第1關:情感分析的基本方法
情感分析簡介
情感分析,又稱意見挖掘、傾向性分析等。簡單而言,是對帶有情感色彩的主觀性文本進行分析、處理、歸納和推理的過程。在日常生活中,情感分析的應用非常普遍,下面列舉幾種常見的應用場景。

圖 1
1、電子商務 情感分析最常應用到的領域就是電子商務。例如淘寶和京東,用戶在購買一件商品以后可以發表他們關于該商品的體驗。通過分配等級或者分數,這些網站能夠為產品和產品的不同功能提供簡要的描述。客戶可以很容易產生關于整個產品的一些建議和反饋。通過分析用戶的評價,可以幫助這些網站提高用戶滿意度,完善不到位的地方。
2、輿情分析 無論是政府還是公司,都需要不斷監控社會對于自身的輿論態度,及時感知輿情,進行情感分析有助于及時公關,正確維護好公司的品牌,以及產品和服務評價。
3、市場呼聲 市場呼聲是指消費者使用競爭對手提供的產品與服務的感受。及時準確的市場呼聲有助于取得競爭優勢,并促進新產品的開發。盡早檢測這類信息有助于進行直接、關鍵的營銷活動。情感分析能夠為企業實時獲取消費者的意見。這種實時的信息有助于企業制定新的營銷策略,改進產品功能,并預測產品故障的可能。
根據分析載體的不同,情感分析會涉及很多主題,包括針對電影評論、商品評論,以及新聞和博客等的情感分析。對情感分析的研究到目前為止主要集中在兩個方面:識別給定的文本實體是主觀的還是客觀的,以及識別主觀的文本的極性。大多數情感分析研究都使用機器學習方法。
在情感分析領域,文本可以劃分為積極和消極兩類,或者積極、消極和中性(或不相關)的多類。分析方法主要分為:詞法分析、基于機器學習的分析以及混合分析。
詞法分析
詞法分析運用了由預標記詞匯組成的字典,使用詞法分析器將輸入文本轉換為單詞序列,將每一個新的單詞與字典中的詞匯進行匹配。如果有一個積極的匹配,分數加到輸入文本的分數總池中;相反,如果有一個消極的匹配,輸入文本的總分會減少。具體流程如圖2所示。
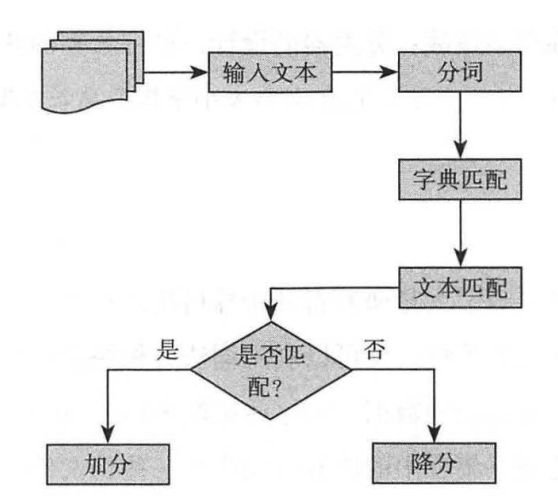
圖 2 詞法分析的流程
文本的分類取決于文本的總得分。目前有大量的工作致力于度量詞法信息的有效性。對單個短語,通過手動標記詞匯(僅包含形容詞)的方式,大概能達到85%準確率,這是由評價文本的主觀性所決定的。詞法分析也存在一個不足:其性能(時間復雜度和準確率)會隨著字典大小(詞匯的數量)的增加而迅速下降。
機器學習方法
機器學習技術由于其具有高的適應性和準確性受到了越來越多的關注。在情感分析中,主要使用的是監督學習方法。它可以分為三個階段:數據收集、預處理、訓練分類。在訓練過程中,需要提供一個標記語料庫作為訓練數據。分類器使用一系列特征向量對目標數據進行分類。
在機器學習技術中,決定分類器準確率的關鍵是合適的特征選擇,通常來說,單個短語、 兩個連續的短語以及三個連續的短語都可以被選為特征向量,當然還有其他的一些特征,如積極詞匯的數量等。
機器學習技術面臨很多挑戰,如分類器的設計、訓練數據的獲取、對一些未見過的短語的正確解釋等等。
混合分析
情感分析研究的進步吸引大量研究者開始探討將兩種方法進行組合的可能性,既可以利用機器學習方法的高準確性,又可以利用詞法分析快速的特點。有研究者利用由兩個詞組成的詞匯和一個未標記的數據,將這些由兩個詞組成的詞匯劃分為積極的類和消極的類。利用被選擇的詞匯集合中的所有單詞產生一些偽文件。然后計算偽文件與未標記文件之間的余弦相似度。根據相似度將該文件劃分為積極的或消極的情感。之后這些訓練數據集被送入樸素貝葉斯分類器進行訓練。

第2關:基于情感詞典的情感分析實戰
情感極性分析簡介
情感極性分析是對帶有感情色彩的主觀性文本進行分析、處理、歸納和推理的過程。按照處理文本的類別不同,可分為基于新聞評論的情感分析和基于產品評論的情感分析。其中,前者多用于輿情監控和信息預測,后者可幫助用戶了解某一產品在大眾心目中的口碑,目前常見的情感極性分析方法主要是兩種:基于情感詞典的方法和基于機器學習的方法。本實訓主要接下來將主要介紹基于情感詞典的情感分析,關于基于機器學習的情感分析,將在后續實訓中介紹。

圖 1
基于情感詞典的情感分析
基于情感詞典的情感分析應該是最簡單的情感分析方法了,它的思路大概為:對文檔分詞,找出文檔中的情感詞、否定詞以及程度副詞,然后判斷每個情感詞之前是否有否定詞及程度副詞,將它之前的否定詞和程度副詞劃分為一個組,如果有否定詞將情感詞的情感權值乘以?1,如果有程度副詞就乘以程度副詞的程度值,最后所有組的得分加起來,大于0的歸于正向,小于0的歸于負向。
基于情感詞典的情感分析算法流程如下:
-
將一個中文文本轉換為一個有短句子字符串組成列表
-
對每一個短句子字符串進行如下操作:
- 使用 jieba 分詞系統將一個短句子轉換成詞語、詞性對的列表;
- 使用詞語的詞性篩選出潛在的情感詞語;
- 在已有的情感詞典中查找這些潛在的情感詞語;
- 所查找的情感詞語的情感詞語分類 以及它的情感值組合成一個詞典并記錄到一個列表中;
- 使用相應的算法處理這個列表,得出這個小句子的情感極值。
-
將一個中文文本中的所有短句子的情感極值記錄在一個列表中;
-
使用相應的算法處理這個列表, 得出整個中文文本的情感極值。
采用情感詞典的情感分析算法準確度主要取決于分詞的準確率以及情感詞典的準確率,對句式簡單的句子的識別準確率高,但對復雜句子的分析依賴于復雜的文本處理算法。
算法實現
在進行基于情感詞典的情感分析之前,首先,我們需要準備好基礎數據,包括有情感詞典、否定詞詞典、程度副詞詞典、停用詞詞。然后開始進行以下步驟: 1、分詞 對我們需要進行情感分析的句子進行分詞,將分詞結果轉為字典,key 為單詞,value 為單詞在分詞結果中的索引。
def list_to_dict(word_list):data = {}for x in range(0, len(word_list)): # 將分詞結果轉為字典data[word_list[x]] = x # key 為單詞,value 為索引return data2、分詞結果的處理 在構建好字典以后,我們需要對分詞結果進行分類,找出句子中的情感詞、否定詞和程度副詞等等,便于后續計算情感極性分值。
for word in word_dict.keys():if word in sen_dict.keys() and word not in not_word_list and word not in degree_dic.keys():# 找出分詞結果中在情感字典中的詞sen_word[word_dict[word]] = sen_dict[word]elif word in not_word_list and word not in degree_dic.keys():# 分詞結果中在否定詞列表中的詞not_word[word_dict[word]] = -1elif word in degree_dic.keys():# 分詞結果中在程度副詞中的詞degree_word[word_dict[word]] = degree_dic[word]3、計算得分 首先設置初始權重 W 為1,從第一個情感詞開始,用權重 W*該情感詞的情感值作為得分(用 score 記錄),然后判斷與下一個情感詞之間是否有程度副詞及否定詞,如果有否定詞將W*-1,如果有程度副詞,W*程度副詞的程度值,此時的 W 作為遍歷下一個情感詞的權重值,循環直到遍歷完所有的情感詞,每次遍歷過程中的得分 score 加起來的總和就是這篇文檔的情感得分。?
def socre_sentiment(sen_word, not_word, degree_word, seg_result):"""計算得分"""# 權重初始化為1W = 1score = 0# 情感詞下標初始化sentiment_index = -1# 情感詞的位置下標集合sentiment_index_list = list(sen_word.keys())# 遍歷分詞結果(遍歷分詞結果是為了定位兩個情感詞之間的程度副詞和否定詞)for i in range(0, len(seg_result)):# 如果是情感詞(根據下標是否在情感詞分類結果中判斷)if i in sen_word.keys():# 權重*情感詞得分score += W * float(sen_word[i])# 情感詞下標加1,獲取下一個情感詞的位置sentiment_index += 1if sentiment_index < len(sentiment_index_list) - 1:# 判斷當前的情感詞與下一個情感詞之間是否有程度副詞或否定詞for j in range(sentiment_index_list[sentiment_index], sentiment_index_list[sentiment_index + 1]):# 更新權重,如果有否定詞,取反if j in not_word.keys():W *= -1elif j in degree_word.keys():# 更新權重,如果有程度副詞,分值乘以程度副詞的程度分值W *= float(degree_word[j])# 定位到下一個情感詞if sentiment_index < len(sentiment_index_list) - 1:i = sentiment_index_list[sentiment_index + 1]return score編程要求
在右側編輯器中的 Begin-End 之間補充 Python 代碼,完成基于情感詞典對所輸入文本進行情感分析,并輸出情感分析結果。其中文本內容通過 input 從后臺獲取。
測試說明
平臺將使用測試集運行你編寫的程序代碼,若全部的運行結果正確,則通關。
測試輸入: 我喜歡和你一起玩
預期輸出: Building prefix dict from the default dictionary ... Dumping model to file cache /tmp/jieba.cache Loading model cost 1.083 seconds. Prefix dict has been built successfully. # 分詞過程的附件信息 情感分析值為:0.00919122712083
from collections import defaultdict
import jieba
import codecs
def seg_word(sentence): # 使用jieba對文檔分詞seg_list = jieba.cut(sentence)seg_result = []for w in seg_list:seg_result.append(w)# 讀取停用詞文件stopwords = set()fr = codecs.open('./stopword.txt', 'r', 'utf-8')for word in fr:stopwords.add(word.strip())fr.close()# 去除停用詞return list(filter(lambda x: x not in stopwords, seg_result))
def classify_words(word_dict): # 詞語分類,找出情感詞、否定詞、程度副詞# 讀取情感字典文件sen_file = open('./sentiment_score.txt', 'r+', encoding='utf-8')# 獲取字典文件內容sen_list = sen_file.readlines()# 創建情感字典sen_dict = defaultdict()# 讀取字典文件每一行內容,將其轉換為字典對象,key為情感詞,value為對應的分值for s in sen_list:# 每一行內容根據空格分割,索引0是情感詞,索引1是情感分值sen_dict[s.split(' ')[0]] = s.split(' ')[1]# 讀取否定詞文件not_word_file = open('./notDic.txt', 'r+', encoding='utf-8')# 由于否定詞只有詞,沒有分值,使用list即可not_word_list = not_word_file.readlines()# 讀取程度副詞文件degree_file = open('./degree.txt', 'r+', encoding='utf-8')degree_list = degree_file.readlines()degree_dic = defaultdict()# 程度副詞與情感詞處理方式一樣,轉為程度副詞字典對象,key為程度副詞,value為對應的程度值for d in degree_list:degree_dic[d.split(',')[0]] = d.split(',')[1]# 分類結果,詞語的index作為key,詞語的分值作為value,否定詞分值設為-1sen_word = dict()not_word = dict()degree_word = dict()# 分類for word in word_dict.keys():if word in sen_dict.keys() and word not in not_word_list and word not in degree_dic.keys():# 找出分詞結果中在情感字典中的詞sen_word[word_dict[word]] = sen_dict[word]elif word in not_word_list and word not in degree_dic.keys():# 分詞結果中在否定詞列表中的詞not_word[word_dict[word]] = -1elif word in degree_dic.keys():# 分詞結果中在程度副詞中的詞degree_word[word_dict[word]] = degree_dic[word]sen_file.close()degree_file.close()not_word_file.close()# 將分類結果返回return sen_word, not_word, degree_word
def list_to_dict(word_list):data = {}for x in range(0, len(word_list)):data[word_list[x]] = xreturn data
def get_init_weight(sen_word, not_word, degree_word):# 權重初始化為1W = 1# 將情感字典的key轉為listsen_word_index_list = list(sen_word.keys())if len(sen_word_index_list) == 0:return W# 獲取第一個情感詞的下標,遍歷從0到此位置之間的所有詞,找出程度詞和否定詞for i in range(0, sen_word_index_list[0]):if i in not_word.keys():W *= -1elif i in degree_word.keys():# 更新權重,如果有程度副詞,分值乘以程度副詞的程度分值W *= float(degree_word[i])return W
def socre_sentiment(sen_word, not_word, degree_word, seg_result): # 計算得分# 權重初始化為1W = 1score = 0# 情感詞下標初始化sentiment_index = -1# 情感詞的位置下標集合sentiment_index_list = list(sen_word.keys())# 任務:完成基于情感詞典對情感得分的計算# ********** Begin *********#for i in range(0, len(seg_result)):# 如果是情感詞(根據下標是否在情感詞分類結果中判斷)if i in sen_word.keys():# 權重*情感詞得分score += W * float(sen_word[i])# 情感詞下標加1,獲取下一個情感詞的位置sentiment_index += 1if sentiment_index < len(sentiment_index_list) - 1:# 判斷當前的情感詞與下一個情感詞之間是否有程度副詞或否定詞for j in range(sentiment_index_list[sentiment_index], sentiment_index_list[sentiment_index + 1]):# 更新權重,如果有否定詞,取反if j in not_word.keys():W *= -1elif j in degree_word.keys():# 更新權重,如果有程度副詞,分值乘以程度副詞的程度分值W *= float(degree_word[j])# 定位到下一個情感詞if sentiment_index < len(sentiment_index_list) - 1:i = sentiment_index_list[sentiment_index + 1]# ********** End **********#return score
def setiment_score(sententce):# 1.對文檔分詞seg_list = seg_word(sententce)# 2.將分詞結果列表轉為dic,然后找出情感詞、否定詞、程度副詞sen_word, not_word, degree_word = classify_words(list_to_dict(seg_list))# 3.計算得分score = socre_sentiment(sen_word, not_word, degree_word, seg_list)return score第3關:基于 SnowNLP 的情感分析實戰
情感分析方法
情感分析即對帶有主觀色彩的文本進行正向、負向、中性等感情色彩進行確定的方法。情感分析的一般步驟為:輸入大量真實的評論文本,通過情感分析對每條評論進行正向負向中性判斷,再進行統計分析,從而得出作品的好評度。
目前主流的情感分析方法有:基于情感詞典的情感分析、基于機器學習的情感分析。

圖 1
1、基于情感詞典的情感分析 情感詞典法,即基于情感詞,否定詞、副詞等大量詞庫,利用相關計算公式對每條評論進行打分,最后基于得分判斷評論的褒貶性。得分為正即為正向評論,如果是負分則是負向評論,0是中性評論。其中情感詞、程度詞、否定詞來自于情感詞庫,其權重的確定由具體所使用的的模型來確定。算法步驟如圖2所示。

圖 2 基于情感詞典的情感分析
需要注意的是,根據算法對計算出的得分進行的判斷,不一定是真實的結果。為了使得判斷結果更可信,常常可以通過人工標注對大量評論進行真實準確地判斷,再對比算法判斷和人工標注的判斷來檢驗算法的準確性。詞典匹配的情感分析語料適用范圍更廣,但受限于語義表達的豐富性。
2、基于機器學習的情感分析 情感分析本質上是一個二分類的問題,通過采用機器學習的方法識別,選取文本中的情感詞作為特征詞,將文本矩陣化,利用邏輯回歸,樸素貝葉斯,支持向量機等方法進行分類。最終分類效果取決于訓練文本的選擇以及正確的情感標注。算法邏輯如圖3所示。

圖 3 基于機器學習的情感分析
認識 SnowNLP
SnowNLP 是一個基于 python 的自然語言處理庫,可以方便地處理中文文本內容,處理英文內容的包主要有 TextBlob , SnowNLP 則是受 TextBlob 的影響而開發的,和 TextBlob 不同的是,它并沒有使用用 NLTK ,所有的算法都是自己實現的,并且自帶了一些訓練好的字典。
在我們進行自然語言處理的實際開發中,SnowNLP 是一個很好的工具。SnowNLP 的功能有很多,如中文分詞、詞性標注、文本分類、情感分析等等。SnowNLP 在實際應用的過程中,我們需要先根據文本創建一個 SnowNLP 對象,再使用對應的方法進行想要的操作。
示例:對文本進行分詞
from snownlp import SnowNLPs = SnowNLP(u'這個東西真心很贊') # 對文本進行分詞print(s.words)
輸出結果: ['這個', '東西', '真心', '很', '贊']
基于 SnowNLP 進行情感分析
SnowNLP 庫中的已經訓練好的情感分析模型是基于商品的評論數據而得出的,因此,在實際使用的過程中,需要根據自己的情況,重新訓練模型。在使用 SnowNLP 進行情感分析時,會得到一個返回值,返回值代表的是文本為正面情緒的概率,越接近1表示正面情緒,越接近0表示負面情緒。
示例:文本情感分析
from snownlp import SnowNLPs = SnowNLP(u"今天我很快樂。你怎么樣呀?"); # 對文本進行情感分析print("[sentiments]",s.sentiments);
輸出結果: [sentiments] 0.971889316039116
在實際的項目中,可以根據需要對實際的數據重新訓練情感分析的模型,訓練步驟大致分為如下的幾個步驟:
-
準備正負樣本,并分別保存;
-
利用 SnowNLP 訓練新的模型;
-
保存好新的模型以供情感分析。
編程要求
在右側編輯器中的 Begin-End 之間補充 Python 代碼,完成基于 SnowNLP 對所輸入文本進行情感分析,并輸出情感分析結果。其中文本內容通過 input 從后臺獲取。
測試說明
平臺將使用測試集運行你編寫的程序代碼,若全部的運行結果正確,則通關。
測試輸入: 今天很歡樂
預期輸出: 積極情緒
from snownlp import SnowNLP
def Analysis():text = input()result=0
# 任務:使用 SnowNLP 模塊,對 text文本進行情感分析,將分析結果保存到result變量中
# ********** Begin *********#s=SnowNLP(text)result=s.sentiments
# ********** End **********#return result
)
)

![一招教你搞定Windows系統指定IP不變[固定IP地址方法]](http://pic.xiahunao.cn/一招教你搞定Windows系統指定IP不變[固定IP地址方法])
IIC子系統及其驅動)







![[RPI] istoreos安裝esphome](http://pic.xiahunao.cn/[RPI] istoreos安裝esphome)

路由v5.x(7)常見應用場景(4)- 路由切換動畫)
![[DDD] 領域驅動設計簡介](http://pic.xiahunao.cn/[DDD] 領域驅動設計簡介)


)