文章目錄
- 前言
- 一、模型結構
- 1. encoder
- 2. decoder
- 3. set
- 二、數據增強
- 三、數據
- splitting the pages
- 四、實驗評估
- repetitions during inference
- 五、代碼
- 1. 環境安裝
- 2. Dataset(dataset.py)
- 3. Model(model.py)
- 總結
前言
科學知識主要存儲在書籍和科學期刊中,通常以PDF的形式。然而PDF格式會導致語義信息的損失,特別是對于數學表達式。文章提出Nougat,一種視覺transformer模型,它執行OCR任務,用于將科學文檔處理成標記語言。
paper:https://arxiv.org/pdf/2308.13418
github:https://github.com/facebookresearch/nougat/tree/main
一、模型結構
模型是一個encoder-decoder模型,允許端到端的訓練。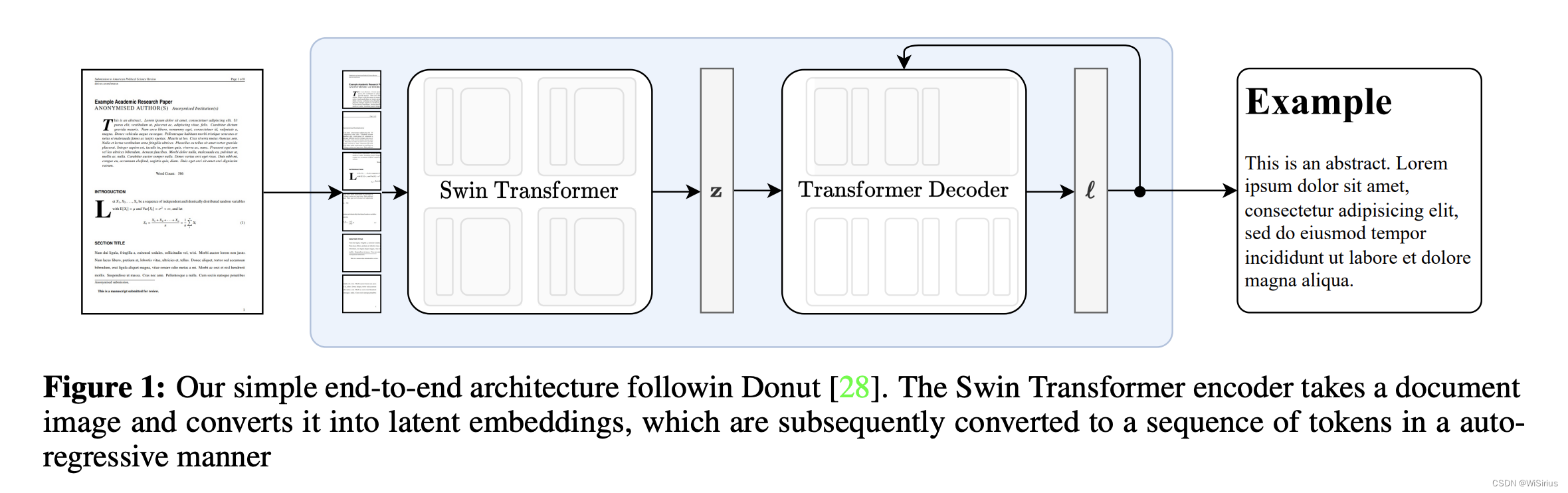
1. encoder
視覺encoder首先接受一張文檔圖像,裁剪邊距并調整圖像大小成固定的尺寸(H,W);如果圖像小于矩形,那么增加額外的填充以確保每個圖像具有相同的維度。encoder使用了Swin Transformer,將圖像分為不重疊的固定大小的窗口,然后應用一系列的自注意力層來聚集跨窗口的信息。該模型輸出一個embedding patch(d*N),其中d是隱層維度,N是patch的數目。
2. decoder
使用帶有cross-attention的mBART解碼器解碼(d*N),生成一系列tokens,tokens以自回歸方式生成,使用自注意力和交叉注意力分別關注輸入序列和編碼器輸出的不同部分,最后tokens被投影到vocabulary的大小,產生logits。
3. set
以 96 DPI 的分辨率渲染文檔圖像。由于 Swin Transformer 的限制性可能輸入維度,選擇輸入大小 (H, W ) = (896, 672)。使用預訓練的權重初始化模型。Transformer decoder的最大序列長度為 S = 4096。這種相對較大的尺寸是由于學術研究論文的文本可能是密集的,尤其是表格的語法是token密集型的。BART 解碼器是一個具有 10 層的僅解碼器Transformer。整個架構共有 350M 參數。此外還使用較小的模型 (250M 參數) 進行實驗,序列長度略小 S = 3584,只有 4 個解碼器層。
訓練:使用AdamW優化器訓練3個epoch,batch_size是192;由于訓練的不穩定性,選擇lr init = 5·10?5的學習率,每15次更新減少0.9996倍,直到達到lrend = 7.5·10?6。
二、數據增強
在圖像識別任務中,使用數據增強來提高泛化性是有效的。文章應用一系列的transformation來模擬掃描文檔的缺陷和可變性。這些變換包括:腐蝕,膨脹,高斯噪聲,高斯模糊,位圖轉換,圖像壓縮,網格失真和彈性變換(這些變換可以借鑒一下,幾乎包括了所有圖像領域常用的變換)。每個都有一個固定的概率來應用給給定圖像(這一步在訓練前完成)。轉換效果如下:

在訓練過程中,會用隨機替換token的方式給groud truth增加擾動
三、數據
目前沒有pdf頁面和其對應的source code的成對數據集。
根據arxiv上的開源文章,建立了自己的數據集。對于layout多樣性,我們引入了PMC開源非商業數據集的子集。在預訓練過程中,也引入了一部分行業文檔庫數據。
ARXIV
我們從arxiv上收集了174w+的pape,收集其源代碼并編譯pdf。為了保證格式的一致性,首先用latex2html處理源文件,并將他們轉為html文件。然后解析html文件,并將他們轉換為輕量級標記語言,支持標題,粗體和斜體文本、公式,表等各種元素。這樣,我們能保證源代碼格式是正確的,方便后續處理。整個過程如圖

PMC
我們還處理了來自PMC的文章,其中除了PDF文件之外,還可以獲得具有語義信息的XML文件。我們將這些文件解析為與arxiv文章相同的標記語言格式,我們選擇使用PMC少得多的文章,因為XML文件并不總是具有豐富的語義信息。通常,方程和表格存儲為圖像,這些情況檢測起來并非易事,這導致我們決定將PMC文字的使用限制在預訓練階段。
IDL
IDL是行業產生的文檔集合。這個僅用在預訓練階段,用于教模型基本的OCR;
splitting the pages
我們根據pdf的頁中斷來分割markdown標記,然后將每個pdf頁面轉為圖像,來獲得圖像-標記pair。在編譯過程中,Latex會自動確定pdf的頁面中斷。由于我們沒有重新編譯每篇論文的Latex源,我們必須啟發式地將源文件拆分為對應不同頁面的部分。為了實現這一點,我們使用PDF頁面上的嵌入文本和源文本進行匹配。
然而,PDF中的圖像和表格可能不對應他們在源代碼中的位置。為了解決這個問題,我們在預處理階段去掉了這些元素。然后將識別的標題和XML文件中的標題進行比較,并根據他們的Levenshtein距離進行匹配。一旦源文檔被分成單個頁面,刪除的圖形和表格就會在每個頁面的末尾重新插入。
四、實驗評估
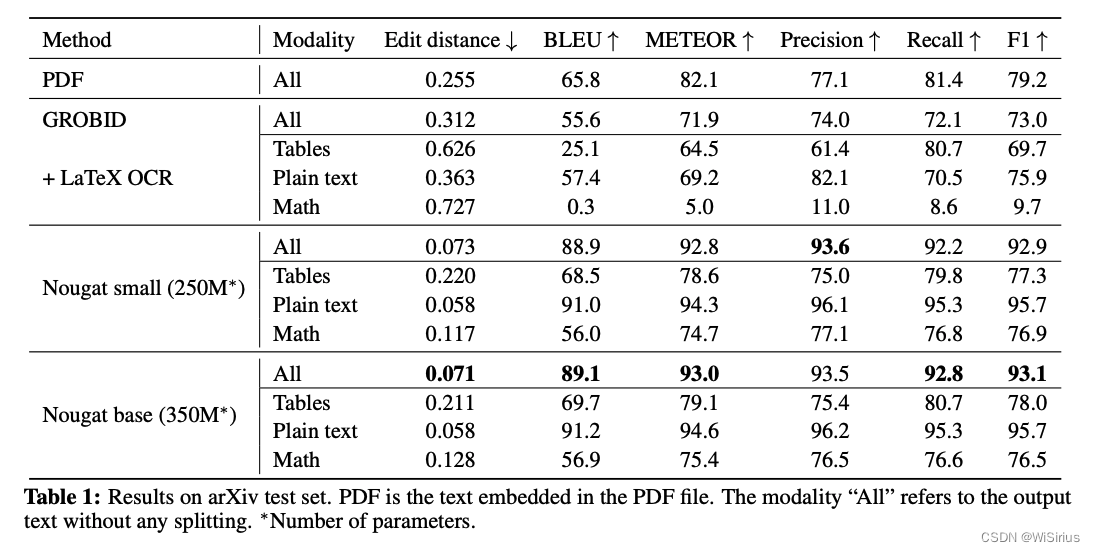
在一篇科研文章中,存在三種不同類型的文本:1) 純文本,占文檔的大部分;2) 數學表達式;3) 表格。在評估過程中,檢查這三個部分中的每一個都很重要。這是因為在LaTeX中,表達同一個數學表達式有多種方式。盡管在LaTeXML預處理步驟中消除了一些可變性,但仍然存在大量歧義,這種歧義降低了數學和純文本的得分。數學表達式的預期得分低于純文本。
repetitions during inference
我們觀察到模型會退化為一遍又一遍地重復相同的句子。模型無法自行從這種狀態中恢復過來。在最簡單的情況下,最后一個句子或段落被不斷地重復(在大模型中也經常出現)。我們在測試集中的1.5%頁面觀察到了這種行為,但領域外文檔的頻率會增加。陷入重復循環是使用貪婪解碼采樣時基于Transformer模型的一個已知問題。模型也可能在兩個句子之間交替,但有時會改變一些單詞,因此嚴格的重復檢測是不夠的。作者提出在訓練過程中引入隨機擾動以增強模型對錯誤預測標記的處理能力,以及在推理時檢測和處理重復的方法,但是仍然無法根本解決這類問題,這也讓模型的實用性受到限制。
個人認為有兩種方法可以降低重復和幻覺:
1. 輸出添加位置信息的預測,比如TextMonkey和mPlug-DocOwl1.5都把text grounding任務做為下游任務進行微調,在消融實驗里也提到了增加文本位置預測可以顯著降低模型輸出的幻覺;2. 降低圖像里文本的數量,在圖片中文本數量較少時,一般不容易出現重復和幻覺,所以可以按上篇文章提到的辦法,將圖片劃分為多個block,再對單個block訓練對應的端到端識別模型,這樣也可以解決模型輸出的重復問題
五、代碼
1. 環境安裝
按照github教程安裝即可,但注意transformer庫的版本, 如果transformer版本可能會報錯:
TypeError: BARTDecoder.prepare_inputs_for_inference() got an unexpected keyword argument ‘cache_position’
由于Nougat自己寫了“prepare_inputs_for_generation”,而與最新版本的transformers實現不同。因此應該在Nougat中安裝舊版本的transformers,例如transformers==4.38.2是沒有問題的。
2. Dataset(dataset.py)
主要函數:NougatDataset —— return input_tensor, input_ids, attention_mask
input_tensor: 圖像經過預處理后的輸入編碼
input_ids: 文本信息經過tokenizer處理后的id
attention_mask: input_ids對應的mask
依賴函數:SciPDFDataset——return {“image”: img, “ground_truth”: data.pop(“markdown”), “meta”: data}
數據格式:

簡單來說,SciPDFDataset輸出一個樣本的基本信息,NougatDatase則輸出模型可直接訓練的信息。
3. Model(model.py)
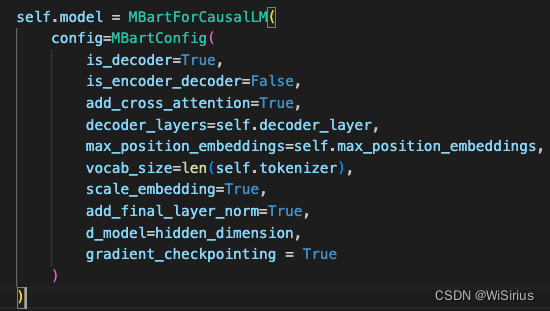
Swintransformer基于timm構建,Bart基于transformer構建。有個小技巧,如果訓練顯存太大,可以嘗試在編碼器解碼器中添加一個參數
編碼器中添加 —— use_checkpoint=True

解碼器中添加 —— gradient_checkpointing=True
總結
Nougat嘗試用一個端到端的方式來實現過去無數小模型+策略配合的結果。確實效果很驚艷,但其缺點也十分明顯:
推理速度慢。雖然過去的pipeline設計多個模型,但每個模型都非常輕量化,組合起來的參數量甚至不到Nougat的1/10。
定制化難。
數據集構建成本高。(但是nougat的數據工程確實也很驚艷,非常值得學習!!!)
訓練成本高。主要體現在機器成本,需要更多的GPU,更長的訓練時間。
優化成本高。Nougat作為一種端到端的解決方法無法針對特定的badcase進行優化。比如在傳統方案中,如果表格OCR這個模塊效果較差單獨優化即可,不會影響到其它模塊。但用端到端的方案,當構建傾向表格的數據時,可能會導致其它場景出現新的badcase。










)

添加文字)






