論文筆記
資料
1.代碼地址
https://github.com/jo-wang/otta_vit_survey
2.論文地址
https://arxiv.org/abs/2310.20199
3.數據集地址
1論文摘要的翻譯
本文介紹了在線測試時間適應(online test-time adaptation,OTTA)的全面調查,OTTA是一種專注于使機器學習模型適應批量到達時的新數據分布的新方法。盡管最近OTTA方法得到了廣泛應用,但該領域仍陷入了諸如模糊設置、過時的主干網絡和不一致的超參數調優等問題,這些問題混淆了真正的挑戰,并使可重復性難以捉摸。為了清晰和嚴格的比較,我們將OTTA技術分為三個主要類別,并使用強大的視覺轉換(ViT)主干對它們進行基準測試,以發現真正有效的策略。我們的基準涵蓋了傳統的損壞數據集,如CIF AR-10/100C和ImageNet-C,以及CIF AR-10.1和CIF AR-10-Warehouse中體現的真實變化,通過擴散模型封裝了搜索引擎和合成數據的變化。為了衡量在線場景中的效率,我們引入了新的評估指標,包括GFLOPs,揭示了適應精度和計算開銷之間的權衡。我們的研究結果與現有文獻不同,表明:(1)變壓器對不同的域位移表現出更高的彈性;(2)許多OTTA方法的有效性取決于充足的批量;(3)優化的穩定性和對擾動的抵抗在適應過程中至關重要,特別是當批量大小為1時
在這些見解的激勵下,我們指出了未來研究的有希望的方向。
2問題背景
這里主要介紹問題的定義,并介紹了廣泛使用的數據集、指標和應用。并且提供OTTA的正式定義,并深入研究其基本屬性。此外,我們探索了廣泛使用的數據集和評估方法,并研究了OTTA的潛在應用場景。進行比較分析,以區分OTTA與類似的設置,以確保清晰的理解
2.1問題定義
2.2 數據集介紹
2.2.1 CIFAR-10-C
圖像分類的標準基準。它包含950,000張彩色圖像,每張32 × 32像素,跨越10個不同的類。CIF AR10-C保留了CIF AR-10的分類結構,但納入了15種不同的損壞類型,嚴重程度從1級到5級不等。這種損壞的變體旨在模擬在圖像采集、存儲或傳輸等過程中可能出現的真實圖像失真或損壞。
2.2.2 CIFAR-100-C
95萬張32 × 32像素的彩色圖像,均勻分布在100個獨特的類別中。CIF AR-100損壞數據集,類似于CIF AR-10-C,將人工損壞集成到規范的CIF AR-100圖像中。
2.2.3 ImageNet- c
ImageNet測試集的損壞版本。由ImageNet-1k生成,ImageNet-C有19種類型的損壞域,包括4種驗證損壞。對于每個領域,產生了5個嚴重級別,每個嚴重級別有來自1000個類的50,000個圖像。
以上數據集人為創建的領域差異
以下數據集是現實世界的實驗基準
2.2.4 CIFAR-10.1
具有與CIFAR-10相同標簽空間的真實測試集。它包含大約2000張從Tiny Image數據集采樣的圖像
2.2.5 CIFAR-10-Warehouse
集成了來自兩種擴散模型的圖像,特別是穩定擴散,以及七個流行搜索引擎的目標關鍵字搜索。包含37個生成數據集和143個真實數據集,每個子集有300到8000張圖像,在不同的搜索標準中顯示出明顯的類內變化。
2.3 評估指標
2.3.1 Mean error
它計算所有損壞類型或域的平均錯誤率。
雖然有用,但這個指標通常不能在OTTA中提供特定于類的見解。
2.3.2 GFLOPs
指每秒千兆次浮點運算,它量化了一個模型在一秒鐘內執行的浮點運算次數。GFLOPs越低的模型計算效率越高
2.3.3 Number of updated parameter
提供了對適應過程復雜性的見解。需要大量更新參數的模型可能不適合在線自適應。
2論文的貢獻
- 據我們所知,這是第一次關于在線考試時間適應的重點調查,它提供了對三個主要工作機制的透徹了解。廣泛的實驗調查是在公平的比較環境中進行的。
- 我們在VIT架構下重新實現了具有代表性的Otta基線,并在五個基準數據集上驗證了它們的性能。我們驅動了一組替換規則,使現有的OTTA方法適應新的主干。
- 除了使用傳統的識別精度指標外,我們還通過每秒千兆浮點運算(GFLOPS)進一步提供了對計算效率的各個方面的見解。這些指標在實時流應用中非常重要。
- 雖然現有文獻廣泛探索了OTTA方法在CIFAR-10-C、CIFAR-100-C和ImageNet-C等腐敗數據集上的應用,但我們更感興趣的是它們導航真實世界數據集變化的能力。具體地說,我們評估了OTTA在CIFAR-10-Warehouse,,CIFAR-10-Warehouse,是CIFAR-10的一個新引入的、可擴展的測試集。我們的實證分析和評估導致了與現有調查結果不同的結論。
3 論文方法的概述
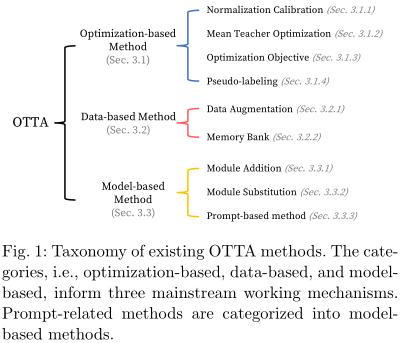
鑒于在線數據與源訓練數據的分布差異,OTTA技術大致分為三類,這取決于它們對兩個主要問題的反應:管理在線數據和緩解由于分布變化而導致的性能下降。基于優化的方法以設計無監督目標為基礎,通常傾向于調整或增強預先訓練的模型。基于模型的方法著眼于修改或引入特定的層。另一方面,基于數據的方法旨在擴大數據多樣性,要么改善模型泛化,要么協調數據視圖之間的一致性。這里的方法可以看到會不類所使用的方法。
3.1 Optimization-based OTTA
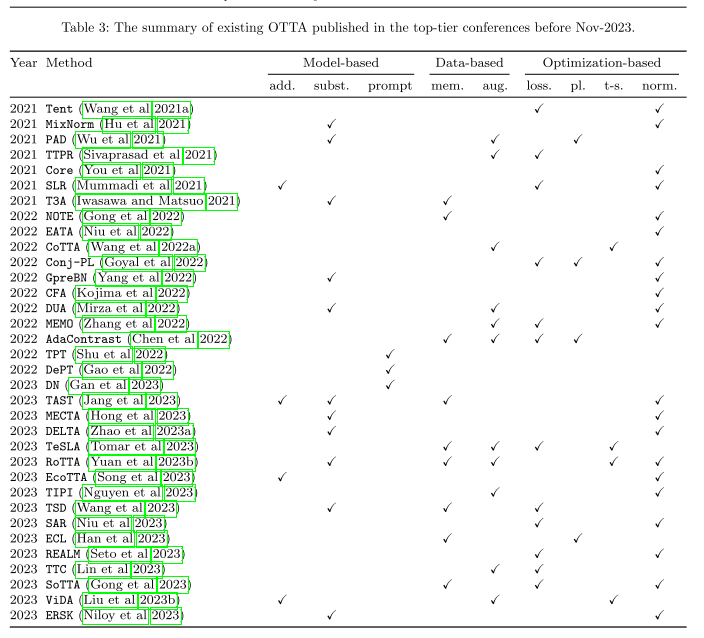
三個子類 (1) recalibrating statistics in normalization layers, (2) enhancing optimization stability with the mean-teacher model(3) designing unsupervised loss functions 下圖為上述策略發展實踐線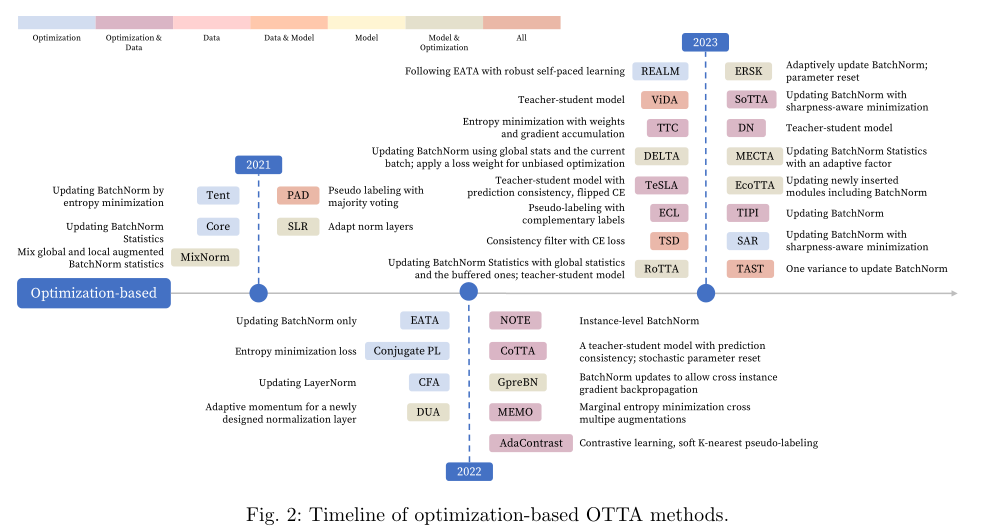
3.1.1 Normalization Calibration
Tent
3.1.2 Mean Teacher Optimization
RoTTA
這種方法涉及使用預先訓練的源模型來初始化教師模型和學生模型。對于任何給定的測試樣本,都會創建弱和強增強版本。然后,每個版本都由學生和教師模型進行相應的處理。這種方法的關鍵在于使用預測一致性,也稱為一致性正則化,來更新學生模型。該策略旨在從不同的數據視圖實現相同的預測,從而降低模型對測試數據變化的敏感度,并提高預測的穩定性。
教師模型被改進為學生在迭代中的移動平均值。值得注意的是,在OTTA中,Mean教師模型和基于BatchNorm的方法并不是相互排斥的;事實上,它們可以有效地集成在一起。將BatchNorm更新納入教師-學生學習框架可以產生更穩健的結果第四節。同樣,Mean-Teacher模型與以數據為中心(如3.2小節所述)的集成。或模型驅動(詳見第節3.3)的方法為進一步提高OTTA的預測精度和穩定性提供了希望,標志著該領域向前邁出了重要的一步。
- Model updating strategies.
遵循均值-教師學習的思想,ViDA利用教師的預測和增加的輸入來監控學生的輸出。它還引入了更新的高/低等級適配器,以適應持續的OTTA學習。
3.1.3 Optimization Objective
在測試數據數量有限的情況下,設計合適的優化目標是非常重要的。圖4總結了常見的基于優化的在線測試時間適應(OTTA)。現有文獻使用以下三種主要策略來解決優化問題。
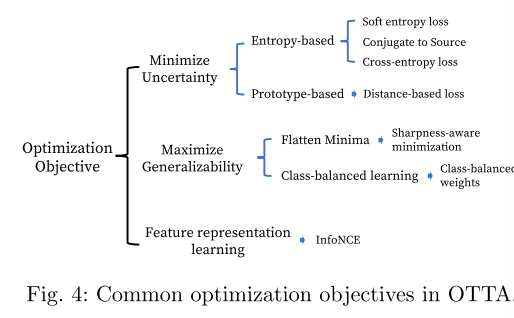
- 策略1:Optimizing (increasing) confidence
一種直觀的方法是增強模型對測試數據的置信度- Entropy-based confidence optimization
該策略通常旨在最小化Softmax輸出向量的熵: H ( y ^ ) = ? ∑ c p ( y ^ c ) log ? p ( y ^ c ) , ( 5 ) H(\hat{y})=-\sum_cp\left(\hat{y}_c\right)\log p\left(\hat{y}_c\right),\quad(5) H(y^?)=?c∑?p(y^?c?)logp(y^?c?),(5)其中 y ^ c \hat{y}_{c} y^?c?是第c個預測類, p ( y ^ c ) p(\hat{y}_{c}) p(y^?c?)是其對應的預測概率。直觀地說,當預測的熵減少時,向量看起來會更尖銳,此時置信度或最大置信度會增加。
在OTTA中,這種優化方法將在不依賴標簽的情況下增加對當前批次的模型置信度,并提高模型精度。
有兩種工作方式。一種考慮整個Softmax向量;另一種利用輔助信息并使用Softmax輸出的最大條目。Tent是前者的一種典型方法。 - Prototype-based
基于原型的學習是一種常用的無標簽數據策略,通過為每個類別選擇代表性或平均值,并根據基于距離的度量對無標簽數據進行分類。然而,在分配變化的情況下,其有效性可能會受到限制。為了尋找可靠的原型,TSD(使用基于香農熵的過濾器從具有高置信度的目標樣本中找到類原型。然后,如果目標樣本最近的原型與來自同一分類器的其類別預測一致,則使用目標樣本來更新感興趣的分類器。
- Entropy-based confidence optimization
- 策略二:Feature representation learning.
由于測試數據沒有假設任何注釋,對比學習自然可以用于測試時間適應任務。在一種自我監督的方式中,對比學習是學習一種特征表示,其中正對(數據樣本及其擴充)接近,而負對(不同數據樣本)彼此推開。然而,這需要多紀元更新,這違反了在線適應設置。為了適應在線學習,AdaContrast使用了目標偽標簽來忽略潛在的同類負樣本,而不是將所有其他數據樣本視為負樣本。
3.1.4 Pseudo-labeling
偽標記技術在領域自適應和半監督學習中是一種有用的技術。它通常以高置信度為樣本分配標簽,然后使用這些偽標簽樣本進行訓練。在OTTA中,適應僅限于當前批次的測試數據,經常使用批次級別的偽標記。例如,MuSLA實現了偽標簽,作為BatchNorm更新后的優化步驟。這種方法使用當前批次的偽標簽來改進分類器,從而提高了模型的準確性。
此外,teacher-student框架,如COTTA、Rotta和Vida等模型也采用了偽標簽策略,其中teacher輸出被用作軟偽標簽。由于在反向傳播過程中保持了不確定性,這可以防止模型被過度擬合以適應錯誤的預測。
- Reliable pseudo labels
在OTTA的中使用這一可靠的偽標簽策略,這是特別具有挑戰性的。一方面,由于連續數據流的使用,我們數據利用的機會有限。另一方面,源和測試集之間的協變量差異會顯著降低偽標簽的可靠性。
為了應對這些挑戰,TAST采用了基于原型的偽標簽策略。該算法首先將原型作為支持集中的類質心,支持集首先由源預先訓練好的分類器的權值得到,然后利用測試數據的歸一化特征進行細化和更新。為了避免不可靠的偽標簽帶來的性能下降,該算法只利用附近的支持度樣本來計算質心,然后使用溫度縮放的輸出來獲得偽標簽。或者,AdaContrast在特征空間中使用軟K近鄰投票來為目標樣本生成可靠的偽標簽。另一方面,Wu等人(2021)提出使用多重擴充和多數投票來獲得一致和可信的偽標簽。
3.1.5 其他方法
LAME:
3.1.6 小結
基于優化的方法是在線測試時間適應中最常見的類別,獨立于神經體系結構。這些方法集中于確保優化中的一致性、穩定性和健壯性。然而,這些方法的一個基本假設是有足夠的目標數據可用,這應該反映全局測試數據分布。關于這一方面,下一節將重點介紹基于數據的方法,研究它們如何解決OTTA中缺乏可訪問的目標數據的問題。
3.2 Data-based OTTA
由于測試批次中的樣本數量有限,經常會遇到出現意外分布變化的測試樣本。我們承認,數據可能是彌合源數據和測試數據之間差距的關鍵。在本節中,我們將更深入地探討以OTTA中的數據為中心的策略。我們重點介紹了數據的各個方面,例如每批中的數據多樣化(3.2.1節)和在全局范圍內保存高質量信息(3.2.2節)。這些策略可以增強模型的泛化能力,并針對當前的數據批次定制模型的識別能力。
3.2.1 Data Augmentation
數據增強在域適應和域泛化中非常重要,它們模仿真實世界的變化,以提高模型的可轉移性和泛化能力。它對于測試時間適應特別有用。
- Predefined augmentations
常見的數據增強方法,如裁剪、模糊和翻轉,被有效地整合到各種OTTA方法中。這種整合的一個例子是TTC,它使用來自多次擴充的平均預測來更新模型。另一種場景來自平均教師模型,例如Rotta、Cotta和ViDA,將預定義的擴充應用于教師/學生輸入,并在不同的擴充視圖上保持預測一致性。
為了確保一致和可靠的預測,PAD采用了對單個測試樣本的多次擴充進行多數投票。這是基于這樣一種信念,即如果大多數增強的視圖產生相同的預測,那么它很可能是正確的,因為它表明了對風格變化的不敏感。相反,TTPR采用KL發散來實現一致的預測。對于每個測試樣本,它都會生成三個增強版本。然后,通過將這些增強視圖上的平均預測與每個視圖的預測對齊來改進模型。另一種方法是Memo,它使用AugMix來測試圖像。對于測試數據點,將生成來自AugMix pool A \mathcal {A} A的一個范圍(通常為32或)64的增量,以做出一致的預測。 - Contextual Augmentations
OTTA方法通常預先確定增強策略。考慮到測試分布在不斷發展的環境中可能經歷很大的變化,存在這樣的風險,即這種固定的擴充策略可能不適合每一個測試樣本。在COTTA中,不是通過統一的策略來擴大每個測試樣本,而是只有在檢測到領域差異(即低預測置信度)時才明智地應用擴大,從而降低誤導模型的風險。 - Adversarial Augmentation
傳統的增強方法總是提供有限的數據視圖,而不能完全表示領域差異。TeSLA遠離了這一點。相反,它利用對抗性數據增強來確定最有效的增強策略。它不是固定的擴充集,而是創建一個策略搜索空間O作為擴充池,然后為每個擴充分配一個幅度參數 m ∈ [ 0 , 1 ] m\in[0,1] m∈[0,1]。子策略由增量 ρ ρ ρ及其相應的大小組成。為了優化策略,教師模型使用具有嚴重程度正則化的熵最大化損失來適應,以鼓勵預測變化,同時避免增強太強而不能遠離原始圖像。
3.2.2 Memory Bank
除了可以使數據批次多樣化的擴充策略之外,內存庫還是一個強大的工具,可以為未來的內存重播保留有價值的數據信息。設置內存庫涉及兩個關鍵注意事項:(1)。確定哪些數據應該存儲在內存庫中。這需要在適應期間對確定可能有價值的樣本放入。(2)。內存庫的管理。這包括添加新實例和從庫中刪除舊實例的策略。
內存庫策略通常分為time-uniform和class-balanced兩類。值得注意的是,許多方法選擇將這兩種類型集成在一起,以最大化有效性。為了解決以上策略問題帶來的挑戰,Note引入了Prediction-Balanced Reservoir Sampling (PBRS)來保存樣本-預測對。PBRS的獨創性在于它融合了兩種截然不同的抽樣策略:time-uniform和class-balanced。time-uniform的方法,reservoir sampling(RS),目的是在時間流上獲得統一的數據。具體地說,對于被預測為類 k k k的樣本 x x x,我們從均勻分布 [ 0 , 1 ] [0,1] [0,1]中隨機抽樣值 p p p。然后,如果 p p p小于類 k k k在整個內存庫樣本中的比例,則從相同的類中隨機選擇一個,并用新的 x x x替換它。相反,預測一致節省策略(PB)對預測的標簽進行優先排序,以確定內存中的多數類。在識別后,它用新的數據樣本取代從多數類中隨機選擇的實例,從而確保表示的均衡性。Sotta也采用了類似的策略來促進班級平衡學習。當存儲體具有可用空間時,存儲每個高置信度樣本-預測對。如果銀行已滿,則該方法選擇替換來自多數類之一的樣本,或者如果樣本屬于多數類,則選擇替換來自其類的樣本。這確保了更公平的班級分配,并加強了針對班級不平衡的學習過程。
3.2.3 小結
基于數據的技術對于處理可能有偏見或具有獨特風格約束的在線測試集特別有用。然而,這些技術經常增加計算需求,在在線場景中構成挑戰。
3.3 Model-based OTTA
Model-based OTTA一類的方法主要專注于調整模型體系結構以應對分布變化。對體系結構進行的更改通常涉及添加新組件或替換現有神經網絡塊。它涉及adapting prompt parameters方法或使用 prompts 來引導適應過程.
3.3.1 添加模塊
- Input Transformation
一般在模型的頂部這里的模型 - Adaptation Module
為了在模型更新期間穩定預測,TAST將20個適應模塊集成到源預訓練模型。基于BatchEnSemble,這些模塊被附加到預先訓練的特征抽取器的頂部。通過將它們的平均結果與用于一批數據的相應偽標簽合并來獨立地多次更新自適應模塊。
在不斷適應的情況下,及時檢測和適應數據分布的變化是不可避免的,以應對災難性的遺忘和錯誤的積累。為了實現這一點,Vida利用了低/高階特征合作的思想。低階特征保留通用共的知識,而高階級特征更好地捕捉分布變化。為了獲得這些特征,作者引入了兩個相應地并行于線性層的適配器模塊(如果主干模型是ViT)。此外,由于連續OTTA的分布變化是不可預測的,戰略性地組合低/高等級信息是至關重要的。在這里,作者使用MC Dropout來評估關于輸入x的模型預測不確定性。然后,這種不確定性被用來調整賦予每個特征的權重。直觀地說,如果模型對樣本不確定,則領域特定知識(高等級特征)的權重增加,反之,領域共享知識(低等級特征)的權重增加。這有助于模型動態識別分布變化,同時保留其決策能力。
3.3.2 修改模塊
層替換通常是指將模型中的現有層替換為新層。常用的技術包括:
- Classifier
基于余弦距離的分類器通過利用與代表性示例的相似性來進行決策,從而提供了極大的靈活性和可解釋性。利用這一點,TAST通過評估樣本特征和支持集之間的余弦距離來制定預測。TSD使用了類似的分類器,根據來自記憶庫的K最近鄰居的特征來評估當前樣本的特征。PAD在其多數投票過程中使用余弦分類器來預測擴大的測試樣本。T3A依靠支持集中的模板和輸入數據表示之間的點積進行分類。在更新BatchNorm統計數據的情況下,對BatchNorm進行的任何超出標準更新方法的更改都可以歸入這一類別。這包括Mecta Norm、MixNorm、RBN和GpreBN等技術。為了保持重點和避免冗余,本節將不再廣泛介紹這些具體方法及其復雜的細節。
3.3.3 基于提示的方法
視覺語言模型的興起展示了它們在零次學習泛化方面的非凡能力。然而,對于特定于領域的數據,這些模型往往表現不佳。在試圖解決這一問題時,傳統的微調策略通常會通過改變模型的參數來損害模型的泛化能力。
相對應的,借鑒了TTA的思想,Test Time Prompt Tuning作為一種解決方案應運而生。與傳統方法不同,它對提示進行了微調,只調整了模型輸入的上下文,從而保留了模型的泛化能力。其中一個代表是TPT。它生成每個測試圖像的N個隨機增加的視圖,并通過最小化平均預測概率分布的熵來更新提示參數。另外,提出了一種置信度選擇策略來濾除高熵的輸出,以避免不可信樣本帶來的噪聲更新。通過更新提示符的可學習參數,可以更容易地使模型適應新的、不可見的領域。
與提示相關的想法在OTTA任務中也很強大。Decorate the Newcomers(Dn)使用提示作為添加到圖像輸入上的補充信息。為了給提示注入相關信息,它采用了學生-教師框架和凍結的源預先訓練模型來捕獲領域特定和領域不可知的提示。為了獲取特定領域的知識,它優化了教師和學生模型輸出之間的交叉損失。此外,DN引入了參數不敏感度損失,以減輕容易發生域移的參數的影響。該策略旨在確保對領域變化不太敏感的更新參數有效地保留與領域無關的知識。通過這種方法,域名系統在學習新的、特定于領域的信息的同時,保持關鍵的、與領域相關的知識。
這里有一種新的方法(DEPT)。它的過程首先將transformer分割成多個階段,然后在每個階段的初始層結合圖像和CLS令牌引入可學習的提示。在適應過程中,DEPT使用mean-teacher模型來更新學生模型中的可學習提示和分類器。對于學生模型,基于計算的偽標簽和來自強增廣的學生輸出的輸出之間的交叉熵損失進行更新。值得注意的是,這些偽標簽是從學生模型中生成的,使用記憶庫中學生弱增強輸出的前k個最近鄰居的平均預測。在師生互動方面,為了應對不正確的偽標簽帶來的潛在錯誤,DePT在學生和教師模型的強增強觀點所做出的預測之間實現了熵損失。此外,該方法在transformer的輸出層最小化了學生和教師模型的組合提示之間的均方誤差。此外,為了確保不同的提示集中在不同的功能上,并防止瑣碎的解決方案,系還最大化了學生組合提示之間的余弦距離。
3.3.4 小結
基于模型的OTTA方法已顯示出有效性,但不如其他組流行,這主要是因為它們依賴于特定的主干架構。例如,模型中主要基于BatchNorm的層替換使得它們不適用于基于ViT的體系結構。
這一類別的一個關鍵特征是它與激勵策略的有效整合。這種組合允許更少但更有影響力的模型更新,從而帶來更大的性能改進。這樣的效率使得基于模型的OTTA方法特別適合于復雜場景。
4 實證研究
在這項實證研究中,我們專注于升級現有的用于視覺變壓器(ViT)模型的OTTA方法,調查它們遷移到新一代主干的潛力。我們提供了使最初為CNN架構提出的方法適應ViTS的解決方案。基線。我們對七種Otta方法進行了基準測試。為了確保公平性,我們堅持標準化的測試協議,選擇了五個數據集,包括三個損壞的數據集(即CIFAR-10-C、CIFAR-100-C和ImageNetC)、一個真實世界移動的數據集(CIFAR-10.1)和一個綜合數據集(CIFAR-10-Warehouse)。CIFAR-10-Warehouse知識庫在我們的評估中發揮了關鍵作用,提供了廣泛的子集,包括來自不同搜索引擎的真實世界變體和通過擴散過程生成的圖像。具體地說,我們的調查集中在CIFAR-10-Warehouse數據集的兩個子集上:Google Split和Diffsion Split。這些子集既包括真實世界的數據轉移,也包括人工數據轉移,有助于對OTTA方法的全面評估。
4.1 實現細節
所有方法的基礎主干都是VIT-BASE-patch16-224 當使用CIFAR-10-C、CIFAR-10.1和CIFAR-10-Warehouse作為目標域時,我們在CIFAR-10上訓練源模型,迭代8,000次,包括跨越1,600次迭代的預熱階段。訓練使用批量和隨機梯度下降算法,學習率為 3 e ? 2 3e?2 3e?2。CIFAR-100上的源模型,延長的訓練持續時間為16,000次,熱身期跨越4,000次。ImageNet-1k數據集上的源模型是從TIMM存儲庫獲取的。此外,我們在所有方法中應用了基本的數據增強技術,包括隨機調整大小和裁剪。ADAM優化器的動量項 β \beta β為0.9%,學習率為 1 e ? 3 1e?3 1e?3,確保了適應期間的一致性。調整大小和裁剪技術被應用為所有數據集的默認預處理步驟。然后,采用均勻歸一化(0.5,0.5,0.5)來消除算法核心操作之外的外部因素引起的潛在性能波動。
- 組件替換
為了成功調整核心方法以與Vision Transformer(VIT)配合使用,我們制定了一系列策略:- 切換到LayerNorm
鑒于VIT中沒有BatchNorm層,我們用LayerNorm更新替換所有BatchNorm更新。 - Disregard BatchNorm mixup
去除統計混合策略最初是為基于BatchNorm的方法設計的,因為LayerNorm是為了獨立地對每個數據點進行歸一化而設計的。 - Sample Embedding Changes
去除統計混淆策略最初是為基于BatchNorm的方法設計的,因為LayerNorm是為了獨立地對每個數據點進行歸一化而設計的。 - Pruning Incompatible Components
應識別并刪除與VIT框架不一致的任何要素。
- 切換到LayerNorm
這些策略為將核心OTTA方法與Vision Transformer集成奠定了基礎,從而擴大了它們在這一高級模型體系結構中的應用。值得注意的是,這些解決方案并不僅限于Otta方法。相反,它們可以被視為一套更廣泛的指導原則,可以應用于需要升級到新一代主干架構的地方。
基線:我們仔細選擇了七種方法,以徹底檢查OTTA方法的適應性。它們包括:
- Tent
一種根植于BatchNorm更新的基本Otta方法。為了在ViTs上重現它,我們用LayerNorm更新策略替換了它的BatchNorm更新。 - CoTTA
采用Mean-Teacher模型、參數重置和選擇性擴充策略。雖然它需要更新整個學生網絡,但我們進一步評估了LayerNorm更新學生模型的策略。我們還解構了它的參數重置策略,得到了四種變體:參數重置加層范數更新(COTA-LN)、參數重置加完全網絡更新(COTA-ALL)、更新層范數而不重置參數(COTA?-LN)和完全網絡更新而不重置參數(COTA?-ALL)。 - SAR
遵循與Tent相同的策略,同時使用清晰度感知最小化進行優化。 - Conj-PL
作為通過交叉點損失優化的源模型,它類似于Tent,但允許模型與數據交互兩次:一次用于更新LayerNorm,另一次用于預測。 - MEMO
考慮了兩種不同版本的Memo:完全模型更新和LN更新。我們將所有數據規格化從其增強集中刪除,以保持一致性并防止意外的性能變化。 - RoTTA
由于VITS的體系結構限制,我們在ROTTA中排除了RBN模塊。由于VIT中的LayerNorm是為在樣本級別處理數據而設計的,因此RBN模塊不適用。 - TAST
我們使用第一維的類嵌入作為特征表示,以適應VIT體系結構。
盡管有很多Otta方法,徹底評估這個選定的子集即可。在實證研究中,我們解決了以下關鍵研究問題
4.2 OTTA方法在ViT基礎上有效?
為了評估所選方法的有效性,我們將它們與僅限來源(即直接推斷)的基線進行比較。在接下來的部分中,我們將討論每個數據集的實驗結果。
4.2.1 在 CIFAR-10-C and CIFAR-10.1 基準
我們評估了批次大小為1和16的CIFAR-10-C和CIFAR-10.1數據集,并在圖8中顯示了結果。為了清楚地理解預測模式,我們從三個方面討論了我們的觀察結果:1)損壞類型的變化,2)批次大小的變化,3)適應策略的變化。
- Corruption類型。如圖8和圖15所示,一個值得注意的觀察是,大多數方法都經歷了帶有噪聲破壞的高錯誤率,而與它們的批次大小無關。然而,對于其他一些類型的腐敗,這些方法表現出了合理的性能。

這些不同可能歸于噪聲破壞的隨機性和不可預測性,而不是更結構化的類型,如雪花、變焦或亮度,這些類型可能更易于在線適應。
此外,適應噪聲破壞對基于置信度優化的方法(3.1.3節),與批次大小無關。這一困難可能與前面討論的噪聲模式的顯著的磁區間隙和不可預測的性質有關。盡管這些策略旨在增加模型的信心,但它們并不具備直接糾正錯誤預測的能力。 - Batch Size
批次大小的變化不會顯著改變平均誤差,但Tent、Conj-CE和Memo例外。如SEC中所觀察到的。在4.4節,我們得出結論,對于純粹基于優化的方法,較大的批量可以穩定損失優化,從而有利于適應。然而,納入預測可靠性的考慮可以大大減輕小批量施加的限制,這在COTTA、TAST和SAR等方法中得到了證明。在CIFAR-10.1中也觀察到了類似的模式,其中兩種基于熵的方法在小批量時顯示出局限性。 - Adaptation Strategy
SAR和ROTTA表現出穩定的性能,不受域或批次大小變化的影響。Rotta中的內存庫有助于維護全局信息,使其更具批次不可知性。從另一個角度來看,SAR實現了平坦的極小值,這確保了模型的穩定性優化,并防止了自適應過程中的偏向學習。MEMO在某些領域也表現出令人印象深刻的性能,即使批次大小只有1。
4.2.2 關于 CIFAR-100-C 基準
在CIFAR-100-C數據集上的性能表現出與在CIFAR-10-C數據集上觀察到的類似的趨勢。為了確保討論的重點,只有當它們的性能模式與CIFAR-100-C數據集的性能模式明顯不同時,我們才會探索具體的適應策略。值得注意的是,CIFAR-100-C上的性能相對較差,特別是在使用批次大小為16的情況下。這種性能下降可能是由于CIFAR-100-C數據集中的更大復雜性和多樣性,其中包括更廣泛的類。
- Adaptation Strategy
COTTA在大多數類型的腐敗中表現出明顯的有效性下降,特別是在批次大小為16的情況下。這種性能下降可以部分歸因于大量的類,例如,相比于CIFAR-10-C中的10類和CIFAR-100-C中的100類。此外,隨機參數重置可能導致新獲得的關于這些不同領域的知識的丟失。同樣SAR開始表現出局限性,特別是在存在噪聲失真的情況下,如高斯噪聲、鏡頭噪聲和脈沖噪聲。一個有趣的觀察是對比腐敗領域的性能下降。在這里,Rotta是唯一一種始終優于直接推斷的方法,與批次大小無關。這凸顯了有效保存有價值的樣本信息的重要性,特別是對于處理對批次敏感和具有挑戰性的適應任務而言。在圖10中也可以觀察到類似的趨勢。

4.2.3在Imagenet-C基準上
- Adaptation Strategy
對于圖10中描述的ImageNet-C數據集,當批大小設置為16時,SAR、Conj-CE和ROTTA在平均誤差方面優于僅源模型。相比之下,Tent、Memo和Cotta表現出明顯的糟糕結果。值得注意的是,Conj-CE為最終預測的每一批進行額外的推斷,在大多數領域和平均誤差上明顯超過Tent。這表明ImageNet-C存在顯著的批次間分布變化,例如樣式或類別差異,這表明基于優化當前批次來預測下一批次的策略不太有效。此外,在標簽集復雜和數據多樣性顯著的場景中,MEMO面臨著挑戰。COTTA的參數重置也可能對模型的區分能力產生不利影響,特別是在復雜環境中。
當批量減少到1時,只有RoTTA保持其性能水平,這意味著典型的無監督損失函數可能不足以滿足復雜的適應任務。同時,保留有價值的數據可以顯著減少由域轉換引起的性能差異。 - Batch Size
與CIFAR-10-C和CIFAR-100-C相比,ImageNet-C經歷了更明顯的性能下降,特別是當批量減少到1時。這一觀察結果,結合我們對適應策略的分析,表明具有更高復雜性和難度的數據集對批量大小的變化更敏感。 - Corruption Type
相對于CIFAR-10-C和CIFAR-100-C數據集(如圖8和圖9所示),ImageNet-C數據集的一個顯著特點是在各種類型的損壞中性能差距較小。這意味著具有較少類的數據集可能會表現出更大的性能變化,以響應不同的損壞。對于包含1,000個類的ImageNet-C,我們觀察到所有腐敗領域的表現一直很差,可能是由于批次間的巨大差異,這阻礙了有效的學習。

4.2.4 關于CIFAR-10-Warehouse基準
我們在新引入的CIFAR-10-Warehouse數據集上評估OTTA技術,它和CIFAR-10標簽相同。在我們的評估中,我們選擇了CIFAR-10-Warehouse中具有代表性的兩個領域。這些域被專門用來衡量OTTA方法在兩種不同的分布變化下的性能:真實世界變化和擴散合成變化。Google split包括來自谷歌搜索引擎的圖片。這一子集是評估當代OTTA方法在管理現實世界分布變化方面的能力的關鍵基準。我們評估了OTTA在其標記為G-01到G12的12個子域中的性能。每個子域代表以不同主色為主的圖像,提供了一系列不同的視覺場景,以測試OTTA方法在現實世界條件下的適應性和有效性。
-
Batch Size
關于圖11中描述的批次大小差異,我們觀察到,當批次大小為16時,大多數OTTA方法的性能與直接推理相當或超過。這一結果表明,目前的OTTA方法總體上是有效的。此外,大多數OTTA方法的性能在批量減少到1時保持穩定。然而,Tent和Conj-CE等方法在大多數領域表現出性能下降。這可能歸因于單樣本批次優化的不穩定性,特別是在Tent中,它只專注于優化熵。 -
Adaptation Strategy
無論批次大小,ROTTA和SAR都表現出非凡的穩定性。這種穩定性是通過保留ROTTA的高質量數據信息和在SAR的優化中尋求平坦極小來實現的。我們比較了Conj-CE和Conj-Poly,其中Conj-Poly指的是當源訓練前損失為PolyLoss時的適應策略。在我們的實驗中,我們在不改變訓練前損失來源的情況下修改了適應策略,以觀察性能差異。有趣的是,即使當批處理大小設置為1,并且源預訓練損失是交叉熵損失(其中Conj-Poly不是假定的最佳選擇)時,Conj-Poly仍然設法在平均誤差方面優于Conj-CE。這一發現挑戰了Conj-PL原始論文中得出的結論,表明Conj-Poly可能比最初認為的更有效,即使與原始的訓練前損失不一致。 -
Adaptation Strategy
另一個值得注意的觀察是COTTA、SAR和ROTTA的穩定表現。通過采用銳度感知最小化,SAR使模型能夠到達優化環境中對數據變化不那么敏感的區域,從而產生穩定的預測。CONTTA的參數重置策略有效地減輕了偏向適應,允許從源域恢復部分知識,從而有助于其一致的性能,即使在具有挑戰性的DM-05子域中也是如此。最后,ROTTA利用信息豐富的內存庫,在子域之間實現了很好的性能。 -
小結
從我們廣泛的實驗來看,大多數OTTA方法在不同的數據集上顯示出類似的行為模式。這種一致性強調了當代OTTA技術在有效管理不同領域轉移方面的潛力。特別值得注意的是ROTTA和SAR,強調了優化不敏感和信息保存的重要性。
4.3 OTTA是否高效
為了評估OTTA算法的性能,特別是在硬件限制的情況下,我們使用GFLOPS作為度量,如圖13所示。較低的GFLOPS和平均誤差是可取的。我們的觀察表明,Memo取得了較高的性能,但會產生較高的計算成本。相比之下,RoTTA成功地平衡了低錯誤率和高效更新。這還表明,減少批處理大小可能有助于實現性能和計算效率之間的平衡。

4.4 OTTA對超參數選擇是否敏感
批量大小很重要,但僅在一定程度上。圖15在CIFAR-10-C數據集中檢查了不同批次大小對Tent性能的影響。它顯示,在大多數損壞中,性能隨著批處理大小的不同而顯著不同,從1到16。然而,與傳統的BatchNorm設置相比,隨著批次大小的增加(16到128),這種可變性減小,這表明LayerNorm更新對批次大小的影響較小。這種模式在其他數據集中是一致的,如圖14所示。

然而,批次大小仍然至關重要。以穩定優化過程。例如,在CIFAR-10-Warehouse數據集的Google拆分的置信度優化方法中,批次大小為16的性能優于批次大小1。然而,對于像CIFAR-100-C和ImageNet-C這樣的復雜數據集來說,更大的批次大小是必不可少的,在這些復雜數據集中,直接推理很難進行,強調需要根據數據的復雜性來調整批次大小。此外,圖15表明,增加批次大小對諸如高斯和散粒噪聲等具有挑戰性的腐敗現象并不有效。這突出表明,在復雜的學習情況下,有必要采取更先進的適應策略,而不僅僅是調整批量。

- 優化層很重要
為了評估LayerNorm的關鍵作用,我們將基于LayerNorm的優化與完全模型優化進行了比較,如表2所示。本文的消融研究主要集中在COTA和MEMO上,單獨評估了優化LayerNorm的影響。值得注意的是,對于所有方法,LayerNorm更新在獲得高性能方面發揮了重要作用,強調了它通過避免顯著忘記源知識來提高模型性能的有效性。

5 未來方向
我們對Vision Transformer的初步評估顯示,許多在線測試時間適應方法沒有完全針對此架構進行優化,導致結果不是最優的。基于這些發現,我們為理想的OTTA方法提出了幾個關鍵屬性,適用于未來的研究并針對VIT等高級體系結構進行了定制
- 在真實環境中細化OTTA
未來的OTTA方法應該在現實環境中進行測試,采用先進的架構、實用的試驗臺和合理的批次大小。這種方法旨在獲得更深入和更相關的見解。 - 應對多模式挑戰并探索激勵技術
隨著向CLIP等基礎模式的演變,OTTA面臨著新的挑戰。這些模式可能會面臨各種模式的變化,這就需要創新的OTTA戰略,超越僅依賴圖像的范圍。探索基于提示的方法可能會在OTTA方面取得重大突破。 - 熱插拔OTTA
跟上主干架構的快速發展是至關重要的。未來的OTTA方法應該關注與不斷發展的體系結構無縫集成的適應性和通用性。 - OTTA算法的穩定和穩健的優化
優化中的穩定性和穩健性仍然是最重要的。鑒于更大的批次大小在ViT中顯示的有效性有限,未來的研究應該調查更普遍的優化改進。這些改進旨在持續提高模型性能,而不受批次大小等外部因素的影響。
6 總結
在這項調查中,我們徹底檢查了在線測試時間適配(OTTA),詳細介紹了現有的方法、相關數據集、評估基準及其實施。綜合實驗評估了現有OTTA方法應用于視覺轉換器的有效性和效率。我們的觀察表明,與其他類型的移位相比,噪聲合成的域移通常會帶來更大的挑戰,例如在真實世界場景或擴散環境中遇到的移位。此外,數據集中存在的大量類可能會導致批次之間的顯著差異,潛在地影響OTTA模型保持一致知識的能力。這可能會導致學習困難和嚴重健忘的風險增加。為了應對這些挑戰,我們發現用記憶庫或優化平坦度更新歸一化層,結合適當的批次大小選擇,可以有效地穩定適應過程并減少遺忘。
知識點
災難性遺忘:災難性遺忘即學習了新的知識之后,幾乎徹底遺忘掉之前習得的內容。
轉載自于:https://blog.csdn.net/u013468614/article/details/95623987

第二十五天 | 134. 加油站、135. 分發糖果、860. 檸檬水找零、406. 根據身高重建隊列)















——監聽器)

-MobileNet為例)