一、解決問題
在基于網絡的長形式問答(Web-enhanced Long-form Question Answering, LFQA)任務中,現有RAG在生成答案時存在的問題:
-
事實性不足:研究表明,現有系統生成的答案中只有大約一半的陳述能夠完全得到檢索到的參考資料的支持,這嚴重影響了這些系統的可信度。
-
清晰邏輯的缺失:與短答案的傳統問答任務不同,LFQA任務中理想的答案往往需要多方面組織和整合信息,但現有的開源方法在生成答案時往往缺乏清晰的邏輯結構。
二、提綱增強RAG
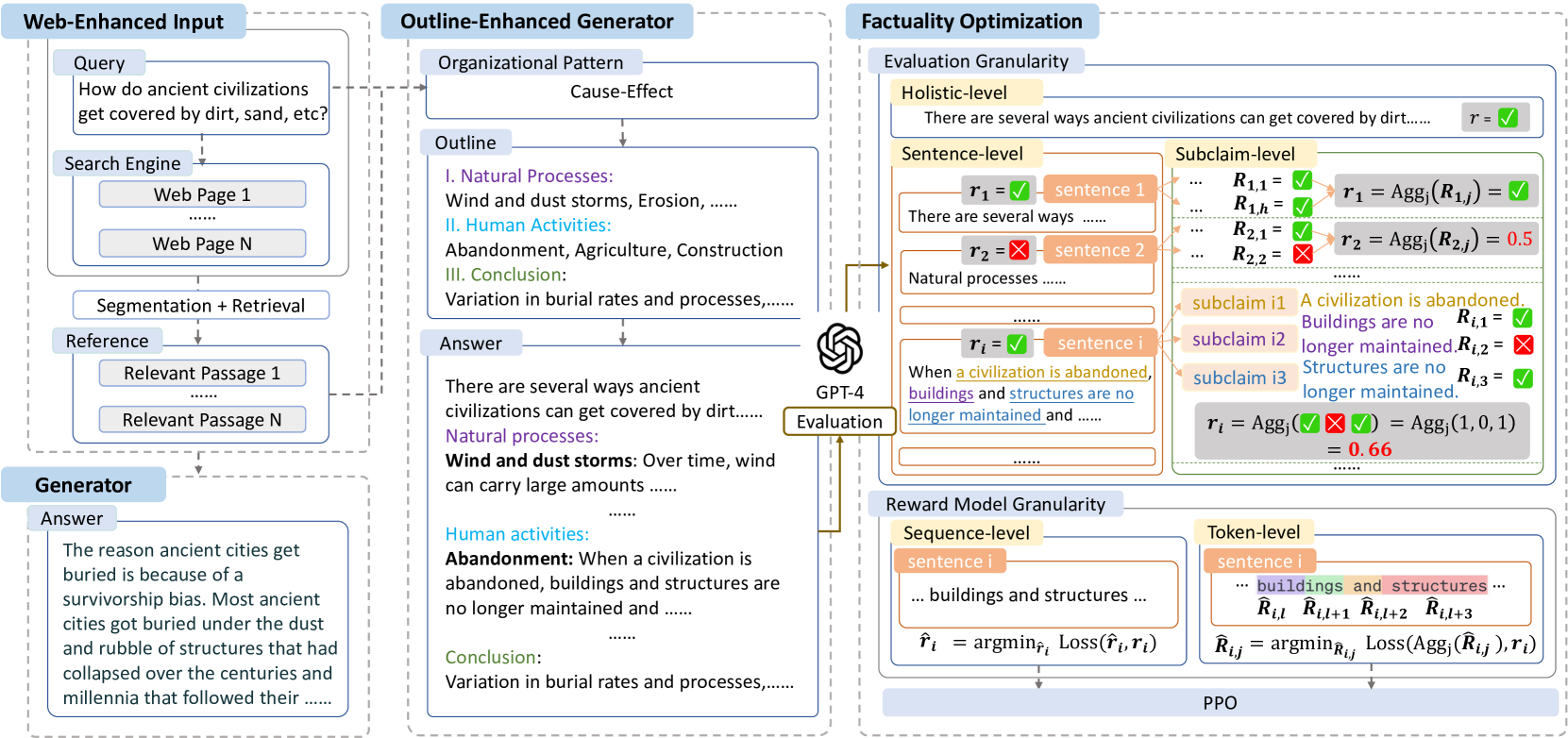
提出提綱增強RAG,以改善長形式問題回答 LFQA 中生成答案的結構和質量。
2.1 Outline-Enhanced Generator
現有的開源方法在生成答案時,通常是直接將檢索到的內容與原始查詢拼接,然后使用特定的提示模板(prompt template)輸入到生成模型中。這種方法生成的答案往往較短,缺乏清晰的邏輯結構。為了提高答案的組織性,提出了 “Outline-Enhanced Generator”,它包含以下兩個階段:
-
Outline Stage(提綱階段):
在此階段,生成器首先使用提綱模板,根據用戶查詢和上下文生成答案的提綱。提綱模板引導大型語言模型(LLM)考慮哪種組織模式最適合當前問題,例如“因果關系”或“比較對比”。然后,LLM根據選定的組織模式輸出提綱,為后續的擴展階段做準備。
-
Expansion Stage(擴展階段):
基于前一階段生成的提綱,LLM擴展每個要點,構建最終答案。模型被要求在包含查詢、上下文和提綱的輸入下,生成對問題的答案。
注:提綱增強階段的生成器有SFT訓練得到。
2.2 Outline-Enhanced Long-Form QA Dataset
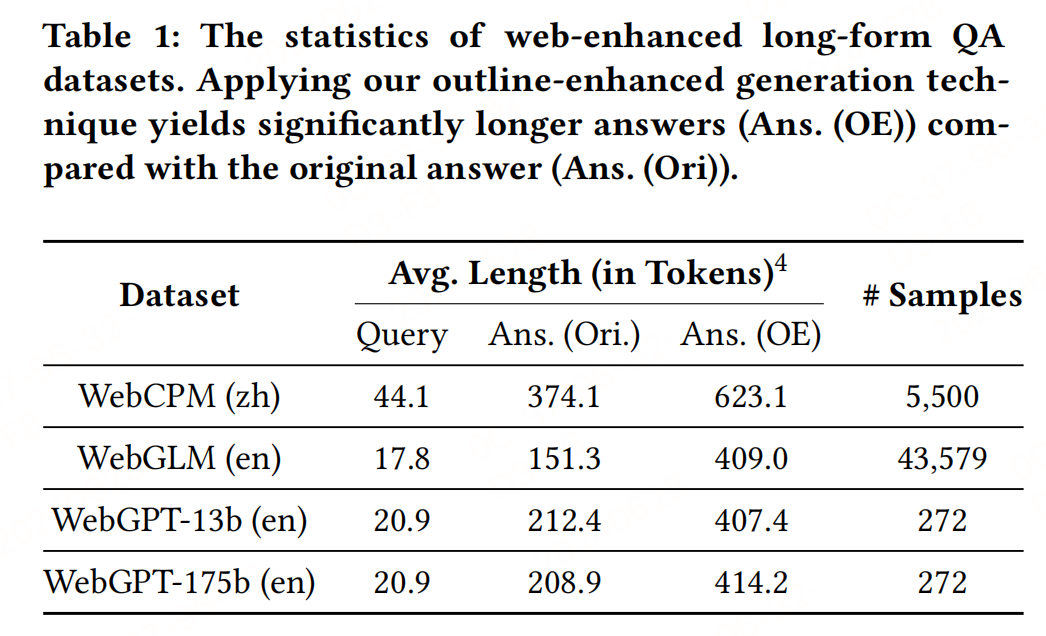
為了支持 “Outline-Enhanced Generator” 的訓練和評估,構建了兩個大規模的提綱增強型LFQA數據集。這些數據集利用現有的WebCPM和WebGLM數據集的查詢和相關段落,并通過GPT4模型應用提綱增強生成技術來收集提綱增強型答案。統計信息顯示,使用提綱增強技術生成的答案比現有工作中的答案更長,其具有更強的邏輯結構。


2.3 提綱增強數據構建提示詞
-
英文提示詞


-
中文提示詞

小結:通過引入提綱階段來增強生成答案的邏輯結構,并通過擴展階段來完善和詳細化答案內容,從而提高了長形式問題回答的質量。
三、事實性優化RAG
傳統的RLHF,優化事實性所面臨困難如下:
- 數據標注成本高:手動標注事實性標簽通常成本很高,因為它涉及到比較長篇答案和對應長篇參考資料之間的事實細節。
- 整體性獎勵信號稀疏:標準RLHF使用整體性獎勵,即只有在整個回答的最后一個token上才有非零獎勵,這為生成模型的訓練提供了稀疏的信號,在長篇回答中尤為明顯。
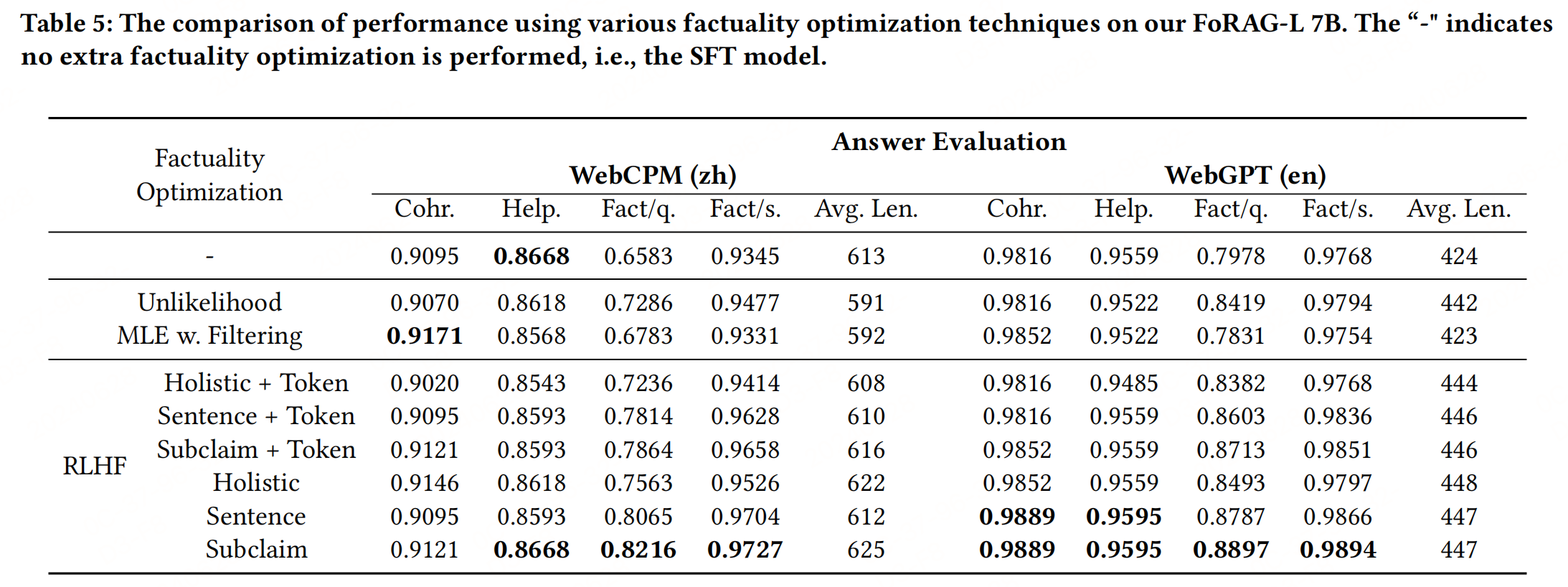
因此,提出了一種新穎的事實性優化方法(Doubly Fine-grained RLHF),旨在解決網絡增強型 LFQA 中的事實性問題。
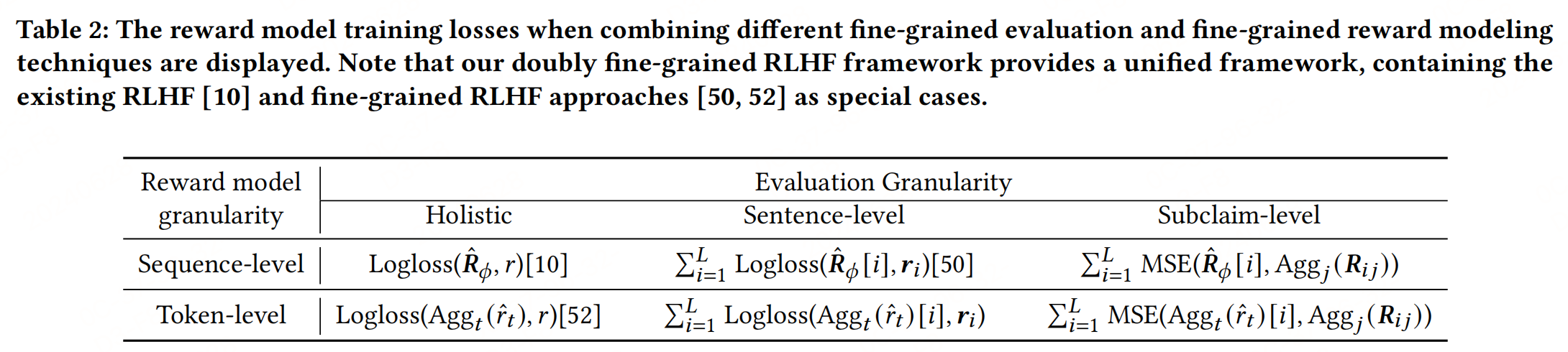
3.1 Doubly Fine-grained RLHF
提出了一種新的事實性優化框架,通過在評估和獎勵建模中采用細粒度的設計,有效地提高了長形式問題回答中生成答案的事實性,同時減少了對人工標注的依賴。
細粒度評估(Fine-grained Evaluation):
- 整體性(Holistic):使用單一事實性評分評估整個答案。
- 句子級別(Sentence-level):將答案分割成句子,并分別評估每個句子。
- 子聲明級別(Subclaim-level):進一步將每個句子分解為多個子聲明,并對每個子聲明單獨評估事實性。
細粒度獎勵建模(Fine-grained Reward Modeling):
- Sequence-level:為每個序列學習單一的獎勵,反映相應序列的事實性。
- Token-level:為序列中的每個token學習獎勵,通過聚合所有token級別的獎勵來計算序列的獎勵。
實現方法
-
獎勵模型訓練:使用Logloss或MSE損失函數來訓練獎勵模型,具體取決于評估過程中得到的是二元標簽還是連續值獎勵。
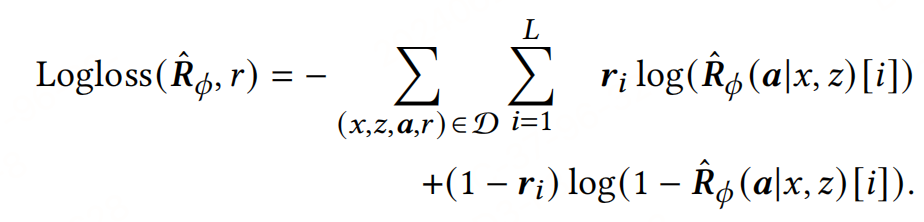
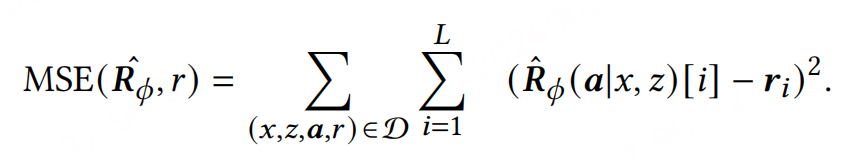
-
PPO優化:采用近端策略優化(Proximal Policy Optimization, PPO)來優化生成模型,通過最大化細粒度的獎勵信號來改善模型性能。
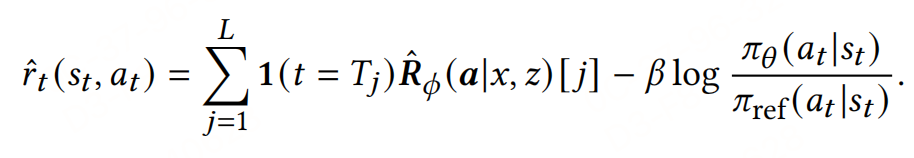
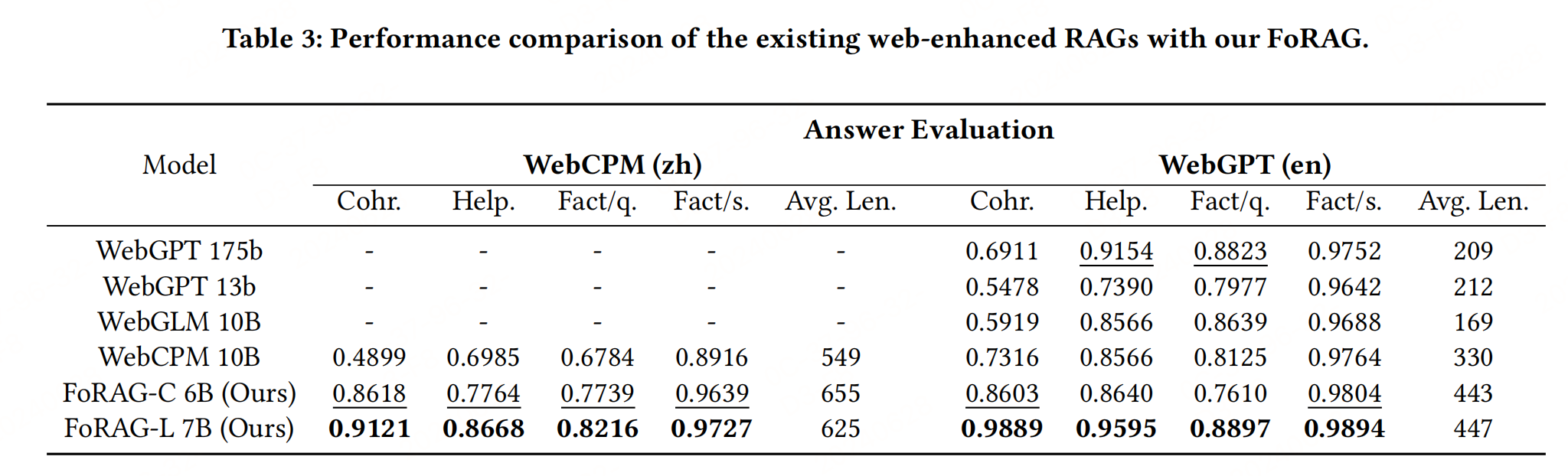
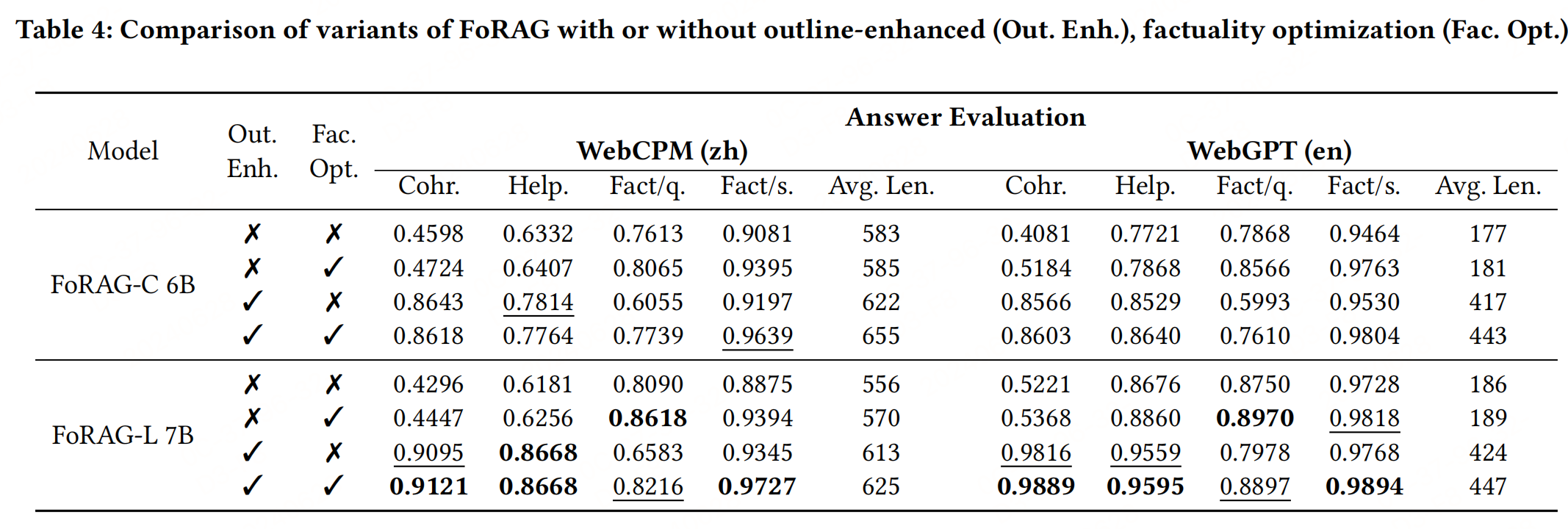
四、實驗結果
參考文獻
paper:FoRAG: Factuality-optimized Retrieval Augmented Generation for Web-enhanced Long-form Question Answering,https://arxiv.org/abs/2406.13779
huggingface:https://huggingface.co/forag
:Qt3D三維開發基礎概念介紹)


)















