🍉 CSDN 葉庭云:https://yetingyun.blog.csdn.net/
一、什么是 Treelite?
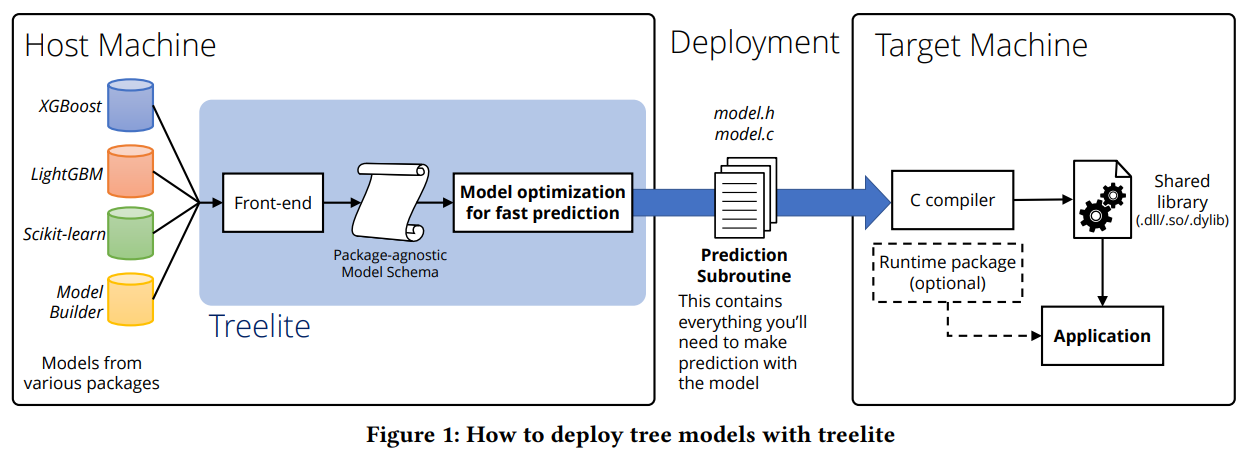
Treelite 是一個專門用于將決策樹集成模型高效部署到生產環境中的機器學習模型編譯器,特別適合處理大批量數據的推理任務,能夠顯著提升推理性能。它提供多個前端接口,可與其他集成梯度提升樹庫(如 XGBoost、LightGBM 和 scikit-learn)配合使用。通過編譯優化,Treelite 能將模型的性能提升 2 到 6 倍,相比于原生模型。Treelite 的核心功能在于將樹模型編譯為高效的 C 代碼,從而在推理階段實現顯著的性能提升。
Treelite 官網:https://treelite.readthedocs.io/en/latest/index.html#
Treelite 的主要功能
- 模型編譯:將決策樹模型編譯成高效的可部署形式,方便部署。
- 性能優化:使用 Treelite 進行模型編譯優化后的性能相比于原生的 XGBoost、LightGBM 模型通常會提升 2-4 倍。
- 互操作性:支持與其他樹模型庫(例如 XGBoost、LightGBM 和 scikit-learn)的無縫集成。
Treelite 的設計特點
- 模塊化設計:前端(與其他樹庫交互的部分)和后端(生成可部署 C 文件的部分)之間有明顯的分離。前端負責與其他樹庫的交互,后端負責生成可部署的 C 文件。這種設計使得 Treelite 能夠輕松地與不同的樹模型庫集成,同時保持其核心編譯功能的獨立性。
- 前端接口:提供了多個前端接口來與其他樹庫配合使用,包括專用接口導入 XGBoost、LightGBM 和 scikit-learn 生成的模型
- 可擴展性:允許用戶以編程方式指定其模型,還支持自定義模型編譯。
Treelite 支持的模型類型
- 決策樹集成:包括隨機森林和梯度提升決策樹(GBDTs)。
- 支持的前端接口:XGBoost、LightGBM 和 scikit-learn。
Treelite 的設計與實現
- 編譯過程:Treelite 的編譯過程包括將樹模型轉換為中間表示(Intermediate Representation,IR),然后優化該 IR 并生成最終的 C 代碼。這一過程充分利用了編譯器優化技術,將樹模型轉換為高效的代碼,從而在推理階段實現快速響應。
- 優化策略:Treelite 采用多種優化策略,包括邏輯分支優化、內存訪問優化和并行計算優化,以提高模型推理速度。這些優化策略使得 Treelite 生成的 C 代碼在推理時能夠充分利用硬件資源,實現高性能推理。
Treelite 的性能優勢:優化后的模型在預測速度上相比原生模型有顯著提升,最高可提高 6 倍。Treelite 主要在以下兩個方面進行了改進:
- 通過規則編譯加快預測速度。將決策規則 “編譯” 為嵌套的 if-else 條件,可以將給定的樹集成模型轉化為 C 程序。在轉換過程中,每個測試節點被轉化為一對 if-else 語句,隨后遞歸地將左右子節點擴展為 C 代碼,直至觸及每個葉節點。通過這種方式,我們能夠針對正在檢查的模型實現編譯時優化。以前,模型在運行時從文件中加載,且預測邏輯并未考慮到與特定模型相關的信息。然而,現在通過規則編譯,編譯器能夠訪問正在編譯的特定模型中的每一位信息,進而利用這些信息進一步優化生成的機器代碼。作為早期演示,Treelite 提供了兩種優化方案。
- 邏輯分支優化,對條件分支進行注釋。我們預測每個條件的可能性時,會依據訓練數據中滿足該條件的數據點數量。若條件在訓練數據中有至少 50% 的概率為真,則將其標記為 “預期為真”;否則,標記為 “預期為假”。GCC 和 clang 編譯器均提供
__builtin_expect這一編譯器內在函數,用以指定條件的預期結果。這有助于編譯器更智能地決定分支順序,從而改進分支預測。 - 在邏輯比較優化方面,原始的分支比較可能涉及浮點數比較邏輯。為提高效率,我們建議將浮點數比較量化為整數數值比較。這一優化措施將測試節點中的所有閾值轉換為整數,從而確保每個閾值條件都執行整數比較,而非傳統的浮點比較。通過 “量化” 閾值為整數索引,在 x86-64 等平臺上,將浮點比較替換為整數比較,不僅減少了可執行代碼的大小,還改善了數據局部性,進而提升了性能。
Treelite 的應用場景
- 大規模數據推理:特別適用于需要處理大量數據的場景。
- 模型部署:高效地將訓練好的模型部署到生產環境中。
通過這些功能和應用場景,Treelite 為數據科學家和機器學習工程師提供了一個強大的工具,用于優化決策樹集成模型的部署和推理性能。
二、為什么要用 Treelite?
在生產環境部署決策樹集成模型,為什么要使用 Treelite?
在生產環境中部署決策樹集成模型時,選擇使用 Treelite 的主要原因包括以下幾點:
- 模型導出和獨立的預測庫:Treelite 可以將訓練好的模型導出為獨立的預測庫,從而在部署時無需安裝任何機器學習包,簡化部署流程。
- 模型編譯優化:Treelite 可以將樹模型編譯優化為單獨的庫,顯著提高模型的預測速度,例如,XGBoost 模型的預測速度可提高 2~6 倍。
- 支持多種樹模型:Treelite 支持包括隨機森林、GBDT、XGBoost、LightGBM 和 scikit-learn 等在內的多種流行機器學習庫。
- 跨語言支持:Treelite 提供多個前端接口,便于將模型部署到不同編程語言環境(如 C、Java 等),從而更容易地集成到現有生產系統中。
- 性能提升:使用 Treelite 進行模型編譯優化后,性能通常比原生的 XGBoost、LightGBM 模型提升 2~4 倍,這對處理大批量數據的推理場景尤為重要。
- 良好的社區支持:Treelite 擁有一個活躍的社區,提供詳細的文檔和豐富的資源,如官方文檔、技術論文和示例代碼等。這些資源為開發者提供了深入學習和使用的便利,進一步推動了 Treelite 在機器學習領域的應用和發展。
綜上所述,Treelite 以其模型導出、編譯優化、多模型支持、跨語言部署和性能提升等特點,成為生產環境中部署決策樹集成模型的首選工具。
三、使用 Treelite 部署決策樹集成模型的具體操作步驟
Treelite 是一個專門用于加速決策樹集成模型推理(預測)速度的庫。在生產環境中部署決策樹集成模型時,使用 Treelite 可以顯著加快模型的推理速度。以下是使用 Treelite 在生產環境中部署決策樹集成模型的具體操作步驟:
1. 安裝 Treelite 和 TL2cgen:
確保你已經安裝好了 Treelite 和 TL2cgen。如果沒有安裝,可以使用以下命令進行安裝:
pip install treelite
pip install tl2cgen
2. 準備模型:
確保你擁有一個經過良好訓練的決策樹集成模型,如使用 XGBoost、LightGBM 或 CatBoost 訓練得到的模型。模型需保存為支持的格式,常見的格式包括 JSON、BSON 或 pickle。
3. 轉換為 Treelite 格式:
將你的決策樹模型轉換成 Treelite 可以識別的格式。通常,這需要使用 Treelite 提供的 API 來加載模型。下面是一個使用 XGBoost 模型的示例:
import tl2cgen
import treelite
import xgboost as xgb# Importing tree ensemble models:https://treelite.readthedocs.io/en/latest/tutorials/import.html## Treelite 3.x 及更早版本
# xgb_model = treelite.Model.load("my_model.json", model_format="xgboost_json")
# JSON format
model = treelite.frontend.load_xgboost_model("my_model.json")
# Legacy binary format
model = treelite.frontend.load_xgboost_model_legacy_binary("my_model.model")
# To import models generated by LightGBM, use the load_lightgbm_model() method:
model = treelite.frontend.load_lightgbm_model("lightgbm_model.txt")
補充以下內容:
- TL2cgen:Treelite 樹編譯器已遷移到 TL2cgen。TL2cgen(TreeLite 2 C 生成器)是一個決策樹模型的模型編譯器。您可以將任何決策樹集成模型(隨機森林、梯度提升模型)轉換為 C 代碼,并將其作為原生二進制文件分發。
- TL2cgen 與 Treelite 無縫集成。任何由 Treelite 支持的樹模型都可以通過 TL2cgen 轉換為 C 語言代碼。TL2cgen 是一個模型編譯器,能夠將樹模型轉換為 C 代碼。它可以轉換所有采用 Treelite 格式存儲的樹模型。TL2cgen 是眾多使用 Treelite 作為庫的應用程序之一。
- 從 4.0 版本起,Treelite 停止支持將樹模型編譯為 C 代碼,該功能已轉移至 TL2cgen。從 4.0 版本起,Treelite 已轉變為一個小型庫,使得其他 C++ 應用程序能夠在磁盤和網絡上交換及存儲決策樹。使用 Treelite 可以幫助應用程序開發者支持多種樹模型,同時減少代碼重復并保持高度的準確性。樹模型采用一種高效的二進制格式進行存儲。
4. 編譯 Treelite 模型:
為了加快部署推理速度,Treelite 需要將模型編譯成高效的機器碼。這一步驟通常包括指定目標平臺和選擇編譯器選項。例如,若你打算在 CPU 上運行模型,可以采取以下步驟:
# 編譯模型為動態鏈接庫
toolchain = 'gcc' # 或者其他你使用的編譯器,如 'clang', 'msvc'
tl2cgen.export_lib(model, toolchain=toolchain, libpath="./mymodel.so", params={'parallel_comp': 32})
5. 加載編譯后的模型:
在生產環境中,需要加載編譯后的模型文件,如動態鏈接庫(.so 文件或 .dll 文件),使用 tl2cgen 的 Predictor 類加載 .so 文件。
predictor = tl2cgen.Predictor("./mymodel.so")
6. 進行預測:
使用編譯后的模型對新數據進行預測時,需確保輸入數據的格式與訓練時的數據格式一致:
# 假設 X 是特征矩陣
dmat = tl2cgen.DMatrix(X[10:20, :])
out_pred = predictor.predict(dmat)
print(out_pred)
7. 性能優化:
如有必要,可對模型進行性能優化,例如通過量化參數以減少內存占用并提高推理速度。
8. 集成到生產環境:
最后,需將編譯后的模型及必要的 Treelite 運行時代碼集成至生產環境,以便實際應用。
請注意,具體的 API 調用和參數設置可能因模型類型和所用機器學習框架而異。務必參考 Treelite 官方文檔獲取最新、準確的信息。
總的來說,Treelite 是一款優秀的決策樹集成模型部署和推理優化工具,支持將模型部署為 .so 文件,不僅便于其他語言調用,還能有效防止模型參數泄露。
📚? 相關鏈接:
-
AI 編譯器技術剖析(三)- 樹模型編譯工具 Treelite 詳解
-
Treelite:樹模型部署加速工具(支持 XGBoost、LightGBM 和 Sklearn)
-
Treelite is a universal model exchange and serialization format for decision tree forests.
-
TL2cgen: model compiler for decision trees
![[Vite]Vite插件生命周期了解](http://pic.xiahunao.cn/[Vite]Vite插件生命周期了解)
、大數乘法】)








及Python和MATLAB實現)

方法慢)


)
)

opencv處理圖像視頻)
