目錄
一、概念
二、模擬實現
三、布隆過濾器擴展應用
?
上一篇章學習了位圖的使用,但它只適用于整數,對于要查詢字符串是否在不在,位圖并不能解決。所以針對這一問題,布隆過濾器可以派上用場,至于布隆過濾器是什么,其實并沒有什么神奇的,就是在位圖上套了哈希函數罷了,這兩者組合起來就是布隆過濾器,而字符串就可以通過哈希函數轉換成整數映射到位圖當中去。?
一、概念
布隆過濾器是由布隆(Burton Howard Bloom)在1970年提出的一種緊湊型的、比較巧妙的概念性數據結構,特點是高效地插入和查詢,可以用來告訴你“某樣東西一定不存在或者可能存在”,他是用多個哈希函數,將一個數據映射到位圖結構中。此種方式不僅可以提升查詢效率,也可以節省大量的內存空間。
原理分析:?
我們來進行分析,為什么不存在是一定的,而存在是可能的,以及為什么要這樣做。
首先來解釋為什么要用多個哈希函數。
我們知道,字符串可以通過哈希函數轉換成整數,但是哈希沖突是避免不了的,可能存在多個字符串通過哈希函數都得到了一樣的整數,所以,為了盡量的減少哈希沖突,可以使用多個哈希函數,讓字符串通過多個哈希函數得到多個映射位置,只要不是多個映射位置都相同,就不會沖突,這樣大大提高了效率。至于要用幾個哈希函數是適合的。
這里有一份研究:(轉載詳解布隆過濾器的原理,使用場景和注意事項 - 知乎 (zhihu.com))
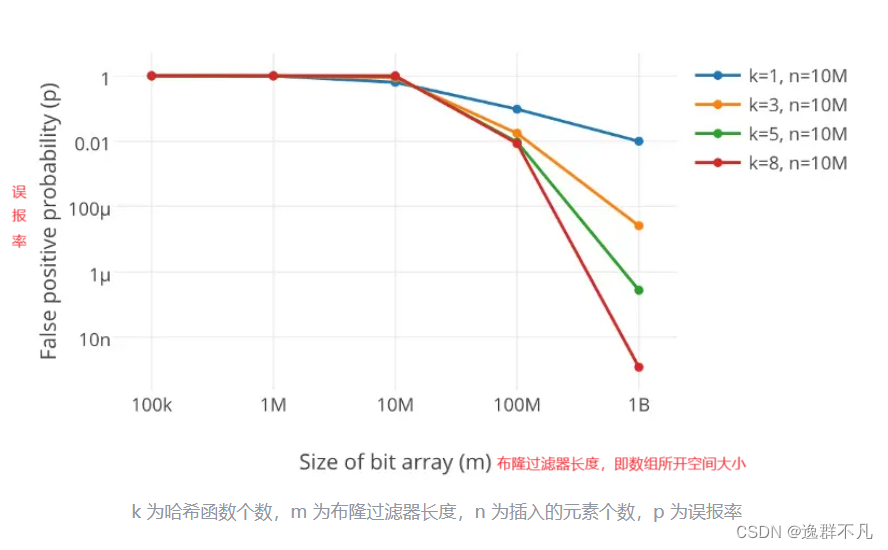
其中誤報率就是哈希沖突率?
其中k、m、n滿足:
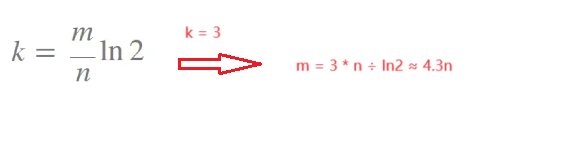
?其中k、m、p滿足:
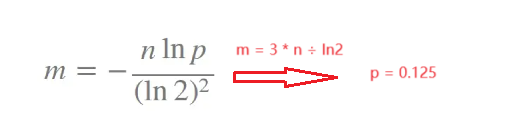
我們可以發現,哈希函數用的越多,哈希沖突率就越低,但是哈希函數到3之后,誤報率已經很低了,其次,當哈希函數、插入元素固定,所開空間越大,誤報率也越低。
用一張圖來表示通過哈希函數映射到位圖中:
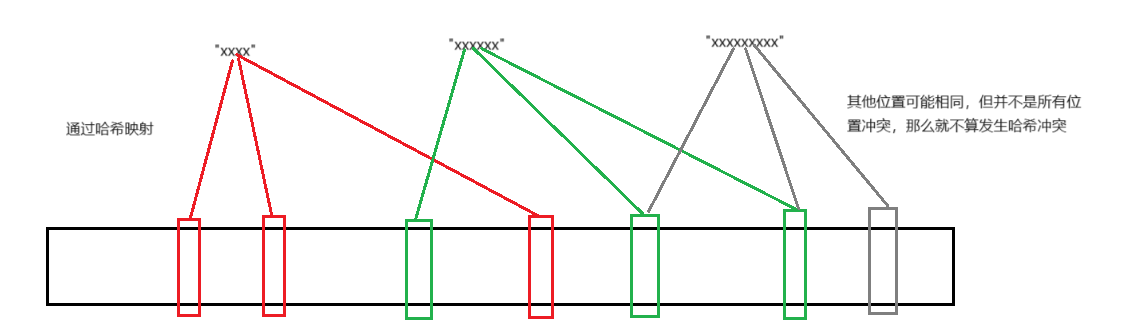
那么綜上,即使采用了多個哈希函數,也依然可能會存在哈希沖突,所以在判斷東西在不在時,若返回的是存在,這有可能是誤判,說明映射的位置依然可能完全相同,而不存在時,說明映射的位置不完全相同,這是正確的結果,為了確保沖突率,我們在模擬實現的時候就采用3個哈希函數。
二、模擬實現
#include "MyBitSet.h"//在上一篇章已實現
struct BKDRHash
{size_t operator()(const string& key){size_t hash = 0;for (auto e : key){//BKDRhash *= 31;hash += e;}return hash;}
};struct APHash
{size_t operator()(const string& key){size_t hash = 0;for (size_t i = 0; i < key.size(); i++){if ((i & 1) == 0){hash ^= ((hash << 7) ^ key[i] ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ key[i] ^ (hash >> 5)));}}return hash;}
};
struct DJHash
{size_t operator()(const string& key){register size_t hash = 5381;for(auto e : key){hash += (hash << 5) + e;}return hash;}
};
namespace bit
{template<size_t N, class K = string, //默認輸入的是字符串class HashFunc1 = BKDRHash,class HashFunc2 = APHash,class HashFunc3 = DJHash>class BloomFilter{public:void set(const K& key){//獲取三個映射位置int hash1 = HashFunc1()(key) % N;int hash2 = HashFunc2()(key) % N;int hash3 = HashFunc3()(key) % N;_blf.set(hash1);_blf.set(hash2);_blf.set(hash3);}bool test(const K& key){//key不存在是準確的。int hash1 = HashFunc1()(key) % N;if (_blf.test(hash1) == false)return false;int hash2 = HashFunc2()(key) % N;if (_blf.test(hash2) == false)return false;int hash3 = HashFunc3()(key) % N;if (_blf.test(hash3) == false)return false;//key存在可能有誤判return true;}private:bitset<N> _blf;};
}void TestBF1()
{bit::BloomFilter<100> bf;bf.set("豬八戒");bf.set("沙悟凈");bf.set("孫悟空");bf.set("二郎神");cout << bf.test("豬八戒") << endl;cout << bf.test("沙悟凈") << endl;cout << bf.test("孫悟空") << endl;cout << bf.test("二郎神") << endl;cout << bf.test("二郎神1") << endl;cout << bf.test("二郎神2") << endl;cout << bf.test("二郎神 ") << endl;cout << bf.test("太白晶星") << endl;
}void TestBF2()
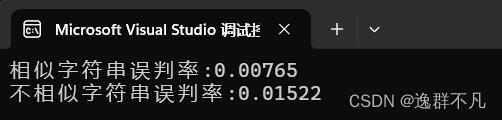
{srand(time(0));const size_t N = 100000;bit::BloomFilter<N * 10> bf;std::vector<std::string> v1;//std::string url = "https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html";std::string url = "豬八戒";for (size_t i = 0; i < N; ++i){v1.push_back(url + std::to_string(i));}for (auto& str : v1){bf.set(str);}// v2跟v1是相似字符串集(前綴一樣),但是不一樣std::vector<std::string> v2;for (size_t i = 0; i < N; ++i){std::string urlstr = url;urlstr += std::to_string(9999999 + i);v2.push_back(urlstr);}size_t n2 = 0;for (auto& str : v2){if (bf.test(str)) // 誤判{++n2;}}cout << "相似字符串誤判率:" << (double)n2 / (double)N << endl;// 不相似字符串集std::vector<std::string> v3;for (size_t i = 0; i < N; ++i){//string url = "zhihu.com";string url = "孫悟空";url += std::to_string(i + rand());v3.push_back(url);}size_t n3 = 0;for (auto& str : v3){if (bf.test(str)){++n3;}}cout << "不相似字符串誤判率:" << (double)n3 / (double)N << endl;
}測試:
#include <string>
#include "MyBloomFilter.h"int main()
{TestBF2();return 0;
}?輸出結果:
三、布隆過濾器擴展應用
1.給兩個文件,分別由100億個字符串,只有1G內存,如何找到兩個文件交集?
假設每個字符串占50個字節,那么100億就是5000字節,約等于500G,內存肯定存不下,此時可以采用哈希切分。如圖:
?
2.給一個超過100G大小的log file,log中存著IP地址,設計算法找到出現次數最多的IP地址?
與第一題類似,先進行哈希切分,然后通過map統計每個小文件中IP地址出現的次數進行比較即可。?





】為什么我會看到包含管道橋的Nios II設計出現 Flash Programmer 問題?)




)





30張,超高清!)


