文章目錄
- 一、為什么使用文件?
- 二、什么是文件?
- 1、程序文件
- 2、數據文件
- 3、文件名
- 三、文件的打開和關閉
- 1、文件指針
- 2、文件的打開和關閉
- 四、文件的順序讀寫
- 1. 8個重要的庫函數
- 1.1 單字符輸入輸出【fputc和fgetc】
- 1.2 文本行輸入輸出【fputs和fgets】
- 1.3 格式化輸入輸出【fprintf和fscanf】
- 1.4 二進制輸入輸出【fwrite和fread】
- 2、拓展:默認打開的三個流
- 3、對比一組函數
- 五、文件的隨機讀寫
- 1、fseek
- 2、ftell
- 3、rewind
- 六、文本文件和二進制文件
- 七、文件讀取結束的判定
- 1、被錯誤使用的feof
- 2、fgetc、fgets、fscanf、fread結束判斷解讀
- 3、實例代碼走讀
- 八、文件緩沖區
- 拓展:文件外排序
- 1、前言
- 2、思路解析
- 3、代碼詳解
一、為什么使用文件?
-
我們前面學習結構體時,寫了通訊錄的程序,當通訊錄運行起來的時候,可以給通訊錄中增加、刪除數據,此時數據是存放在內存中,當程序退出的時候,通訊錄中的數據自然就不存在了,等下次運行通訊錄程序的時候,數據又得重新錄入,如果使用這樣的通訊錄就很難受
-
所以就想到了通訊錄就應該把信息記錄下來,只有我們自己選擇刪除數據的時候,數據才不復存在。這就涉及到了數據持久化的問題,我們一般數據持久化的方法有,把數據存放在【磁盤文件】、存放到【數據庫】等方式
二、什么是文件?
-
磁盤上的文件是文件
-
但是在程序設計中,我們一般談的文件有兩種:程序文件、數據文件(從文件功能的角度來分類的)
1、程序文件
-
包括源程序文件(后綴為.c),目標文件(windows環境后綴為.obj),可執行程序(windows環境后綴為.exe)。
-
【程序文件】一般指的是我們創建工程時所編寫的代碼,也就想下面這個【test.c】一樣
2、數據文件
-
文件的內容不一定是程序,而是程序運行時讀寫的數據,比如程序運行需要從中讀取數據的文件,或者輸出內容的文件。
-
【數據文件】一般指通過程序去操縱的那個文件
-
就想上面的這個【test.txt】就是一個數據文件,通過【test.exe】運行起來時,內存中有有了數據,此時我們可以將數據寫到這個【test.txt】中,自然也可以從這個文件中讀取數據到內存中
3、文件名
-
一個文件要有一個唯一的文件標識,以便用戶識別和引用
-
文件名包含3部分:文件路徑+文件名主干+文件后綴
-
例如:
c:\code\test.txt -
為了方便起見,文件標識常被稱為文件名。
三、文件的打開和關閉
1、文件指針
-
緩沖文件系統中,關鍵的概念是文件類型指針,簡稱文件指針
-
每個被使用的文件都在內存中開辟了一個相應的文件信息區,用來存放文件的相關信息(如文件的名字,文件狀態及文件當前的位置等)。這些信息是保存在一個結構體變量中的。該結構體類型是有系統聲明的,取名
FILE
例如,VS2019編譯環境提供的 stdio.h 頭文件中有以下的文件類型申明:
struct _iobuf {char *_ptr;int _cnt;char *_base;int _flag;int _file;int _charbuf;int _bufsiz;char *_tmpfname;};
typedef struct _iobuf FILE;
FILE* pf;//文件指針變量
- 不同的C編譯器的FILE類型包含的內容不完全相同,但是大同小異。每當打開一個文件的時候,系統會根據文件的情況自動創建一個FILE結構的變量,并填充其中的信息,使用者不必關心細節
- 一般都是通過一個FILE的指針來維護這個FILE結構的變量,這樣使用起來更加方便。我們來看看如何創建一個
FILE*的指針變量
FILE* pf; //文件指針變量
- 定義
pf是一個指向FILE類型數據的指針變量。可以使pf指向某個文件的文件信息區(是一個結構體變量)。通過該文件信息區中的信息就能夠訪問該文件。也就是說,通過文件指針變量能夠找到與它關聯的文件
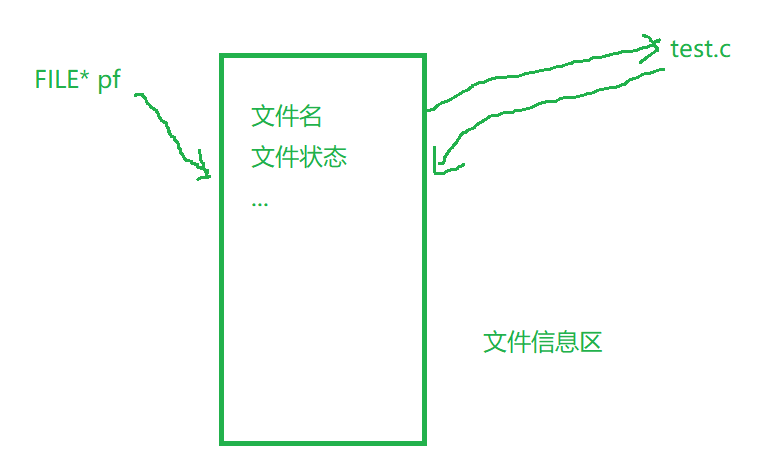
2、文件的打開和關閉
注:文件在讀寫之前應該先打開文件,在使用結束之后應該關閉文件
- ANSIC 規定使用
fopen函數來打開文件,fclose來關閉文件。顯示如何打開和關閉文件的個格式
//打開文件
FILE * fopen ( const char * filename, const char * mode );
//關閉文件
int fclose ( FILE * stream );
- 下面是文件的一些打開方式,有很多的操作,大家挑重點記就行
注:a即append(追加);b即binary(二進制)
| 文件使用方式 | 含義 | 如果指定文件不存在 |
|---|---|---|
| 【重點】“r”(只讀) | 為了輸入數據,打開一個已經存在的文本文件 | 出錯 |
| 【重點】“w”(只寫) | 為了輸出數據,打開一個文本文件 | 建立一個新的文件 |
| 【重點】“a”(追加) | 向文本文件尾添加數據 | 建立一個新的文件 |
| rb”(只讀) | 為了輸入數據,打開一個二進制文件 | 出錯 |
| “wb”(只寫) | 為了輸出數據,打開一個二進制文件 | 建立一個新的文件 |
| “ab”(追加) | 向一個二進制文件尾添加數據 | 出錯 |
| “r+”(讀寫) | 為了讀和寫,打開一個文本文件 | 出錯 |
| “w+”(讀寫) | 為了讀和寫,建議一個新的文件 | 建立一個新的文件 |
| “a+”(讀寫) | 打開一個文件,在文件尾進行讀寫 | 建立一個新的文件 |
| “rb+”(讀寫) | 為了讀和寫打開一個二進制文件 | 出錯 |
| “wb+”(讀寫) | 為了讀和寫,新建一個新的二進制文件 | 建立一個新的文件 |
| “a+”(讀寫) | 打開一個二進制文件,在文件尾進行讀寫 | 建立一個新的文件 |
例:
int main()
{//打開文件FILE* pf = fopen("test.txt", "w");if (NULL == pf){perror("fail fopen");return 1;}//寫文件// ...//關閉文件fclose(pf);pf = NULL; //防止野指針return 0;
}
四、文件的順序讀寫
1. 8個重要的庫函數
- 下面的8個庫函數都很重要,大家最好都要記住,而且對于它們的用法也要熟知
| 功能 | 函數名 | 適用于 |
|---|---|---|
| 字符輸入函數【讀】 | fgetc | 所有輸入流 |
| 字符輸出函數【寫】 | fputc | 所有輸出流 |
| 文本行輸入函數【讀】 | fgets | 所有輸入流 |
| 文本行輸出函數【寫】 | fgets | 所有輸入流 |
| 格式化輸入函數【讀】 | fscanf | 所有輸入流 |
| 格式化輸出函數【寫】 | fprintf | 所有輸入流 |
| 二進制輸入【讀】 | fread | 文件 |
| 二進制輸入【寫】 | fwrite | 文件 |
對于上面的這些函數的使用最關鍵的一點就是:【讀】對應的輸入流,【寫】對應的輸出流
- 在初識C語言時,我們學習了【scanf】和【printf】,只要了如何從鍵盤讀取數據,然后將數據顯示在屏幕上
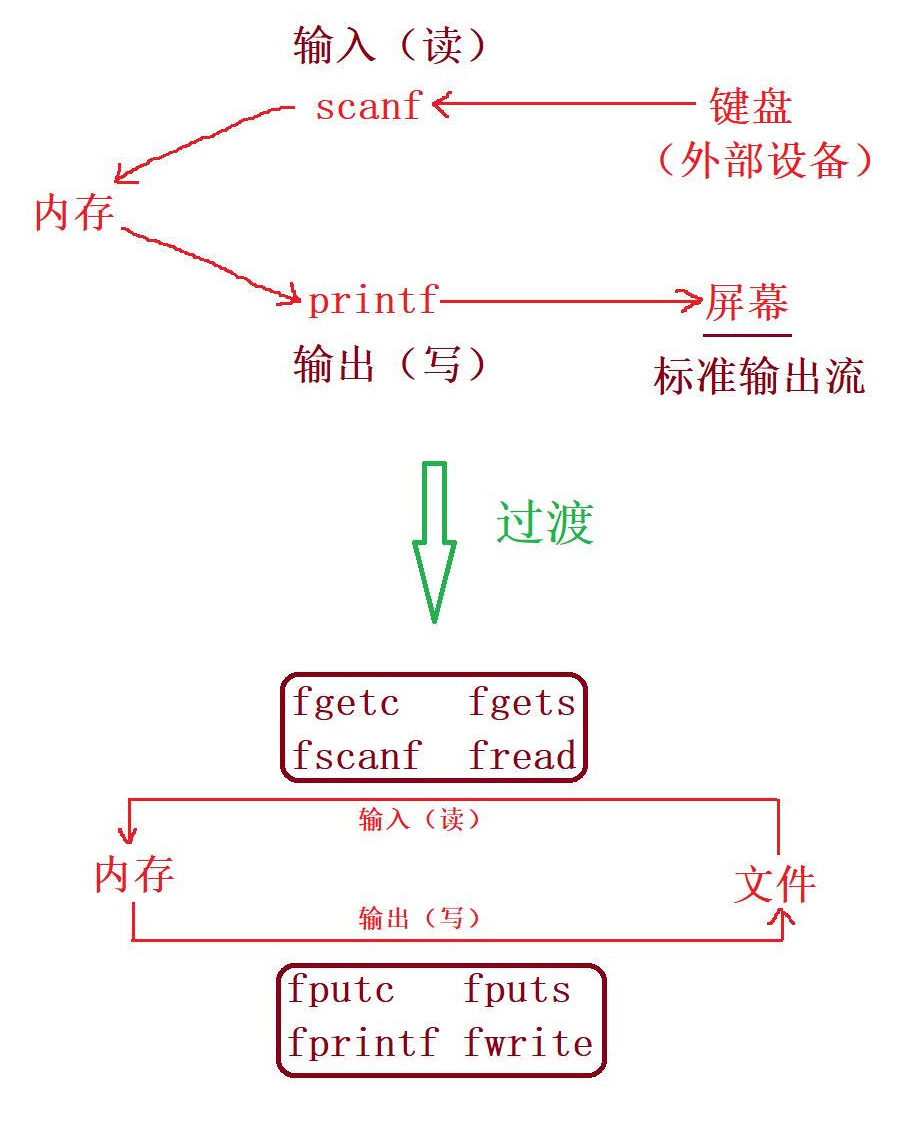
- 現在我們可以從鍵盤、屏幕過渡到文件,也可以從文件讀、寫數據
1.1 單字符輸入輸出【fputc和fgetc】
- 首先我們去cplusplus里面找到這兩個函數的描述
int fputc ( int character, FILE * stream );
int fgetc ( FILE * stream );


好,有了一個基本的了解后,我們就到VS2019中去實操一下
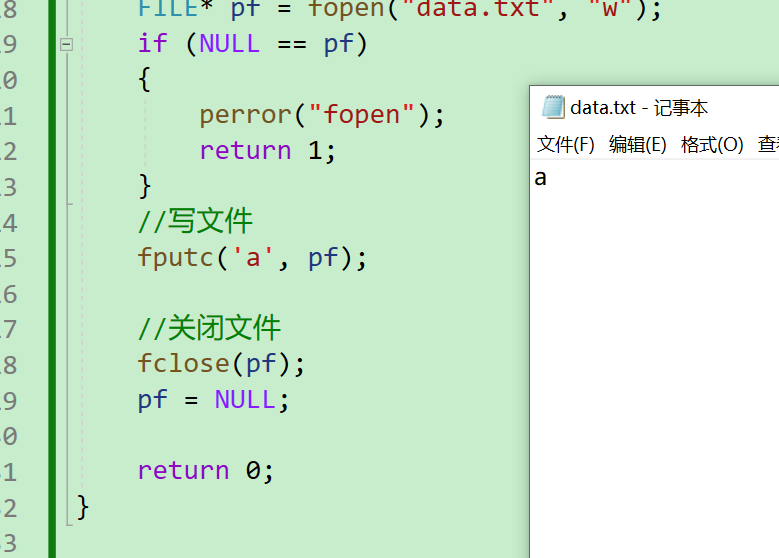
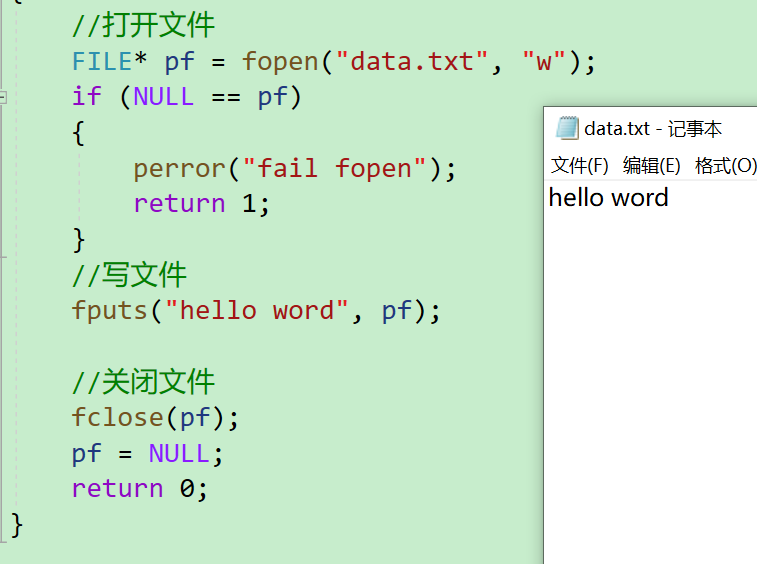
- 首先是寫文件,我們往【test.txt】中寫一個字符a進去
#include<stdio.h>
int main()
{//打開文件FILE* pf = fopen("data.txt", "w");if (NULL == pf){perror("fopen");return 1;}//寫文件fputc('a', pf);//關閉文件fclose(pf);pf = NULL;return 0;
}
- 既然能寫一個,那也就可以寫多個

- 那我們能不能將26個字母都寫進去呢?當然是可以的,不過不是這么一句一句寫,要用循環來寫
for (char ch = 'a'; ch <= 'z'; ch++)
{fputc(ch, pf);
}
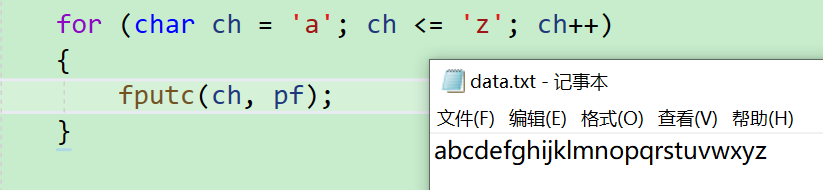
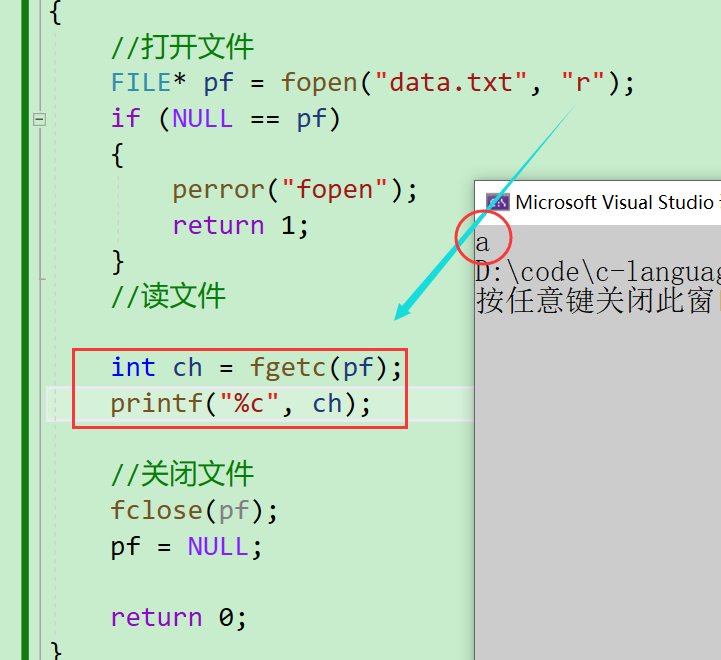
- 可以寫數據了,那能不能將我們寫進去的內容再讀出來呢,這就要用到 fgetc() 了,而且在打開文件的時候要以【讀】也就是【r】的形式打開
- 既然是讀取數據,那我們就要去接收讀到的這個數據,剛才看到這個庫函數的返回值是【int】,是一個ASCLL碼值,所以我們就這么去接收
int ch = fgetc(pf);
printf("%c", ch);
- 能讀一個,那也能讀多個,我們多讀幾個試試
int ch = fgetc(pf);
printf("%c", ch);ch = fgetc(pf);
printf("%c", ch);ch = fgetc(pf);
printf("%c", ch);ch = fgetc(pf);
printf("%c", ch);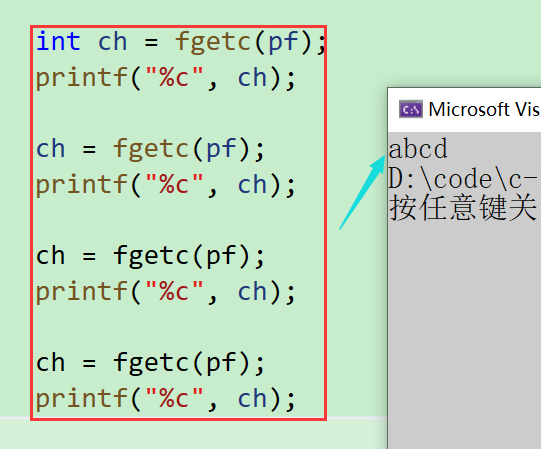
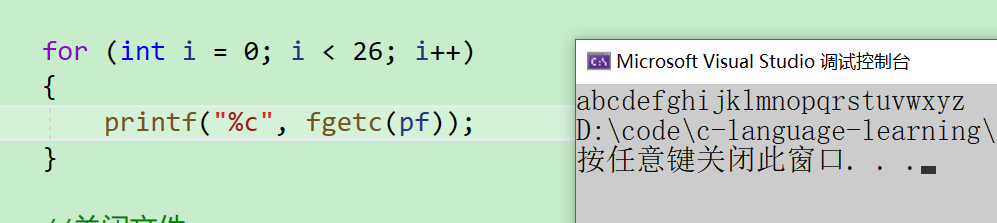
- 然后我們再把這26個字母都讀出來試試
for (int i = 0; i < 26; ++i)
{printf("%c", fgetc(pf));
}
- 但是呢,我們平常在讀取文件中內容的時候,并不知道里面有什么東西,有多少東西,因此應該寫一個通過的程序,才能適應更多的情況
- 我們再仔細看看
fgetc的簡述。可以看到當它讀到文件末尾的時候便會返回EOF,即End Of File(文件結束)

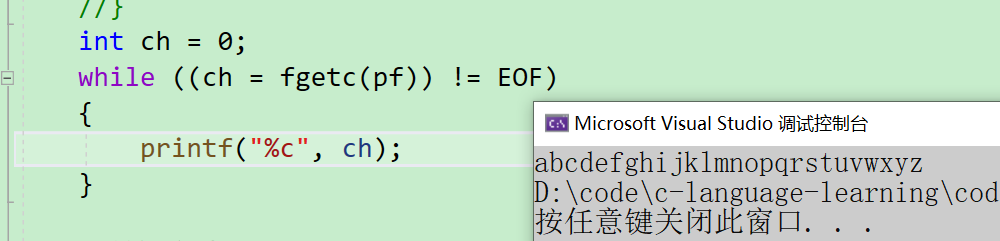
- 此時我們就可以將代碼寫成這樣。將for循環改為while循環
int ch = 0;
while ((ch = fgetc(pf)) != EOF)
{printf("%c", ch);
}
可以看到,一樣是可以顯示出來的
1.2 文本行輸入輸出【fputs和fgets】
- 首先來了解一下這個兩個函數
fputs
fgets
int fputs ( const char * str, FILE * stream );
char * fgets ( char * str, int num, FILE * stream );


- 然后我們像向文件中寫入一個字符串試試
- 接下去多寫幾行試試
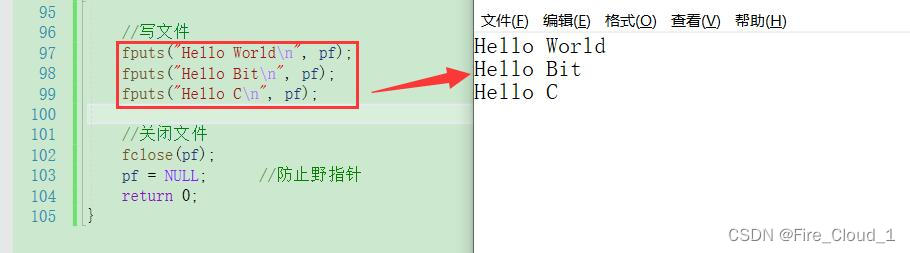
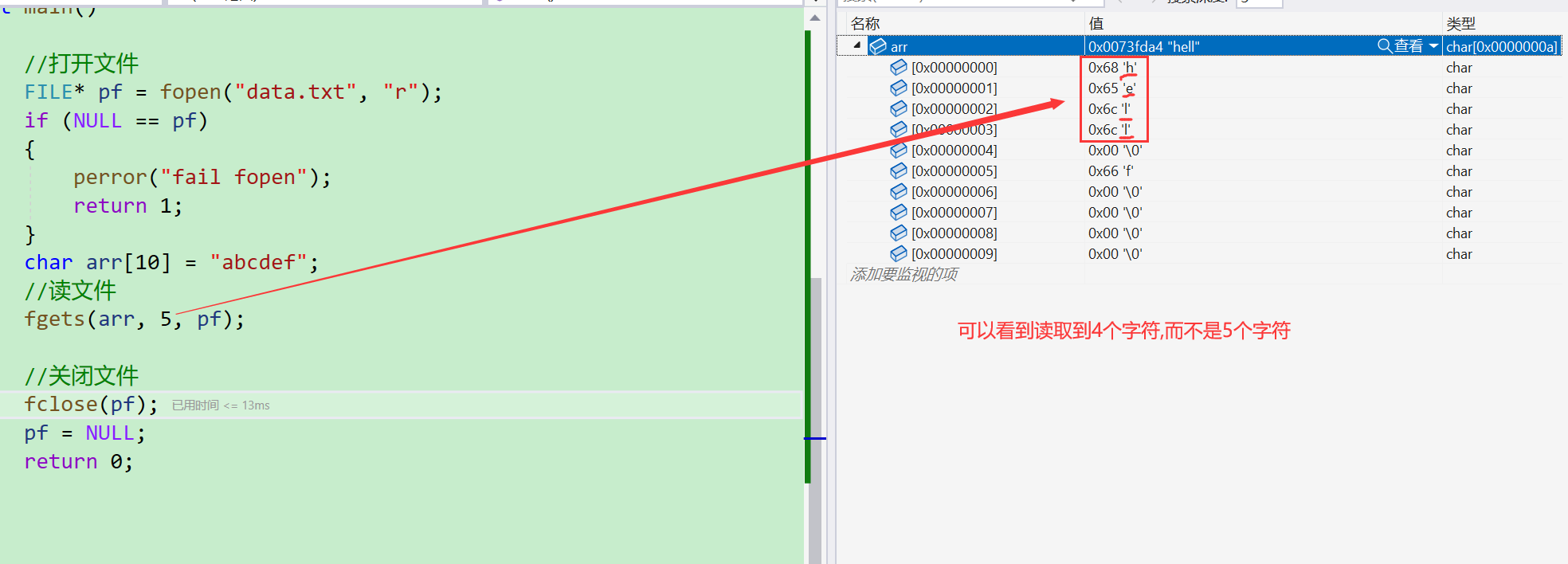
- 可以寫東西進去了,接下去一樣,將我們寫的東西讀出來試試
- 可以看到在讀取結束之后
DeBug和顯示窗口都可以看到只有四個字符,并沒有5個,這是為什么呢?似乎是讀到了一個換行符
- 我們再仔細地觀察一個這個函數
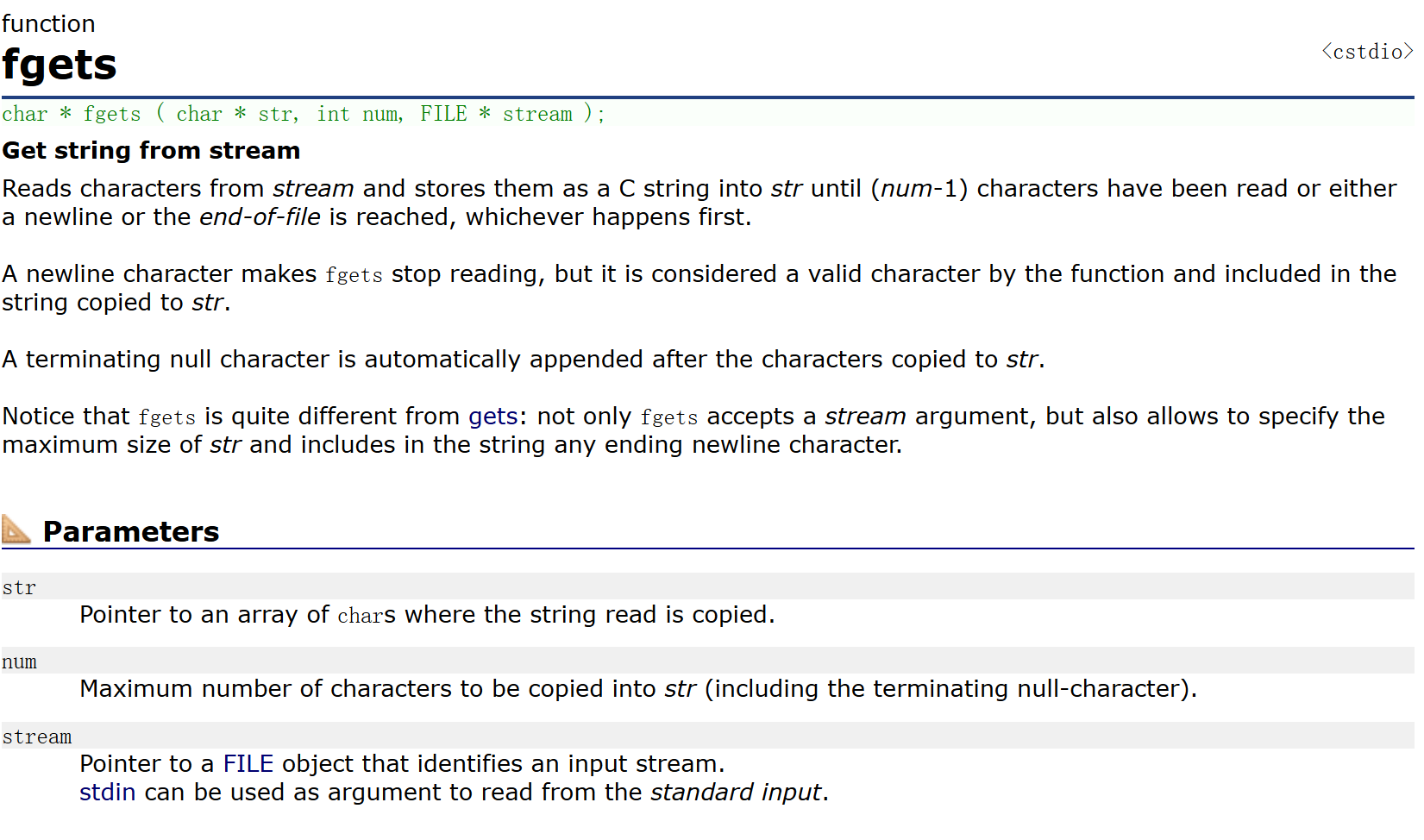
- 看了一些官方文檔的描述,應該清楚為什么會只有四個了吧,
- 若是最大字符數num < 本行的字符數,那么就會顯示【num - 1】個,最后一個給到【\0】,也就是對于字符串而言的結束符
- 若是最大字符數num > 本行的字符數,那么除了顯示本行的所有字符之外,還會讀入一個換行符,接著就不會往下讀了。若是需要讀取下一行數據,則需要再次使用這個函數進行讀取
1.3 格式化輸入輸出【fprintf和fscanf】
fprintf
fscanf
- 看到這個【fprintf】和【fscanf】是不是又想起來我們之前學的【printf】和【scanf】呢,我們對其進行一個對比。如下圖所示
int fprintf ( FILE * stream, const char * format, ... );
int fscanf ( FILE * stream, const char * format, ... );


- 既然是進行格式化的輸入輸出,那我們就來嘗試寫一些不同格式的內容到文件里去,這里直接定義一個結構體
typedef struct student {char name[20];int height;float score;
}st;
st s = { "zhangsan", 175, 95.5 };//寫文件
fprintf(pf, "%s %d %f", s.name, s.height, s.score);
- 可以看到,就寫進去了
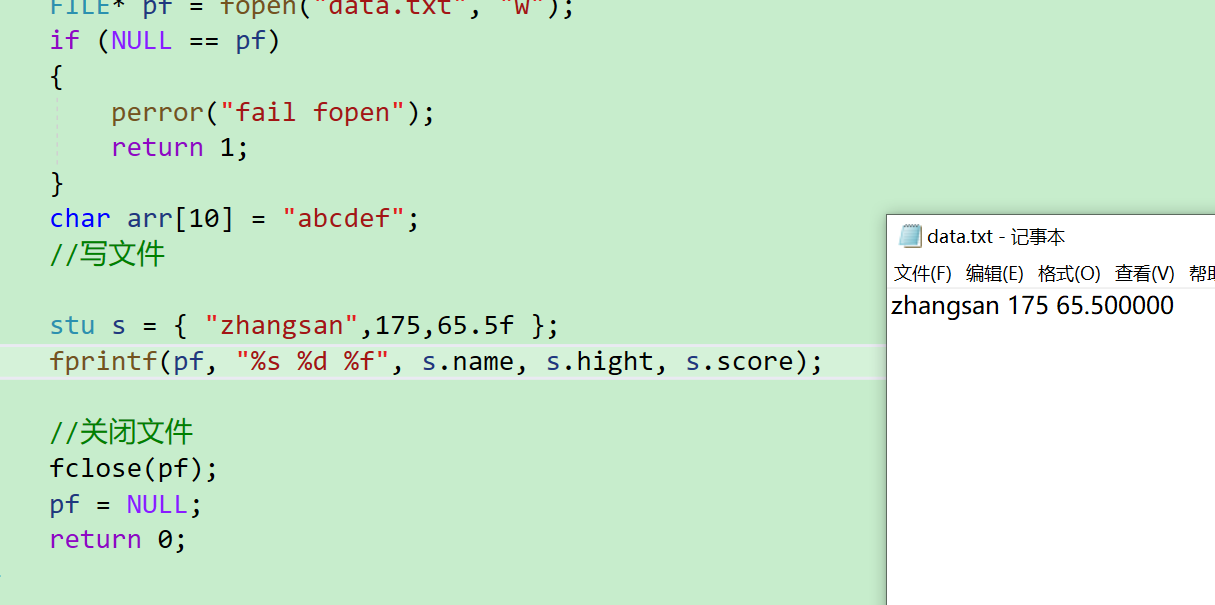
還是一樣也可以讀出來打印

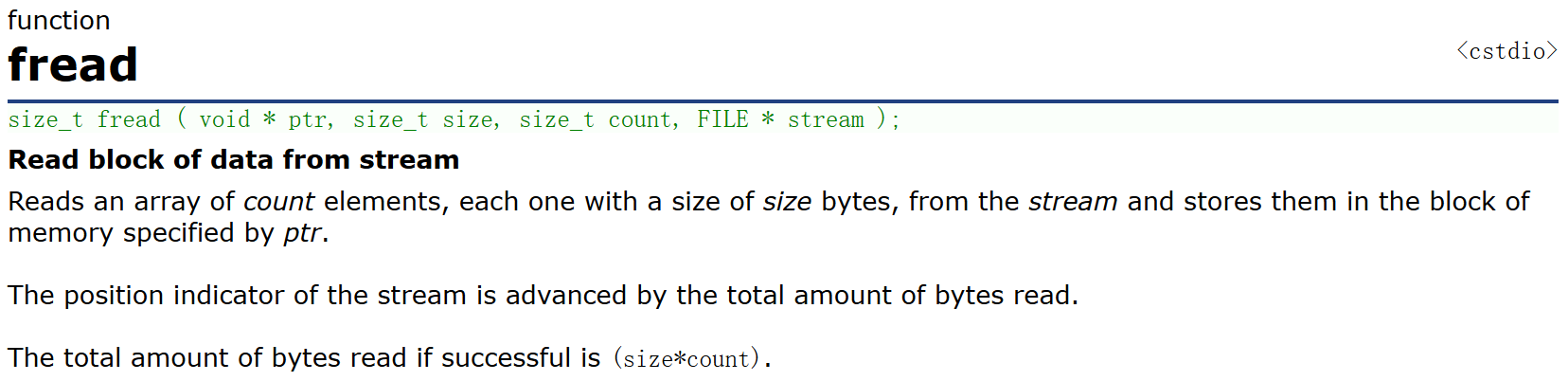
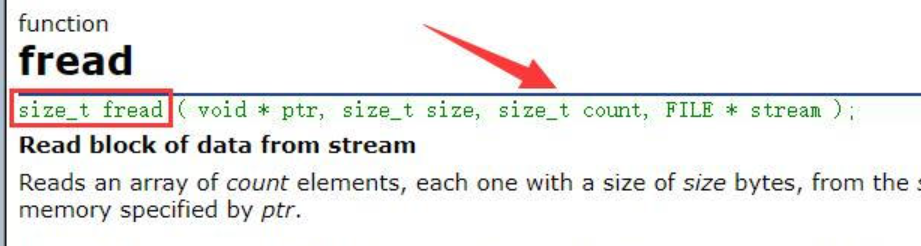
1.4 二進制輸入輸出【fwrite和fread】
fwite
fread
然后繼續看一下
size_t fwrite ( const void * ptr, size_t size, size_t count, FILE * stream );
size_t fread ( void * ptr, size_t size, size_t count, FILE * stream );

- 可以看到文件中是寫入了一些數據,但是呢寫進去的東西是亂碼的樣子,看不太懂
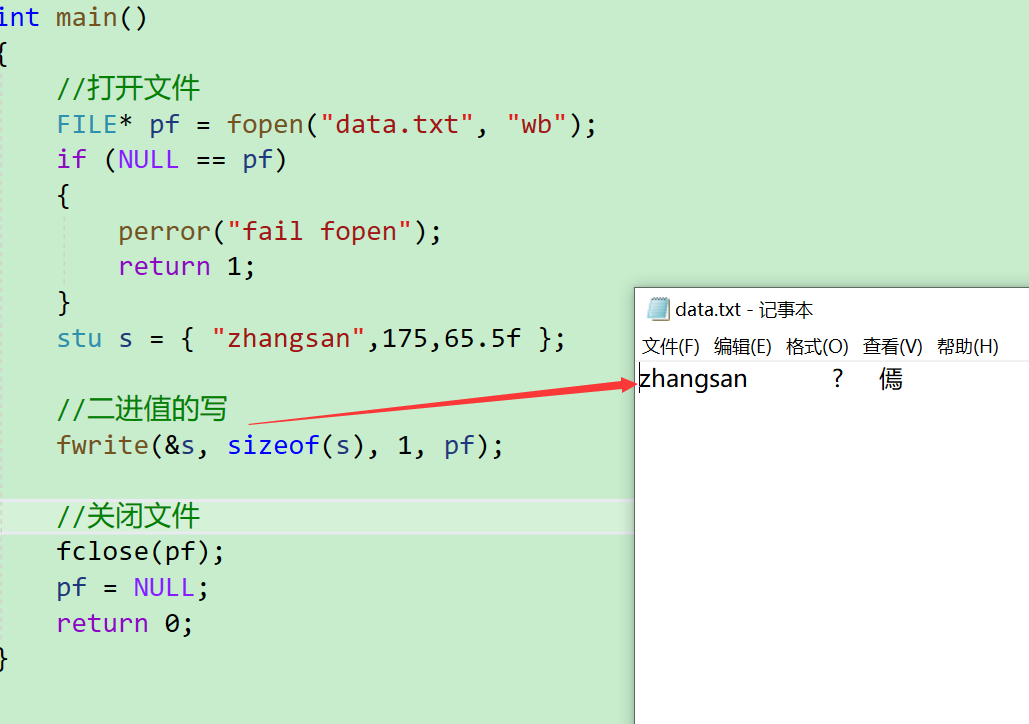
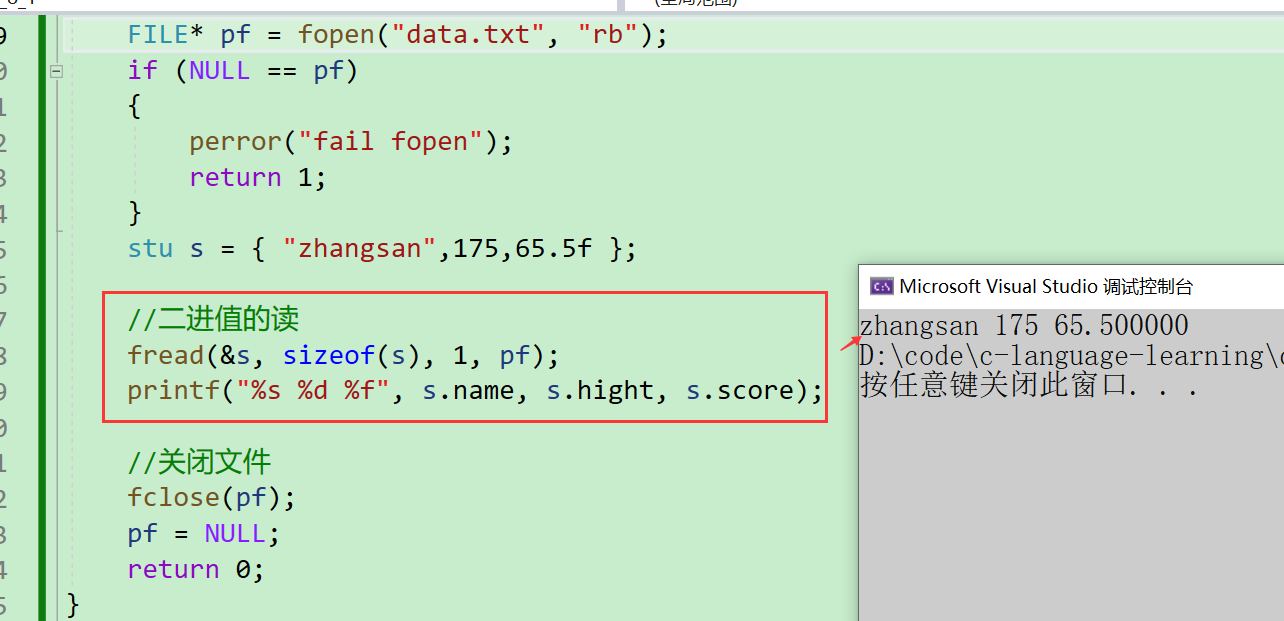
- 既然都是以二進值寫的,那么我們也需要以二進值讀
可以看到,以二進值的方式讀出來了
2、拓展:默認打開的三個流
對于任何一個C語言程序,只要運行起來,就會默認地打開三個流
- stdin - 標準輸入流 - 鍵盤
- stdout - 標準輸出流 - 屏幕
- stderr - 標準輸錯誤 - 屏幕
- 通過觀看源碼可以知曉,他們都是以宏定義的形式存放在內存中的,之前我們說過,對于宏定義而言是在程序開始之前就定義好的,也就是當程序運行起來之后,那它們就會存在了

- 然后我們去程序中運行一下試試
int ch = fgetc(stdin);
fputc(ch, stdout);
- 然后可以看到,我們確實可以使用【stdin】和【stdout】這兩個流來進行輸入和輸出

int ch = 0;
fscanf(stdin, "%c", &ch);
fprintf(stdout, "%c", ch);

3、對比一組函數
- 上面講到了8個有關文件順序讀寫的庫函數,接下去給大家對比一下一組函數
- scanf / fscanf / sscanf
- printf / fprintf / sprintf
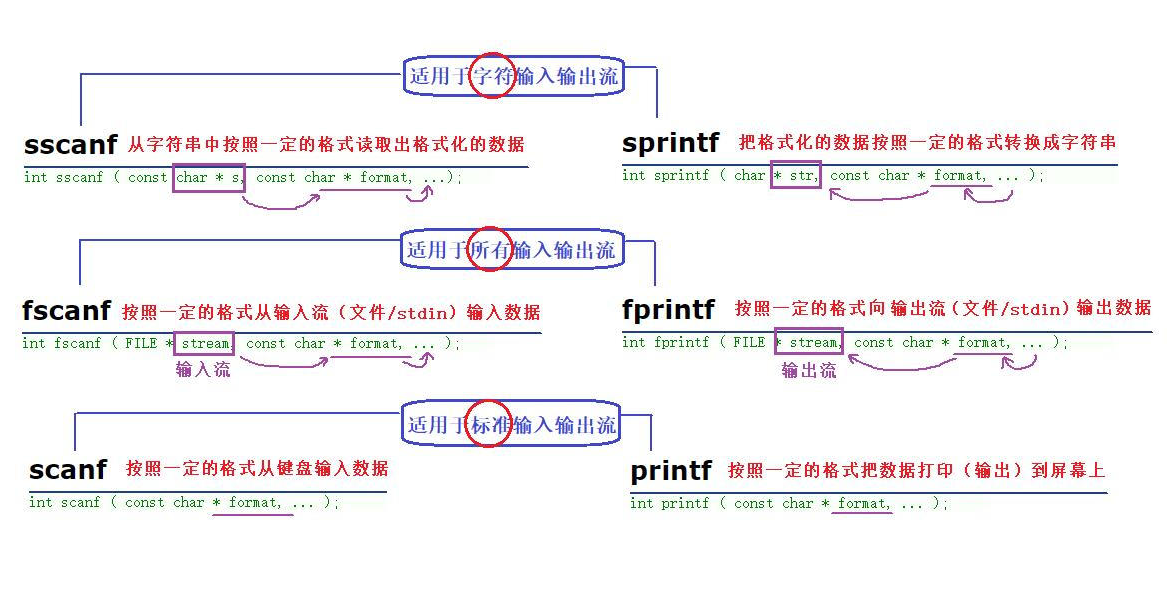
- 主要還是來看看【sprintf】和【sscanf】這兩個新面貌
int sprintf ( char * str, const char * format, ... );

int sscanf ( const char * s, const char * format, ...);

- 接下去我們通過代碼來看看是不是真的可以實現
char buf[100] = { 0 };
st s = { "zhangsan", 170, 95.5f };
st tmp = { 0 };//能否將這個結構體的成員轉化為字符串
sprintf(buf, "%s %d %f", s.name, s.height, s.score);
printf("%s\n", buf);//能否將這個字符串中內容還原為一個結構體數據呢
sscanf(buf, "%s %d %f", tmp.name, &(tmp.height), &(tmp.score));printf("%s %d %f", tmp.name, tmp.height, tmp.score);
- 可以看到,我將一個結構體數據以格式化的形式寫到了一個字符串中,然后又從這個字符串中以格式化的形式讀取數據到一個結構體變量中,這么轉換來轉換去,完全沒有問題。

- 那可能這么講還是有點抽象,我們通過一個現實中開發的場景再來描述一下。比如說前端給到用戶一個收集信息的表單,用戶輸入數據之后呢,前端就將這些信息用“+”號做了一個拼接給到后端,后端呢為了要識別這些信息,一定會創建一個結構體,里面包含這些信息的,這個時候就可以使用到我們上面所說的【sscanf】以格式化的方式去讀取這個字符串了,然后就可以解析出用戶的這些數據,然后去進行一個處理了
- 當然在現實的軟件開發中,是不會這么去做的,因為有現成封裝的API可以調用,庫里面會提供一個【序列化/反序列化】的API可以調用,開發者無需考慮其底層的實現
五、文件的隨機讀寫
1、fseek
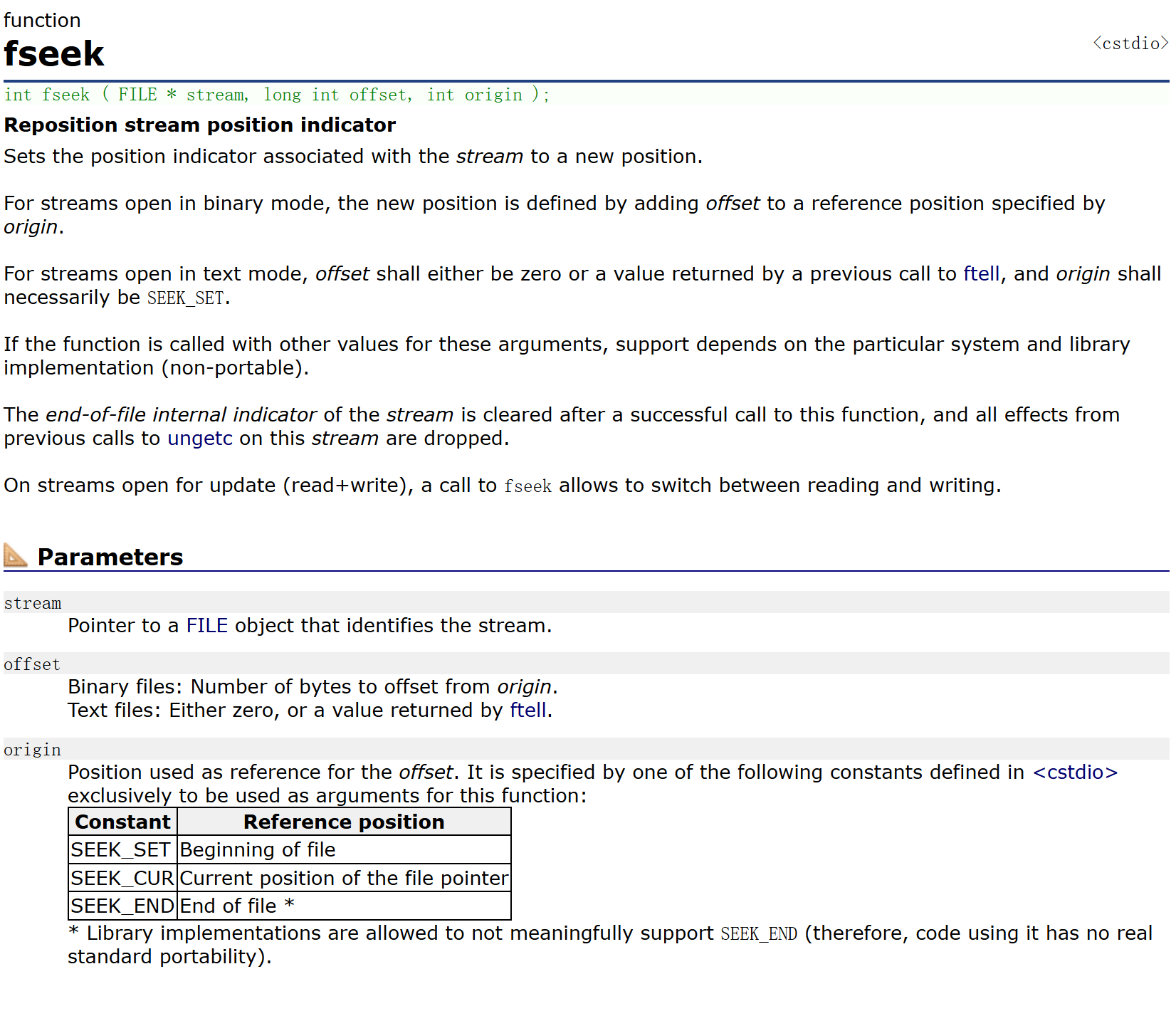
根據文件指針的位置和偏移量來定位文件指針
fseek
- 首先來看看它的相關介紹
- 可以看到,最重要的還是最后的那個參數,因為有三個選項可以使用。
int fseek ( FILE * stream, long int offset, int origin );
- 然后通過代碼我們再來實現一下這個功能。首先看到是使用到了【SEEK_SET】從文件的起始位置開始偏移,因為文件的起始是從第一個字符開始,向后偏移三位就到了【d】的位置


- 接下來我們再來看一種。剛才是從前往后偏移,現在則是從后往前偏移,那就要使用到【SEEK_END】
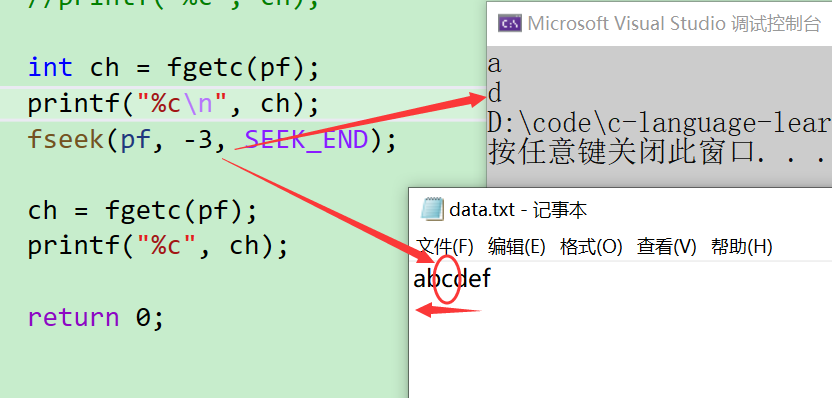
- 最后一個是【SEEK_CUR】,也就是從當前位置向后偏移

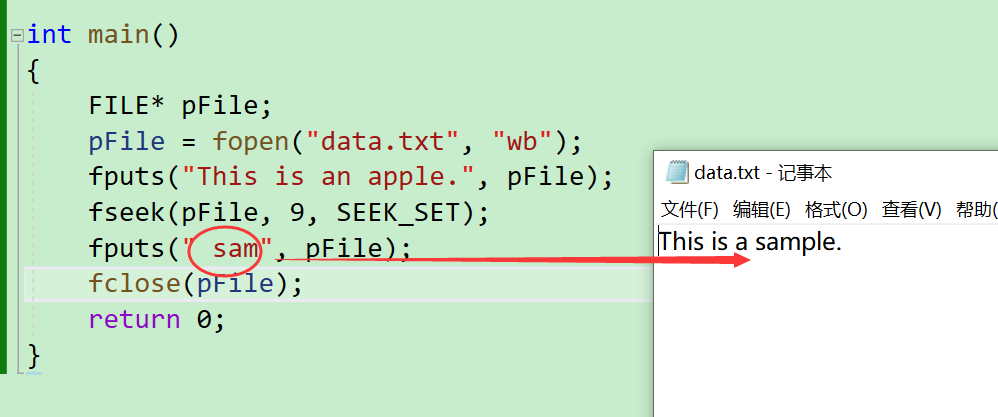
補充一個實際案例
FILE* pFile;
pFile = fopen("example.txt", "wb");
fputs("This is an apple.", pFile);
fseek(pFile, 9, SEEK_SET);
fputs(" sam", pFile);
fclose(pFile);
- 偏移到
This is a然后修改后面的內容
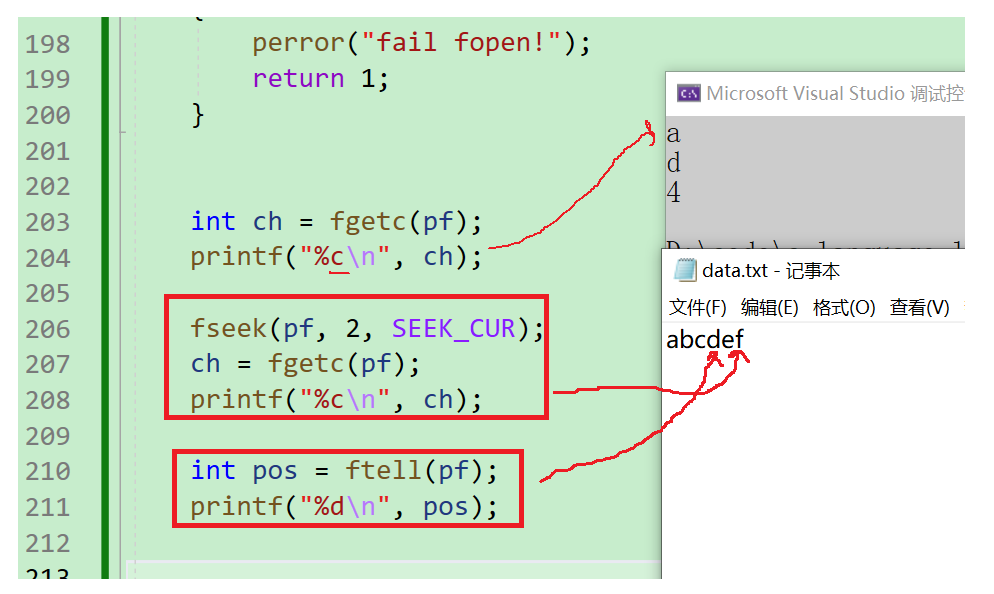
2、ftell
fteel
- 返回文件指針相對于起始位置的偏移量
long int ftell ( FILE * stream );

- 這個很簡單,就是返回當前文件指針所在流中的位置
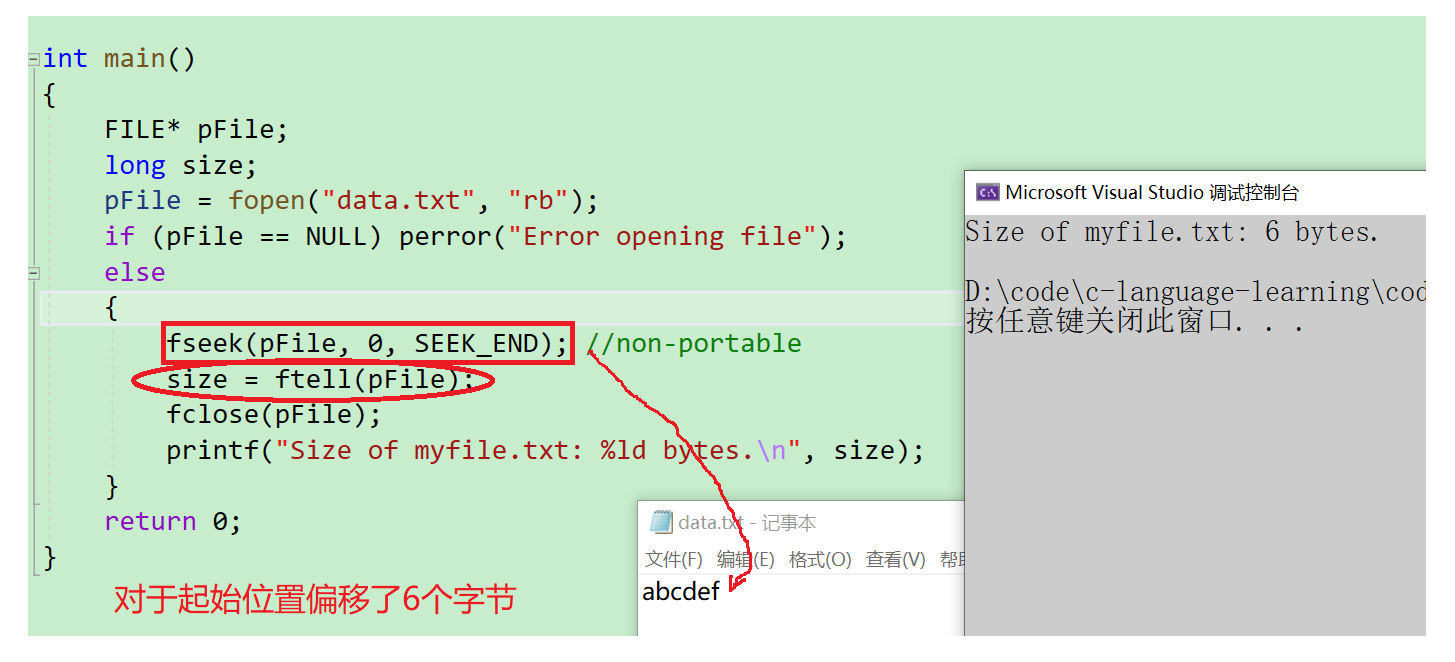
補充一個實際案例
FILE* pFile;
long size;
pFile = fopen("myfile.txt", "rb");
if (pFile == NULL) perror("Error opening file");
else
{fseek(pFile, 0, SEEK_END); //non-portablesize = ftell(pFile);fclose(pFile);printf("Size of myfile.txt: %ld bytes.\n", size);
}
- 這個案例很巧妙地結合了我們上面所學過的【fseek】和【ftell】,求出了這個文件的字節大小
3、rewind
rewind
- 讓文件指針的位置回到文件的起始位置
void rewind ( FILE * stream );
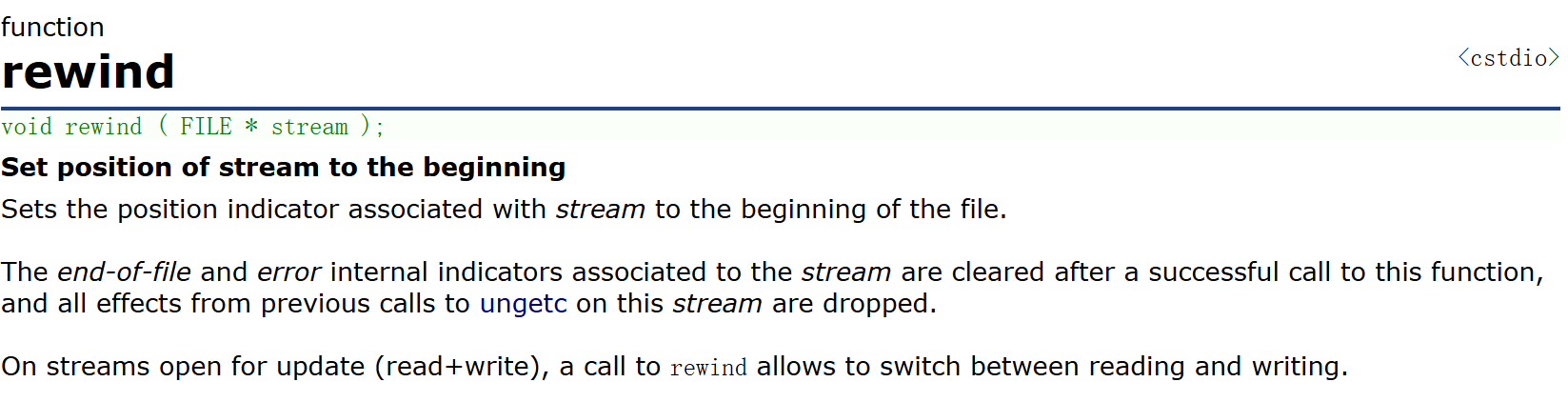
- 可以看到,我們又讀到了a,表明文件指針pf確實回到到了起始位置
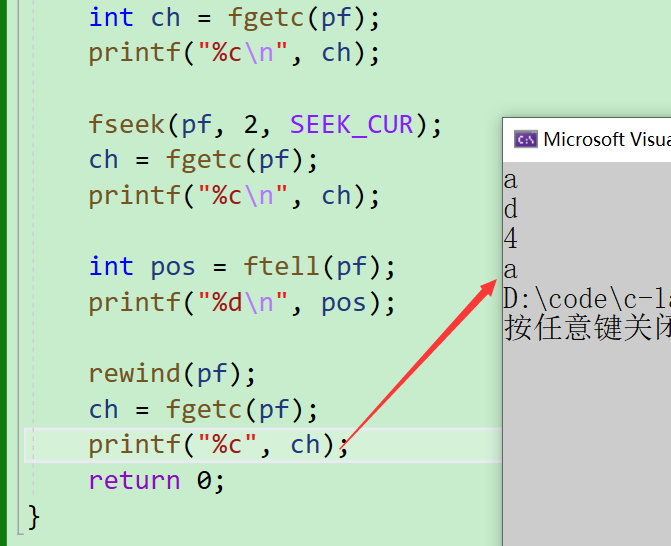
補充一個實際案例
int n;
FILE* pFile;
char buffer[27];
pFile = fopen("myfile.txt", "w+");
for (n = 'A'; n <= 'Z'; n++)fputc(n, pFile);rewind(pFile); //當文件指針pFile重新回到起始位置
fread(buffer, 1, 26, pFile); //通過文件指針讀入26個字母到buffer字符數組中
fclose(pFile);
buffer[26] = '\0'; //'\0'表示字符串的結束位置
puts(buffer);
- 這個案例就是將1~26個大寫英文字母寫入文件,然后在讓文件指針回到起始位置,在使用二進制的讀取方式將文件中的內容讀取到字符數組中,最后為字符串設置結束標志,打印出來便是文件中寫入的內容
六、文本文件和二進制文件
- 【二進制文件】:數據在內存中以二進制的形式存儲。不加轉換的輸出到外存
- 【文本文件】:以ASCII字符的形式存儲的文件。在外存上以ASCII碼的形式存儲,則需要在存儲前轉換
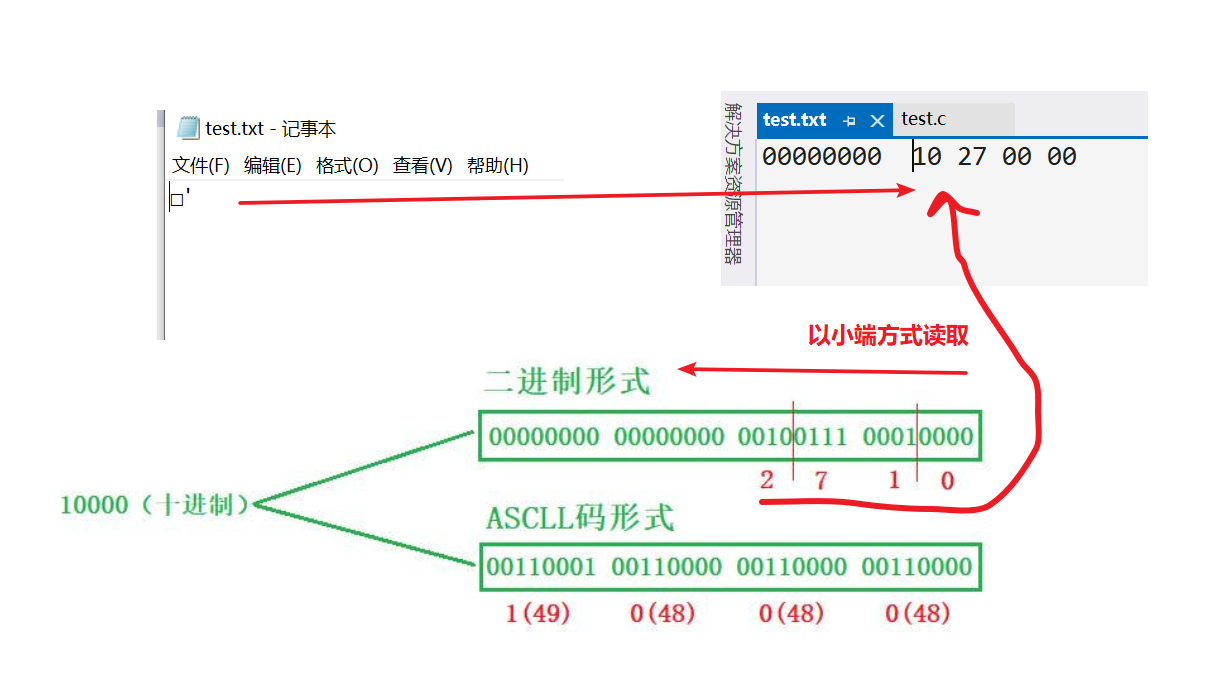
字符一律以ASCII形式存儲,數值型數據既可以用ASCII形式存儲,也可以使用二進制形式存儲
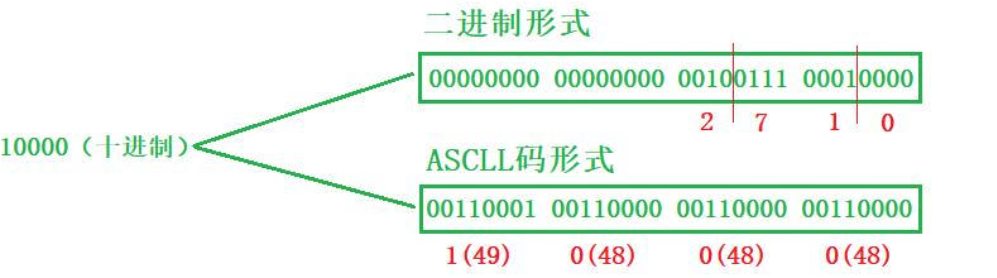
上面就是一個十進制的數值10相關的兩種存儲形式,我測試了一下,以二進制的形式存放到文件里只占4個字節,但是以ASCLL碼的形式存放到文件里就需要占5個字節
- 接下去我們通過下面這段代碼來看看二進制的存儲形式
int main()
{int a = 10000;FILE* pf = fopen("test.txt", "wb");fwrite(&a, 4, 1, pf);//二進制的形式寫到文件中fclose(pf);pf = NULL;return 0;
}
七、文件讀取結束的判定
- 牢記:在文件讀取過程中,不能用feof函數的返回值直接用來判斷文件的是否結束
1、被錯誤使用的feof
-
去網上看很多的代碼可以發現,大家幾乎都錯誤地使用了【feof】這個函數,認為它和EOF一樣就是用來判斷文件是否結束,但是并不是這樣,我們一起來探究一下這個函數
-
從中我們可以知曉【feof】應用于當文件讀取結束的時候,判斷是讀取失敗結束,還是遇到文件尾結束

2、fgetc、fgets、fscanf、fread結束判斷解讀
- 對于上面的四個讀取文件函數,要怎么去判斷它們是否\結束呢?我們通過觀察這些函數的返回值來看看
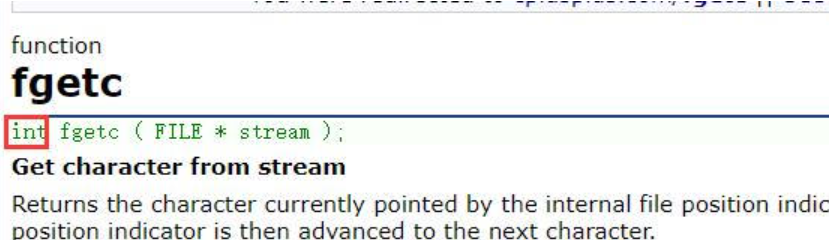
fgetc
- 如果讀取正常,返回讀取到的字符的ASCLL碼值
- 如果讀取失敗,返回EOF
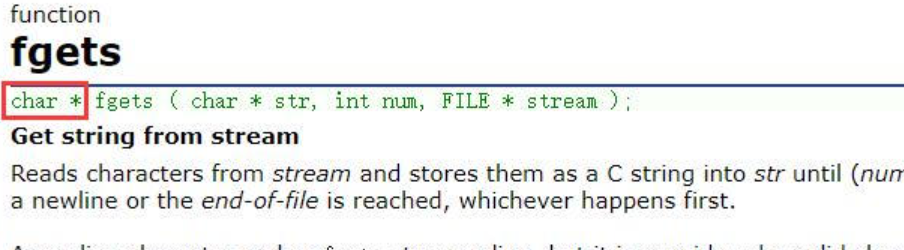
fgets
- 如果讀取正常,返回讀取到的數據的地址
- 如果讀取失敗,返回NULL
fscanf
- 如果讀取正常,返回的是格式串中指定的數據個數
- 如果讀取失敗,返回的是小于格式串中指定的數據個數

fread
- 如果讀取正常,返回的是等于要讀取的數據個數
- 如果讀取失敗,返回的是小于要讀取的數據個數
3、實例代碼走讀
文本文件操作
- 首先通過文件指針以讀的形式打開了這個文件,然后去判斷一下是否打開成功。
(fp == NULL) - 因為條件表達式為真也就是1的時候會進入if判斷,那
!pf == 1可以推出pf == 0等價于pf == NULL - 接下去的話就是去這個文件中一個讀取內容然后輸出,若是文件到達了EOF,也就是【fgetc】的結束判斷條件,此時才可以使用【feof】去進行判斷,所以可以看出【feof】是在文件結束之后去判斷文件是因為什么而結束的。【ferror】若是成立的話表示這個文件是因為I/O的讀取的問題中斷的;若不是【feof】判斷滿足就表示其是正常結束的
int c; // 注意:int,非char,要求處理EOF
FILE* fp = fopen("test.txt", "r");
if (!fp) {perror("File opening failed");return EXIT_FAILURE;
}
//fgetc 當讀取失敗的時候或者遇到文件結束的時候,都會返回EOF
while ((c = fgetc(fp)) != EOF) // 標準C I/O讀取文件循環
{putchar(c);
}
//判斷是什么原因結束的
if (ferror(fp))puts("I/O error when reading");
else if (feof(fp))puts("End of file reached successfully");
fclose(fp);
二進制文件操作
- 這是一個二進制的文件操作,所以以二進制的形式打開,然后使用二進制的寫法【fwrite】從a這個數組的首元素地址開始拿取SIZE個大小為double的數據通過fp這個文件指針寫出到文件中
講一下這里的(sizeof *a)是什么意思,a是數組的首元素地址,然后通過【 * 】解引用可以獲取到每個數組元素的大小了 - 數組a中的數據寫入文件后,就要再打開這個文件然后將文件中的內容個讀出來,我們將其保存在一個變量中然后對這個變量進行一個判斷
- 因為這個是一個二進制文件,因此我們要去判斷它返回的個數是否小于需要讀取的個數,若是成立則表示沒有讀完就結束了,若是和SIZE的個數相同的話表示都讀完了,然后我們將讀取到數組b中的內容輸出一下即可
- 若是沒有讀完但是文件又結束了,那么此時使用【feof】判斷成立了,將不對的信息打印出來即可,若是沒有到達文件末尾但是又讀取結束了,進入了【ferror】的判斷,表示文件的I/O流出現問題了
enum { SIZE = 5 };
int main()
{double a[SIZE] = { 1.,2.,3.,4.,5. };double b[SIZE];FILE* fp = fopen("test.bin", "wb"); // 必須用二進制模式fwrite(a, sizeof *a, SIZE, fp); // 寫 double 的數組fclose(fp);fp = fopen("test.bin", "rb");size_t ret_code = fread(b, sizeof *b, SIZE, fp); // 讀 double 的數組if (ret_code == SIZE) {puts("Array read successfully, contents: ");for (int n = 0; n < SIZE; ++n) printf("%f ", b[n]);putchar('\n');}else { // error handlingif (feof(fp))printf("Error reading test.bin: unexpected end of file\n");else if (ferror(fp)) {perror("Error reading test.bin");}}fclose(fp);
}
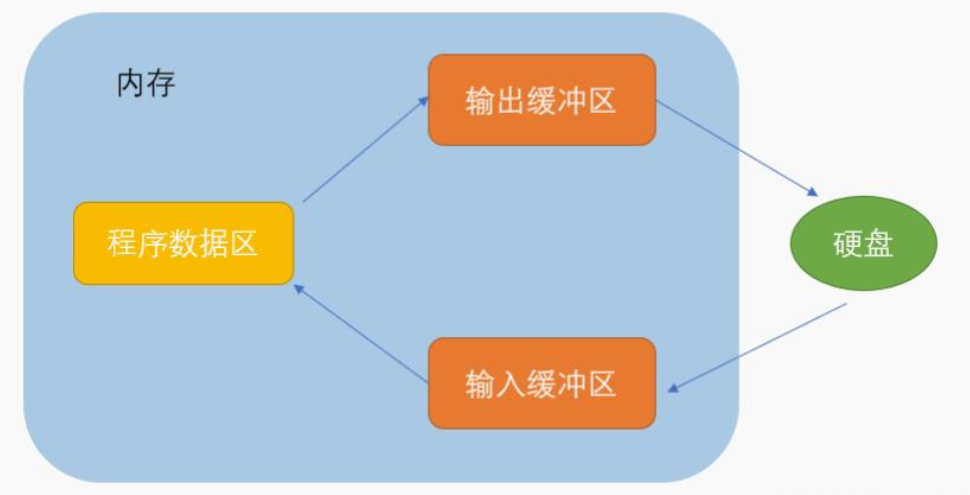
八、文件緩沖區
-
ANSIC 標準采用【緩沖文件系統】處理的數據文件的,所謂緩沖文件系統是指系統自動地在內存中為程序中每一個正在使用的文件開辟一塊“文件緩沖區”。
-
從內存向磁盤輸出數據【寫】會先送到內存中的緩沖區,裝滿緩沖區后才一起送到磁盤上。
-
如果從磁盤向計算機【讀】入數據,則從磁盤文件中讀取數據輸入到內存緩沖區(充滿緩沖區),然后再從緩沖區逐個地將數據送到程序數據區(程序變量等)。
-
緩沖區的大小根據C編譯系統決定的
下面是有關文件緩沖區的示意圖
下面是實例代碼
int main()
{FILE* pf = fopen("test.txt", "w");fputs("abcdef", pf); //先將代碼放在輸出緩沖區printf("睡眠10秒-已經寫數據了,打開test.txt文件,發現文件沒有內容\n");Sleep(10000);printf("刷新緩沖區\n");fflush(pf);//刷新緩沖區時,才將輸出緩沖區的數據寫到文件(磁盤)//注:fflush 在高版本的VS上不能使用了printf("再睡眠10秒-此時,再次打開test.txt文件,文件有內容了\n");Sleep(10000);fclose(pf);//注:fclose在關閉文件的時候,也會刷新緩沖區pf = NULL;return 0;
}
拓展:文件外排序
1、前言
- 對于文件中的數據,一般都是很大的,不像我們上面所講的十二十個數,可能會有成千上百的數據需要我們去排序,此時效率最高的就是【歸并排序】了,因為面對海量的數據而言,像效率較高的【快速排序】需要克服三數取中的困難,還有像【堆排序】【希爾排序】這些,都無法支持隨機訪問,所以很難去對大量的文件進行一個排序,速度會非常之慢。即使是有文件函數【fseek()】這樣的函數可以使文件指針偏移,還是很難做到高效。因為磁盤的速度比起內存差了太多太多了,具體的我不太清楚大概有差個幾千倍這樣,
- 所以我們就想到了【歸并排序】,它既是內排序,也是外排序,而且性能也不差,算是速度較快的幾個排序之一了。但是要如何進行歸并呢?
2、思路解析
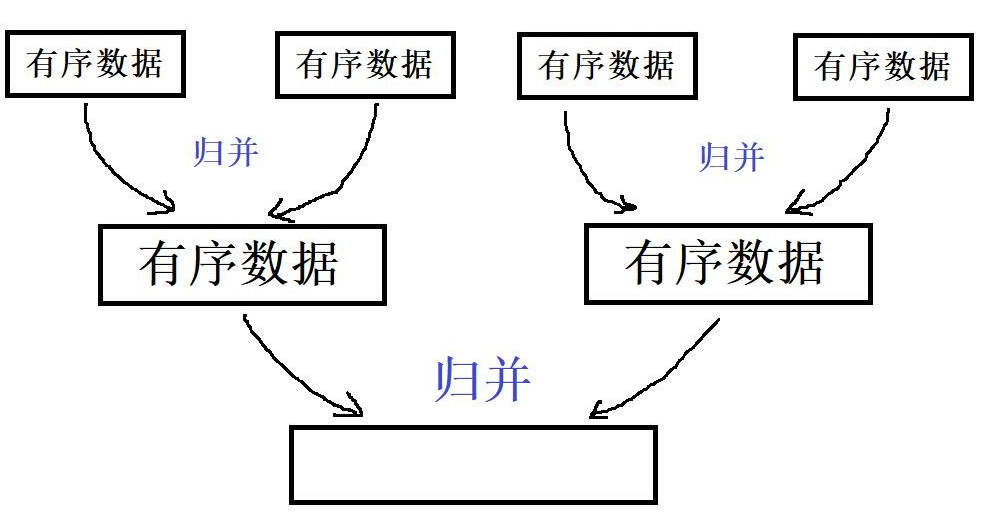
- 回憶一下歸并排序的原理,就是兩個有序區有序,然后兩兩一歸才使得整體可以有序,如果左右都無需,那么繼續對其進行左右分割歸并
- 但是本次,我要教給你的你是另外一種思路:
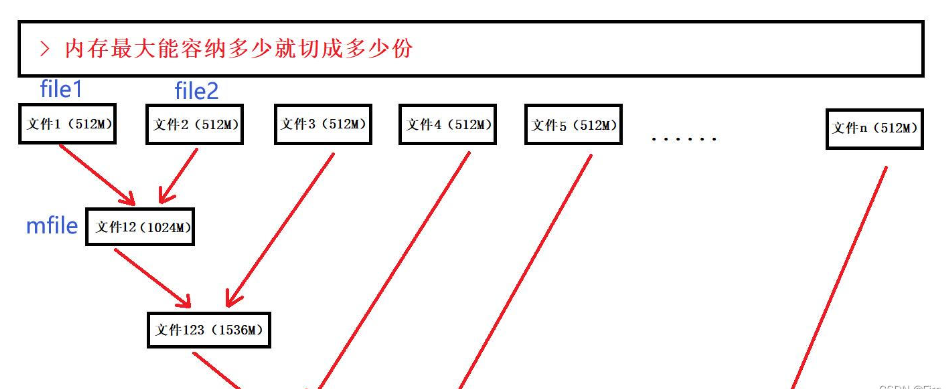
將一個大文件平均分割成N份,保證每份的大小可以加載到內存中,然后使用快排將其排成有序再寫回一個個小文件,此時就擁有了文件中歸并的先決條件
- 具體示意圖如下

- 這里我設置一個這樣的規則,令文件1為【1】,文件2位【2】,它們歸并之后即為【12】,然后再讓【12】和文件3即【3】歸并變成【123】,以此類推,所以最后歸出的文件名應該是【12345678910】
3、代碼詳解
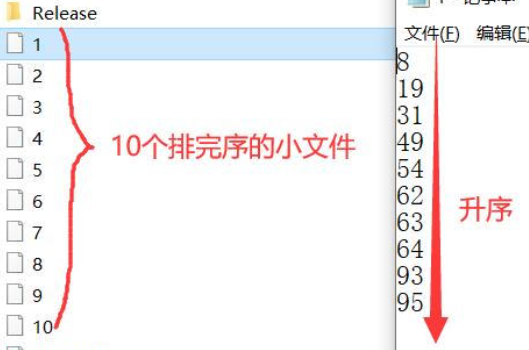
下面是大文件分割成10個小文件的邏輯,首先來講解一下這塊,代碼中很多內容涉及到文件操作,如果有文件操作還不是很懂的小伙伴記得再去溫習一下
- 整體的邏輯就在于從文件中讀取100個數據,但是分批進行讀取,每次首先去讀9個數,然后當讀到第十個數的時候,先將其加入數組中,然后再對數組中的這10個數進行排序。排完序后就將這個10個數通過文件指針再寫到一個小文件中
- 接著當第二次循環上來的時候,就開始讀第11~20個數;以此往復,直到讀完這個100個數為止,那此時我們的工程目錄下就會出現10個小文件,就是對這100個數的分隔排序后的結果
void MergeSortFile(const char* file)
{FILE* fout = fopen(file, "r");if (!fout){perror("fopen fail");exit(-1);}int num = 0;int n = 10;int i = 0;int b[10];char subfile[20];int filei = 1;//1.讀取大文件,然后將其平均分成N份,加載到內存中后對每份進行排序,然后再寫回小文件memset(b, 0, sizeof(int) * n);while (fscanf(fout, "%d\n", &num) != EOF){if (i < n - 1){b[i++] = num; //首先讀9個數據到數組中}else{b[i] = num; //再將第十個輸入放入數組QuickSort(b, 0, n - 1); //對其進行排序sprintf(subfile, "%d", filei++);FILE* fin = fopen(subfile, "w");if (!fin){perror("fopen fail");exit(-1);}//再進本輪排好序的10個數以單個小文件的形式寫到工程文件下for (int j = 0; j < n; ++j){fprintf(fin, "%d\n", b[j]);}fclose(fin);i = 0; //i重新置0,方便下一次的讀取memset(b, 0, sizeof(int) * n);}}
}
- 我們來看一下排序的結果
- 將大文件分成10個小文件后,接下去就是要對這個10個小文件進行歸并,具體規則我上面已經說了
- 下面就是單趟歸并的邏輯的,就和我們上面說到的歸并排序的代碼是很類似的,只不過這里是文件的操作而已。要注意的是對于文件來說是有一個文件指針的,若是你讀取了一個之后那么文件指針這個結構體中的數據標記就會發生變化,標記為當然所讀內容的下一個了
- 所以我們不能將讀取讀取小文件中的數據的操作放在while循環中,應該單獨將其抽離出來進行判斷才才對。若是哪個文件中的數小,那么就將這個數寫到新的【mfile】文件中去,然后繼續讀取當前文件的后一個內容
//文件歸并邏輯
void _MergeSortFile(const char* file1, const char* file2, const char* mfile)
{FILE* fout1 = fopen(file1, "r");if (!fout1){perror("fopen fail");exit(-1);}FILE* fout2 = fopen(file2, "r");if (!fout2){perror("fopen fail");exit(-1);}FILE* fin = fopen(mfile, "w");if (!fin){perror("fopen fail");exit(-1);}int num1, num2;//返回值拿到循環外來接受int ret1 = fscanf(fout1, "%d\n", &num1);int ret2 = fscanf(fout2, "%d\n", &num2);while (ret1 != EOF && ret2 != EOF){if (num1 < num2){fprintf(fin, "%d\n", num1);ret1 = fscanf(fout1, "%d\n", &num1);}else{fprintf(fin, "%d\n", num2);ret2 = fscanf(fout2, "%d\n", &num2);}}while (ret1 != EOF){fprintf(fin, "%d\n", num1);ret1 = fscanf(fout1, "%d\n", &num1);}while (ret2 != EOF){fprintf(fin, "%d\n", num2);ret2 = fscanf(fout2, "%d\n", &num2);}fclose(fout1);fclose(fout2);fclose(fin);
}
最后在打開文件后不要忘了將文件關閉哦,不然就白操作了
- 當然上面是一個單趟的邏輯,我們還要對【file1】【file2】【mfile】進行一個迭代
//利用互相歸并到文件,實現整體有序
char file1[100] = "1";
char file2[100] = "2";
char mfile[100] = "12";
for (int i = 2; i <= n; ++i)
{_MergeSortFile(file1, file2, mfile);//迭代strcpy(file1, mfile);sprintf(file2, "%d", i + 1);sprintf(mfile, "%s%d", mfile, i + 1);}
- 大概就是這么一個迭代的過程

整體代碼展示
//文件歸并邏輯
void _MergeSortFile(const char* file1, const char* file2, const char* mfile)
{FILE* fout1 = fopen(file1, "r");if (!fout1){perror("fopen fail");exit(-1);}FILE* fout2 = fopen(file2, "r");if (!fout2){perror("fopen fail");exit(-1);}FILE* fin = fopen(mfile, "w");if (!fin){perror("fopen fail");exit(-1);}int num1, num2;//返回值拿到循環外來接受int ret1 = fscanf(fout1, "%d\n", &num1);int ret2 = fscanf(fout2, "%d\n", &num2);while (ret1 != EOF && ret2 != EOF){if (num1 < num2){fprintf(fin, "%d\n", num1);ret1 = fscanf(fout1, "%d\n", &num1);}else{fprintf(fin, "%d\n", num2);ret2 = fscanf(fout2, "%d\n", &num2);}}while (ret1 != EOF){fprintf(fin, "%d\n", num1);ret1 = fscanf(fout1, "%d\n", &num1);}while (ret2 != EOF){fprintf(fin, "%d\n", num2);ret2 = fscanf(fout2, "%d\n", &num2);}fclose(fout1);fclose(fout2);fclose(fin);
}/*文件外排序*/
void MergeSortFile(const char* file)
{srand((unsigned int)time(NULL));FILE* fout = fopen(file, "r");if (!fout){perror("fopen fail");exit(-1);}//先寫100個隨機數進文件//for (int i = 0; i < 100; ++i)//{// int num = rand() % 100;// fprintf(fout, "%d\n", num);//}int num = 0;int n = 10;int i = 0;int b[10];char subfile[20];int filei = 1;//1.讀取大文件,然后將其平均分成N份,加載到內存中后對每份進行排序,然后再寫回小文件memset(b, 0, sizeof(int) * n);while (fscanf(fout, "%d\n", &num) != EOF){if (i < n - 1){b[i++] = num; //首先讀9個數據到數組中}else{b[i] = num; //再將第十個輸入放入數組QuickSort(b, 0, n - 1); //對其進行排序sprintf(subfile, "%d", filei++);FILE* fin = fopen(subfile, "w");if (!fin){perror("fopen fail");exit(-1);}//再進本輪排好序的10個數以單個小文件的形式寫到工程文件下for (int j = 0; j < n; ++j){fprintf(fin, "%d\n", b[j]);}fclose(fin);i = 0; //i重新置0,方便下一次的讀取memset(b, 0, sizeof(int) * n);}}//利用互相歸并到文件,實現整體有序char file1[100] = "1";char file2[100] = "2";char mfile[100] = "12";for (int i = 2; i <= n; ++i){_MergeSortFile(file1, file2, mfile);//迭代strcpy(file1, mfile);sprintf(file2, "%d", i + 1);sprintf(mfile, "%s%d", mfile, i + 1);}
}運行結果展示

)
【附源碼】)


:消息隊列、ElasticSearch、Mysql等亮點合集】)
)










)
)

