STL—容器—string類
其實string類準確來說并不是容器,因為他出現的時間比STL要早,但是也可以說是容器吧。
1.為什么要學習string類?
1.1C語言當中的字符串
C語言中,字符串是以’\0’結尾的一些字符的集合,為了操作方便,C標準庫中提供了一些str系列的庫函數,但是這些庫函數與字符串是分離開的,不太符合OOP的思想,而且底層空間需要用戶自己管理,稍不留神可能還會越界訪問。
1.2面試題
415. 字符串相加 - 力扣(LeetCode)
在OJ中,有關字符串的題目基本以string類的形式出現,而且在常規工作中,為了簡單、方便、快捷,基本
都使用string類,很少有人去使用C庫中的字符串操作函數。
2.標準庫中的string類
2.1string類的了解
string類的文檔介紹
-
字符串是表示字符序列的類
-
標準的字符串類提供了對此類對象的支持,其接口類似于標準字符容器的接口,但添加了專門用于操作單字節字符字符串的設計特性。
-
string類是使用char(即作為它的字符類型,使用它的默認char_traits和分配器類型(關于模板的更多信息,請參閱basic_string)。
-
string類是basic_string模板類的一個實例,它使用char來實例化basic_string模板類,并用char_traits和allocator作為basic_string的默認參數(根于更多的模板信息請參考basic_string)。
-
注意,這個類獨立于所使用的編碼來處理字節:如果用來處理多字節或變長字符(如UTF-8)的序列,這個類的所有成員(如長度或大小)以及它的迭代器,將仍然按照字節(而不是實際編碼的字符)來操作。
總結:
-
string是表示字符串的字符串類
-
該類的接口與常規容器的接口基本相同,再添加了一些專門用來操作string的常規操作。
-
string在底層實際是:basic_string模板類的別名,typedef basic_string<char, char_traits, allocator> string;
-
不能操作多字節或者變長字符的序列。
在使用string類時,必須包含#include頭文件以及using namespace std;
我們在包含頭文件的時候經常會遇到兩個比較容易混淆的頭文件引用#include<string.h> 和 #include ,兩者的主要區別如下:
#include<string.h>是C語言的標準庫,主要是對字符串進行操作的庫函數,是基于char*進行操作的,例如常見的字符串操作函數stpcpy、strcat都是在該頭文件里面聲明的。
#include是C++語言的標準庫,該庫里面定義了string類,你可以包含這個頭文件,然后定義一個字符串對象,對于字符串的操作就基于該對象進行,例如:string str;
一般來說,c++的頭文件不會有.h的出現,比如
————————————————
文檔方面,個人覺得這個比較好用
- C++ Reference
作為一個程序員,查文檔是一個必須具備的基本素質,當遇到一個不熟悉的接口需要使用的時候,查文檔就是最好的解決方法,因此我們需要學會怎么查文檔。
2.2string類的常用接口說明
2.2.1.string類的常見構造
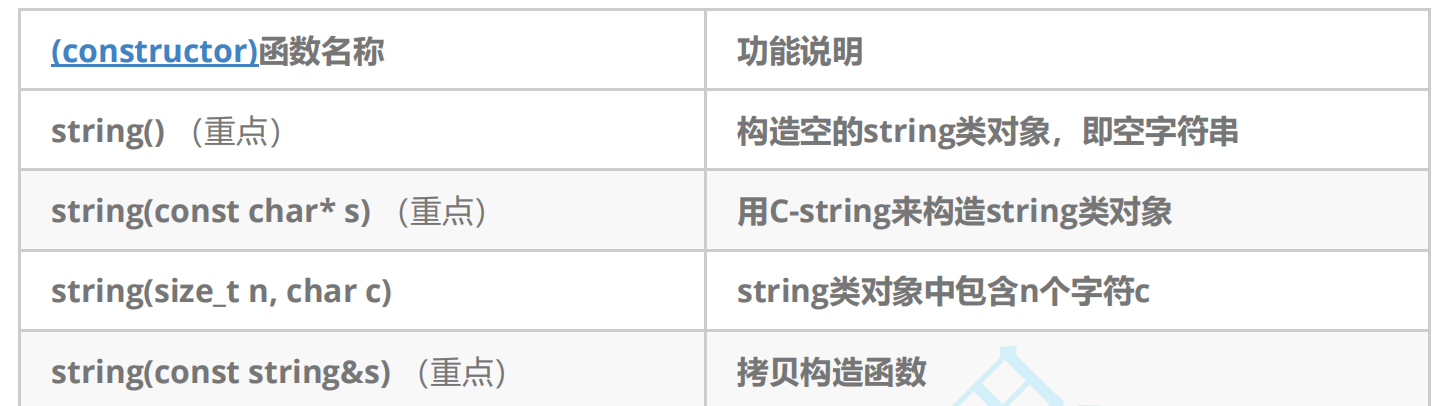
c++98版本中全部的構造
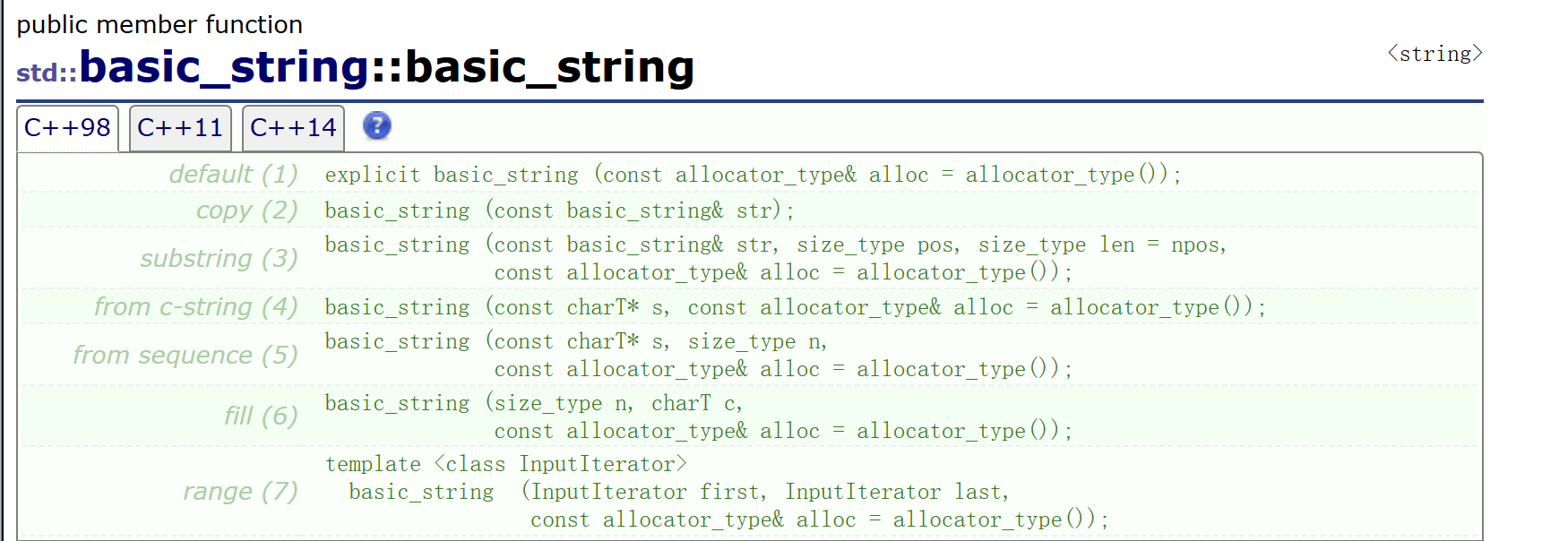
實例:
// 初識string類
// string類 有很多的接口和成員函數,我們主要得熟悉的使用其中的2成,剩下的8成需要我們去通過網絡查詢來解決
# include<string>
# include<iostream>using namespace std;
int main()
{// 關于string類的構造string s1; // 構造string s2("string"); // 直接構造string s3(s2); // 拷貝構造// 上面這三個最常用string s4(10, 's'); // string類中的的不常用的特殊構造string s5("hello", 1, 3); // string類中的不常用的特殊構造 [這里如果給的不是3 是過大的值,那么就是npos,意思就是將字符串后面有多少給多少] 這些知識都可以查文檔查到// 能使用 << 來輸出是因為 庫中 已經對<< 進行了重載cout << s1 << endl; // [這里默認是空串]cout << s2 << endl; // stringcout << s3 << endl; // stringcout << s4 << endl; // sssssssssscout << s5 << endl; // ell [取"hello"中的 第 1~3號元素來構造的, 正好就是ell]string s6 = s4; // 這里還是拷貝構造string s7 = "string"; // 這里正常來說就是發生隱式類型轉化 意味著,先直接構造,在拷貝構造// 但是這里的直接構造 + 拷貝構造發生在了同一表達式,因此編譯器直接優化成直接構造cout << s6 << endl; // sssssssssscout << s7 << endl; // stringreturn 0;
}
2.2.2string類對象的容量操作
常見的與容量相關的接口:
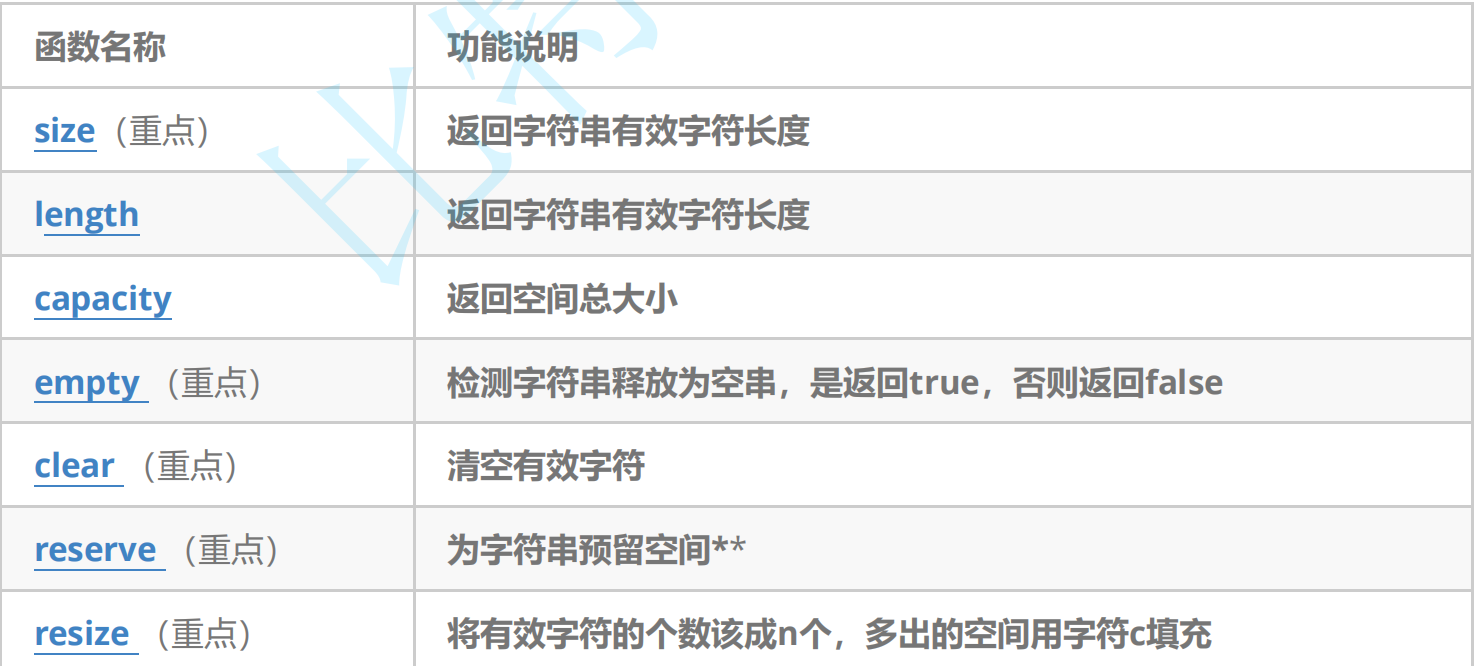
接口的代碼使用:
1.size(重點)
size可以統計字符串的有效字符長度并返回。一般來說會用作遍歷。
// string類對象有關容量的常見接口
// 1.size()
# include<string>
# include<iostream>
using namespace std;int main()
{ string s("hello");cout << "s: ";// 遍歷for (size_t i = 0; i < s.size(); i++){s[i] += 1; // 寫 [這個相當于對取出來的字符+1,就相當于給其ASCII碼值+1]}for (size_t i = 0; i < s.size(); i++){cout << s[i]; // 讀}cout << endl; //s8: ifmmp [hello每個字符的ASCII碼值分別+1]return 0;
}
2.length
length也會統計字符串的有效長度并返回。其實和size是非常像的,甚至其底層的實現原理都是一樣的、
其實在早期的時候用的都是length,但是后面數據結構都用size了,就統一用size了,length和size可以說就是一樣的,這里推薦使用size
// 2.length# include<string>
# include<iostream>
using namespace std;void test_string()
{string s1("hello, world");cout << s1.size() << endl; // 12cout << s1.length() << endl; // 12}int main()
{test_string();return 0;
}
3.capacity
capacity可以返回當前空間的總大小
// 3.capacity
# include<string>
# include<iostream>
using namespace std;int main()
{string s("hello, world");cout << s.capacity() << endl; // 15// 目前s有12個空間存放數據,如果超出空間,會增容多少呢?s += "ddddd";cout << s.capacity() << endl; // 31// 可以發現,直接將其增容到了2倍的容量。return 0;
}
4.clear(重點)
清空字符串內容 【注意,空間不會被銷毀,只是內容被清空了】
// 4.clear# include<string>
# include<iostream>
using namespace std;int main()
{string s("hello, world");cout << s << endl; // hello, worlds.clear();cout << s << endl; // 空串// 我們清除了字符串內容,不代表空間被銷毀了、cout << s.capacity() << endl; // 15return 0;
}
5.empyt(重點)
empty可以檢測字符串是否為空串,是就返回true,不是就返回false
//5.empty# include<string>
# include<iostream>
using namespace std;int main()
{string s("hello, world");if (s.empty())cout << "該string類對象為空" << endl;elsecout << "該string類對象不為空" << endl;s.clear();if (s.empty())cout << "該string類對象為空" << endl;elsecout << "該string類對象不為空" << endl;return 0;
}
6.reserve/resize(重點)
在學習這兩個接口之前,我們先來看一個代碼:
這個代碼可以觀察到每次增容時容量的變化大小
# include<string>
# include<iostream>
using namespace std;int main()
{string s;size_t sz = s.capacity();cout << "s_capacity grow\n";for (int i = 0; i < 100; i++){s.push_back('c'); // 也可以s += 'c'if (sz != s.capacity()) // != 的時候就說明s進行了增容{sz = s.capacity(); // 將新容量給到szcout << "new capacity: " << sz << endl; // 將此時的容量打印出來}}return 0;
}
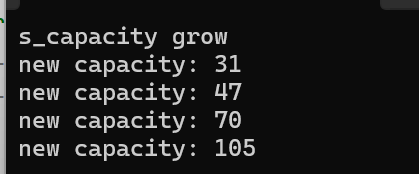
我們發現是接近1.5倍增容的。但是我們之前知道15容量在增容的時候是按兩倍增容增到31的、
規律是:空間基數越大,增容的倍數越小
因為增容是有代價的。增容越多的空間,執行越多次增容,代價就越大。
知道了這個小知識,我們就可以來看resize和reserve了。
reserve:給字符串預留空間。
其實就是給字符串開辟空間
// 6.resize/reserve
# include<string>
# include<iostream>
using namespace std;int main()
{string s;s.reserve(100); // 我們知道s需要100個空間,提前開好空間size_t sz = s.capacity();cout << "s_capacity grow\n";for (int i = 0; i < 100; i++){s.push_back('c'); // 也可以s += 'c'if (sz != s.capacity()) // != 的時候就說明s進行了增容{sz = s.capacity(); // 將新容量給到szcout << "new capacity: " << sz << endl; // 將此時的容量打印出來}}return 0;
}
由于我們提前開辟好了100個空間【實際上不一定會開100個,因為要考慮內存對齊,最后還要放個\0】,s沒有再執行增容操作。
這樣我們只增容了一次,比起自動增容的次數就減少了許多。
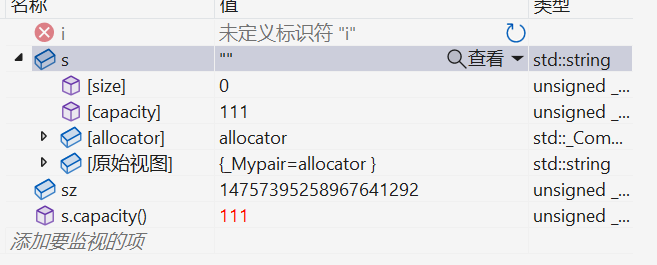
直接開辟了111個空間,并不是我們輸入的100。【了解一下】
resize:在reserve的基礎上,將有效字符的個數修改,并填充字符
int main()
{string s;//s.reserve(100); // 我們知道s需要100個空間,提前開好空間s.resize(100); // 將有效字符個數修改到100,并填充\0size_t sz = s.capacity();cout << "s_capacity grow\n";for (int i = 0; i < 100; i++){s.push_back('c'); // 也可以s += 'c'if (sz != s.capacity()) // != 的時候就說明s進行了增容{sz = s.capacity(); // 將新容量給到szcout << "new capacity: " << sz << endl; // 將此時的容量打印出來}}return 0;
}
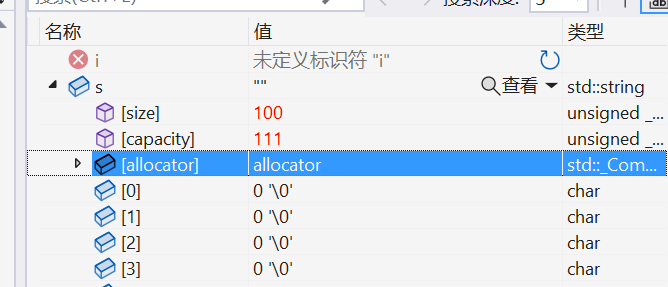
可以看到它相當于reserve(100)并且將有效字符個數修改到了100,并且填充了\0、

由于前100個空間被resize填充了\0,因此后面還是會執行增容操作
因此如果想后面不執行增容操作,這里要用reserve
我們還可以指定填充的字符
int main()
{string s;//s.reserve(100); // 我們知道s需要100個空間,提前開好空間//s.resize(100); // 將有效字符個數修改到100,并填充\0s.resize(100,'6'); // 將有效字符修改到100,并填充6// 因此如果想后面不執行增容操作,這里要用reservesize_t sz = s.capacity();cout << "s_capacity grow\n";for (int i = 0; i < 100; i++){s.push_back('c'); // 也可以s += 'c'if (sz != s.capacity()) // != 的時候就說明s進行了增容{sz = s.capacity(); // 將新容量給到szcout << "new capacity: " << sz << endl; // 將此時的容量打印出來}}return 0;
}
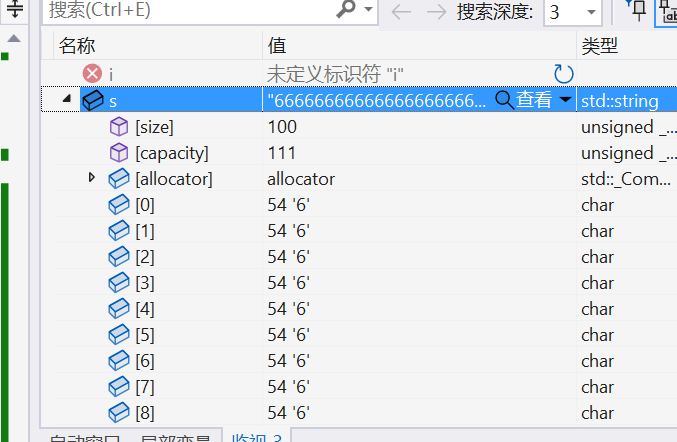
可以看到不再填充\0而是填充我們指定的字符6
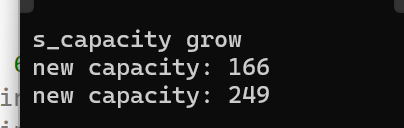
并且由于前100個空間都被resize填入了元素,因此后面插入100個c的時候還是會增容的
因此如果想后面不執行增容操作,這里要用reserve
總結(重要):
string容量相關方法使用代碼演示
- size()與length()方法底層實現原理完全相同,引入size()的原因是為了與其他容器的接口保持一致,一般情況下基本都是用size()。
- clear()只是將string中有效字符清空,不改變底層空間大小
- resize(size_t n) 與 resize(size_t n, char c)都是將字符串中有效字符個數改變到n個,不同的是當字符個數增多時:resize(n)用0來填充多出的元素空間,resize(size_t n, char c)用字符c來填充多出的元素空間。注意:resize在改變元素個數時,如果是將元素個數增多,可能會改變底層容量的大小,如果是將元素個數減少,底層空間總大小不變。
string s1("hello, world");
s1.resize(5); // 會將原來的size減小到 5。
cout << s1 << endl; // hellos1.resize(20, 'x'); // 將size改到20,由于前5個已經有元素了,后15個填入x【空間不夠會自動擴容】
cout << s1 << endl; // helloxxxxxxxxxxxxxxx
- reserve(size_t res_arg=0):為string預留空間,不改變有效元素個數,當reserve的參數小于string的底層空間總大小時,reserver不會改變容量大小
注意:
- 上面我們講的有關容量的接口都是常用的,并不是全部。全部的接口可以去文檔中查看
- 在查看接口的時候,目前來說只需要查看接口如何使用,不用查看接口的底層實現,因為以目前的水平,是完全看不懂的。
- 常用的接口需要熟悉使用、
2.2.3string類對象的訪問及遍歷操作

string中元素訪問及遍歷代碼演示
下面我們對于遍歷一共有3種方法【[] + 下標】【迭代器】【范圍for】
拓展:迭代器
我們來了解一下迭代器

如圖所示,迭代器一共四種,這里我們就是了解一下,具體的我們后面會詳細學習。
遍歷的代碼:
void test_string3()
{// 迭代器一共有4種迭代器,這里在介紹一種string s("hello world");// 倒著遍歷string::reverse_iterator rit = s.rbegin(); //要用rbegin,指向字符串的最后一個有效元素// auto rit = s.rbegin();while (rit != s.rend()) // rend,指向字符串的首元素{cout << *rit;rit++; // 其實是倒著走的}cout << endl;// dlrow olleh
}int main()
{ // [] + 下標 【平常推薦使用這個】string s("hello");cout << "s: ";// 遍歷for (size_t i = 0; i < s.size(); i++){s[i] += 1; // 寫 [這個相當于對取出來的字符+1,就相當于給其ASCII碼值+1]}for (size_t i = 0; i < s.size(); i++){cout << s[i]; // 讀}cout << endl; //s8: ifmmp [hello每個字符的ASCII碼值分別+1]// 迭代器【每個容器都會有自己的迭代器】【迭代器一共有四種】(這里了解一下迭代器)string::iterator it = s.begin(); // string::iterator 實際是一個類型//auto it = s1.begin(); // 也可以這樣寫 [自動推演]// 遍歷while (it != s.end()){*it -= 1; // 寫++it; // 迭代}it = s.begin(); // 重置while (it != s.end()){cout << *it; // 讀++it; // 迭代}cout << endl;// hellotest_string3(); // 另外一種迭代器的使用// 上述是迭代器的使用方法,熟悉一下就行,后面會詳細學習。// 范圍for(c++11) [原理其實就是迭代器]for (auto ch : s) // 自動把s8從左到右依次給到ch auto會自動推斷類型{cout << ch;}cout << endl; //helloreturn 0;
}再來看一個場景:
- 將字符串轉化為整數
// 將傳進來的字符串轉化成整數 【使用迭代器】
int string2int(const string& str)// 用引用提高效率,并且不改變str,const修飾
{int val = 0;string::const_iterator cit = str.begin(); // 此時的str是const對象,返回的是const類型的迭代器類型while (cit != str.end()){val *= 10;val += (*cit - '0');}cout << val << endl;
}int main()
{// 將字符串轉化成整數string s("12345");int val = 0; for (int i = 0; i < s.size(); i++) // 遍歷{// 讓val + 上取出來的數字,然后再*10, 循環,直至全部取出、val *= 10; val += (s[i] - '0'); // -'0'是因為 取出來的是字符 而不是整形, - 去'0'的ASCII值才是對應整形}cout << val << endl; // 12345string s1("12345");int ret = string2int(s1);cout << ret << endl; // 12345return 0;
}
通過上面兩個例子,我們了解到了遍歷有不同的方式去遍歷。
在這里面當中,迭代器似乎是一個比較麻煩的使用方式。
從方向上分:正向和反向迭代器
從權限上分:普通迭代器,const迭代器。
因此使用的時候似乎不吃香,從短期來看確實是如此,因為經過了c語言的學習,我們已經習慣于用數組的方式去遍歷。但是數組這個方式只能用于vector 和 string。等到后面更多的數據結構,也就是容器出現,迭代器就會頻繁使用,因為+所有容器的迭代器使用方法都是類似的。
因此迭代器的學習是c++中一個重要的部分。迭代器可以用于所有STL庫中的容器的遍歷
2.2.4string類對象的修改操作
常見的幾個與修改操作相關的接口
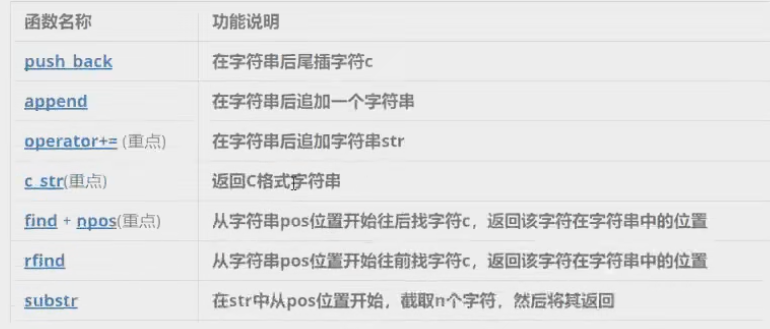
1.push_back/append/+=(重要)
push_back:在字符串后邊尾插字符
append:在字符串后邊追加字符串
+=:在字符串后邊追加字符串
這三個我們推薦**+=**
有關尾插的三個接口的使用的代碼:
// 1.+= / push_back / append 【有關尾插的三個接口】
# include<string>
# include<iostream>
using namespace std;int main()
{string s1;s1.push_back('p');s1 += 'p'; // 推薦使用+=cout << s1 << endl; //pp 可以看到 += 和 調用尾插接口的結果是一樣的s1 += "hello"; // 這里調用的是另外一個 += 的重載函數cout << s1 << endl; // pphellos1.append(" world"); // 在s1后尾插" world"字符串cout << s1 << endl; // pphello world// 在上述三個尾插的操作接口中,我們推薦使用+=return 0;
}
如果想在具體位置插入的話可以使用insert接口,想刪除具體位置的話用erase接口
可以上文檔查具體使用方法,這里不做詳解
2.c_str

c_str: 會將string類對象以const char 的格式返回*
他會在string類對象中找到\0 ,把\0之前的字符串內容當做一個 const char 類型返回*
代碼操作:
//2.c_str
# include<string>
# include<iostream>
using namespace std;int main()
{string s("hello");const char* str = s.c_str();// str拿到的是const char* 類型。// 獲取字符數組的首地址,用c語言中的字符串形式去遍歷while (*str) // 只要*str不是\0就繼續{cout << *str;str++;}cout << endl; // hello// 也可以直接輸出cout << s << endl; // hello// 這里調用的是string類中的重載的<<, 它會將整個s進行輸出cout << s.c_str() << endl; // hello// 這里相當于直接對 const char* 進行輸出,遇到\0就會結束輸出s += '\0';s += ' ';s += "world";cout << s << endl; // hello world 中間的\0是不可見字符,不會打印出來cout << s.c_str() << endl; // hello 因為從h到 \0 被當做了一個const char*,s.c_str()返回的就是 helloreturn 0;
}
拓展:編碼表
我們知道一個中文占據兩個字節,這是由編碼表實現的,因為中文的編碼表是GDK
而英文的編碼表是ASCII表
編碼的本質是:映射,將對應的值映射到表中的某一個位置。
我們來看一段代碼:
// 編碼表
# include<string>
# include<iostream>
using namespace std;int main()
{// 我們知道英文是用ASCII碼表來編碼的string s = "中國"; // 中文使用GDK來編碼的cout << s << endl; //中國s[3] = -7;cout << s << endl; // 中郭s[3] = -8;cout << s << endl; // 中鍋s[3] = -9;cout << s << endl; // 中棍return 0;
}
下圖是s字符串中存儲的信息:
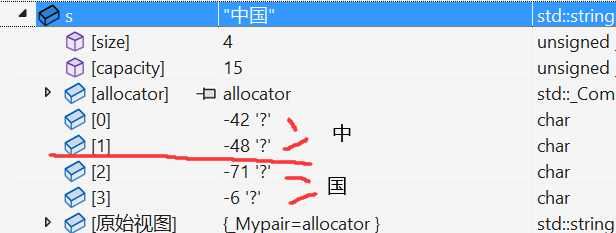
可以很清楚的看到中文是兩個字節共同編碼成一個中文。
3.find/rfind/substr(重要)

find: 可以查詢字符串中的某個字符
如果找不到會返回npos【rfind找不到也一樣返回npos】

npos是-1 size_t的-1相當于int類型的最大值,42億多

substr:可以返回指定位置以后得字符串。如果不指定就是默認從頭開始
來看一段代碼:
//3.find/rfind
# include<string>
# include<iostream>
using namespace std;int main()
{string s("text.cpp"); // 如果我們想查詢這個后綴.cpp// 我們就可以用find去查詢. 再將其后邊的打印出來size_t pos = s.find('.'); // pos = 4if (pos != string::npos) // npos是-1 size_t的-1相當于int類型的最大值,42億多{// 用substr接口實現.后的打印cout << s.substr(pos) << endl; // .cpp// s.substr(pos)就是打印pos之后的數據,包括pos}return 0;
}
rfind:可以查詢字符串中的一個字符,并且是最后一次出現的
//3.find/rfind
# include<string>
# include<iostream>
using namespace std;int main()
{string s("text.cpp"); // 如果我們想查詢這個后綴.cpp// 我們就可以用find去查詢. 再將其后邊的打印出來size_t pos = s.find('.'); // pos = 4if (pos != string::npos) // npos是一個-1 size_t的-1相當于int類型的最大值,42億多{// 用substr接口實現.后的打印cout << s.substr(pos) << endl; // .cpp// s.substr(pos)就是打印pos之后的數據,包括pos}// 還會有一種情況,如果想查詢的字符串有多個后綴,我們想輸出最后一個后綴的話// 我們就可以用rfind 重復的查找. 找到最后一個.string s1("test.cpp.zip"); // pos1 = 8size_t pos1 = s1.rfind('.');if (pos1 != string::npos){cout << s1.substr(pos1) << endl; // .zip}return 0;
}
拓展:網址
平常我們看到的網址是由協議、域名、資源名稱
// 網址
# include<string>
# include<iostream>
using namespace std;// 協議、域名、資源名稱
int main()
{string url("https://gitee.com/wzf-sang");//https是協議 http和https的差別就是https是加密的///gitee.com其實是個ip但是綁定了域名。如果不綁定域名這里是個ip【域名更好記住】//wzf-sang就是資源名稱。//【在我們輸入網址敲回車之后,服務器做的第一件事就是將你輸入的網址拆成協議、域名、資源名稱】//【因此才能在對應協議下申請訪問對應的域名并根據資源名稱返回資源】// 現在有個要求:分離出url。size_t i1 = url.find(':'); // i1 = 5if (i1 != string::npos){cout << url.substr(0, i1) << endl; // https//從0這個下標,輸出i1個元素}size_t i2 = url.find('/', i1 + 3); // 從i1 + 3開始找if (i2 != string::npos){cout << url.substr(i1 + 3, i2 - i1 - 3) << endl;// gitee.com// 從i1 + 3這個下標,輸出i2 - i1 - 3個元素}cout << url.substr(i2 + 1) << endl; //wzf-sangreturn 0;
}
而我們可以將其功能分離出來,抽象成一個函數
// 網址
# include<string>
# include<iostream>
using namespace std;// 該函數用于分離網址的三個必要信息
void spilt_url(const string& url)
{//【在我們輸入網址敲回車之后,服務器做的第一件事就是將你輸入的網址拆成協議、域名、資源名稱】//【因此才能在對應協議下申請訪問對應的域名并根據資源名稱返回資源】// 現在有個要求:分離出url。size_t i1 = url.find(':'); // i1 = 5if (i1 != string::npos){cout << url.substr(0, i1) << endl; // https//從0這個下標,輸出i1個元素}size_t i2 = url.find('/', i1 + 3); // 從i1 + 3開始找if (i2 != string::npos){cout << url.substr(i1 + 3, i2 - i1 - 3) << endl;// gitee.com// 從i1 + 3這個下標,輸出i2 - i1 - 3個元素}// 在i2這個下標后面的都是資源名稱cout << url.substr(i2 + 1) << endl; // wzf-sang// + 1是因為i2是 / ,i2后面的才是資源名稱
}// 協議、域名、資源名稱
int main()
{string url("https://gitee.com/wzf-sang");string url2("https://leetcode.cn/problems/majority-element/description/?envType=study-plan-v2&envId=top-interview-150");//https是協議 http和https的差別就是https是加密的///gitee.com其實是個ip但是綁定了域名。如果不綁定域名這里是個ip【域名更好記住】//wzf-sang就是資源名稱。spilt_url(url);// https// gitee.com// wzf - sangspilt_url(url2);//https//leetcode.cn//problems/majority-element/description/?envType=study-plan-v2&envId=top-interview-150return 0;
}
2.2.5string類非成員函數
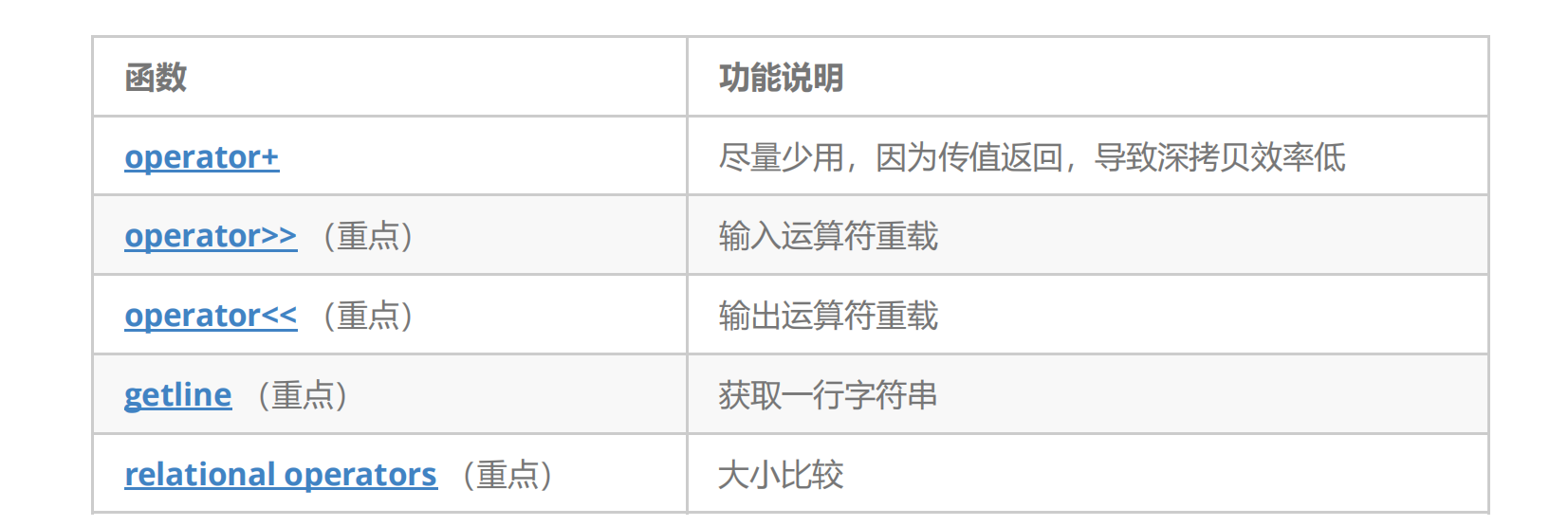
上面的幾個接口了解一下,下面的OJ題目中會有一些體現他們的使用。string類中還有一些其他的操作,這里不一一列舉,在需要用到時不明白了查文檔即可。
2.2.6.vs和g++下string結構的說明
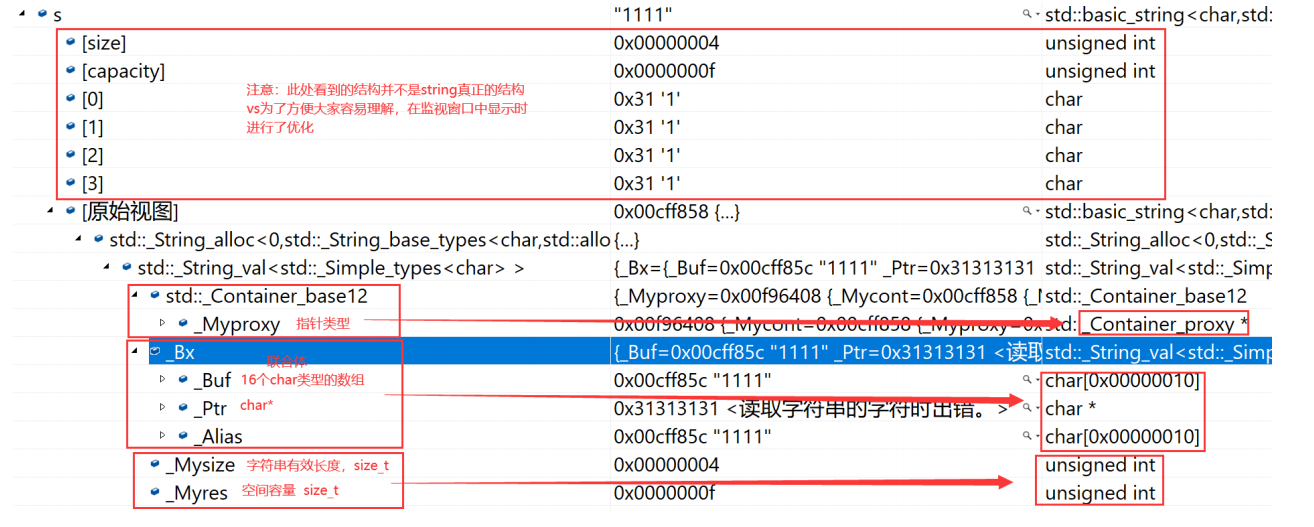
注意:下述結構是在32位平臺下進行驗證,32位平臺下指針占4個字節。
- vs下string的結構
string總共占28個字節,內部結構稍微復雜一點,先是有一個聯合體,聯合體用來定義string中字
符串的存儲空間:
當字符串長度小于16時,使用內部固定的字符數組來存放
當字符串長度大于等于16時,從堆上開辟空間
這種設計是合理的,大多數情況下字符串的長度都小于16,那string對象創建好之后,內
部已經有了16個字符數組的固定空間,不需要通過堆創建,效率高。
其次:還有一個size_t字段保存字符串長度,一個size_t字段保存從堆上開辟空間總的容量
最后:還有一個指針做一些其他事情。
故總共占16+4+4+4=28個字節
- g++下string的結構
G++下,string是通過寫時拷貝實現的,string對象總共占4個字節,內部只包含了一個指針,該指
針將來指向一塊堆空間,內部包含了如下字段:
-
空間總大小
-
字符串有效長度
-
引用計數
struct _Rep_base
{size_type _M_length;size_type _M_capacity;_Atomic_word _M_refcount;
};
- 指向堆空間的指針,用來存儲字符串。
2.2.7與string相關的oj題目
-
917. 僅僅反轉字母 - 力扣(LeetCode)
-
387. 字符串中的第一個唯一字符 - 力扣(LeetCode)
-
字符串最后一個單詞的長度
-
125. 驗證回文串 - 力扣(LeetCode)
-
415. 字符串相加 - 力扣(LeetCode)
-
541. 反轉字符串 II - 力扣(LeetCode)
-
557. 反轉字符串中的單詞 III - 力扣(LeetCode)
-
43. 字符串相乘 - 力扣(LeetCode)較難
-
找出字符串中第一個只出現一次的字符較難
)





:冒泡排序、選擇排序、插入排序)


——Learning Phase Competition for Traffic Signal Control)







)

