隨著ChatGPT的迅速出圈,加速了大模型時代的變革。對于以Transformer、MOE結構為代表的大模型來說,傳統的單機單卡訓練模式肯定不能滿足上千(萬)億級參數的模型訓練,這時候我們就需要解決內存墻和通信墻等一系列問題,在單機多卡或者多機多卡進行模型訓練。
最近,我也在探索大模型相關的一些技術,下面做一個簡單的總結,后續爭取每一個季度更新一次,本文主要涉及AI集群、AI集群通信、大模型訓練(參數高效微調)、大模型推理加速、大模型評估、大模型生態相關技術等相關內容.
同時,也對之前寫過的一些大模型相關的文章進行了匯總,篇幅太長,建議先收藏后再閱讀。
技術交流群
前沿技術資訊、算法交流、求職內推、算法競賽、面試交流(校招、社招、實習)等、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企開發者互動交流~
建了技術交流群&星球!想要資料、進交流群的同學,保存圖片到wx掃描二v碼免費領取【保證100%免費】🆓


AI 集群
由于目前只有3臺A800 GPU服務器(共24卡),基于目前現有的一些AI框架和大模型,無法充分利用3臺服務器。比如:OPT-66B一共有64層Transformer,當使用Alpa進行流水線并行時,通過流水線并行對模型進行切分,要么使用16卡,要么使用8卡,沒法直接使用24卡,因此,GPU服務器最好是購買偶數臺(如:2臺、4臺、8臺)。
具體的硬件配置如下:
-
CPUs: 每個節點具有 1TB 內存的 Intel CPU,物理CPU個數為64,每顆CPU核數為16。
-
GPUs: 24 卡 A800 80GB GPUs ,每個節點 8 個 GPU(3 個節點)。

目前使用Huggingface Transformers和DeepSpeed進行通過數據并行進行訓練(pretrain),單卡可以跑三百億參數(啟用ZeRO-2或ZeRO-3),如OPT-30B,具體訓練教程參考官方樣例。
使用Alpa進行流水線并行和數據并行進行訓練(fine tuning)時,使用了3臺共24卡(PP:12,DP:2)進行訓練OPT-30B,具體訓練教程參考官方樣例。但是進行模型訓練之前需要先進行模型格式轉換,將HF格式轉換為Alpa格式的模型文件,具體請參考官方代碼。如果不想轉換,官網也提供了轉換好的模型格式,具體請參考文檔:Serving OPT-175B, BLOOM-176B and CodeGen-16B using Alpa。

前幾天對H800進行過性能測試,整體上來說,對于模型訓練(Huggingface Transformers)和模型推理(FasterTransformer)都有30%左右的速度提升。但是對于H800支持的新數據類型FP8,目前很多開源框架暫不支持,雖然,Nvidia自家一些開源框架支持該數據類型,目前不算太穩定。

AI處理器(加速卡)
目前,主流的AI處理器無疑是NVIDIA的GPU,NVIDIA的GPU產品主要有GeForce、Tesla和Quadro三大系列,雖然,從硬件角度來看,它們都采用同樣的架構設計,也都支持用作通用計算(GPGPU),但因為它們分別面向的目標市場以及產品定位的不同,這三個系列的GPU在軟硬件的設計和支持上都存在許多差異。其中,GeForce為消費級顯卡,而Tesla和Quadro歸類為專業級顯卡。GeForce主要應用于游戲娛樂領域,而Quadro主要用于專業可視化設計和創作,Tesla更偏重于深度學習、人工智能和高性能計算。
-
Tesla:A100(A800)、H100(H800)、A30、A40、V100、P100…
-
GeForce:RTX 3090、RTX 4090 …
-
Quadro:RTX 6000、RTX 8000 …
其中,A800/H800是針對中國特供版(低配版),相對于A100/H100,主要區別:
-
A100的Nvlink最大總網絡帶寬為600GB/s,而A800的Nvlink最大總網絡帶寬為400GB/s。
-
H100的Nvlink最大總網絡帶寬為900GB/s,而A800的Nvlink最大總網絡帶寬為400GB/s。
其他的一些國外AI處理器(加速卡):
-
AMD:GPU MI300X
-
Intel:Xeon Phi
-
Google:TPU
國產AI處理器(加速卡):
-
華為:昇騰910(用于訓練和推理),昇騰310(用于推理)。采用自家設計的達芬奇架構。
-
海光DCU:8100系列(深算一號),以GPGPU架構為基礎。
-
寒武紀:思元370、思元590。
-
百度:昆侖芯,采用的是其自研XPU架構。
-
阿里:含光800。
大模型算法
模型結構:
目前主流的大模型都是Transformer、MOE結構為基礎進行構建,如果說Transformer結構使得模型突破到上億參數量,MoE 稀疏混合專家結構使模型參數量產生進一步突破,達到數萬億規模。
大模型算法:
下圖詳細展示了AI大模型的發展歷程: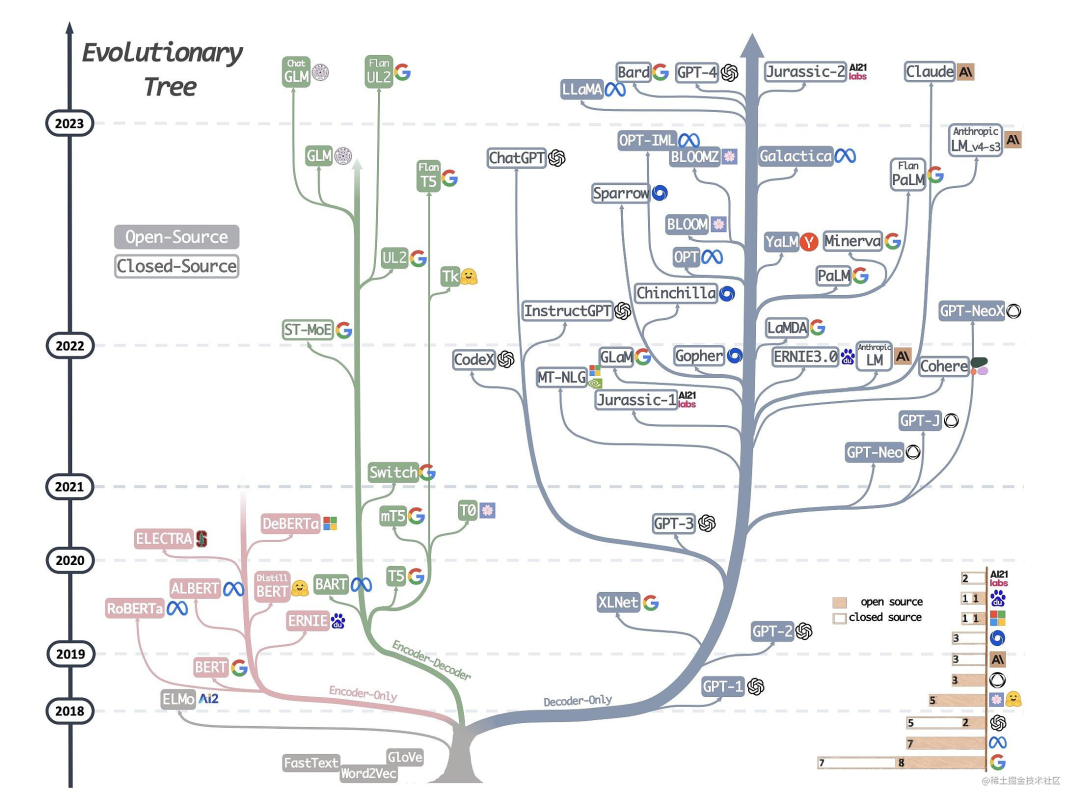
可以說,Transformer 開創了繼 MLP 、CNN和 RNN之后的第四大類模型。而基于Transformer結構的模型又可以分為Encoder-only、Decoder-only、Encoder-Decoder這三類。
-
僅編碼器架構(Encoder-only):自編碼模型(破壞一個句子,然后讓模型去預測或填補),更擅長理解類的任務,例如:文本分類、實體識別、關鍵信息抽取等。典型代表有:Bert、RoBERTa等。
-
僅解碼器架構(Decoder-only):自回歸模型(將解碼器自己當前步的輸出加入下一步的輸入,解碼器融合所有已經輸入的向量來輸出下一個向量,所以越往后的輸出考慮了更多輸入),更擅長生成類的任務,例如:文本生成。典型代表有:GPT系列、LLaMA、OPT、Bloom等。
-
編碼器-解碼器架構(Encoder-Decoder):序列到序列模型(編碼器的輸出作為解碼器的輸入),主要用于基于條件的生成任務,例如:翻譯,概要等。典型代表有:T5、BART、GLM等。
大語言模型
目前業界可以下載到的一些大語言模型:
-
ChatGLM-6B / ChatGLM2-6B :清華開源的中英雙語的對話語言模型。目前,第二代ChatGLM在官網允許的情況下可以進行商用。
-
GLM-10B/130B :雙語(中文和英文)雙向稠密模型。
-
OPT-2.7B/13B/30B/66B :Meta開源的預訓練語言模型。
-
LLaMA-7B/13B/30B/65B :Meta開源的基礎大語言模型。
-
Alpaca(LLaMA-7B):斯坦福提出的一個強大的可復現的指令跟隨模型,種子任務都是英語,收集的數據也都是英文,因此訓練出來的模型未對中文優化。
-
BELLE(BLOOMZ-7B/LLaMA-7B/LLaMA-13B):本項目基于 Stanford Alpaca,針對中文做了優化,模型調優僅使用由ChatGPT生產的數據(不包含任何其他數據)。
-
Bloom-7B/13B/176B:可以處理46 種語言,包括法語、漢語、越南語、印度尼西亞語、加泰羅尼亞語、13 種印度語言(如印地語)和 20 種非洲語言。其中,Bloomz系列模型是基于 xP3 數據集微調。 推薦用于英語的提示(prompting);Bloomz-mt系列模型是基于 xP3mt 數據集微調。推薦用于非英語的提示(prompting)。
-
Vicuna(7B/13B):由UC Berkeley、CMU、Stanford和 UC San Diego的研究人員創建的 Vicuna-13B,通過在 ShareGPT 收集的用戶共享對話數據中微調 LLaMA 獲得。其中,使用 GPT-4 進行評估,發現 Vicuna-13B 的性能在超過90%的情況下實現了與ChatGPT和Bard相匹敵的能力;同時,在 90% 情況下都優于 LLaMA 和 Alpaca 等其他模型。而訓練 Vicuna-13B 的費用約為 300 美元。不僅如此,它還提供了一個用于訓練、服務和評估基于大語言模型的聊天機器人的開放平臺:FastChat。
-
Baize:白澤是在LLaMA上訓練的。目前包括四種英語模型:白澤-7B、13B 、 30B(通用對話模型)以及一個垂直領域的白澤-醫療模型,供研究 / 非商業用途使用,并計劃在未來發布中文的白澤模型。白澤的數據處理、訓練模型、Demo 等全部代碼已經開源。
-
LLMZoo:來自香港中文大學和深圳市大數據研究院團隊推出的一系列大模型,如:Phoenix(鳳凰) 和 Chimera等。
-
MOSS:由復旦 NLP 團隊推出的 MOSS 大語言模型。
-
baichuan-7B:由百川智能推出的大模型,可進行商用。
-
CPM-Bee:百億參數的開源中英文雙語基座大模型,可進行商用。
前兩天測試了BELLE,對中文的效果感覺還不錯。具體的模型訓練(預訓練)方法可參考Hugingface Transformers的樣例,SFT(指令精調)方法可參考Alpaca的訓練代碼。
從上面可以看到,開源的大語言模型主要有三大類:GLM衍生的大模型(wenda、ChatSQL等)、LLaMA衍生的大模型(Alpaca、Vicuna、BELLE、Phoenix、Chimera等)、Bloom衍生的大模型(Bloomz、BELLE、Phoenix等)。
| 模型 | 訓練數據量 | 模型參數 | 訓練數據范圍 | 詞表大小 |
|---|---|---|---|---|
| LLaMA | 1T~1.4T tokens(其中,7B/13B使用1T,33B/65B使用1.4T) | 7B~65B | 以英語為主要語言的拉丁語系 | 32000 |
| ChatGLM-6B | 約 1T tokens | 6B | 中文、英語 | 130528 |
| Bloom | 1.6TB預處理文本,轉換為 350B 唯一 tokens | 300M~176B | 46種自然語言,13種編程語言 | 250680 |
從表格中可以看到,對于像ChatGLM-6B、LLaMA、Bloom這類大模型,要保證基座模型有比較好的效果,至少需要保證上千億、萬億級的Token量。
目前來看,LLaMA無疑是其中最閃亮的星。但是國內關于LLaMA比較大的一個爭論就是LLaMA是以英語為主要語言的拉丁語系上進行訓練的,LLaMA詞表中的中文token比較少(只有幾百個),需不需要擴充詞表?如果不擴充詞表,中文效果會不會比較差?
-
如果不擴充詞表,對于中文效果怎么樣?根據Vicuna官方的報告,經過Instruction Turing的Vicuna-13B已經有非常好的中文能力。
-
LLaMA需不需要擴充詞表?根據Chinese-LLaMA-Alpaca和BELLE的報告,擴充中文詞表,可以提升中文編解碼效率以及模型的性能。但是擴詞表,相當于從頭初始化開始訓練這些參數。如果想達到比較好的性能,需要比較大的算力和數據量。同時,Chinese-LLaMA-Alpaca也指出在進行第一階段預訓練(凍結transformer參數,僅訓練embedding,在盡量不干擾原模型的情況下適配新增的中文詞向量)時,模型收斂速度較慢。如果不是有特別充裕的時間和計算資源,建議跳過該階段。因此,雖然擴詞表看起來很誘人,但是實際操作起來,還是很有難度的。
下面是BELLE針對是否擴充詞表,數據質量、數據語言分布、數據規模對于模型性能的對比:
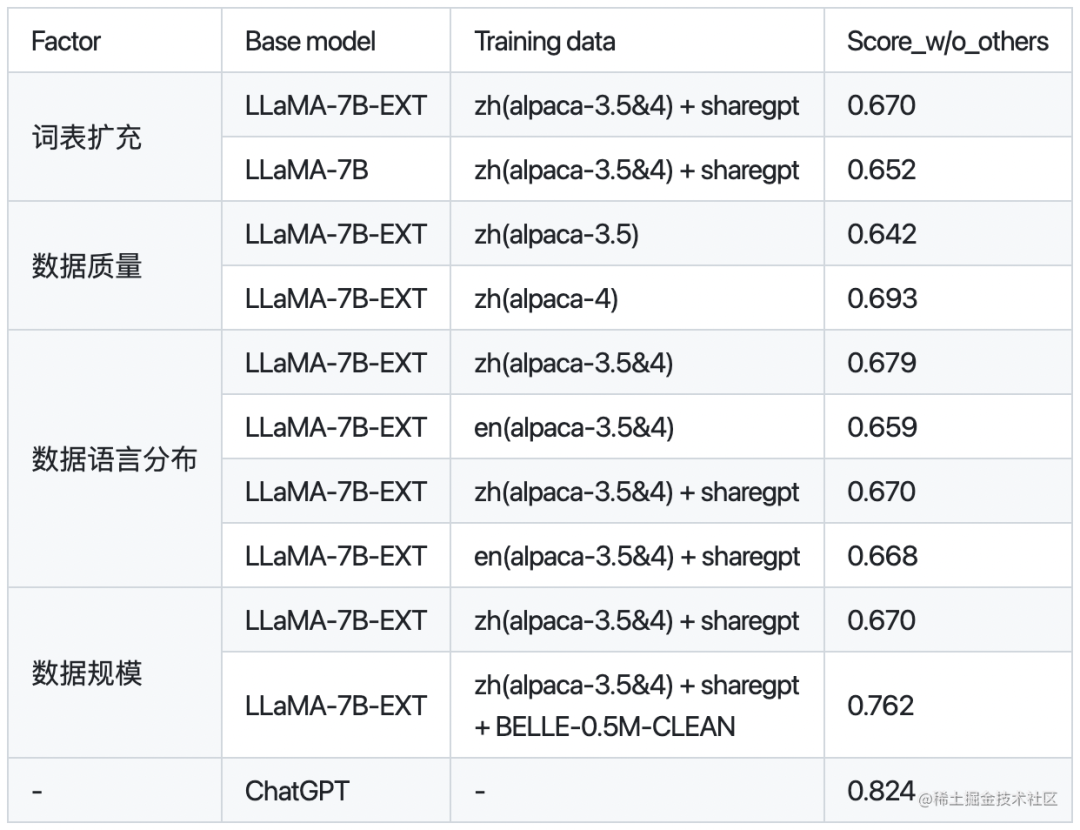
其中,BELLE-0.5M-CLEAN是從230萬指令數據中清洗得到0.5M數據(包含單輪和多輪對話數據)。LLaMA-7B-EXT是針對LLaMA做了中文詞表擴充的預訓練模型。
下面是Chinese-LLaMA-Alpaca針對中文Alpaca-13B、中文Alpaca-Plus-7B、中文Alpaca-Plus-13B的效果對比:
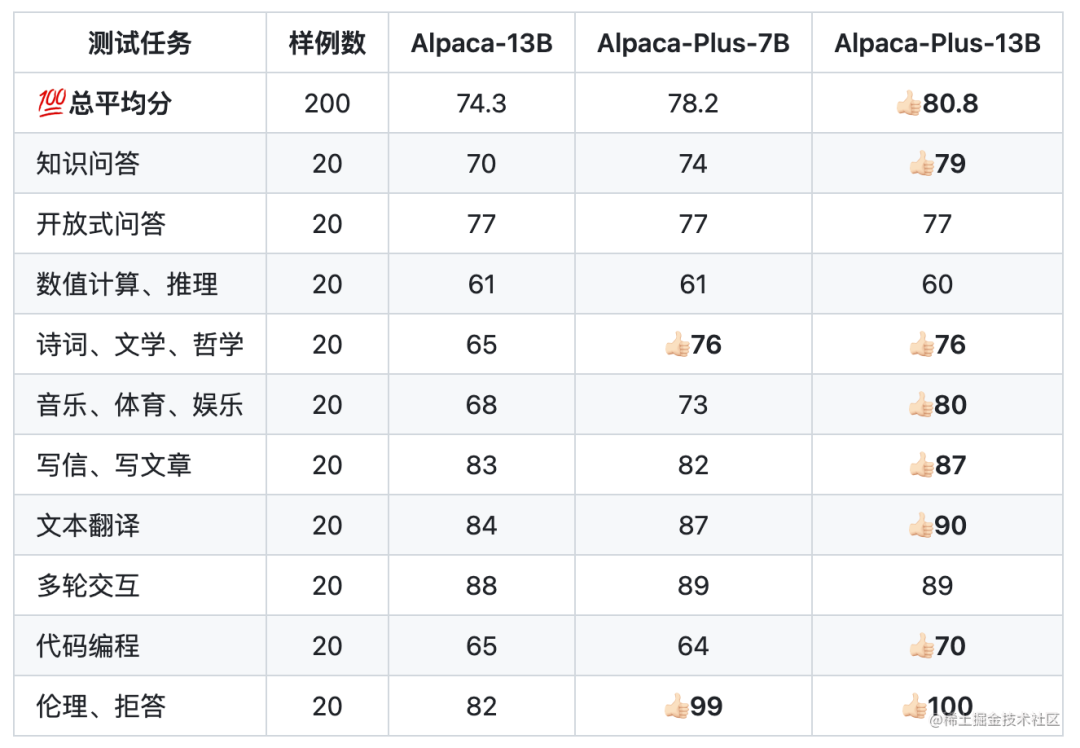
其中,Plus系列Alpaca是在原版LLaMA的基礎上擴充了中文詞表,使用了120G中文通用純文本數據進行二次預訓練。
因此,如果既想要中文詞表,又沒有很大的算力,那建議直接使用ChatGLM-6B或者使用BELLE和Chinese-LLaMA-Alpaca進行中文詞表擴充后訓練好的模型作為Base模型。
多模態大模型
目前業界可以下載到的一些多模態大模型:
-
MiniGPT-4:沙特阿拉伯阿卜杜拉國王科技大學的研究團隊開源。
-
LLaVA:由威斯康星大學麥迪遜分校,微軟研究院和哥倫比亞大學共同出品。
-
VisualGLM-6B:開源的,支持圖像、中文和英文的多模態對話語言模型,語言模型基于 ChatGLM-6B,具有 62 億參數;圖像部分通過訓練 BLIP2-Qformer 構建起視覺模型與語言模型的橋梁,整體模型共78億參數。
-
VisCPM:于CPM基礎模型的中英雙語多模態大模型。
領域大模型
金融領域大模型
-
軒轅:在BLOOM-176B的基礎上針對中文通用領域和金融領域進行了針對性的預訓練與微調。
-
Cornucopia(聚寶盆):開源了經過中文金融知識指令精調/指令微調(Instruct-tuning) 的LLaMA-7B模型。通過中文金融公開數據+爬取的金融數據構建指令數據集,并在此基礎上對LLaMA進行了指令微調,提高了 LLaMA 在金融領域的問答效果。基于相同的數據,后期還會利用GPT3.5 API構建高質量的數據集,另在中文知識圖譜-金融上進一步擴充高質量的指令數據集。
-
BBT-FinCUGE-Applications:開源了中文金融領域開源語料庫BBT-FinCorpus,中文金融領域知識增強型預訓練語言模型BBT-FinT5及中文金融領域自然語言處理評測基準CFLEB。
法律領域大模型
-
ChatLaw:由北京大學開源的大模型,主要有13B、33B。
-
LexiLaw:LexiLaw 是一個經過微調的中文法律大模型,它基于 ChatGLM-6B 架構,通過在法律領域的數據集上進行微調,使其在提供法律咨詢和支持方面具備更高的性能和專業性。
-
LaWGPT:該系列模型在通用中文基座模型(如 Chinese-LLaMA、ChatGLM 等)的基礎上擴充法律領域專有詞表、大規模中文法律語料預訓練,增強了大模型在法律領域的基礎語義理解能力。在此基礎上,構造法律領域對話問答數據集、中國司法考試數據集進行指令精調,提升了模型對法律內容的理解和執行能力。
-
Lawyer LLaMA:開源了一系列法律領域的指令微調數據和基于LLaMA訓練的中文法律大模型的參數。Lawyer LLaMA 首先在大規模法律語料上進行了continual pretraining。在此基礎上,借助ChatGPT收集了一批對中國國家統一法律職業資格考試客觀題(以下簡稱法考)的分析和對法律咨詢的回答,利用收集到的數據對模型進行指令微調,讓模型習得將法律知識應用到具體場景中的能力。
醫療領域大模型
-
DoctorGLM:基于 ChatGLM-6B的中文問診模型,通過中文醫療對話數據集進行微調,實現了包括lora、p-tuningv2等微調及部署。
-
BenTsao:源了經過中文醫學指令精調/指令微調(Instruct-tuning) 的LLaMA-7B模型。通過醫學知識圖譜和GPT3.5 API構建了中文醫學指令數據集,并在此基礎上對LLaMA進行了指令微調,提高了LLaMA在醫療領域的問答效果。
-
BianQue:一個經過指令與多輪問詢對話聯合微調的醫療對話大模型,基于ClueAI/ChatYuan-large-v2作為底座,使用中文醫療問答指令與多輪問詢對話混合數據集進行微調。
-
HuatuoGPT:開源了經過中文醫學指令精調/指令微調(Instruct-tuning)的一個GPT-like模型。
-
Med-ChatGLM:基于中文醫學知識的ChatGLM模型微調,微調數據與BenTsao相同。
-
QiZhenGPT:該項目利用啟真醫學知識庫構建的中文醫學指令數據集,并基于此在LLaMA-7B模型上進行指令精調,大幅提高了模型在中文醫療場景下效果,首先針對藥品知識問答發布了評測數據集,后續計劃優化疾病、手術、檢驗等方面的問答效果,并針對醫患問答、病歷自動生成等應用展開拓展。
-
XrayGLM:該項目為促進中文領域醫學多模態大模型的研究發展,發布了XrayGLM數據集及模型,其在醫學影像診斷和多輪交互對話上顯示出了非凡的潛力。
-
MedicalGPT:訓練醫療大模型,實現包括二次預訓練、有監督微調、獎勵建模、強化學習訓練。發布中文醫療LoRA模型shibing624/ziya-llama-13b-medical-lora,基于Ziya-LLaMA-13B-v1模型,SFT微調了一版醫療模型,醫療問答效果有提升,發布微調后的LoRA權重。
教育領域大模型
-
桃李(Taoli):一個在國際中文教育領域數據上進行了額外訓練的模型。項目基于目前國際中文教育領域流通的500余冊國際中文教育教材與教輔書、漢語水平考試試題以及漢語學習者詞典等,構建了國際中文教育資源庫,構造了共計 88000 條的高質量國際中文教育問答數據集,并利用收集到的數據對模型進行指令微調,讓模型習得將知識應用到具體場景中的能力。
-
EduChat:該項目華東師范大學計算機科學與技術學院的EduNLP團隊研發,主要研究以預訓練大模型為基底的教育對話大模型相關技術,融合多樣化的教育垂直領域數據,輔以指令微調、價值觀對齊等方法,提供教育場景下自動出題、作業批改、情感支持、課程輔導、高考咨詢等豐富功能,服務于廣大老師、學生和家長群體,助力實現因材施教、公平公正、富有溫度的智能教育。
數學領域大模型
- chatglm-maths:基于chatglm-6b微調/LORA/PPO/推理的數學題解題大模型, 樣本為自動生成的整數/小數加減乘除運算, 可gpu/cpu部署,開源了訓練數據集等。
RLHF(人工反饋強化學習)
根據 OpenAI 之前做的一些實驗,可以看到使用了 PPO(近端策略優化)算法的 RLHF 模型整體上都更好一些。當把結果提供給人類時,相比于 SFT 模型和通過 prompt 化身為助理的基礎模型,人類也基本更喜歡來自 RLHF 模型的 token。
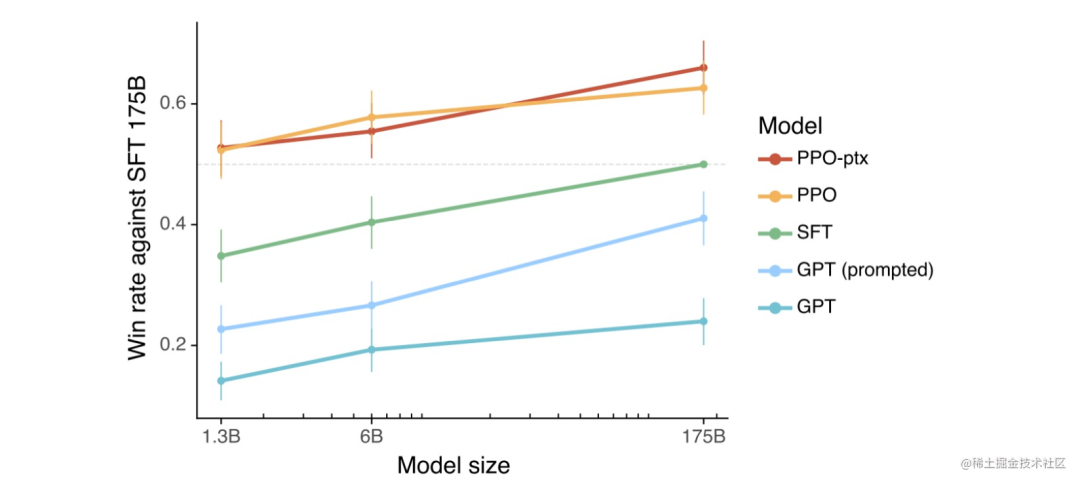
那 RLHF 為什么能讓模型更好呢?目前 AI 研究界還沒有找到一個得到大家認可的理論,一種可能與比較和生成的計算難度之間的不對稱性有關。
舉個例子說明一下:假設我們要讓一個模型寫一首關于回形針的俳句。如果你是一位正努力創建訓練數據的合同工,正在為 SFT 模型收集數據。那么你該怎樣寫出一首關于回形針的好俳句呢?而你可能并不是一位優秀的俳句詩人。但是,如果給你幾首俳句,你卻有能力辨別它們中哪首更好一些。也就是說,比起創建一個好樣本,判斷哪個樣本更好是簡單得多的任務。因此,這種不對稱性可能使得比較是一種更好的方法,能更好地利用人類的判斷來創造出好一些的模型。
但目前來看,RLHF 并不總是會為基石模型帶來提升。在某些情況下,RLHF 模型會失去一些熵,也就是說它們會輸出更加單調、變化更少的結果。而基礎模型的熵更高,可以輸出更加多樣化的結果。
RLHF開源工具
下面是目前開源的一些RLHF工具:
-
DeepSpeed Chat:基于Opt系列模型進行示例。
-
ColossalChat:基于LLaMA系列模型進行示例。
分布式并行及顯存優化技術
并行技術:
-
數據并行(如:PyTorch DDP)
-
模型/張量并行(如:Megatron-LM(1D)、Colossal-AI(2D、2.5D、3D))
-
流水線并行(如:GPipe、PipeDream、PipeDream-2BW、PipeDream Flush(1F1B))
-
多維混合并行(如:3D并行(數據并行、模型并行、流水線并行))
-
自動并行(如:Alpa(自動算子內/算子間并行))
-
優化器相關的并行(如:ZeRO(零冗余優化器,在執行的邏輯上是數據并行,但可以達到模型并行的顯存優化效果)、PyTorch FSDP)
顯存優化技術:
-
重計算(Recomputation):Activation checkpointing(Gradient checkpointing),本質上是一種用時間換空間的策略。
-
卸載(Offload)技術:一種用通信換顯存的方法,簡單來說就是讓模型參數、激活值等在CPU內存和GPU顯存之間左右橫跳。如:ZeRO-Offload、ZeRO-Infinity等。
-
混合精度(BF16/FP16):降低訓練顯存的消耗,還能將訓練速度提升2-4倍。
-
BF16 計算時可避免計算溢出,出現Inf case。
-
FP16 在輸入數據超過65506 時,計算結果溢出,出現Inf case。
分布式訓練框架
如何選擇一款分布式訓練框架?
-
訓練成本:不同的訓練工具,訓練同樣的大模型,成本是不一樣的。對于大模型,訓練一次動輒上百萬/千萬美元的費用。合適的成本始終是正確的選擇。
-
訓練類型:是否支持數據并行、張量并行、流水線并行、多維混合并行、自動并行等
-
效率:將普通模型訓練代碼變為分布式訓練所需編寫代碼的行數,我們希望越少越好。
-
靈活性:你選擇的框架是否可以跨不同平臺使用?
常見的分布式訓練框架:
-
第一類:深度學習框架自帶的分布式訓練功能。如:TensorFlow、PyTorch、MindSpore、Oneflow、PaddlePaddle等。
-
第二類:基于現有的深度學習框架(如:PyTorch、Flax)進行擴展和優化,從而進行分布式訓練。如:Megatron-LM(張量并行)、DeepSpeed(Zero-DP)、Colossal-AI(高維模型并行,如2D、2.5D、3D)、Alpa(自動并行)等
目前訓練超大規模語言模型主要有兩條技術路線:
-
TPU + XLA + TensorFlow/JAX :由Google主導,由于TPU和自家云平臺GCP深度綁定。
-
GPU + PyTorch + Megatron-LM + DeepSpeed :由NVIDIA、Meta、MicroSoft大廠加持,社區氛圍活躍,也更受到大家歡迎。
對于國內來說,華為昇騰在打造 AI 全棧軟硬件平臺(昇騰NPU+CANN+MindSpore+MindFormers)。不過目前整個生態相對前兩者,還差很遠。
參數高效微調(PEFT)技術
在面對特定的下游任務時,如果進行Full FineTuning(即對預訓練模型中的所有參數都進行微調),太過低效;而如果采用固定預訓練模型的某些層,只微調接近下游任務的那幾層參數,又難以達到較好的效果。
PEFT技術旨在通過最小化微調參數的數量和計算復雜度,來提高預訓練模型在新任務上的性能,從而緩解大型預訓練模型的訓練成本。這樣一來,即使計算資源受限,也可以利用預訓練模型的知識來迅速適應新任務,實現高效的遷移學習。因此,PEFT技術可以在提高模型效果的同時,大大縮短模型訓練時間和計算成本,讓更多人能夠參與到深度學習研究中來。除此之外,FEFT可以緩解全量微調帶來災難性遺忘的問題。
-
Prefix Tuning:與full fine-tuning更新所有參數的方式不同,該方法是在輸入token之前構造一段任務相關的virtual tokens作為Prefix,然后訓練的時候只更新Prefix部分的參數,而Transformer中的其他部分參數固定。該方法其實和構造Prompt類似,只是Prompt是人為構造的“顯式”的提示,并且無法更新參數,而Prefix則是可以學習的“隱式”的提示。 同時,為了防止直接更新Prefix的參數導致訓練不穩定的情況,他們在Prefix層前面加了MLP結構(相當于將Prefix分解為更小維度的Input與MLP的組合后輸出的結果),訓練完成后,只保留Prefix的參數。
-
Prompt Tuning:該方法可以看作是Prefix Tuning的簡化版本,只在輸入層加入prompt tokens,并不需要加入MLP進行調整來解決難訓練的問題。隨著預訓練模型參數量的增加,Prompt Tuning的方法會逼近fine-tuning的結果。
-
P-Tuning:該方法的提出主要是為了解決這樣一個問題:大模型的Prompt構造方式嚴重影響下游任務的效果。P-Tuning將Prompt轉換為可以學習的Embedding層,并用MLP+LSTM的方式來對prompt embedding進行一層處理。
-
P-Tuning v2:讓Prompt Tuning能夠在不同參數規模的預訓練模型、針對不同下游任務的結果上都達到匹敵Fine-tuning的結果。相比Prompt Tuning和P-tuning的方法,P-Tuning v2方法在多層加入了Prompts tokens作為輸入,帶來兩個方面的好處:
-
帶來更多可學習的參數(從P-tuning和Prompt Tuning的0.1%增加到0.1%-3%),同時也足夠參數高效。
-
加入到更深層結構中的Prompt能給模型預測帶來更直接的影響。
-
Adapter Tuning:該方法設計了Adapter結構(首先是一個down-project層將高維度特征映射到低維特征,然后過一個非線形層之后,再用一個up-project結構將低維特征映射回原來的高維特征;同時也設計了skip-connection結構,確保了在最差的情況下能夠退化為identity),并將其嵌入Transformer的結構里面,在訓練時,固定住原來預訓練模型的參數不變,只對新增的Adapter結構進行微調。同時為了保證訓練的高效性(也就是盡可能少的引入更多參數)。
-
LoRA:在涉及到矩陣相乘的模塊,引入A、B這樣兩個低秩矩陣模塊去模擬full fine-tuning的過程,相當于只對語言模型中起關鍵作用的低秩本質維度進行更新。
-
QLoRA:使用一種新穎的高精度技術將預訓練模型量化為 4 bit,然后添加一小組可學習的低秩適配器權重,這些權重通過量化權重的反向傳播梯度進行微調。目前,訓練速度較慢。
-
AdaLoRA:對LoRA的一種改進,它根據重要性評分動態分配參數預算給權重矩陣。
典型應用:
-
ChatGLM-Tuning :一種平價的chatgpt實現方案,基于清華的 ChatGLM-6B + LoRA 進行finetune。
-
Alpaca-Lora:使用低秩自適應(LoRA)復現斯坦福羊駝的結果。Stanford Alpaca 是在 LLaMA 整個模型上微調,而 Alpaca-Lora 則是利用 Lora 技術,在凍結原模型 LLaMA 參數的情況下,通過往模型中加入額外的網絡層,并只訓練這些新增的網絡層參數。由于這些新增參數數量較少,這樣不僅微調的成本顯著下降,還能獲得和全模型微調類似的效果。
-
BLOOM-LORA:由于LLaMA的限制,我們嘗試使用Alpaca-Lora重新實現BLOOM-LoRA。
PEFT實現:
-
PEFT:Huggingface推出的PEFT庫。
-
unify-parameter-efficient-tuning:一個參數高效遷移學習的統一框架。
高效微調技術目前存在的兩個問題:
相比全參數微調,大部分的高效微調技術目前存在的兩個問題:
-
推理速度會變慢
-
模型精度會變差
影響大模型性能的主要因素
OpenAI的論文Scaling Laws for Neural Language Models中列舉了影響模型性能最大的三個因素:計算量、數據集大小、模型參數量。也就是說,當其他因素不成為瓶頸時,計算量、數據集大小、模型參數量這3個因素中的單個因素指數增加時,loss會線性的下降。
除了以上的因素之外,還有一個比較大的影響因素就是數據質量。在微軟的論文Instruction Tuning with GPT-4中指出,同樣基于LLaMA模型,使用GPT3和GPT4產生的數據,對模型進行Instruction Turing,可以看到GPT4的數據微調過的模型效果遠遠好于GPT3數據微調的模型,可見數據質量帶來的影響。同樣的,Vicuna(7B/13B)的Instruction Turing中,也對shareGPT的數據做了很細致的清洗工作。
衡量大模型水平
要評估一個大型語言模型的水平,可以從以下幾個維度提出具有代表性的問題。
-
理解能力:提出一些需要深入理解文本的問題,看模型是否能準確回答。
-
語言生成能力:讓模型生成一段有關特定主題的文章或故事,評估其生成的文本在結構、邏輯和語法等方面的質量。
-
知識面廣度:請模型回答關于不同主題的問題,以測試其對不同領域的知識掌握程度。這可以是關于科學、歷史、文學、體育或其他領域的問題。一個優秀的大語言模型應該可以回答各種領域的問題,并且準確性和深度都很高。
-
適應性:讓模型處理各種不同類型的任務,例如:寫作、翻譯、編程等,看它是否能靈活應對。
-
長文本理解:提出一些需要處理長文本的問題,例如:提供一篇文章,讓模型總結出文章的要點,或者請模型創作一個故事或一篇文章,讓其有一個完整的情節,并且不要出現明顯的邏輯矛盾或故事結構上的錯誤。一個好的大語言模型應該能夠以一個連貫的方式講述一個故事,讓讀者沉浸其中。
-
長文本生成:請模型創作一個故事或一篇文章,讓其有一個完整的情節,并且不要出現明顯的邏輯矛盾或故事結構上的錯誤。一個好的大語言模型應該能夠以一個連貫的方式講述一個故事,讓讀者沉浸其中。
-
多樣性:提出一個問題,讓模型給出多個不同的答案或解決方案,測試模型的創造力和多樣性。
-
情感分析和推斷:提供一段對話或文本,讓模型分析其中的情感和態度,或者推斷角色間的關系。
-
情感表達:請模型生成帶有情感色彩的文本,如描述某個場景或事件的情感、描述一個人物的情感狀態等。一個優秀的大語言模型應該能夠準確地捕捉情感,將其表達出來。
-
邏輯推理能力:請模型回答需要進行推理或邏輯分析的問題,如概率或邏輯推理等。這可以幫助判斷模型對推理和邏輯思考的能力,以及其在處理邏輯問題方面的準確性。例如:“所有的動物都會呼吸。狗是一種動物。那么狗會呼吸嗎?”
-
問題解決能力:提出實際問題,例如:數學題、編程問題等,看模型是否能給出正確的解答。
-
道德和倫理:測試模型在處理有關道德和倫理問題時的表現,例如:“在什么情況下撒謊是可以接受的?”
-
對話和聊天:請模型進行對話,以測試其對自然語言處理的掌握程度和能力。一個優秀的大語言模型應該能夠準確地回答問題,并且能夠理解人類的語言表達方式。
大模型評估方法:
人工評估:LIMA、Phoenix
使用 GPT-4 的反饋進行自動評估:Vicuna、Phoenix、Chimera、BELLE
指標評估(BLEU-4、ROUGE分數):ChatGLM-6B;對于像ROUGE-L分數的指標評估,有些地方稱其為非自然指令評估(Unnatural Instruction Evaluation)。
Chatbot Arena:目前用來衡量一個模型好不好的東西基本都是基于一些學術的benchmark,比如在一個某個NLP任務上構建一個測試數據集,然后看測試數據集上準確率多少。然而,這些學術benchmark(如HELM)在大模型和聊天機器人上就不好用了。其原因在于:
-
由于評判聊天機器人聊得好不好這件事是非常主觀的,因此,現有的方法很難對其進行衡量。
-
這些大模型在訓練的時候就幾乎把整個互聯網的數據都掃了一個遍,因此,很難保證測試用的數據集沒有被看到過。甚至更進一步,用測試集直接對模型進行「特訓」,如此一來表現必然更好。
-
理論上我們可以和聊天機器人聊任何事情,但很多話題或者任務在現存的benchmark里面根本就不存在。
因此,Chatbot Arena 的做法是放棄benchmark,通過對抗,實時聊天,兩兩比對人工進行打分,采用elo分數進行評測。
大模型評估工具:
-
OpenAI evals:OpenAI的自動化評估腳本,核心思路就是通過寫prompt模版來自動化評估。
-
PandaLM:其是直接訓練了一個自動化打分模型,0,1,2三分制用模型對兩個候選模型進行打分。
大模型推理加速
模型推理作為模型投產的最后一公里,需要確保模型精度的同時追求極致的推理性能。相比傳統模型來說,大模型面臨著更多的挑戰。
當前優化模型最主要技術手段概括來說有以下三個層面:
-
算法層面:蒸餾、量化
-
軟件層面:計算圖優化、模型編譯
-
硬件層面:FP8(NVIDIA H系列GPU開始支持FP8,兼有fp16的穩定性和int8的速度)
推理加速框架:
-
FasterTransformer:英偉達推出的FasterTransformer不修改模型架構而是在計算加速層面優化 Transformer 的 encoder 和 decoder 模塊。具體包括如下:
-
盡可能多地融合除了 GEMM 以外的操作
-
支持 FP16、INT8、FP8
-
移除 encoder 輸入中無用的 padding 來減少計算開銷
-
TurboTransformers:騰訊推出的 TurboTransformers 由 computation runtime 及 serving framework 組成。加速推理框架適用于 CPU 和 GPU,最重要的是,它可以無需預處理便可處理變長的輸入序列。具體包括如下:
-
與 FasterTransformer 類似,它融合了除 GEMM 之外的操作以減少計算量
-
smart batching,對于一個 batch 內不同長度的序列,它也最小化了 zero-padding 開銷
-
對 LayerNorm 和 Softmax 進行批處理,使它們更適合并行計算
-
引入了模型感知分配器,以確保在可變長度請求服務期間內存占用較小
AI 集群網絡通信
通信硬件
機器內通信:
-
共享內存,比如:CPU與CPU之間的通信可以通過共享內存。
-
PCIe,通常是CPU與GPU之間的通信,也可以用于GPU與GPU之間的通信。
-
NVLink(直連模式),通常是GPU與GPU之間的通信,也可以用于CPU與GPU之間的通信。
機器間通信:
-
TCP/IP網絡
-
RDMA:遠程直接內存訪問,目前主要有如下三種技術:
-
InfiniBand
-
iWarp
-
RoCE v2
通信軟件
下面是一些常見的網絡通信庫:
-
Gloo: Facebook 開源的一套集體通信庫,提供了對機器學習中有用的一些集合通信算法。
-
NCCL:英偉達基于 NVIDIA-GPU 的一套開源的集合通信庫。
-
OpenMPI:一個開源 MPI(消息傳遞接口 )的實現,由學術,研究和行業合作伙伴聯盟開發和維護。
-
HCCL:華為開發的網絡通信庫。
通信網絡監控
-
nvbandwidth:用于測量 NVIDIA GPU 帶寬的工具。
-
DCGM:一個用于收集telemetry數據和測量 NVIDIA GPU 運行狀況。
大模型生態相關技術
大模型是基座,要想讓其變成一款產品,我們還需要一些其他相關技術:
LLM 應用開發工具
-
langchain:一個用于構建基于大型語言模型(LLM)的應用程序的庫。它可以幫助開發者將LLM 與其他計算或知識源結合起來,創建更強大的應用程序。
-
llama-index:一個將大語言模型和外部數據連接在一起的工具。
-
gpt-cache:LLM 語義緩存層(caching layer),它采用語義緩存(semantic cache)技術,能夠存儲 LLM 響應,從而顯著減少檢索數據所需的時間、降低 API 調用開銷、提升應用可擴展性。
向量數據庫
-
Pinecone
-
Milvus
-
Vespa
-
Weaviate
總的來說,如果想快速驗證,Pinecone 是個不錯的選擇。如果想擁有更靈活的查詢方式,可以考慮 Vespa 或 Weaviate.如果需要更好的可擴展性和可靠性,那么經過大客戶驗證的 Vespa 或 Milvus 可能是不錯的選擇。
經驗與教訓
經驗:
-
對于同一模型,選擇不同的訓練框架,對于資源的消耗情況可能存在顯著差異(比如使用Huggingface Transformers和DeepSpeed訓練OPT-30相對于使用Alpa對于資源的消耗會低不少)。
-
進行大模型模型訓練時,先使用小規模模型(如:OPT-125m/2.7b)進行嘗試,然后再進行大規模模型(如:OPT-13b/30b…)的嘗試,便于出現問題時進行排查。目前來看,業界也是基于相對較小規模參數的模型(6B/7B/13B)進行的優化,同時,13B模型經過指令精調之后的模型效果已經能夠到達GPT4的90%的效果。
-
對于一些國產AI加速卡,目前來說,坑還比較多,如果時間不是時間非常充裕,還是盡量選擇Nvidia的AI加速卡。
教訓:
-
針對已有的環境進行分布式訓練環境搭建時,一定要注意之前環境的python、pip、virtualenv、setuptools的版本。不然創建的虛擬環境即使指定對了Python版本,也可能會遇到很多安裝依賴庫的問題(GPU服務器能夠訪問外網的情況下,建議使用Docker相對來說更方便)。
-
遇到需要升級GLIBC等底層庫需要升級的提示時,一定要慎重,不要輕易升級,否則,可能會造成系統宕機或很多命令無法操作等情況。
大模型實踐文章
LLM訓練:
| LLM | 預訓練/微調/RLHF… | 參數 | 教程 | 代碼 |
|---|---|---|---|---|
| Alpaca | full fine-turning | 7B | 從0到1復現斯坦福羊駝(Stanford Alpaca 7B) | N/A |
| Alpaca | lora | 7B | 1. 足夠驚艷,使用Alpaca-Lora基于LLaMA(7B)二十分鐘完成微調,效果比肩斯坦福羊駝 | |
| 2. 使用 LoRA 技術對 LLaMA 65B 大模型進行微調及推理 | 配套代碼 | |||
| BELLE(LLaMA-7B/Bloomz-7B1-mt) | full fine-turning | 7B | 1. 基于LLaMA-7B/Bloomz-7B1-mt復現開源中文對話大模型BELLE及GPTQ量化 | |
| 2. BELLE(LLaMA-7B/Bloomz-7B1-mt)大模型使用GPTQ量化后推理性能測試 | N/A | |||
| ChatGLM | lora | 6B | 從0到1基于ChatGLM-6B使用LoRA進行參數高效微調 | N/A |
| ChatGLM | full fine-turning/P-Tuning v2 | 6B | 使用DeepSpeed/P-Tuning v2對ChatGLM-6B進行微調 | N/A |
| Vicuna | full fine-turning | 7B | 大模型也內卷,Vicuna訓練及推理指南,效果碾壓斯坦福羊駝 | N/A |
| OPT | RLHF | N/A | 1. 一鍵式 RLHF 訓練 DeepSpeed Chat(一):理論篇 | |
| 2. 一鍵式 RLHF 訓練 DeepSpeed Chat(二):實踐篇 | N/A | |||
| MiniGPT-4 | full fine-turning | 7B | 大殺器,多模態大模型MiniGPT-4入坑指南 | N/A |
| Chinese-LLaMA-Alpaca | lora(預訓練+微調) | 7B | 使用 LoRA 技術對 LLaMA 65B 大模型進行微調及推理 | 配套代碼 |
結語
實踐出真知,以上是這段時間進行大模型實踐的一點點總結,寫的有一些主觀和片面,后續會持續更新自己研究大模型獲得的一些認知和實踐經驗,希望能夠幫助大家,歡迎點贊收藏加關注。
如何學習大模型
現在社會上大模型越來越普及了,已經有很多人都想往這里面扎,但是卻找不到適合的方法去學習。
作為一名資深碼農,初入大模型時也吃了很多虧,踩了無數坑。現在我想把我的經驗和知識分享給你們,幫助你們學習AI大模型,能夠解決你們學習中的困難。
我已將重要的AI大模型資料包括市面上AI大模型各大白皮書、AGI大模型系統學習路線、AI大模型視頻教程、實戰學習,等錄播視頻免費分享出來,需要的小伙伴可以掃取。

一、AGI大模型系統學習路線
很多人學習大模型的時候沒有方向,東學一點西學一點,像只無頭蒼蠅亂撞,我下面分享的這個學習路線希望能夠幫助到你們學習AI大模型。

二、AI大模型視頻教程

三、AI大模型各大學習書籍

四、AI大模型各大場景實戰案例

五、結束語
學習AI大模型是當前科技發展的趨勢,它不僅能夠為我們提供更多的機會和挑戰,還能夠讓我們更好地理解和應用人工智能技術。通過學習AI大模型,我們可以深入了解深度學習、神經網絡等核心概念,并將其應用于自然語言處理、計算機視覺、語音識別等領域。同時,掌握AI大模型還能夠為我們的職業發展增添競爭力,成為未來技術領域的領導者。
再者,學習AI大模型也能為我們自己創造更多的價值,提供更多的崗位以及副業創收,讓自己的生活更上一層樓。
因此,學習AI大模型是一項有前景且值得投入的時間和精力的重要選擇。










)
:【FA模型切換Stage模型指導】 module的切換)





)

