Promethus的監控告警Alertmanager
Alertmanager 介紹
- Prometheus的一個組件,用于定義和發送告警通知,內置多種第三方告警通知方式,同時還提供了對Webhook通知的支持
- 基于警報規則對規則產生的警報進行分組、抑制和路由,并把告警發送給合適的接收端,例如郵件、釘釘或Webhook
- 在Prometheus中一條告警規則組成
- 告警名稱:用戶需要為告警規則命名
- 告警規則:主要由PromQL進行定義,表示當表達式(PromQL)查詢結果持續多長時 間(During)后出發告警
- 關鍵特點
- 分組:將詳細的告警信息合并成一個通知,某些情況下,如由于系統宕機導致大量的告警被同時觸發
- 抑制:當某一告警發出后,可以停止重復發送由此告警引發的其它告警的機制,避免告警轟炸
- 靜默:根據標簽對告警進行靜默處理,如果接收到的告警符合靜默的配置, Alertmanager則不會發送告警通知
Alertmanager安裝
注意:記住這里的地址,后面告警需要配置這個地址
#下載
wget https://github.com/prometheus/alertmanager/releases/download/v0.27.0/alertmanager-0.27.0.linux-arm64.tar.gz
#解壓
tar -zxvf alertmanager-0.27.0.linux-arm64.tar.gz
#重名名
mv alertmanager-0.27.0.linux-amd64 alertmanager# 進入目錄
cd alertmanager#啟動
./alertmanager --config.file=alertmanager.yml#守護進程方式啟動
nohup ./alertmanager --config.file=alertmanager.yml &
- 訪問
http://ip:port, ,比如 http://47.115.61.73:9093/#/alerts
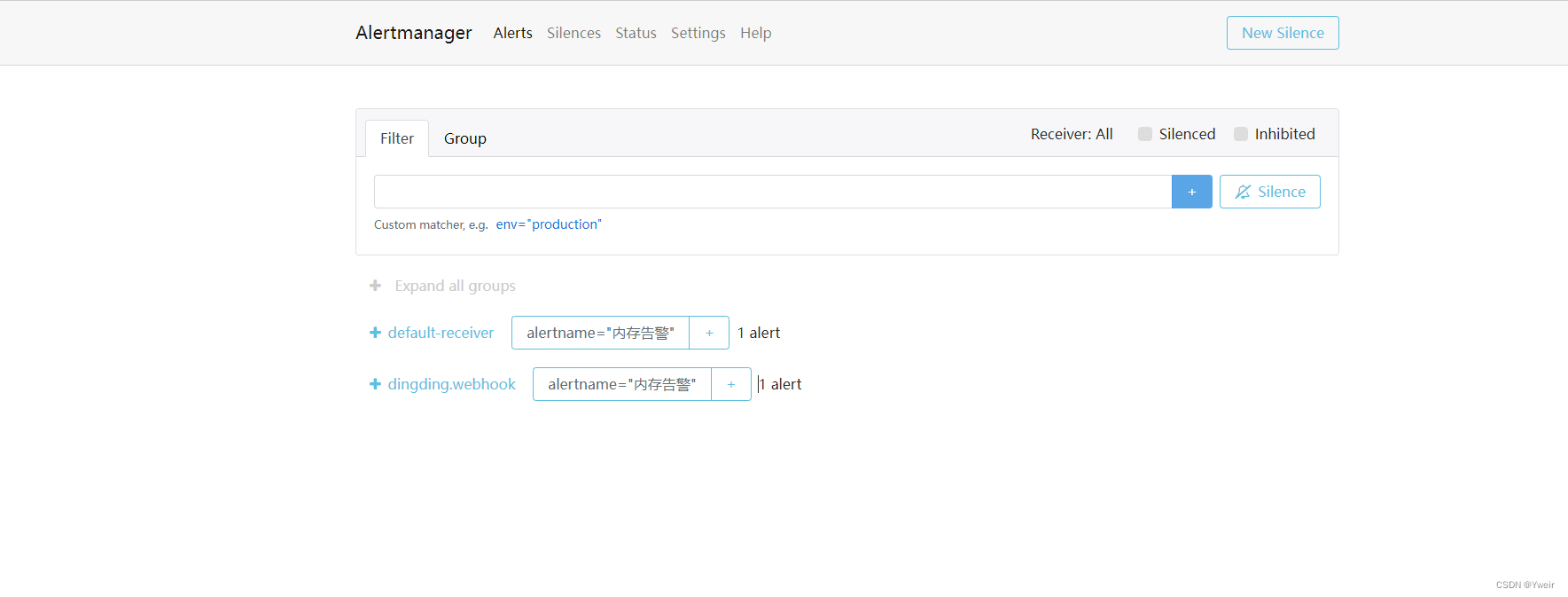
使用流程
-
步驟
- Prometheus的rules.yaml編寫告警規則
- 配置Prometheus,定義在哪些情況下被告警
- 配置Alertmanager
- 添加Email、釘釘或者短信接收程序,為告警通知指定目標和通知媒介
- 建立告警路由
- 定義告警的路由方式,以便區分和分類告警級別,并為不同的告警目標設定不同的火災通知方法。
- Prometheus的rules.yaml編寫告警規則
-
關鍵配置解讀
- Prometheus的
rule.yaml配置文件
- Prometheus的
groups: # 告警規則組
- name: server-alarmrules: #規則,可以配置多個alert告警- alert: # 告警名稱expr: # 告警表達式,基于PromQL表達式告警觸發條件,用于計算是否有時間序列滿足該條件。for: # 評估等待時間,可選,用于表示只有當觸發條件持續一段時間后才發送告警,在等待期間新產生告警 的狀態為pending。labels: #自定義標簽,允許用戶指定要附加到告警上的一組附加標簽。severity: # 告警嚴重程度annotations: #用于指定一組附加信息,比如用于描述告警詳細信息的文字等summary: # 告警摘要description: # 告警詳細描述- alert: "內存告警"expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 > 80for: 1mlabels:severity: warningannotations:summary: "{{$labels.instance}}: 檢測到 高內存 使用率!"description: "{{$labels.instance}}: 內存使用率在 80% 以上 (當前使用值為:{{ $value }})"- alert: "CPU告警"expr: (1 - avg(irate(node_cpu_seconds_total{mode="idle"}[2m])) by(instance)) * 100 > 80for: 1mlabels:severity: warningannotations:summary: "{{$labels.instance}}: 檢測到 高CPU 使用率!"description: "{{$labels.instance}}: CPU使用率在 80% 以上 (當前使用值為:{{ $value }})"
-
severity有以下幾種常用值
- critical(嚴重),用于描述影響系統主要功能甚至導致系統崩潰的情況。
- warning(警告),用于描述存在異常但不會導致系統崩潰或停止服務的情況。
- info(信息),用于描述與業務正常運行相對應的正常狀態信息。
- debug(調試),用于描述可以用于排除故障的調試信息。
-
Alertmanager的alertmanager.yml配置文件- 主要包含兩個部分:路由(
route) + 接收器(receivers)- 告警信息會從配置中的頂級路由(route)進入路由樹,根據路由規則將告警信息發送給相應的接收器
- 主要包含兩個部分:路由(
global:smtp_smarthost: 'smtp.126.com:25' # SMTP服務器地址和端口smtp_from: 'xxxxx@126.com' # 顯示在郵件“發件人”字段中的地址smtp_auth_username: 'xxxx@126.com' # STMP認證時使用的用戶名smtp_auth_password: 'xxxxxx' # SMTP認證時使用的密碼,不是密碼smtp_require_tls: false # SMTP服務器是否需要TLS加密route:receiver: 'email' # 發送告警通知的收件人,和下面的接受者名稱匹配group_wait: 10s # 在發送前等待各個警報的時間group_interval: 30s # 相同警報名稱的警報發送間隔repeat_interval: 10m # 重復發送警報的時間間隔group_by: ['alertname'] # 根據警報名分組告警接收者# 告警接收者
receivers:
- name: 'email' # 接收者名稱email_configs:- to: 'xxxxxx@qq.com' # 接收告警郵件的收件人
Alertmanager監控告警和郵件通知
需求
- 應用程序監控,如果應用程序掛了,觸發郵件發送開發人員
Prometheus板塊配置
- 配置Prometheus的rule告警規則
#創建配置文件 prometheus程序目錄下
touch rules.yml
#配置規則
groups:
- name: server-alarmrules:- alert: "InstanceDown"expr: up == 0for: 1mlabels:severity: warningannotations:summary: "{{ $labels.instance }}"description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
- 配置Prometheus關聯Alertmanager地址和rules規則啟用
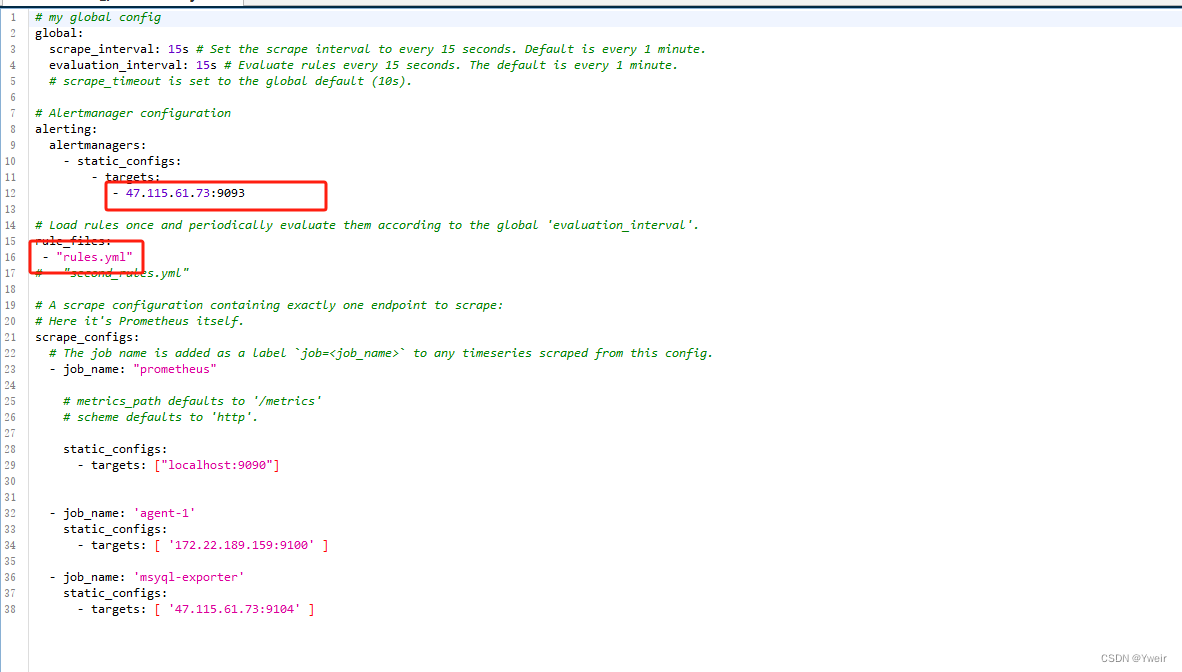
- 動態更新Prometheus配置
注意:Prometheus 需要開啟支持熱更新
curl -X POST http://localhost:9090/-/reload
Alertmanager板塊配置
- alertmanager.yml 配置文件(如果測試服務是在阿里云,需要將25端口(被禁用)改成其它的)
# 第一個版本
global:smtp_smarthost: 'smtp.126.com:465'smtp_from: 'xxxxx@126.com'smtp_auth_username: 'xxxxx@126.com'smtp_auth_password: 'xxxx'smtp_require_tls: falseroute:receiver: 'dingding.webhook'group_wait: 10sgroup_interval: 30srepeat_interval: 10mgroup_by: ['alertname', 'cluster', 'service']routes:- receiver: 'dingding.webhook'continue: true- receiver: 'default-receiver'receivers:- name: 'default-receiver'email_configs:- to: 'xxxxx@qq.com'send_resolved: true- name: 'dingding.webhook'webhook_configs:- url: 'https://oapi.dingtalk.com/robot/send?access_token=xxxx'send_resolved: true
# 第二個版本
global:smtp_smarthost: 'smtp.126.com:25' # SMTP服務器地址和端口smtp_from: 'xxxxx@126.com' # 顯示在郵件“發件人”字段中的地址smtp_auth_username: 'xxxx@126.com' # STMP認證時使用的用戶名smtp_auth_password: 'xxxxxx' # SMTP認證時使用的密碼,不是密碼smtp_require_tls: false # SMTP服務器是否需要TLS加密route:receiver: 'email' # 發送告警通知的收件人,和下面的接受者名稱匹配group_wait: 10s # 在發送前等待各個警報的時間group_interval: 30s # 相同警報名稱的警報發送間隔repeat_interval: 10m # 重復發送警報的時間間隔group_by: ['alertname'] # 根據警報名分組告警接收者# 告警接收者
receivers:
- name: 'email' # 接收者名稱email_configs:- to: 'xxxxxx@qq.com' # 接收告警郵件的收件人
應用和驗證步驟
- 應用
#啟動
./alertmanager --config.file=alertmanager.yml#守護進程方式啟動
nohup ./alertmanager --config.file=alertmanager.yml &
- 驗證步驟
- 停止spring boot程序(停止其他服務都可以)
- 查看prometheus
- 查看alertmanager
- 查看郵件
擴展Alertmanager監控告警和釘釘通知
prometheus-webhook-dingtalk 簡介
- prometheus-webhook-dingtalk是一個開源項目
- 用于將Prometheus的告警信息通過Webhook的方式發送到釘釘(DingTalk)群聊中
- 實現告警通知的即時送達與團隊協作
- 該項目作為一個輕量級但功能強大的工具,使得運維人員和開發團隊能夠直接在常用的通訊平臺上接收到監控系統的告警消息,提高響應速度和協作效率
安裝 prometheus-webhook-dingtalk
配置config.yml
## Request timeout
# timeout: 5s## Uncomment following line in order to write template from scratch (be careful!)
#no_builtin_template: true## Customizable templates path
#templates:
# - contrib/templates/legacy/template.tmpl## You can also override default template using `default_message`
## The following example to use the 'legacy' template from v0.3.0
#default_message:
# title: '{{ template "legacy.title" . }}'
# text: '{{ template "legacy.content" . }}'## Targets, previously was known as "profiles"
targets:webhook1:url: https://oapi.dingtalk.com/robot/send?access_token=xxxx
access_token: 從釘釘獲取的機器人Webhook地址的access_token
安裝
docker run -d --name prometheus-webhook-dingtalk \
-p 8060:8060 \
-v /usr/local/software/config/prometheus-webhook-dingtalk/config.yml:/etc/prometheus-webhook-dingtalk/config.yml \
timonwong/prometheus-webhook-dingtalk
- 將
/usr/local/software/config/prometheus-webhook-dingtalk/config.yml修改為配置config.yml的路徑掛載到容器
修改alertmanager 的alertmanager.yml配置
global:resolve_timeout: 5m
route:group_by: ['alertname']group_wait: 10sgroup_interval: 30srepeat_interval: 1mreceiver: 'dingding.webhook'
receivers:- name: 'dingding.webhook'webhook_configs:- url: 'http://47.115.61.73:8060/dingtalk/webhook1/send'send_resolved: true- 修改
47.115.61.73到實際部署prometheus-webhook-dingtalk服務的地址 - 重新啟動
alertmanager - 按照
應用和驗證步驟進行驗證 - 教程效果如下
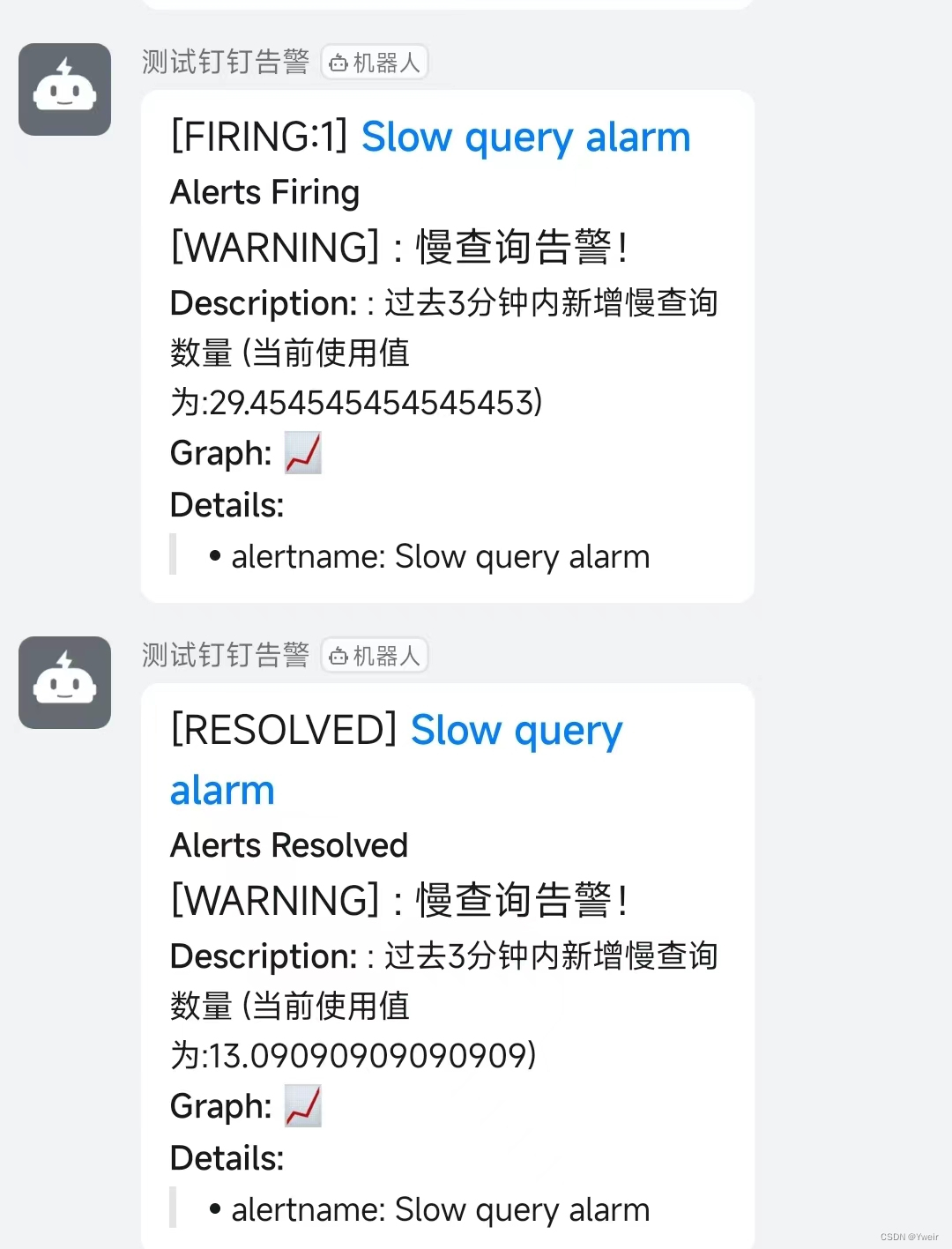
Grafana+釘釘群告警機器人
前言
- Alertmanager告警和Grafana告警功能,兩個組件各有優缺點
- Grafana更適合于小規模或簡單的監控系統,而Alertmanager更適合于大規模或更復雜的告警處理場景
- 如果需要高級告警規則和復雜的告警邏輯,請使用Alertmanager
- 如果僅需要基本的告警功能并且已經使用Grafana進行數據可視化,則可以使用Grafana作為告警處理工具
Alertmanager、Grafana對比
- Grafana
- 優點
- 簡單易用,Grafana的告警規則配置界面直觀易懂,可以方便地設置告警的觸發條件、持續時間和通知方式等
- 定制性強,Grafana的告警規則支持自定義查詢和指標,使得監控系統的告警范圍更加廣泛
- 能夠對告警事件進行統計和可視化處理,在Grafana中可以方便地對告警事件進行統計,同時還可以進行實況監控和定期報告等操作
- 缺點
- 不支持高級告警邏輯。Grafana只能識別基于簡單算術或表達式的邏輯,無法支持更復雜的邏輯
- 設計初衷不是作為告警處理工具,Grafana更多地是作為數據可視化工具
- 核心功能是數據分析和展示,并不是專門的告警處理工具,因此不太適合大規模或復雜的告警處理場景
- 可擴展性不夠,無法滿足比較復雜、高級的告警規則設計
- 優點
- Alertmanager
- 優點
- 提供高級告警邏輯功能,支持許多常用的高級告警邏輯,如靜默、抑制和聚合等
- 支持多通道分發告警,支持將告警通知分發到多個通道,如電子郵件,短信等,能夠滿足不同場景下的需求
- 可靠性高,提供多種保護機制,如去重、失敗重試和自動恢復,確保告警能夠可靠地傳送給相應的接收方
- 支持高度可擴展性,可以與各種 monitoring system 集成使告警觸發進一步個性
- 缺點
- 復雜和難以部署,Alertmanager的配置比Grafana更復雜,需要深入了解監控系統和告警系統
- 學習成本高,Alertmanager需要學習更多的知識和技能才能掌握
- 不善于定義靜態監控告警,對于 Dashboard 監控告警,它可能不太適合
- 優點
需求
- 使用Grafana的alert告警模塊,內存告警
- 配置自動告警機器人,如果內存超過一定范圍,推送到釘釘群
實現步驟
-
創建釘釘告警機器人,獲取webhook地址
- webhook地址:
https://oapi.dingtalk.com/robot/send?access_token=xxxx - Postman 驗證消息推送是否準確
- 釘釘機器人相關地址:https://open.dingtalk.com/document/robots/custom-robot-access
- webhook地址:
-
Grafana新建推送通道
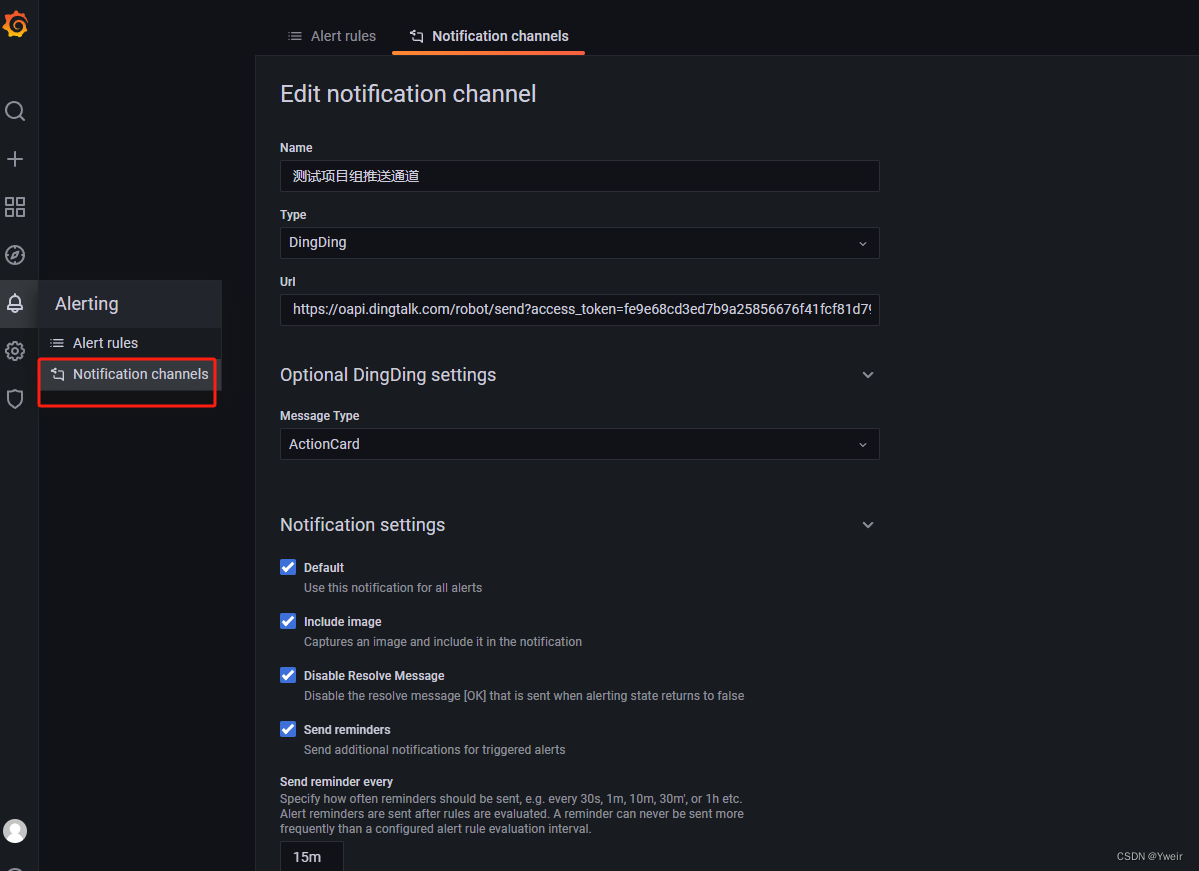
-
面板Panel配置告警規則

告警流程驗證
- 停止應用服務器
- 查看prometheus相關監控(可以停止Alert Manager)
- 查看Grafana相關告警
- 查看釘釘群機器人是否推送(記得配置ip白名單)
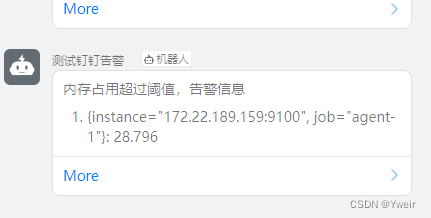
問題修復
- 點擊群告警信息沒法直接進到告警頁面
- 解決方案
- 配置默認跳轉路徑,使用root用戶進入容器修改配置文件
docker exec -u 0 -it #{容器id/容器名稱} /bin/bash
#使用該-u選項時,可以使用root用戶(ID = 0)而不是提供的默認用戶登錄Docker容器.root(id = 0)是容器中的默認用戶
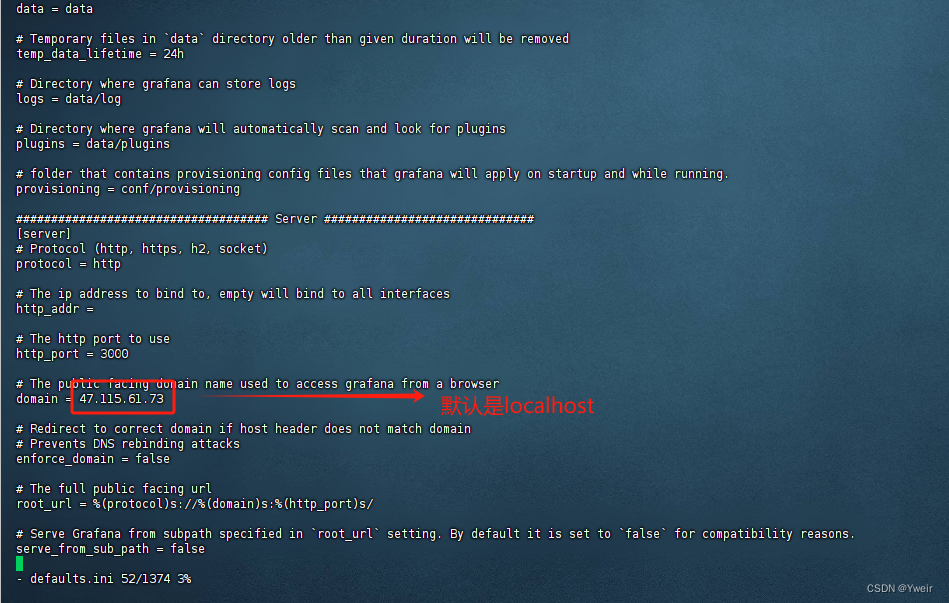
- 編輯配置文件,修改為Grafana的部署地址,然后重啟



















![【Python】已解決:FileNotFoundError: [Errno 2] No such file or directory: ‘配置信息.csv‘](http://pic.xiahunao.cn/【Python】已解決:FileNotFoundError: [Errno 2] No such file or directory: ‘配置信息.csv‘)
