01、案例說明
本期分享案例是:文字分析-情感分析,內容是關于某部電影評論好壞的分析,使用大量的已知數據,通過監督學習的方法,可以對于未知的評論進行判斷其為正面還是負面的評價。
對于數據分析,原來都是處理數值型的問題。直到最近才將數據分析的能力延伸到文本分析的領域之內。通過這個案例我們可以了解對于文字,也同樣的可以利用一些聰明的方式,做成數值方式的表現而進行文字分析,如下圖所示:
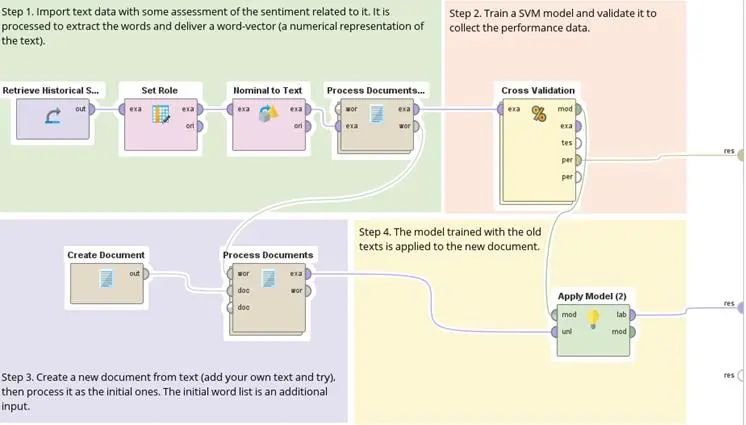
02、數據資料
首先我們看到導入的數據,與之前所經歷的數值數據是非常不同,基本在Text的屬性里面,是非結構性的文字,其內容與長度都有所不同。這個部分RM是作為文本的方式來處理,也請特別注意,如果是使用EXCEL 等其他外部的數據導入,最好還是使用 Import Guru的功能,避免其辨識為其他種類的屬性。
03、操作流程
Step1讀入數據
導入數據之后,將目標值設定為情緒反應(Set Role),以及第三個算子(NominalToText)再一次確保其數據是文本而不是多項式的種類。
最主要的核心在第四個操作(Process Document)元之內,這是RM一個特殊的算子,其參數包括設定如何將令牌(Token)輸出成為文字向量(Vector),打開其中我們可以看到有幾個標準的操作。如下圖所示:
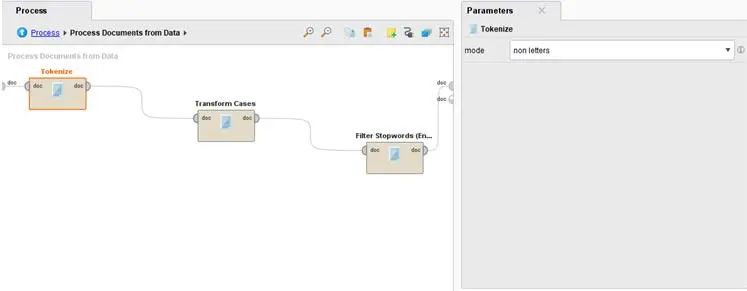
第一個算子(Tokenize)將文字首先轉換為令牌,使用的方式是只要不是文字,就作為一個令牌,所以所有的空白/標點/特殊符號都會去除掉。
第二個算子(Transform Cases)將所有的英文字轉為小寫的字體,避免因為大小寫而變成不同的令牌。
第三個算子(Filter Stopwords)是使用一個在RM中預先建立的字典,將所有沒有意義的字詞去除掉。
做完這些之后,其輸出的形態變成一個超大的矩陣,如下圖所示:
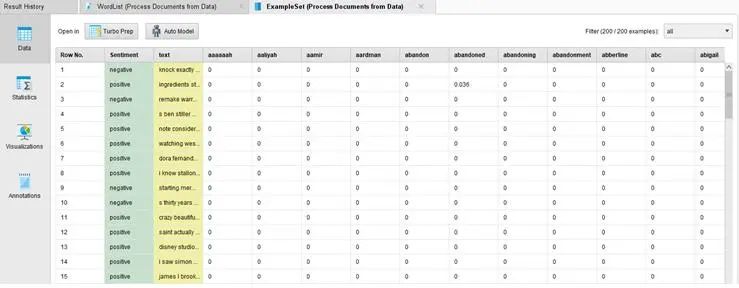
其中一共有200個數據,但是屬性卻達到13418個屬性。而其中的數值(小于1的數值)是其對應令牌在這個數據中的TF-IDF 的數值。
在這里我們就完成了最關鍵的步驟,也就是將文本的資料轉換為實數的數值。通過這個方法,我們之前所學習的所有機器學習模型,都可以應用在這個巨大的矩陣之上。?
Step2 模型建立
有了這個了解,我們就可以用之前我們熟悉的交叉檢驗的算子對這個數據進行模型的建立。因為屬性的龐大,通常我們會使用的是支持向量機(SVM),但是其原理和之前是完全相同的,包括對于精準度的驗證,可以直接打開這個(Cross Validation)算子進行觀察。
Step3:?測試數據
這個步驟(Create Document),我們自行在系統之內創建了一個測試的數據,然后通過使用這個模型來判斷這個數據它的情緒反應為何種。但是請注意,這個所創建的測試數據它們的種類是文本而不是其他的任何一種數據。
第2個步驟是使用之前相同的文本處理的算子,對數據進行令牌建立和向量輸出。但是特別注意,因為這個算子它并不能自行創建令牌,必須使用原來模型所使用的令牌,所以需要將在第一個步驟所產生的文本處理的算子,其wor端口必須直接相連,才能夠確保這兩個算子所使用的令牌是一致的,如下圖所示:
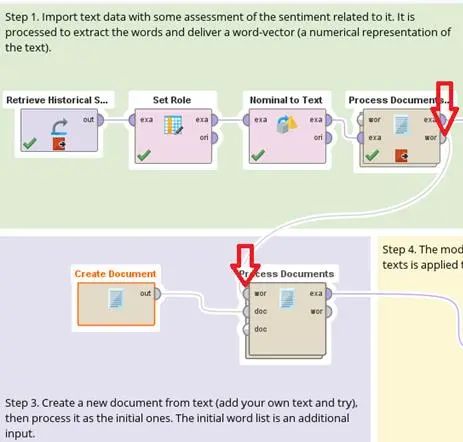
Step4:?模型使用
這個步驟就如我們之前所了解的一樣,使用已經建立好的模型,對于未知的數據進行判斷,并且將其結果輸出。
04、結果說明
對于我們所建立的測試數據,系統的判斷如下,對于結果其信心度有0.587。但是考量模型本身的精確度僅有63.5%+/-6.26%,再配合我們的信心程度很難確定的說這個判斷是否準確,僅能作為參考。而如果細讀文字的本身,事實上對于人腦也是一個較為難以立判好壞的數據,所以無法因此證明系統的無效性,如下圖所示:
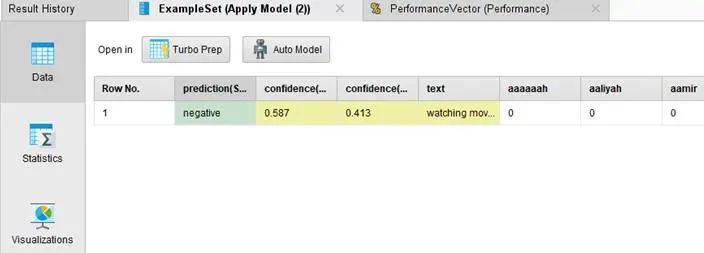
對于電腦要發展到與人腦有類似的功能,僅僅使用這種簡單的文檔分析的方式,遠遠不能達到可接受的程度。事實上,這個已經是需要進入神經網絡和自然語言處理的全新領域。但是簡單的使用這種操作,仍然可以產生出很有趣的結果。
當然另外一個問題,就是對于中文的處理。這個案例里面使用的全部都是英文,其中的文檔處理的(Process Document)算子,必須要重新調整使用我們在之前所提到的Jieba的Python程序碼才有辦法處理中文。相關的案例,如果有興趣的話可以與我們聯絡,可以共同討論。
關于?Altair?RapidMiner
Altair RapidMiner 數據分析與人工智能平臺,是數據分析領域中最早實現將自動化數據科學、文本分析、自動特征工程和深度學習等多種功能同時集成的企業級一站式數據科學平臺,幫助用戶解決從數據清洗、準備、數據科學建模到模型管理和部署的全流程需求,同時支持數據和流數據的實時分析可視化,適用于從學術研究到企業級應用的廣泛場景。
欲了解更多信息,歡迎關注公眾號:Altair 澳汰爾











及其Python 和 MATLAB 實現)


 at 0x800337c:)




)