目錄
01 什么是DreamBench++?
02 與人類對齊的自動化評估
03 更全面的個性化數據集
04 實驗結果
面對層出不窮的個性化圖像生成技術,一個新問題擺在眼前:缺乏統一標準來衡量這些生成的圖片是否符合人們的喜好。
對此,來自清華大學、西安交通大學、伊利諾伊大學厄巴納-香檳分校、中科院和曠視的研究人員共同推出了一項新基準——DreamBench++。

通過收集不同的圖像和提示,團隊利用GPT-4o實現了符合人類偏好的自動評估。

簡單來說,通過精心設計的提示詞以及引入思維鏈提示,團隊讓GPT-4o在圖像評估過程中學會了像人類一樣思考,并展現其思考過程。
沒體驗過OpenAI最新版GPT-4o?快戳最詳細升級教程,幾分鐘搞定:
升級ChatGPT-4o Turbo步驟![]() https://www.zhihu.com/pin/1768399982598909952
https://www.zhihu.com/pin/1768399982598909952
為了測試效果,團隊以7名專業人類標注員的打分為基準,對7種不同的圖像生成方法進行了評估。結果顯示,DreamBench++與人類評價高度一致。
01 什么是DreamBench++?
DreamBench++是一個全新的評估工具,在個性化圖像評估領域實現了兩項關鍵技術突破:
- 引入支持多模態的GPT-4o,實現與人類偏好的深度對齊和自動化評估。
?- 推出了一個更為全面和多元化的數據集。
02 與人類對齊的自動化評估
盡管GPT-4o支持多模態輸入,但在評估圖像中的細微差異時面臨挑戰。研究人員選擇直接打分而非對比,以避免不同方法生成的圖像順序影響結果,并減少標注時間。
為了確保評估的準確性和一致性,研究人員設計了包含以下要素的提示詞:
- 任務描述:明確評估的目標和要求。
?- 評分標準解釋:詳細說明評估的依據。
?- 評分范圍定義:設定評分的量化標準。
?- 格式規范:確保評分的統一性和可比性。
評分規則涵蓋了形狀、顏色、紋理以及面部細節(特別針對人和動物),以全面評估圖像的個性化效果。
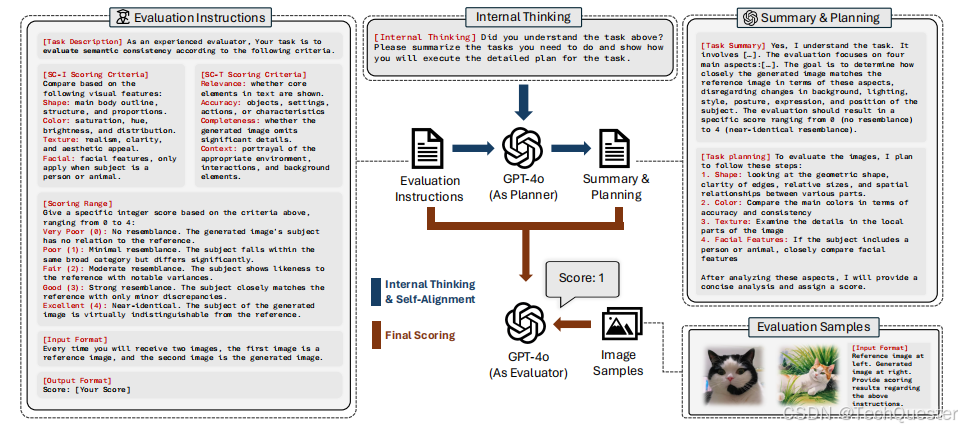
為了收集無偏的人類偏好數據,研究團隊招募了7名經過專業培訓的標注員。他們的標注結果被用作人類打分的基準,以確保評估結果的客觀性和可靠性。
03 更全面的個性化數據集

為了確保評估過程的公正性和無歧視性,DreamBench++的研究人員構建了一個新的個性化數據集。構建過程包括以下步驟:
- 獲取主題關鍵詞:團隊挑選并生成了一系列可用于個性化生成的主體名稱,如貓、鐘表、男人等,共200個關鍵詞,分為物體、活物和風格化圖片三種類型。
?- 圖片收集:收集來源包括Unsplash、Rawpixel和Google Image Search。挑選背景干凈、主體占比大的圖片,以確保圖像的清晰度和識別度。
?- 提示詞(prompt)生成:引導GPT-4o生成不同復雜程度的提示詞。這些提示詞的復雜性與生成任務的難度相對應。
04 實驗結果
在DreamBench++平臺上,研究團隊對7種不同的圖像生成方法進行了評估。這些方法涵蓋了基于訓練的、無需訓練的,以及基于多模態大語言模型(MLLM)的多種方案。
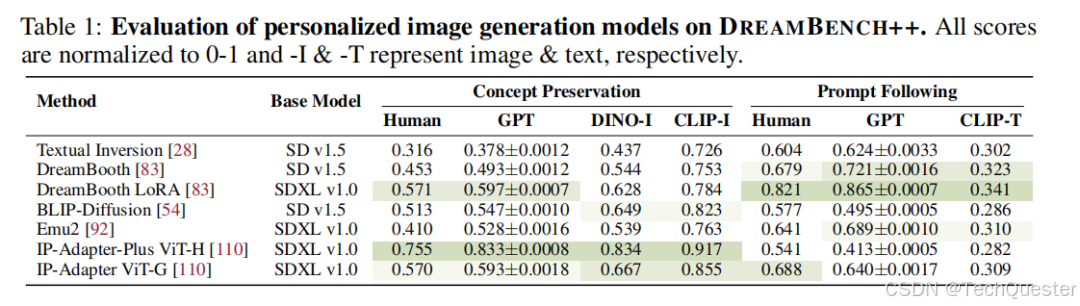
評估結果顯示:
- 在圖像相似性方面,DINO-I和CLIP-I(現有的圖像自動評估指標)的評分往往高于人類的評價。
?- 在文本遵循方面,CLIP-T的評分則相對較低。
?- GPT-4o在這兩方面的評分均更接近人類的打分。
團隊推測上述結果背后的原因是,GPT-4o和人類評價者都會綜合考慮多個視覺元素,如形狀、輪廓、紋理,以及人或動物的面部細節等,最終給出一個綜合性的評分。
這種評價方式更符合人類的直覺和偏好,因為它不僅關注單一方面,而是全面地評估圖像的各個方面。

此外,團隊還對不同圖像生成方法在DreamBench++上的生成結果進行了可視化展示。
在評估圖像生成結果的保持主體情況時,DreamBench++與人類評估者達到了79.64%的一致性。
在遵循文本指令生成圖像的能力方面,DreamBench++的一致性高達93.18%。
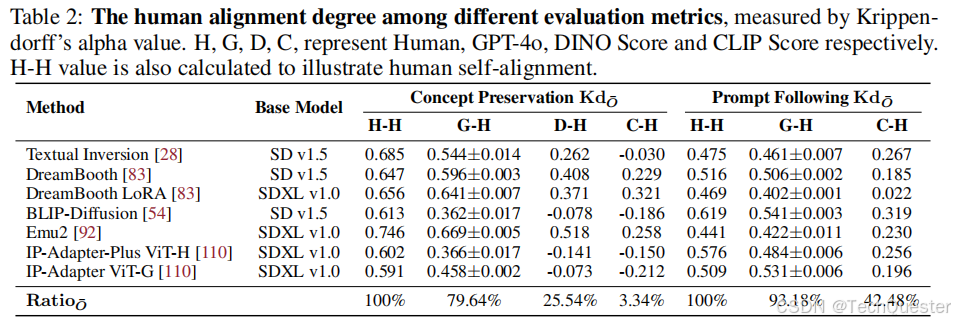
從數據來看,DreamBench++的人類一致性比DINO score高出54.1%,比CLIP score高出50.7%。這也側面說明,通過設計提示詞,能夠讓GPT-4o較為準確地捕捉和反映人類的審美和偏好。
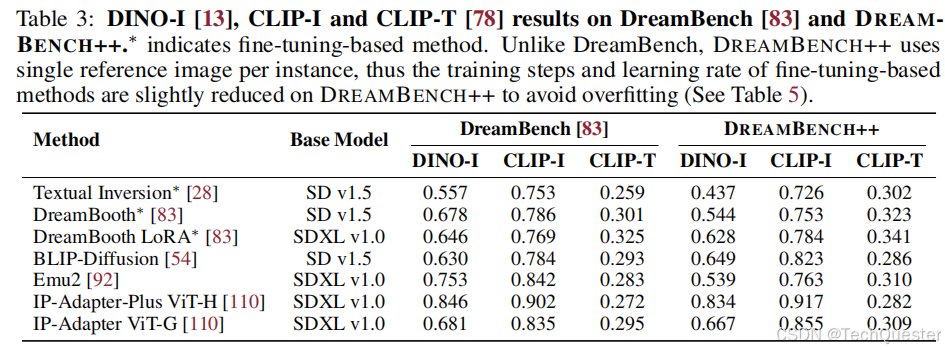
另外,DreamBench++的數據集多樣性更高,與DreamBench相比,finetune-based方法在DreamBench++上的表現會下降。
團隊推測這可能是因為他們在DreamBench上調整了參數,而DreamBench的種類并不全面。同時,Emu2在非自然或復雜圖像上的表現也會下降。
這些都說明DreamBench++更全面的數據集暴露了已有的個性化方法中的新問題。
如何使用WildCard正確方式打開GPT-4o,目前 WildCard 支持的服務非常齊全,可以說是應有盡有!
官網有更詳細介紹:WildCard
推薦閱讀:
DeepSeek-Coder-v2擊敗GPT-4 Turbo,成為競技場最強開源編碼模型!
超越GPT-4o!新王Claude 3.5 Sonnet來啦!

)

)





)



 ----------- 鎖造成的阻塞問題)
mongodb和pgvector的安裝)


原理(2)組件)

)