenseNet詳解_densenet網絡-CSDN博客
yolo系列
YOLO系列算法全家桶——YOLOv1-YOLOv9詳細介紹 !!-CSDN博客
?【YOLO系列】YOLOv1論文超詳細解讀(翻譯 +學習筆記)_yolo論文-CSDN博客
YOLO系列算法精講:從yolov1至yolov8的進階之路(2萬字超全整理)-CSDN博客
NMS

v2引入anchor

分割
計算機視覺—淺談語義分割、實例分割及全景分割任務 (深度學習/圖像處理/計算機視覺)_全景分割和實例分割-CSDN博客
【計算機視覺】最全語義分割模型總結(從FCN到deeplabv3+)-CSDN博客
目標檢測與YOLO(2) + 語義分割(FCN)_yolo模型和fcn-CSDN博客
【yolov8系列】yolov8的目標檢測、實例分割、關節點估計的原理解析-CSDN博客
yolo實現實例分割和關鍵點預測,都是在head部分增加新的檢測頭實現



Bounding-box regression詳解(邊框回歸)_bbox regression-CSDN博客

反卷積(Deconvolution)、上采樣(UNSampling)與上池化(UnPooling)_反卷積和上采樣-CSDN博客
形象解釋:
反卷積(Transposed conv deconv)實現原理(通俗易懂)-CSDN博客
對深度可分離卷積、分組卷積、擴張卷積、轉置卷積(反卷積)的理解-CSDN博客
ShuffleNetV2:輕量級CNN網絡中的桂冠 - 知乎 (zhihu.com)
輕量級神經網絡“巡禮”(一)—— ShuffleNetV2 - 知乎 (zhihu.com)
(31 封私信 / 80 條消息) 怎么選取訓練神經網絡時的Batch size? - 知乎 (zhihu.com)

)
)


之C++11新特性)






)



滑動窗口算法練習:無重復字符的最長子串)


)
培訓)