目錄
HetuEngine是什么?
HetuEngine的特點以及使用場景
特點
使用場景
HetuEngine介紹
結構
近期用到了Hetu,了解下這個工具是起什么作用的。
HetuEngine是什么?
是引擎,設計是為了讓與當前的大數據生態完美融合的引擎,這里的大數據生態例如存儲層的Hive、HBase、ClickHouse等。
它是一個一站式SQL分析引擎,相當于在Hive、GaussDB這種異源數據上面新增了一個上層頁面,我們在上層頁面寫一個SQL,這個SQL中可以同時用到Hive的A表和GaussDB的B表,底層會自動到相應的數據庫中執行、返值等,也就是能把跨源、跨域的數據,關聯到一起做分析,而不用關注多類的數據去寫多類的SQL,中間去搞各種臨時表。
“河圖引擎”在華為的描述中,可以讓“邏輯數據湖”大規模數據融合分析提效50倍,開發效率提高2到10倍,后者我們倒是好理解,在開發者側,引擎它屏蔽了底層的數據存儲設施的復雜度,能像使用普通例如MySQL數據庫一樣使用大數據,能復用各種之前的技能、工具;前者對于分析效率的提高,我們接下來看看為什么怎么高。
HetuEngine的特點以及使用場景
特點
- 完全的內存計算,自動實現計算下推,動態過濾等,實現PB級數據毫秒級響應。
- 優化的計算引擎,先進的分布式計算框架和優化算法,能更高效地分配計算資源,并行處理數據,從而大大提高計算速度。
- 智能的數據緩存與預取,預測和提前加載常用數據,減少數據讀取的時間開銷,加速分析過程,減少IO浪費。
- 擁有強大的查詢優化器,能夠自動分析查詢語句,制定最優的執行計劃,避免不必要的計算和數據訪問。
- 有效地管理和調度系統資源,確保在大規模數據處理時資源得到充分利用,避免資源競爭和浪費。
使用場景
主要還是跨數據源融合分析,整合來自不同數據源(如關系型數據庫、大數據系統、NoSQL 數據庫等)的數據,進行統一的分析,而不用把各種源的數據先統一抽取轉換到一個統一的中間庫中。
另外其實同理的就是,適用于跨域,即多個地域或者說數據中心的快速聯合查詢。
特別說下就是大批量、特別復雜邏輯的批處理場景其實不太適合用HetuEngine。
官網上也強調了“尤其適用于Hadoop集群(MRS)的Hive、Hudi數據的交互式快速查詢場景”。
HetuEngine介紹
結構
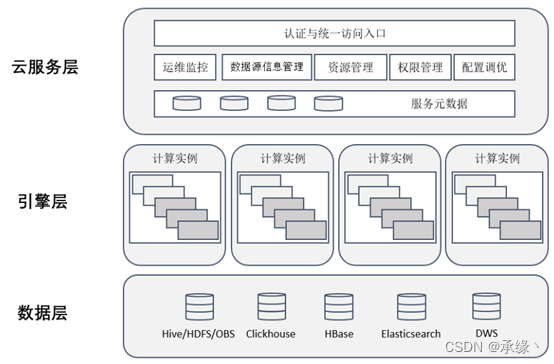
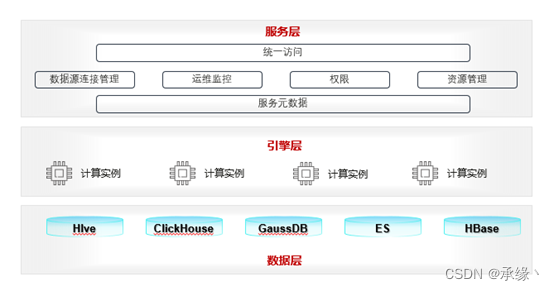
數據層:即HetuEnging支持的數據源,其實也就是數據實際存儲的位置。
引擎層:HetuEnging接收SQL、解析SQL、并行拉取數據層數據、分布式計算的地方。
服務層:門戶、數據源連接以及管理等配置頁面。












)
)





