現在的大模型訓練通常會包括兩個階段:
一是無監督的預訓練,即通過因果語言建模預測下一個token生成的概率。該方法無需標注數據,這意味著可以利用大規模的數據學習到語言的通用特征和模式。
二是指令微調,即通過自然語言指令構建的多樣任務對預訓練模型進行微調,顯著增強了任務泛化能力。
最近,微軟與清華提出了指令預訓練(Instruction Pre-Training)的新方法,該方法在第一階段引入指令—響應對的數據,采用監督多任務學習來探索預訓練語言模型的新途徑。
指令預訓練使Llama3-8B模型在部分領域上的表現甚至超越了Llama3-70B模型。

論文標題:
Instruction Pre-Training: Language Models are Supervised Multitask Learners
論文鏈接:
https://arxiv.org/pdf/2406.14491
github鏈接:
https://github.com/microsoft/LMOps
可能有同學會擔心指令—響應對的數據從何而來,人工構建的話耗時耗力,如果是合成數據,其質量又如何保障?
為了解決以上問題,作者通過將現有的數據集轉換為固定格式,然后微調7B大小的開源模型,構建了200M高質量多樣化的指令-響應對,覆蓋40多個任務類別。
另外,通過與常規的預訓練方法相比,指令預訓練不僅提高了模型性能,還有望強化指令微調,減少微調步數。在持續的預訓練中,指令預訓練使Llama3-8B模型在部分領域上的表現甚至超越了Llama3-70B模型。
指令預訓練
與傳統的直接在原始語料庫上進行預訓練不同,指令預訓練( Instruction Pre-Training)通過使用指令合成器生成一組指令-響應對(instruction-response pairs)來增強每個原始文本,然后利用增強后的語料庫對語言模型進行預訓練。

這些增強的指令-響應對是基于大量原始語料庫的內容合成的,確保了高知識覆蓋率和正確性。因此指令預訓練的核心就是如何構建一個指令合成器,下文將詳細敘述這個過程。
指令合成器
簡單來說,指令合成器的開發,需要先將廣泛的現有數據集轉換們需要的格式:每個示例包含原始文本以及一組指令-響應對。使用這些數據,然后微調語言模型,以基于相應原始文本生成指令-響應對。
與現有使用GPT-3等大型或專有模型合成數據不同,本文選用7B的開源模型,節省成本但性能不輸大模型。合成的數據具有高度多樣性,使得指令合成器能夠泛化到未見過的數據。
數據收集
從基于上下文的任務完成數據集中抽樣并格式化數據。每個數據樣本的上下文作為原始文本,下游任務作為指示-響應對,模版如下圖所示。這些上下文跨越各種領域,如百科全書、社交媒體和學術測試 ,任務包括共性推理和情感分析等各種領域。

微調
使用few-shot的方式微調指令合成器,如下圖所示,一個樣本包含一段原始文本以及它的指令響應對,多個樣本序列相互連接。所有示例均從同一數據集中抽樣,保障不同指示-響應對集合中的模式的一致性。

推理
在推理時,每一輪都將之前輪次的文本、指示-響應對前置到當前文本。這使得指示合成器能夠基于先前示例生成新的指示-響應對。
語言模型預訓練
在收集合成的指令-回應對之后,使用多樣的模板使指令格 式多樣化,并將每個原始文本與其指令-回應對連接起來。通過連接來自M輪的文本和指令對,為后續的預訓練創建了一個M次示例。
除了預訓練數據外, 指令預訓練保持所有其他預訓練設置與一般預訓練相同,同樣使用下一個Token預測目標進行 訓練,并在所有Token上計算損失。
作者同樣進行了從零開始的常規預訓練和領域自適應的持續預訓練(Domain-Adaptive Continual Pre-Training),以驗證在不同預訓練場景中的有效性。
實驗結果
指令預訓練 VS 常規預訓練
指令預訓練表現出強大的泛化性
作者在不同規模的模型上使用不同的數據進行與訓練,結果如下表所示。Vanilla PT代表常規的預訓練方式,Instrcut PT是本文所提出的方法,Mix PT將一般預訓練使用的原始語料庫與指令合成器的微調數據混合在一起。

與Vanilla PT相比,混合了指令合成器的微調數據的Mix PT有所提升。而Instrcut PT則在大多數評估數據集上實現了更好的性能。另外指令合成器的微調數據中不包含任何評估數據集,但卻在未見過的數據集上表現良好,展示出強大的泛化性。
指令預訓練在不同模型規模上具有一致的數據效率。
另外,當將Instrcut PT與其他開源模型比較時,Instrcut PT以較少的參數量與token花費得到了不錯的性能。如下表所示:

使用100B個tokens,500M參數的Instrcut PT,達到了Pythia-1B使用300B tokens的性能,而使用100B個tokens,1.3B參數的Instrcut PT達到了BLOOM-3B使用341B個tokens訓練的性能。
Instrcut PT有望減少微調的步驟數量。
通過對比Vanilla PT與Instrcut PT在zero-shot 和 few-shot下的表現,如下圖所示,隨著步驟增長,Instrcut PT穩步提升。
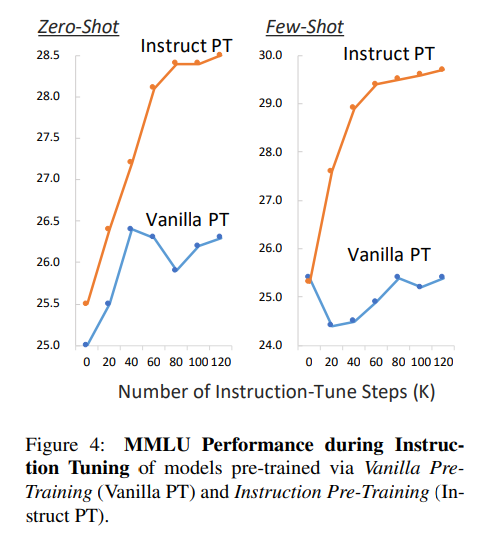
作者認為,指令預訓練與指令調優階段的任務更緊密對齊,有助于在預訓練和微調之間實現順暢的過渡。這種緊密的對齊使得模型能夠更高效地學習下游任務,從而有望顯著減少進一步微調的步驟數量。
指令預訓練 VS 領域自適應持續預訓練
所謂領域自適應持續預訓練就是使用領域語料(本文中使用生物醫學領域和金融領域)對語言模型進一步逐步預訓以使其適應一系列領域。
這里作者展示了經由Vanilla PT持續預訓練后,以及經由Instruct PT持續預訓練后的效果。還展示了Llama3-70B的表現作為參考,如下表所示:
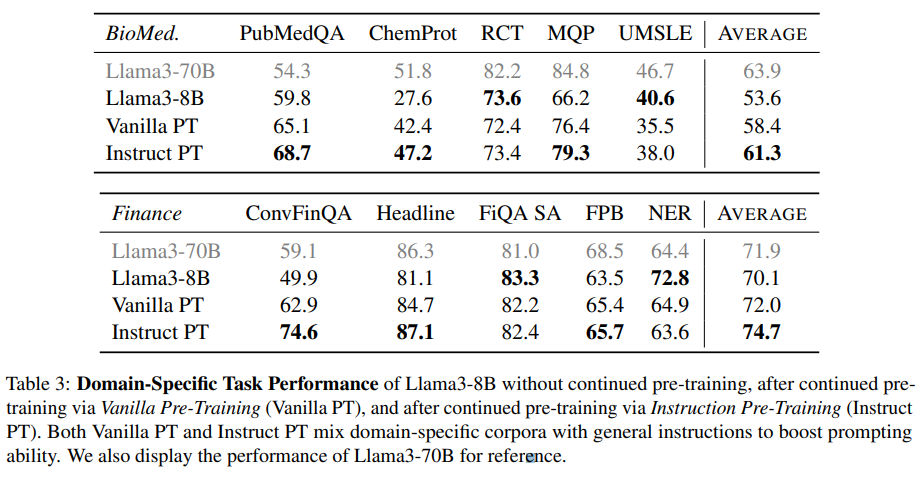
Instruct PT在幾乎所有領域特定任務上始終表現優于Vanilla PT。使用Instruct PT進行持續預訓練大大提升了 Llama3-8B 的領域特定表現,達到與甚至超過 Llama3-70B 的水平。
在金融 NER 基準測試中,Instruct PT表現不及 Vanilla PT,表現出相當大的方差,甚至Llama3-70B 不如 Llama3-8B,表明此基準測試可能不夠可靠。
評估指令合成器生成質量
在本文中起關鍵作用的是前文介紹的指令合成器,能夠生成任何原始文本的指令-響應對。因此,作者在已見數據集和未見數據集上評估了指令合成器的性能。
響應準確性
為了評估生成響應的準確性,作者給定原始文本和任務指令,使指令合成器生成一個響應,然后計算生成的響應與黃金響應之間的 F1 相似度以評估響應準確性。
由于該指令合成器是從基礎 Mistral-7B 模型微調而來的。為了比較,作者對比基礎模型的結果。如下表所示:

可以看到,微調的合成器在已知和未知數據集上明顯優于基礎模型。
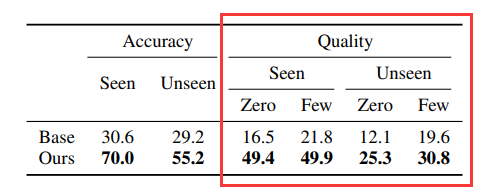
指令-響應對質量
該評測是給定原始文本,指令合成器生成一組指令-響應對。與基礎模型相比,微調的合成器在零樣本、少樣本、已知和未知數據集這四個維度上顯著優于基準。
合成的指令-響應對提高LM的泛化性
這給定里將測試原始文本、合成對和測試指令串聯在一起的提示,LM 生成一個響應。然后通過在提示中使用或者不使用合成的指令-響應對分別衡量LM的性能,結果如下圖所示:

在已知和未知數據集上,本文加入合成的指令-響應對的方法持續增強了 LM 在測試任務上的表現,超過了所有基線。即使是沒有見過的數據集,也能帶來很大的幫助。
合成的指令-響應對的多樣性
作者從語料庫中抽取了500個增強的指令文本,并使用GPT-4示評估合成的指令是否與原始文本的上下文相關(上下文相關性),以及基于指令和上下文回復是否準確(回復準確性)。

從上表中,可以看到指令合成器生成涵蓋 49 個不同任務類別的指令-響應對,其中超過 85% 與上下文相關,響應準確率達到70%。
作者進一步將任務類別分為 9 個通用任務場景。下圖顯示了通用預訓練中指令增強語料庫中每個任務場景的百分比。表明本文的合成數據涵蓋了所有通用任務場景,展示了高度多樣化。

結論
本文提出的指令預訓練(Instruction Pre-Training)方法展示了監督多任務學習的巨大潛力。通過微調指令合成器生成高質量多樣化的指令-響應對來增強語料庫,然后在增強的語料庫上對LMs進行預訓練,該方法顯著提高了模型在多種任務上的泛化能力。此外,在持續預訓練中,指令預訓練使得小模型在特定領域的表現能夠媲美甚至超過大模型。
希望這項工作能夠激發對監督多任務預訓練領域的進一步探索,有效提升LMs的通用能力。


?)


















