目錄
1.文件的讀取
1.1.目錄
1.2.文件
1.3.目錄樹讀取
1.4.文件系統大小與磁盤讀取性能
2.增添文件
2.1.數據的不一致(Inconsistent)狀態
2.2.日志式文件系統(Journaling filesystem)
3.Linux文件系統的運行
4、文件的刪除
4.1. 刪除文件
?4.2.為什么拷貝文件的時候很慢,而刪除文件的時候很快?
4.3.、文件誤刪后的解決方案
5、大文件存儲
1.文件的讀取
????????我們知道在Linux系統下,每個文件(不管是一般文件還是目錄文件)都會占用一個inode,且可依據文件內容的大小來分配多個區塊給該文件使用。
目錄的內容在記錄文件名,一般文件才是實際記錄數據內容的地方。
我們現在已經了解了Linux的文件系統,那么Linux是如何對文件進行讀取的呢?
1.1.目錄
當我們在Linux下的文件系統建立一個目錄時,文件系統會分配一個inode與至少一塊區塊給該目錄。
其中,inode記錄該目錄的相關權限與屬性,并可記錄分配到的那塊區塊號碼,而區塊則是記錄在這個目錄下的文件名與該文件名占用的inode號碼數據,也就是說目錄所使用的區塊記錄如下的信息:

???如果想要實際觀察root 根目錄內的文件所占用的inode號碼時,可以使用Is-i這個選項來處理:

由于每個人所使用的計算機并不相同,系統安裝時選擇的項目與磁盤分區都不一樣,因此你的環境不可能與我的inode號碼一模一樣,上表的左邊所列出的inode僅是我的系統所顯示的結果而已。
而由這個目錄的區塊結果我們現在就能夠知道,當你使用【|| /】時,出現的目錄幾乎都是1024的倍數,為什么?因為每個區塊的數量都是1K、2K、4K,看一下我的環境:
由于我的根目錄使用的區塊大小為4K,因此每個目錄幾乎都是4K的倍數,其中由于/usr/sbin的內容比較復雜因此占用了3個區塊。
至于奇怪的/proc我們在講過該目錄不占磁盤容量所以當然使用的區塊就是0。
????????由上面的結果我們知道目錄并不只會占用一個區塊而已,也就是說:在目錄下面的文件數如果太多而導致一個區塊無法記錄得下所有的文件名與inode對照表時,Linux會多給該目錄一個區塊來繼續記錄相關的數據。
1.2.文件
當我們在Linux下的ext2建立一個一般文件時,ex2會分配一個inode與相對于該文件大小的區塊數量給該文件。
例如:假設我的一個區塊為4KB,而我要建立一個100KB的文件,那么Linux將分配一個inode與25個區塊來存儲該文件。但同時請注意,由于inode僅有12個直接指向,因此還要需要一個區塊來記錄區塊號碼。
1.3.目錄樹讀取
好了,經過上面的說明你也應該要很清楚地知道inode本身并不記錄文件名,文件名的記錄是在目錄的區塊當中。
????????那么因為文件名是記錄在目錄的區塊當中,因此當我們要讀取某個文件時,就務必會經過目錄的inode與區塊,然后才能夠找到那個待讀取文件的inode號碼,最終才會讀取到該文件的區塊中的數據。
????????由于目錄樹是由根目錄開始讀起,因此系統通過掛載的信息可以找到掛載點的inode號碼,此時就能夠得到根目錄的inode內容,并依據該inode 讀取根目錄的區塊內的文件名數據,再一層一層的往下讀到正確的文件名。
舉例來說,如果我想要讀取/etc/passwd這個文件時,系統是如何讀取的呢?
在我系統上面與/etc/passwd有關的目錄與文件數據如上表所示,該文件的讀取流程為(假
設讀取者身份為dmtsai 這個一般身份用戶):
- 1. /的inode:
通過掛載點的信息找到inode號碼為2的根目錄inode,且 inode 規范的權限讓我們可以讀取
該區塊的內容(有r與x);
- 2./ 的區塊:
經過上個步驟取得區塊的號碼,并找到該內容有etc/目錄的inode 號碼(1310721);
- 3. etc/ 的inode:
讀取1310721號inode 得知zs_108具有r與x的權限,因此可以讀取etc/的區塊內容;
- 4. etc/的區塊:
經過上個步驟取得區塊號碼,并找到該內容有passwd 文件的inode 號碼(1311648);
- 5. passwd 的 inode:
讀取1311648號inode 得知zs_108具有r的權限,因此可以讀取passwd的區塊內容;
- 6. passwd的區塊:
最后將該區塊內容的數據讀出來;

1.4.文件系統大小與磁盤讀取性能
????????另外,關于文件系統的使用效率,當你的一個文件系統規劃得很大時,例如100GB這么大時,由于磁盤上面的數據總是來來去去的,所以,整個文件系統上面的文件通常無法連續寫在一起(區塊號碼不會連續的意思),而是填入式地將數據寫入沒有被使用的區塊當中。
如果文件寫入的區塊真的很分散,此時就會有所謂的文件數據離散的問題發生了。
????????如前所述,雖然我們的ext2在inode處已經將該文件所記錄的區塊號碼都記上了,所以數據可以一次性讀取,但是如果文件真的太過離散,確實還是會發生讀取效率下降的問題,因為磁頭還是得要在整個文件系統中來來去去地頻繁讀取。
????????果真如此,那么可以將整個文件系統內的數據全部復制出來,將該文件系統重新格式化,再將數據給它復制回去即可解決這個問題。
????????此外,如果文件系統真的太大,那么當一個文件分別記錄在這個文件系統的最前面與最后面的區塊號碼中,此時會造成磁盤的機械手臂移動幅度過大,也會造成數據讀取性能的下降。
而且磁頭在查找整個文件系統時,也會花費比較多的時間去查找。
因此,磁盤分區的規劃并不是越大越好,而是要針對您的主機用途來進行規劃才行。
2.增添文件
上一小節談到的僅是讀取而已,那么如果是新建一個文件或目錄時,我們的文件系統是如何處理的呢?
這個時候就得要區塊對照表及inode 對照表的幫忙了。
假設我們想要新增一個文件,此時文件系統的操作是:
- 1.先確定用戶對于欲新增文件的目錄是否具有w與x的權限,若有的話才能新增;
- 2.根據inode 對照表找到沒有使用的inode號碼,并將新文件的權限/屬性寫入;
- 3.根據區塊對照表找到沒有使用中的區塊號碼,并將實際的數據寫入區塊中,且更新inode的區塊指向數據;
- 4.將剛剛寫入的inode與區塊數據同步更新inode對照表與區塊對照表,并更新超級區塊的內容。
一般來說,
- 我們將inode 對照表與數據區塊稱為數據存放區域,
- 至于其他例如超級區塊、區塊對照表與inode 對照表等區段就被稱為元數據(metadata)
因為超級區塊、inode對照表及區塊對照表的數據是經常變動的,每次新增、刪除、編輯時都可能會影響到這三個部分的數據,因此才被稱為元數據。
2.1.數據的不一致(Inconsistent)狀態
在一般正常的情況下,上述的新增操作當然可以順利的完成。
但是如果有個萬一怎么辦?
例如你的文件在寫入文件系統時,因為某些原因導致系統中斷(例如突然的停電、系統內核發生錯誤等的怪事發生時),所以寫入的數據僅有inode對照表及數據區塊而已,最后一個同步更新元數據的步驟并沒有完成,此時就會發生元數據的內容與實際數據存放區產生不一致(Inconsistent)的情況。
既然有不一致當然就得要解決。
????????在早期的ext2文件系統中,如果發生這個問題,那么系統在重新啟動的時候,就會借由超級區塊當中記錄的有效位(是否有掛載)與文件系統狀態(正確卸載與否)等狀態來判斷是否強制進行數據一致性的檢查,若有需要檢查時則以e2fsck這個程序來進行。
????????不過,這樣的檢查真的是很費時,因為要針對元數據區域與實際數據存放區來進行比對,呵呵,得要查找整個文件系統,如果你的文件系統有100GB以上,而且里面的文件數量又多時,哇,系統真忙碌,而且在對提供網絡服務的服務器主機上面,這樣的檢查真的會造成主機恢復時間的拉長,真是麻煩,這也就造成后來所謂日志式文件系統的興起。
2.2.日志式文件系統(Journaling filesystem)
????????為了避免上述提到的文件系統不一致的情況發生,我們的前輩們想到一個方式,如果在我們的文件系統當中規劃出一個區塊,該區塊專門記錄寫入或修改文件時的步驟,那不就可以簡化一致性檢查的步驟了?
也就是說:
- 1.預備:當系統要寫入一個文件時,會先在日志記錄區塊中記錄某個文件準備要寫入的信息;
- 2.實際寫入:開始寫入文件的權限與數據;開始更新metadata的數據;
- 3.結束:完成數據與metadata的更新后,在日志記錄區塊當中完成該文件的記錄;
在這樣的程序當中,萬一數據的記錄過程當中發生了問題,那么我們的系統只要去檢查日志記錄區塊,就可以知道哪個文件發生了問題,針對該問題來做一致性的檢查即可,而不必針對整個文件系統進行檢查,這樣就可以達到快速修復文件系統的目的,這就是日志式文件最基礎的功能。
????????那么我們的ext2可實現這樣的功能嗎?
當然可以,使用ext3與ext4即可。ext3與ext4是ex的升級版本,并且可向下兼容ext2版本。所以,目前我們才建議大家,可以直接使用ext4這個文件系統,如果你還記得dumpe2fs 輸出的信息,可以發現超級區塊里面含有下面這樣的信息:
看到了吧!通過inode 8號記錄日志區塊的區塊指向,而且該日志區塊具有32MB的容量來記錄
日志信息。這樣對于所謂的日志式文件系統有沒有一點概念呢?
3.Linux文件系統的運行
????????我們現在知道了目錄樹與文件系統的關系,但我們也知道,所有的數據要加載到內存后CPU才能夠進行處理。
????????想一想,如果你常常編輯一個好大的文件,在編輯的過程中又頻繁地要系統來寫入到磁盤中,由于磁盤寫入的速度要比內存慢很多,因此你會常常耗在等待磁盤的讀寫上真沒效率。
為了解決這個效率的問題,Linux使用一個稱為異步處理(asynchronously)的方式。所謂的異步處理是這樣的:
????????當系統加載一個文件到內存后,如果該文件沒有被修改過,則在內存區段的文件數據會被設置為【干凈(clean)】。但如果內存中的文件數據被更改過了(例如你用nano去編輯過這個文件),此時該內存中的數據會被設置為【臟的(Dirty)】,此時所有的操作都還在內存中執行,并沒有寫入到磁盤中。系統會不定時的將內存中設置為【Dirty】的數據寫回磁盤,以保持磁盤與內存數據的一致性。你也可以利用sync命令來手動強制寫入磁盤。
????????我們知道內存的速度要比磁盤快得多,因此如果能夠將常用的文件放置到內存當中,這不就會提高系統性能了嗎?
沒錯,是有這樣的想法。
因此我們Linux系統上面的文件系統與內存有非常大的關系:
- 系統會將常用的文件數據放置到內存的緩沖區,以加速文件系統的讀寫操作;
- 因此 Linux的物理內存最后都會被用光,這是正常的情況,可加速系統性能;你可以手動使用sync來強制內存中設置為Dirty的文件回寫到磁盤中;
- 若正常關機時,關機命令會主動調用sync來將內存的數據回寫入磁盤內;
- 但若不正常關機(如斷電、宕機或其他不明原因),由于數據尚未回寫到磁盤內,因此重新啟動后可能會花很多時間在進行磁盤校驗,甚至可能導致文件系統的損壞(非磁盤損壞)
4、文件的刪除
文件創建后,如何刪除?
刪除并不是真刪除,而是將 inode 對照表 和 Block對照表 中位圖信息進行修改即可(只要訪問不到,就是刪除)
- 根據文件名找到 inode 編號
- 再根據 inode 屬性中的映射關系,設置 Block 對照表對應的比特位,設置為 0 (刪內容)
- 最后根據 inode 編號設置 inode對照表中對應的比特位為 0 (刪屬性)
將位圖信息置為 0 后,創建新文件時,系統可以直接使用
至于文件的查找與修改,通過 inode 修改其內部屬性即可
注意: inode 和 Data blcok 可能存在失衡的情況
- 一直創建空文件,導致 inode 滿載,而 Data block 空余很多
? - 不斷往同一個文件中寫入數據,導致 Data block 被占用,后續創建文件時,inode 無法再分配到 Data block
4.1. 刪除文件
刪除文件的步驟
- 首先根據文件名找到
inode編號 - 再將該文件對應的
inode,在inode位圖當中置為無效(置0) - 最后將該文件申請的數據塊,在塊位圖當中置為無效(置0)
此刪除操作并不會真正將文件對應的信息刪除,而只是將其inode號和數據塊號置為了無效,起到了訪問不到就等于刪除的效果
當我們刪除文件后短時間內是可以恢復的
?????????為什么說是短時間內呢,
因為該文件對應的inode號和數據塊號已經被置為了無效,因此后續創建其他文件或是對其他文件進行寫入操作申請inode號和數據塊號時,可能會將該置為無效了的inode號和數據塊號分配出去,此時刪除文件的數據就會被覆蓋,也就無法恢復文件了。
?4.2.為什么拷貝文件的時候很慢,而刪除文件的時候很快?
- 因為拷貝文件需要先創建文件,然后再對該文件進行寫入操作,該過程需要先申請inode號并填入文件的屬性信息,之后還需要再申請數據塊號,最后才能進行文件內容的數據拷貝,
- 而刪除文件只需將對應文件的inode號和數據塊號置為無效即可,無需真正的刪除文件,因此拷貝文件是很慢的,而刪除文件是很快的。
4.3.、文件誤刪后的解決方案
磁盤中的數據被刪除后,還可以再恢復嗎?
答案是可以的,但不能完全恢復,并且越早斷電、送修越好
前面說過,刪除并不是真刪除,訪問不到就行了,所以只要在刪除后,根據 inode 找到 Data block,其中的內容沒有被覆蓋,數據就可以找回來
應急方案:
- 不要輕舉妄動,避免 Data block 被覆蓋
- 通過 inode 將 inode 位圖 中的位圖置 1,使文件復活,再根據屬性進行數據恢復
- 如果自己不知道 inode,那就盡早斷電,送給廠家恢復(專業)
如何避免誤刪文件?
- 學習 Windows 中的回收站,刪除不是真刪除,而是先將文件移入回收站(目錄)中,留給用戶反悔的時間
5、大文件存儲
單個數據塊大小有限(4 kb),如何做到一個數據塊存儲大量數據?
答案是?套娃,Data block?中存儲其他?Data block?信息,此時稱為多級索引,可以做到一個數據塊中存儲大量數據
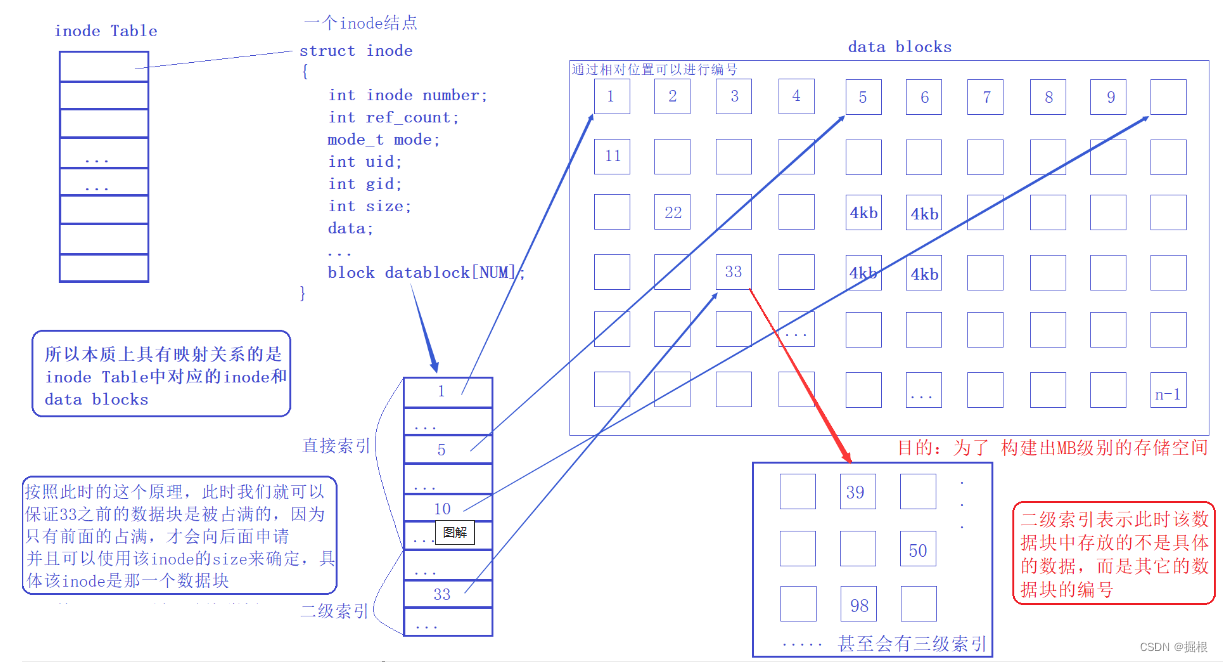

)






)



)


上傳文件)



