3.1 數據來源信息
該數據集來源于Kaggle網站,數據集中包含了羅平菜籽油的銷售數據,每行數據對應一條記錄,記錄了羅平菜籽油銷售數據。其中,菜籽產量、菜籽價格和菜籽油價格是數值型數據,共2486條數據。
通過讀取Excel文件并進行數據預處理,本文可以利用這些數據來進行羅平菜籽油銷售數據的分析和預測。部分數據如下圖3-1所示:
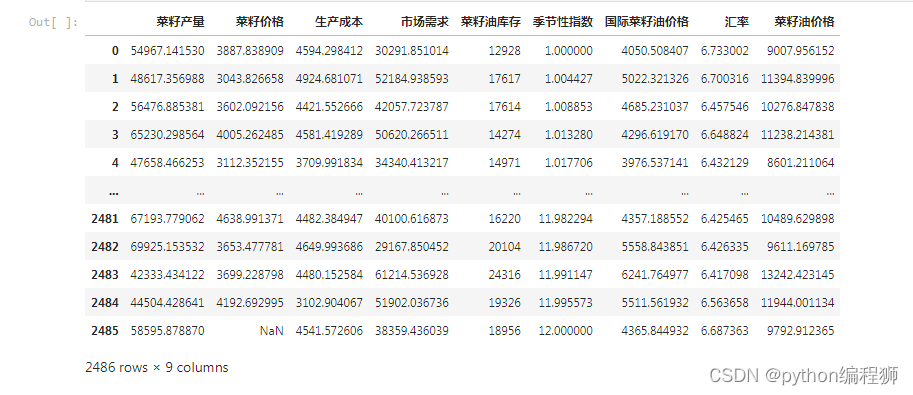
圖3-1數據詳情
3.2數據預處理
數據預處理的目的是清洗和準備數據,使其適用于后續的分析和建模。通過刪除缺失值和異常值,可以提高數據的質量和準確性,避免錯誤的影響。而標準化則可以消除不同特征之間的尺度差異,使得模型能夠更好地對特征進行學習和預測。通過這些數據預處理方法,本文可以得到更加干凈、準確和可靠的羅平菜籽油銷售數據集,為后續的分析和建模奠定基礎。數據預處理階段使用了以下幾個方法來處理羅平菜籽油銷售數據。
缺失值處理,通過使用統計空值方法檢查每個字段是否存在缺失值,并使用dropna()方法刪除包含缺失值的行。這樣可以確保數據的完整性和準確性,避免在后續分析中對缺失值進行處理時引入偏差。異常值處理,首先計算每個字段的均值和標準差,然后根據均值加減3倍標準差的范圍確定異常值的上下界,將超出該范圍的數據點刪除。這樣可以有效去除異常值的影響,使得后續分析更加穩定和可靠。數據標準化,使用標準化函數對特征進行標準化處理,將菜籽產量和菜籽價格的數據進行歸一化,消除不同特征之間的尺度差異。同時,將菜籽油價格轉換為千克單位,以便更好地適應實際應用場景。標準化可以使得數據具有零均值和單位方差,使得模型訓練過程更加穩定且更容易收斂。
3.2.1缺失值處理
使用統計空值方法檢測每個字段是否存在缺失值。該方法返回一個布爾型的一維對象,其中缺失值對應的位置為True,非缺失值對應的位置為False。
使用刪除空值方法刪除包含缺失值的行。該方法會刪除數據集中存在缺失值的所有行,并在原數據集上進行修改,即對數據集進行了操作。缺失值處理前如下圖3-2:

圖3-2缺失值處理前
通過這些步驟,可以實現對數據集中缺失值的處理。首先,通過檢測每個字段是否存在缺失值,可以了解到數據集中哪些字段存在缺失值。然后,使用刪除空值方法,將包含缺失值的行從數據集中刪除,以保證數據的完整性和準確性。
3.2.2異常值處理
通過循環遍歷數據集的每一列,獲取列名列表。對于每一列,首先計算其均值和標準差,使用平均值和標準差方法來計算,確定異常值的上下界。根據均值加減3倍標準差的范圍,使用循環遍歷數據集中的每一行,檢查每個字段的取值是否超出了異常值的上下界。如果某個字段的取值超出了上下界,則將該行數據從數據集中刪除,使用刪除空值方法進行刪除操作。
通過重新設置索引,對數據集的索引進行重新排序,以保證索引的連續性和正確性。
通過以上步驟,可以實現對數據集中異常值的處理。具體地,通過計算均值和標準差,確定異常值的上下界,然后遍歷數據集中的每一行,檢查每個字段的取值是否超過上下界,如果超出則刪除該行數據。這樣可以有效去除異常值的影響,使得數據更加可靠和準確。異常值處理結果如下圖3-4所示:

3.2.3數據標準化
數據標準化的實現包括以下幾個步驟:
通過定位列分別獲取特征和目標列。這里假設特征列位于數據集的前面,目標列位于最后一列。使用標準化函數創建一個標準化器對象stand。調用標準化器對象的特征進行標準化處理,將其轉換為均值為0、方差為1的標準正態分布,同時進行擬合和轉換操作。將目標列中的數據進行單位轉換,以便更好地適應實際應用場景。在這個例子中,將菜籽油價格從千克轉換為噸,即將每個值除以1000。
SVM 模型實現流程圖如下圖4-1所示:
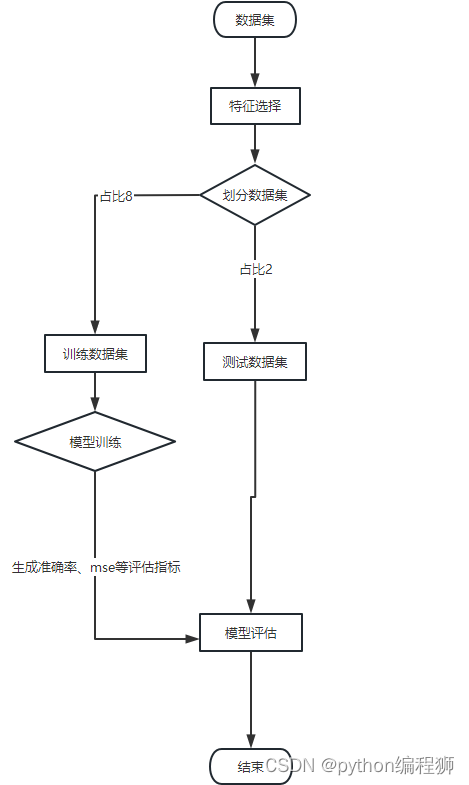
圖4-1模型實現流程
SVM 模型構建原理:
數據準備:準備羅平菜籽油銷售數據集,包括特征(銷售量、銷售時間等)和目標變量(銷售額等)。
特征工程:對數據進行特征選擇、處理和轉換,確保特征數據符合 SVM 模型的要求。
SVM 模型訓練:使用羅平菜籽油銷售數據集訓練 SVM 模型,選擇合適的核函數(如線性核、多項式核或高斯核)。
模型優化:調整 SVM 模型的超參數(如懲罰系數 C、核函數參數等),以獲得最佳的模型性能。
模型評估:使用交叉驗證等方法評估模型的性能,確保模型具有較好的泛化能力。
在 SVM 模型中,評價指標包括:準確率(Accuracy):(分類正確的樣本數占總樣本數的比例。精確率(Precision):預測為正類別且分類正確的樣本數占預測為正類別的樣本數的比例。召回率(Recall):預測為正類別且分類正確的樣本數占實際正類別的樣本數的比例。F1 分數(F1 Score):精確率和召回率的調和平均數,綜合考慮了模型的準確性和召回性能。
其公式如下:
(1)準確率(Accuracy)
其中,TP 表示真正例(True Positive)、TN 表示真負例(True Negative)、FP 表示假正例(False Positive)、FN 表示假負例(False Negative)。
(2)精確率(Precision)
(2)召回率(Recall)
(4)F1 分數(F1 Score)
這些評價指標可以幫助評估分類模型的性能,并提供關于模型在正例和負例分類方面的表現的詳細信息。綜合考慮精確率和召回率可以更全面地評估模型的性能。
對模型進行評估的過程如下所示:使用測試集的特征數據進行預測,將預測結果存儲變量中。然后,使用一些評估指標來評估模型的性能。包括均方誤差、平均絕對誤差和決定系數),分別計算了預測結果與實際結果之間的均方誤差、平均絕對誤差和決定系數。最后,根據評估結果,可以判斷模型的擬合效果和預測準確度。均方誤差和平均絕對誤差越小,表示模型的預測結果與實際結果越接近;決定系數越接近1,表示模型對觀測數據的擬合程度越好。評估結果如下圖4-2所示:
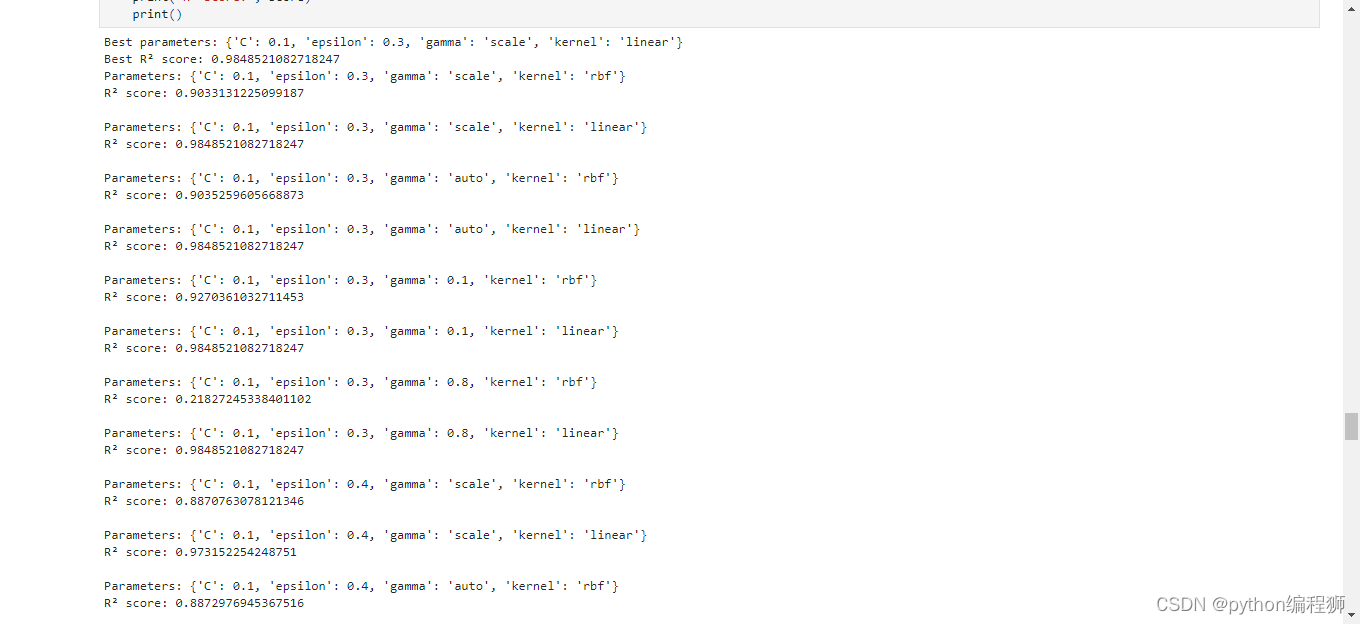
圖4-2評估結果
根據給定的評估結果,可以得出以下結論:
根據羅平菜籽油銷售數據的分析結果顯示,經過對 SVM 模型進行參數優化后,得到最佳參數組合為 C=0.1、epsilon=0.3、gamma='scale'、kernel='linear',對應的最佳 R2 得分為 0.9849。這意味著該 SVM 模型能夠解釋目標變量約 98.49% 的銷售數據方差,具有較高的預測精度。進一步觀察不同參數組合的評估結果發現,線性核函數在不同參數下的 R2 得分普遍較高,而徑向基核函數的 R2 得分相對較低。參數 C 和 epsilon 對模型性能影響較小,而參數 gamma 的取值對模型性能有一定影響,較小的 gamma 值會導致模型 R2 得分下降。綜合來看,經過優化的 SVM 模型在分析羅平菜籽油銷售數據方面表現出色,具有較高的預測準確性和穩定性。最終優化后結果如下圖4-3所示:
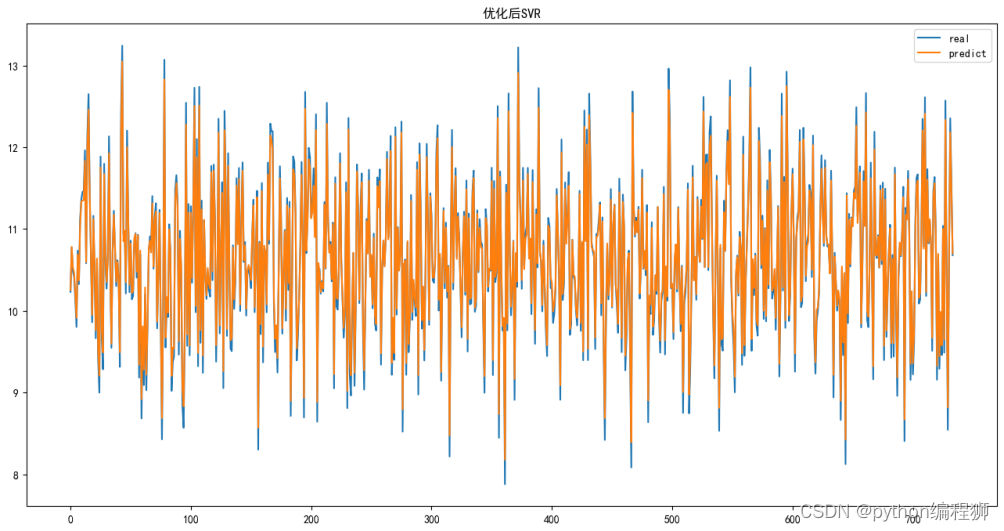
圖4-3優化后結果
根據圖4-2中羅平菜籽油銷售數據的預測值和測試值的折線對比圖,可以得出以下結論:
(1)模型預測值與實際測試值整體趨勢一致,說明經過優化的 SVM 模型能夠較好地擬合銷售數據的變化趨勢。
(2)預測值與測試值之間的偏差較小,表明該 SVM 模型在預測羅平菜籽油銷售數據時具有較高的準確性和穩定性。
(3)隨著時間的推移,預測值與測試值之間的偏差保持在較小的范圍內,說明該模型對于未來銷售數據的預測具有一定的可靠性和穩定性,為銷售預測和決策提供了可靠的參考依據。

-多頭自注意力機制)



)













